Ceph no Proxmox: 5 Erros de Arquitetura que Custam Caro (e Como Evitar)

A facilidade da GUI do Proxmox esconde a complexidade do Ceph. Descubra por que SSDs sem PLP, redes de 1GbE e Réplica 2 são bombas-relógio no seu cluster HCI.
A integração nativa do Ceph no Proxmox VE (PVE) é, sem dúvida, uma das funcionalidades mais sedutoras da virtualização moderna. Com alguns cliques, você transforma três servidores isolados em um cluster hiperconvergente (HCI) capaz de sobreviver à falha de nós inteiros. A promessa é mágica: armazenamento distribuído, escalável e resiliente.
No entanto, como engenheiro de performance, aprendi que a física não perdoa. O Ceph não é apenas um software que você instala; é um sistema distribuído complexo que troca ciclos de CPU e latência de rede por consistência de dados. A facilidade de instalação do Proxmox mascara a complexidade arquitetural subjacente. Se você tratar o Ceph como um RAID local glorificado, o resultado não será apenas lentidão; será instabilidade operacional e latência de I/O na casa dos segundos.
Abaixo, dissecamos os erros arquiteturais mais comuns, não baseados em opiniões, mas na mecânica de funcionamento do protocolo RADOS.
O que é o "Write Penalty" do Ceph?
Definição de Arquitetura: O Ceph prioriza a consistência dos dados (CP no teorema CAP). Isso significa que uma operação de escrita (Write) só é confirmada ao cliente quando os dados foram persistidos fisicamente no disco de todas as réplicas ativas. Esse comportamento síncrono introduz uma penalidade de latência inevitável, tornando a escolha do hardware (especialmente discos e rede) crítica para evitar gargalos em cascata.
1. A Mecânica da Escrita: Entendendo a Latência Distribuída
Para diagnosticar performance no Ceph, você precisa abandonar o modelo mental de um disco local. Em um servidor tradicional, o SO envia dados para a controladora e recebe um "OK". No Ceph, o buraco é muito mais embaixo.
Quando uma VM no Proxmox solicita uma gravação, o Ceph não apenas "salva o arquivo". Ele precisa replicar esse dado através da rede para outros nós (OSDs) antes de liberar a VM para continuar processando.
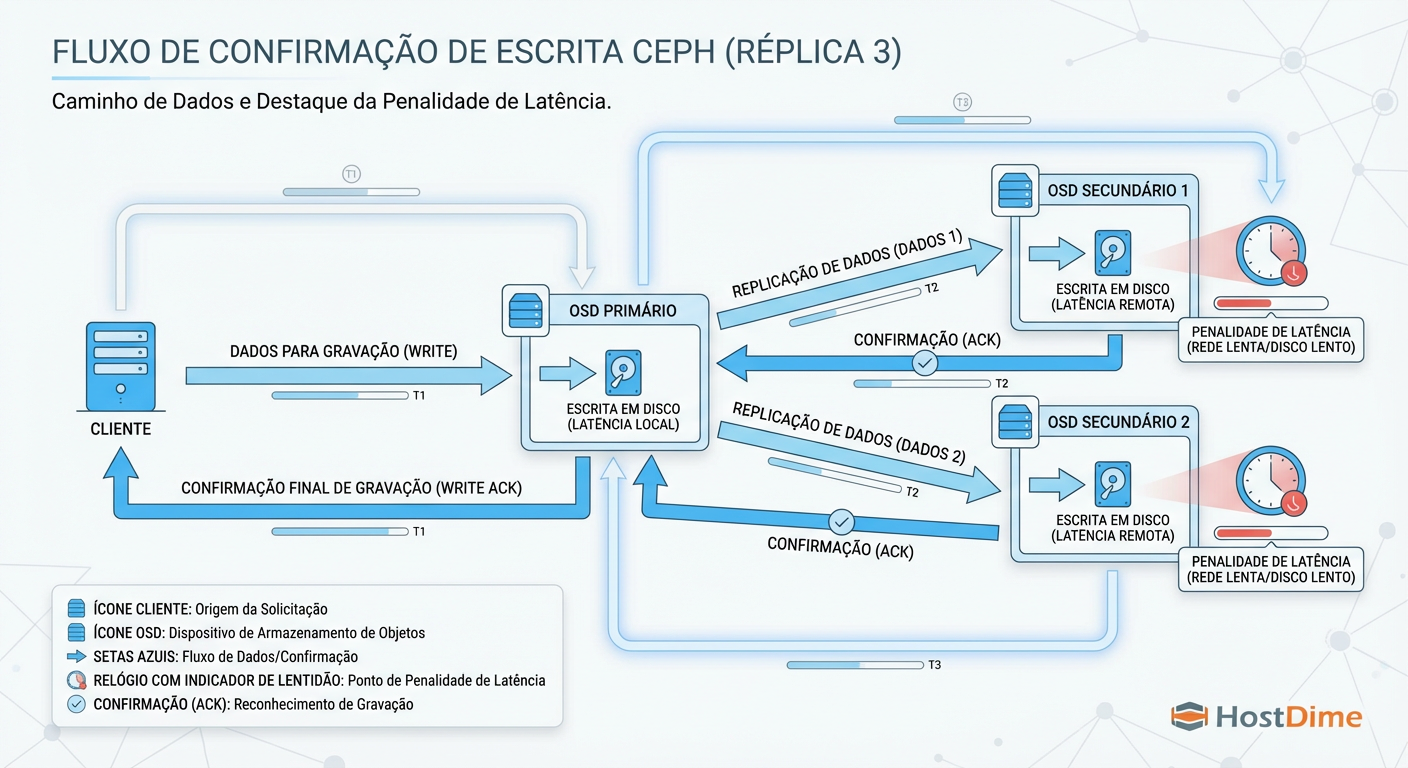 Figura: O Caminho do Write: O cliente só recebe 'OK' quando todos os OSDs confirmam.
Figura: O Caminho do Write: O cliente só recebe 'OK' quando todos os OSDs confirmam.
Como ilustrado acima, o cliente (sua VM) fica em estado de espera (I/O Wait) até que o OSD Primário e os OSDs Secundários confirmem a gravação. Se qualquer componente nesse caminho for lento — seja o disco do nó secundário ou o switch de rede — todo o cluster sofre. A latência do Ceph é ditada pelo componente mais lento da corrente.
2. Por que SSDs sem PLP Destroem a Performance do Ceph
O erro mais devastador em setups de homelab ou pequenas empresas é o uso de SSDs de consumo (Samsung EVO, QVO, Kingston básicos) para armazenar OSDs do Ceph.
O problema não é a velocidade de leitura ou a interface SATA/NVMe. O problema é como o Ceph lida com Sync Writes. O Ceph usa um journal (BlueStore WAL/DB) e exige que o disco confirme que o dado está fisicamente seguro na NAND flash antes de prosseguir.
SSDs de consumo mentem ou engasgam sob essa pressão. Eles dependem de cache DRAM volátil. Para garantir a segurança (flush), eles precisam pausar e gravar na flash, o que é lento. Já SSDs Enterprise possuem PLP (Power Loss Protection) — capacitores físicos que permitem ao drive confirmar a gravação instantaneamente (na DRAM do disco) e gravar na flash depois, com segurança garantida pelos capacitores em caso de queda de energia.
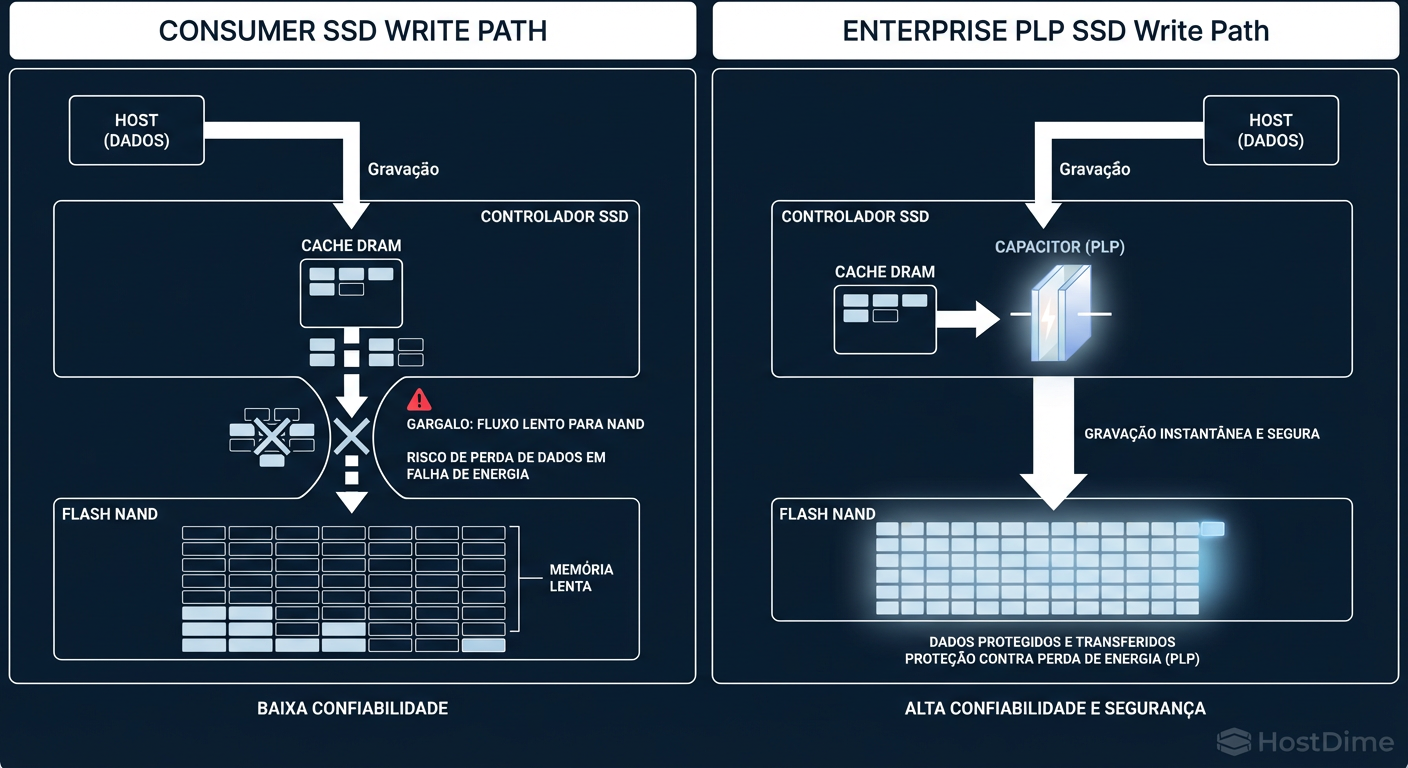 Figura: O Efeito PLP: Por que SSDs de consumo engasgam com writes síncronos do Ceph.
Figura: O Efeito PLP: Por que SSDs de consumo engasgam com writes síncronos do Ceph.
A diferença não é marginal. Em testes de random write 4k síncronos (padrão de banco de dados e virtualização):
SSD Consumo: ~400 a 1.000 IOPS (latência > 10ms).
SSD Enterprise (PLP): ~20.000 a 50.000 IOPS (latência < 0.5ms).
Se o seu cluster Proxmox apresenta iowait alto nas VMs, verifique o modelo dos seus SSDs. Se não tiverem PLP, você encontrou seu gargalo.
Comparativo Técnico: SSD Consumo vs. Enterprise (PLP)
| Característica | SSD Consumo (Ex: Samsung 980/QVO) | SSD Enterprise (Ex: Intel D3-S4510 / Micron 5300) | Impacto no Ceph |
|---|---|---|---|
| Proteção de Cache | Nenhuma (Volátil) | Capacitores (PLP) | PLP permite commits imediatos e seguros. |
| Latência de Sync Write | Alta (precisa flush na NAND) | Baixa (flush na DRAM protegida) | Latência de VM cai de 10ms para 0.2ms. |
| Endurance (DWPD) | Baixo (0.3 - 0.6) | Alto (1.0 - 3.0+) | O Ceph é "write-heavy" devido à replicação. |
| Consistência | Variável (Saturação de cache SLC) | Estável / Previsível | Evita picos de lentidão aleatórios ("stalls"). |
3. Rede e Latência: O Mito do 1GbE e a Rede de Cluster
Há uma crença perigosa de que "para poucas VMs, 1GbE é suficiente". Em armazenamento distribuído, latência importa mais que largura de banda.
O tráfego do Ceph compete com o tráfego das VMs, tráfego de migração e corosync. Em uma rede de 1GbE, a serialização dos pacotes (o tempo para colocar os bits no fio) adiciona milissegundos preciosos. Mais grave ainda é o tempo de recuperação (rebalancing).
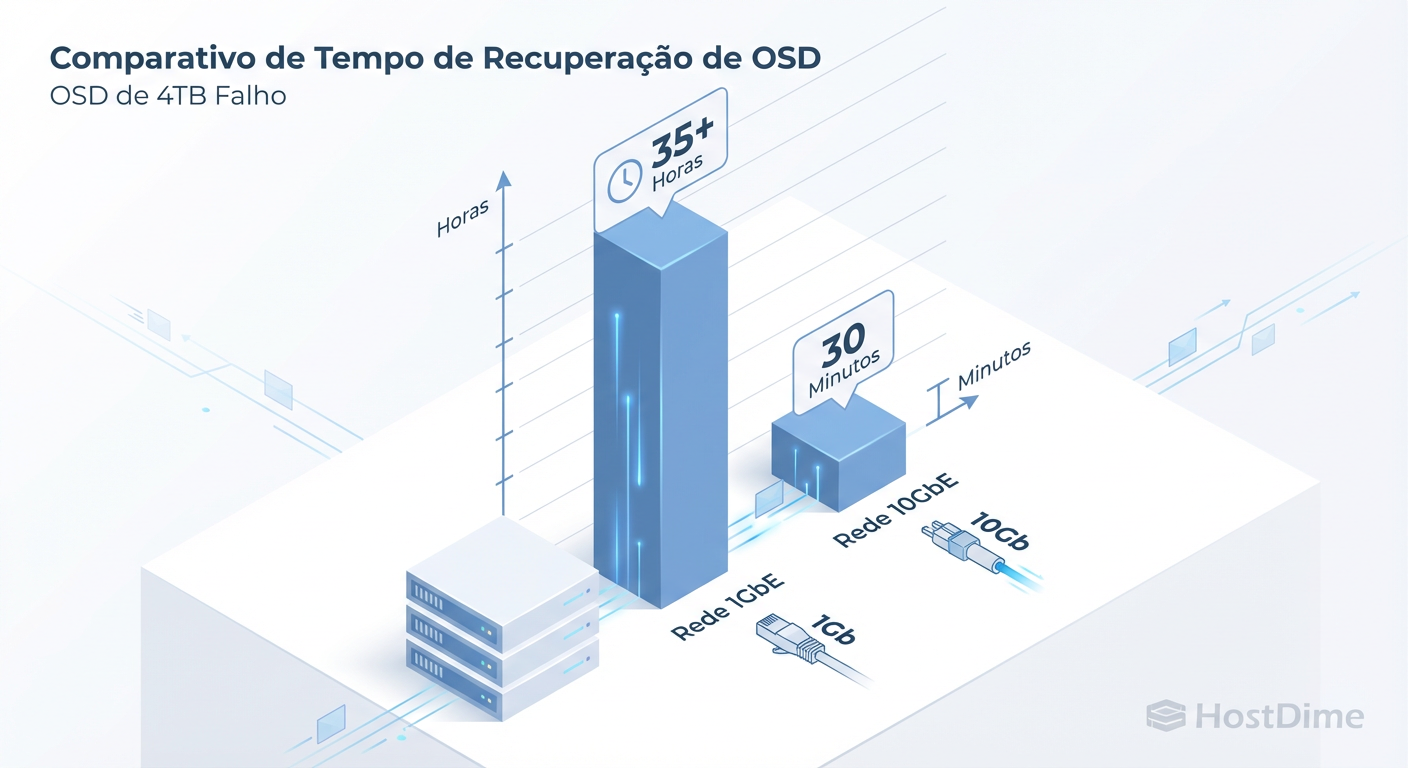 Figura: Impacto da Rede na Recuperação: O tempo que seu cluster fica vulnerável.
Figura: Impacto da Rede na Recuperação: O tempo que seu cluster fica vulnerável.
Quando um OSD falha ou um nó reinicia, o Ceph tenta "curar" o cluster movendo dados para restaurar a redundância. Em 1GbE, essa reconstrução satura o link completamente. O resultado? As latências de escrita das VMs disparam porque o "tubo" está entupido com dados de recuperação.
Separação de Tráfego: Rede Pública vs. Cluster
Vale a pena separar?
Rede Pública (Front-end): Onde as VMs (clientes) falam com os OSDs.
Rede de Cluster (Back-end): Onde os OSDs replicam dados entre si (heartbeats e rebalanceamento).
Em ambientes de alta performance, a separação física (duas placas/portas distintas) é vital. Se você perder um OSD e o cluster iniciar o rebalancing na mesma interface que serve as VMs, sua produção vai parar. No mínimo, use VLANs distintas com QoS, mas o ideal físico é mandatório para estabilidade sob estresse.
4. A Armadilha da 'Economia': Replica 2 vs. Replica 3
O padrão do Ceph é size=3, min_size=2. Isso significa: "Mantenha 3 cópias, mas aceite escrever se pelo menos 2 confirmarem".
Muitos administradores alteram para size=2, min_size=1 para economizar 33% de espaço em disco. Isso é roleta russa.
Risco de Perda de Dados: Se você tem
size=2e um disco falha, você tem apenas uma cópia restante. Se, durante a recuperação (que estressa os discos), ocorrer um erro de leitura (URE - Unrecoverable Read Error) no disco sobrevivente, o dado está perdido para sempre.Risco de Split-Brain: Com 2 réplicas, em caso de partição de rede, é difícil para o cluster determinar qual cópia é a "verdadeira" atualizada sem um árbitro adequado.
Disponibilidade Operacional: Com
size=3, min_size=2, você pode desligar um nó para manutenção e o cluster continua aceitando escritas (pois 2 cópias ainda existem). Comsize=2, min_size=2, se um nó cai, o pool entra em modo Read Only para proteger a integridade, parando todas as suas VMs.
Veredito: O custo de um disco extra é infinitamente menor que o custo de downtime ou perda de dados. Mantenha Replica 3.
5. Controladoras de Disco: O Perigo do Hardware RAID
O Ceph é projetado para gerenciar o disco diretamente. Ele conhece a geometria, gerencia setores defeituosos e monitora a saúde via SMART.
Colocar o Ceph em cima de um RAID de Hardware (ex: RAID 0 ou RAID 5 na controladora) é um erro crasso por dois motivos:
Mascaramento de Erros: A controladora de RAID tenta "corrigir" erros silenciosamente. O Ceph precisa saber imediatamente se um setor falhou para buscar a réplica em outro nó. O RAID esconde isso, causando timeouts no sistema operacional.
Cache Duplo e Flush: Controladoras RAID com cache de bateria podem mentir sobre o flush de dados de maneira que conflita com o journal do Ceph, ou introduzir latência ao processar filas que o Ceph poderia gerenciar melhor.
A Solução: Use HBAs (Host Bus Adapters) ou controladoras RAID flashadas em IT Mode (Initiator Target). Isso expõe os discos brutos (JBOD) ao Proxmox/Ceph. O ZFS e o Ceph foram feitos para controlar o hardware, não para lutar contra ele.
6. Métricas que não mentem: Validando seu Pool
Não coloque seu cluster em produção baseando-se em "sensação". Teste. Mas não use dd (que testa apenas throughput sequencial e muitas vezes cai no cache do Linux). Use fio para simular a carga real de virtualização.
O cenário mais difícil para o Ceph (e o mais comum em VMs) é Random Write 4k.
Execute este comando dentro de uma VM (não no host) para testar o desempenho real que a aplicação sentirá:
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 \
--name=test --filename=teste.fio --bs=4k --iodepth=64 --size=4G \
--readwrite=randwrite --ramp_time=4
Interpretação dos Resultados:
IOPS: Se o resultado for < 500 IOPS, seu cluster está impróprio para bancos de dados ou muitas VMs Windows.
Latência (clat): Olhe para o percentil 95% ou 99%. Se estiver acima de 10ms-20ms, usuários reportarão lentidão.
Veredito Técnico
O Ceph no Proxmox é uma ferramenta poderosa de nível empresarial, mas exige respeito às leis da física e da computação distribuída. A "economia" feita em SSDs sem PLP, rede de 1GbE ou réplicas reduzidas será cobrada com juros compostos na forma de instabilidade e noites sem dormir recuperando dados.
Arquitetar corretamente significa entender que, no Ceph, a confiabilidade e a latência são produtos diretos do hardware que você escolhe e da topologia que você desenha.
Referências & Leitura Complementar
Ceph Documentation - Hardware Recommendations: Foco em requisitos de CPU e OSD Journaling.
Proxmox VE Admin Guide - Ceph Server: Detalhes específicos da implementação Hyper-Converged.
Micron Tech Brief: "Impact of SSD Write Cache and Power Loss Protection on Ceph Performance".
Sebastien Han (Red Hat): Artigos seminais sobre otimização de BlueStore e RocksDB.

Vinícius Rocha
Enterprise Storage Consultant
Consultor para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.