Ceph Networking: 10GbE vs 25GbE vs 100GbE e a Verdade sobre Gargalos

Pare de desperdiçar orçamento em placas 100GbE sem motivo. Descubra onde o gargalo real do Ceph se esconde: latência, CPU ou rede, e quando migrar de 10GbE para 25GbE.
Em arquitetura de armazenamento distribuído, existe um ditado brutalmente honesto: O Ceph não é um sistema de storage que usa a rede; o Ceph é uma aplicação de rede que, ocasionalmente, grava em disco.
Muitos engenheiros cometem o erro de dimensionar a rede baseando-se apenas na soma da velocidade dos discos. Eles olham para as especificações de throughput sequencial de um SSD e multiplicam pelo número de drives. O resultado é quase sempre um cluster que engasga sob carga ou desperdiça orçamento em hardware ocioso. A rede no Ceph é o sistema nervoso central; se ela satura ou introduz latência, o cérebro (MONs/MGRs) entra em pânico e os músculos (OSDs) atrofiam.
Neste artigo, vamos dissecar a física por trás das interfaces de 10GbE, 25GbE e 100GbE, ignorando o marketing dos fabricantes de switch e focando no que os contadores de performance do kernel e a latência de commit do OSD realmente nos dizem.
O Que Define a Performance de Rede no Ceph?
A performance de rede em um cluster Ceph é determinada pelo equilíbrio entre Throughput (vazão para recuperação de dados e grandes gravações) e Latência de Serialização (tempo para colocar pacotes no fio). Enquanto o throughput resolve gargalos de backfill e rebalanceamento, a redução da latência de serialização — obtida ao migrar de 10GbE para 25GbE ou 100GbE — melhora diretamente o IOPS de gravação e a responsividade do cluster, mesmo que a banda total não seja saturada.
Largura de Banda vs. Latência de Serialização: A Física do Fio
A maioria dos administradores visualiza a rede como um cano de água: um cano de 100GbE é 10 vezes mais largo que um de 10GbE. Essa analogia é perigosa porque ignora o tempo. Uma analogia melhor é uma rodovia com limites de velocidade diferentes.
No Ceph, cada gravação (write) precisa ser replicada. Se você tem size=3, o dado entra no OSD Primário e é enviado para dois OSDs Secundários. O Primário não pode dizer "OK" ao cliente até que os Secundários confirmem a gravação. Aqui entra a Latência de Serialização.
Em uma interface de 10GbE, leva-se um tempo físico mensurável para colocar um frame Ethernet de 1500 bytes no fio. Em 100GbE, esse tempo é 10 vezes menor. Mesmo que seu cluster esteja trafegando apenas 2 Gbps de dados, a interface de 100GbE entregará cada pacote individual mais rápido, reduzindo a latência total da operação de escrita.
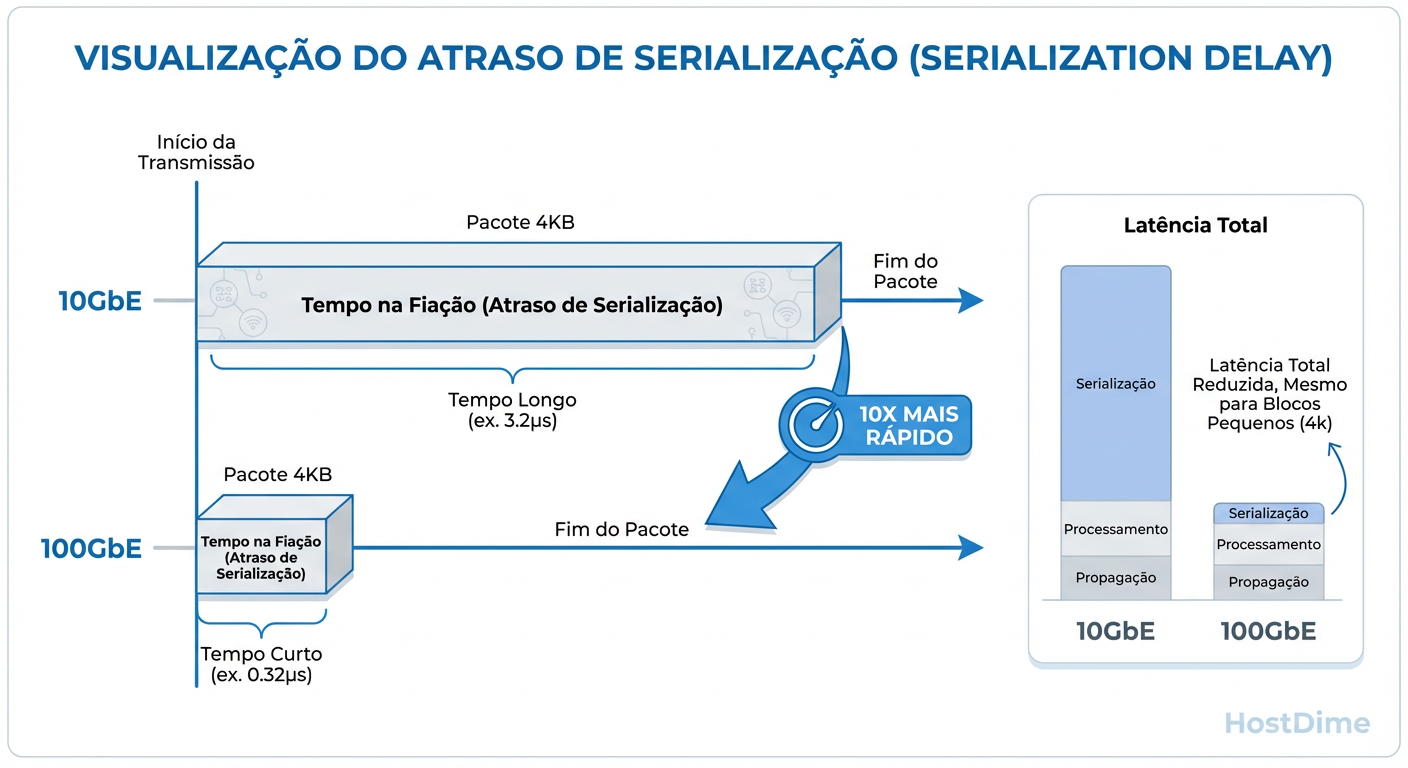 Figura: Latência de Serialização: Por que 100GbE reduz a latência mesmo sem saturar a banda. O tempo para colocar o pacote no fio diminui drasticamente.
Figura: Latência de Serialização: Por que 100GbE reduz a latência mesmo sem saturar a banda. O tempo para colocar o pacote no fio diminui drasticamente.
Isso explica um fenômeno que confunde muitos engenheiros: ao migrar de 10GbE para 100GbE, a latência média de gravação cai drasticamente, mesmo que o gráfico de utilização de banda mostre que o link nunca passou de 20%. Você não comprou 100GbE pela largura; você comprou pela velocidade de serialização.
O Limite do 10GbE e o Pesadelo do Recovery
A interface de 10GbE foi o padrão por uma década, mas hoje ela representa a "zona de perigo" para qualquer cluster que não seja puramente baseado em HDDs (Hard Disk Drives).
O problema real do 10GbE no Ceph não é o tráfego de cliente em dia calmo (steady state). O problema é o Recovery e Backfill. Quando um OSD falha ou um nó é reiniciado, o Ceph tenta curar o cluster movendo dados para restaurar a redundância. Esse tráfego compete violentamente com o tráfego do cliente.
Se você tem um nó com 10 SSDs SATA, cada um capaz de ler a 500MB/s, esse nó pode gerar internamente 5GB/s (40Gbps) de tráfego de leitura durante um rebalanceamento. Um link de 10GbE (1.25GB/s teóricos) se torna um funil imediato.
O Sintoma Clínico: Durante um rebuild, a latência do cliente dispara de 2ms para 200ms+. O link satura, os buffers do switch enchem, e pacotes de heartbeat do Ceph começam a atrasar, podendo causar falsos positivos de OSDs "down", gerando um efeito cascata (flapping).
Por que 25GbE é o Padrão Ouro para SATA/SAS (e o fim do 40GbE)
Se 10GbE é pouco, por que não usar 40GbE? Porque 40GbE é, tecnicamente, uma "gambiarra" histórica. O padrão 40GbE geralmente consiste em 4 canais de 10GbE amarrados (4x10G lanes). Isso não melhora a latência de serialização por canal da mesma forma que um salto de tecnologia de sinalização.
O 25GbE, por outro lado, usa uma única lane (SFP28) com sinalização mais rápida.
Custo-Benefício: O custo por porta de 25GbE é marginalmente superior ao de 10GbE hoje em dia.
Adequação à Mídia: Um servidor 1U ou 2U cheio de SSDs SATA/SAS raramente saturará 25GbE (aprox. 3GB/s) em tráfego de cliente normal, mas oferece "teto" suficiente para que o recovery aconteça sem matar a latência da aplicação.
Top-of-Rack (ToR): Switches modernos de 100GbE geralmente permitem fazer breakout de uma porta 100G para 4x 25G, simplificando o cabeamento.
Para clusters All-Flash baseados em SATA/SAS, 25GbE é a escolha pragmática. Oferece a largura de banda necessária para evitar contenção durante falhas, sem o custo premium de óptica e switches 100GbE.
A Ilusão do 100GbE: Onde a CPU se torna o Gargalo
Ao entrar no território do NVMe e do 100GbE, as regras da física mudam. Você resolve o problema da rede, mas colide violentamente com a capacidade da CPU e a eficiência do barramento PCIe.
Mover 100 Gigabits por segundo requer processar milhões de pacotes por segundo. Se o tamanho do seu MTU for padrão (1500 bytes), estamos falando de mais de 8 milhões de pacotes por segundo para saturar o link. Cada pacote gera uma interrupção na CPU.
O Deslocamento do Gargalo: Em 100GbE, é comum ver um núcleo da CPU ir a 100% de uso tratando interrupções de rede (SoftIRQs), enquanto o resto da CPU está ocioso e a rede está em 40% de uso. O gargalo não é mais o fio, é o kernel Linux tentando tirar dados do fio rápido o suficiente.
 Figura: O deslocamento do gargalo: À medida que a rede se abre (100GbE), o teto de performance colide violentamente com a capacidade da CPU e a latência do software, não mais com o 'cano' da rede.
Figura: O deslocamento do gargalo: À medida que a rede se abre (100GbE), o teto de performance colide violentamente com a capacidade da CPU e a latência do software, não mais com o 'cano' da rede.
Para operar 100GbE eficientemente no Ceph, você precisa de uma abordagem cirúrgica:
NUMA Awareness: A placa de rede deve estar no mesmo soquete de CPU que os drives NVMe que ela serve. Cruzar o barramento QPI/UPI entre processadores adiciona latência que o NVMe não perdoa.
Jumbo Frames (MTU 9000): Essencial. Reduz o número de pacotes a processar em 6 vezes.
Offloads: LRO (Large Receive Offload) e TSO (TCP Segmentation Offload) devem estar ativos e funcionando corretamente.
Análise de Cenário: Dimensionando a Rede por Tipo de Mídia
Não existe "melhor rede", existe rede alinhada à capacidade da mídia de armazenamento. Abaixo, uma comparação técnica para guiar a decisão de arquitetura.
| Tipo de Cluster (Mídia) | Interface Recomendada | Racional Técnico | Risco Principal |
|---|---|---|---|
| HDDs (Spinning Rust) | 2x 10GbE (LACP) | HDDs são lentos. O gargalo é mecânico (seek time). 10GbE sobra para IO de cliente, mas o LACP ajuda no Recovery. | Rebuilds muito lentos se a densidade de discos por nó for alta (>12 OSDs). |
| SATA/SAS SSDs | 25GbE (Dual) | O "Sweet Spot". Equilibra a velocidade agregada dos SSDs com a capacidade da rede. | Usar 10GbE aqui causará engasgos severos durante Backfill. |
| NVMe (High Performance) | 100GbE | NVMe expõe a latência do fio. 25GbE se torna o gargalo imediato. Necessário para baixa latência. | CPU Overhead. Sem tuning de kernel e NUMA, você desperdiça o investimento. |
| NVMe (Edge/Entry) | 50GbE / 2x 25GbE | Para clusters NVMe menores ou com CPUs mais modestas onde 100GbE é overkill. | Complexidade de cabeamento se usar bonding de muitas interfaces. |
Como Medir a Saturação Real da Rede no Ceph
Esqueça o iperf3 por um momento. O iperf3 mede o que a rede pode fazer em condições sintéticas, não o que o Ceph está sofrendo. Para provar um gargalo de rede no Ceph, você precisa correlacionar métricas.
1. Verifique Drops e Erros no Driver
Antes de culpar a banda, verifique se há problemas físicos ou de buffer.
ethtool -S eth0 | grep -E "drop|fail|err|miss" | grep -v ": 0"
Se você vir contadores de rx_dropped ou rx_missed_errors subindo, sua CPU não está conseguindo drenar o buffer do anel da placa de rede rápido o suficiente, ou o switch está descartando pacotes.
2. Monitore a Fila de Transmissão (TX Queue)
Use o comando ss ou sar para ver se o kernel está enfileirando pacotes porque a interface não dá conta.
# Observe a coluna 'tx-queue' ou use sar
sar -n EDEV 1 5
Se %ifutil estiver próximo de 100% e você vir latência no Ceph, a correlação é clara.
3. Latência de OSD Commit vs. Apply
No Ceph, monitore a diferença entre a latência de apply (gravação no journal/WAL) e commit (flush para o disco). Se a latência de rede entre OSDs for alta, você verá tempos de commit flutuantes e altos tempos de peer ping.
Use o daemon de performance do Ceph para validar:
ceph osd perf
Foque na coluna commit_latency_ms. Se ela for alta apenas em alguns nós e correlacionar com alto tráfego de rede nesses nós, você encontrou seu gargalo.
Veredito Técnico: O Pragmatismo Vence o Hype
Não implemente 100GbE apenas para dizer que tem. Implemente se seus drives NVMe exigirem latência de microssegundos. Não fique preso ao 10GbE se você usa SSDs, ou seus tempos de recuperação de falha deixarão seus usuários insatisfeitos.
A rede no Ceph é um exercício de equilíbrio: o cano deve ser largo o suficiente para o pior dia (recovery), e rápido o suficiente (latência) para a melhor experiência.
Referências & Leitura Complementar
Ceph Network Configuration Guide - Documentação oficial sobre Front-end vs Back-end networks.
Intel Ethernet Controller E810 Datasheet - Detalhes sobre Application Device Queues (ADQ) e otimizações para NVMe-oF.
Mellanox/NVIDIA Tuning Guide for Storage - Whitepapers sobre otimização de IRQ affinity e NUMA para 100GbE.
RFC 2544 - Benchmarking Methodology for Network Interconnect Devices (Fundamental para entender testes de throughput vs latência).

Daniel Siqueira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensor do 'Infrastructure as Code' para storage.