Ceph QoS e Multi-tenancy: Isolamento Real ou Ilusão de Controle?

Cansado de 'vizinhos barulhentos' derrubando seu banco de dados no Ceph? Entenda a diferença entre Limites RBD e o algoritmo mClock, e aprenda a medir se o isolamento de tenants realmente funciona.
Você recebe um chamado às 3 da manhã. O banco de dados de produção está engasgando. A latência de gravação, que deveria ser estável em 2ms, está oscilando entre 50ms e 200ms. Você verifica os gráficos e vê que o throughput total do cluster está longe do máximo teórico.
A primeira reação do administrador médio é aplicar limites rígidos: "Vou limitar todo mundo a 500 IOPS". Ele aplica a configuração, reinicia as VMs e vai dormir. O problema persiste.
Por que isso acontece? Porque em sistemas distribuídos como o Ceph, limitar a velocidade de um carro não impede o engarrafamento na estrada. Como investigador forense de sistemas, não aceitamos a palavra "configurado" como sinônimo de "resolvido". Vamos dissecar a anatomia do QoS no Ceph, separar o que é controle real do que é apenas throttling cosmético e entender por que o algoritmo mClock (introduzido no Quincy) mudou as regras do jogo.
O que é QoS no Ceph?
Ceph Quality of Service (QoS) é o conjunto de mecanismos que gerencia a contenção de recursos de I/O, operando em duas camadas distintas: o cliente (librbd) e o servidor (OSD). Enquanto o QoS do cliente apenas limita a taxa de envio de requisições (Token Bucket), o QoS do OSD (mClock scheduler) reordena e prioriza ativamente as operações na fila do disco, garantindo que cargas de trabalho críticas recebam sua fatia de tempo reservada mesmo durante picos de saturação ou tarefas de background.
A Falácia do Limite Rígido no Cliente (Librbd)
O erro mais comum ao projetar QoS no Ceph é confiar exclusivamente nas configurações de imagem RBD (rbd_qos_iops_limit).
Quando você define um limite na imagem RBD, você está configurando um Token Bucket Filter dentro da biblioteca librbd, que roda no host do cliente (no hipervisor KVM/QEMU). O cliente monitora a si mesmo e, se exceder o limite, segura os pacotes antes de enviá-los à rede.
Isso é útil para cobrança (billing) em nuvens públicas, mas é péssimo para garantir performance.
O problema da "Estrada Livre": Imagine que seu cluster está vazio. Um cliente com limite de 500 IOPS vai rodar a 500 IOPS, desperdiçando todo o resto da capacidade do cluster. O problema do "Vizinho Barulhento": Imagine que 100 clientes, cada um limitado a 100 IOPS, decidem gravar ao mesmo tempo. O OSD recebe 10.000 IOPS. Se o disco físico só aguenta 5.000 IOPS, a fila enche e a latência explode para todos, inclusive para aquele cliente crítico que estava enviando apenas 10 IOPS.
O limite no cliente não tem consciência do estado do disco. É um controle cego.
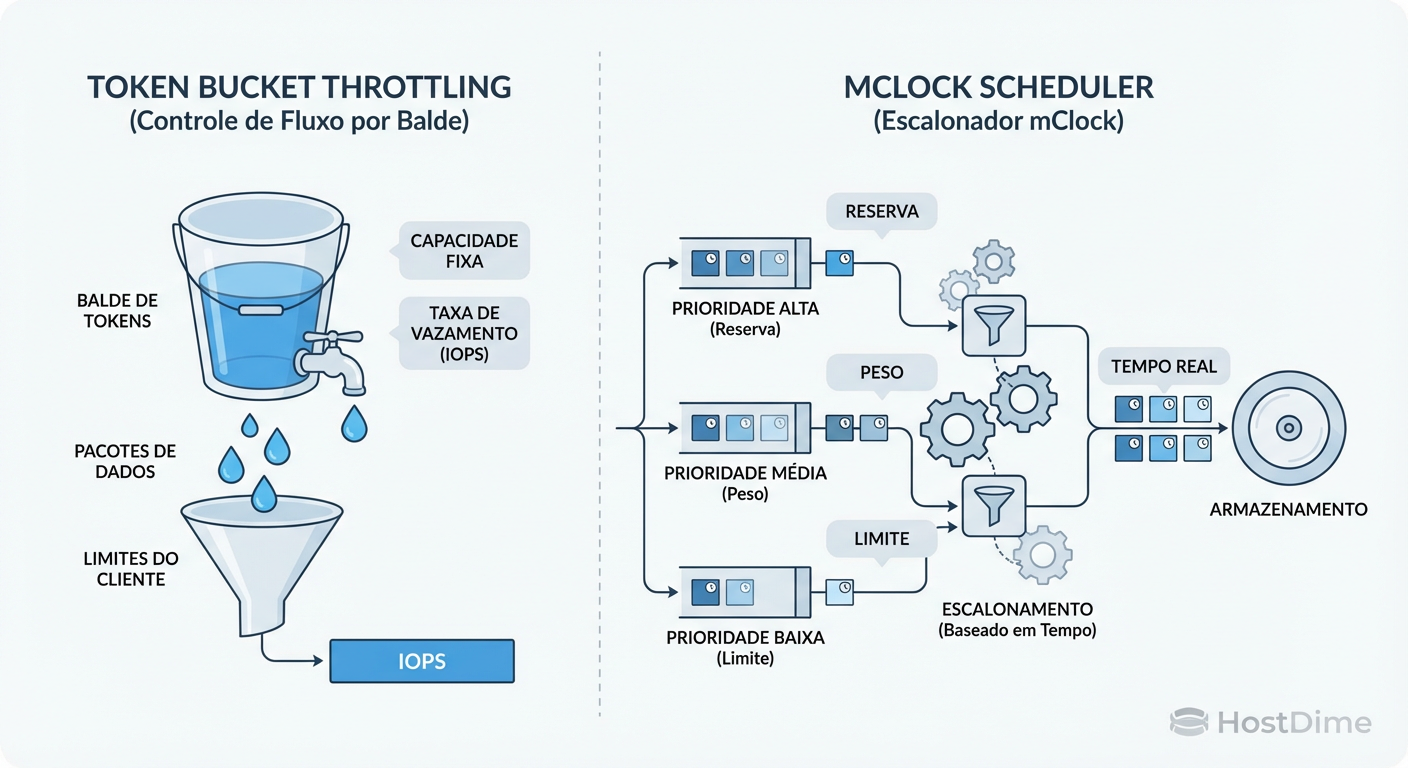 Figura: A Ilusão vs. A Realidade: Throttling no cliente apenas segura o tráfego, enquanto o Scheduler no OSD (mClock) realmente organiza a disputa pelo disco.
Figura: A Ilusão vs. A Realidade: Throttling no cliente apenas segura o tráfego, enquanto o Scheduler no OSD (mClock) realmente organiza a disputa pelo disco.
Arquitetura de Controle: Token Bucket vs. mClock Scheduler
Para ter isolamento real, o controle precisa acontecer onde a disputa ocorre: na fila de entrada do OSD, logo antes de gravar no disco (BlueStore).
Até versões antigas (pré-Quincy), o Ceph usava o WPQ (Weighted Priority Queue). Era simples: operações de clientes tinham prioridade sobre operações de background (como recovery). Mas o WPQ falhava em diferenciar "Cliente Gold" de "Cliente Bronze".
A partir do Ceph Quincy, o padrão tornou-se o mClock. Este algoritmo não é apenas um limitador; é um agendador de recursos baseado em tempo. Ele permite definir três parâmetros cruciais para cada tipo de tráfego:
Reservation (Reserva): O mínimo garantido (IOPS ou Banda). O sistema deve atender isso custe o que custar.
Weight (Peso): A proporção justa do que sobra. Se o cluster tem capacidade ociosa, quem tem mais peso pega mais.
Limit (Limite): O teto máximo (o clássico limit). Ninguém passa daqui, mesmo que o disco esteja ocioso.
Comparativo de Mecanismos de Controle
| Característica | Throttling no Cliente (Librbd) | Agendamento no OSD (mClock) |
|---|---|---|
| Local de Atuação | Hipervisor / VM | Ceph OSD (Servidor) |
| Mecanismo | Token Bucket (Pausa envio) | DMClock (Reordena fila) |
| Visibilidade | Cego (Só vê o próprio tráfego) | Total (Vê todos os clientes + background) |
| Objetivo Principal | Limitar consumo (Billing) | Garantir SLA (Performance) |
| Impacto em Latência | Adiciona latência artificial | Reduz latência de cauda (tail latency) |
| Proteção Real | Nenhuma (Vizinhos ainda afetam) | Alta (Isola fluxos concorrentes) |
Dissecando o mClock no Ceph Quincy+
O mClock resolve o dilema de "limitar vs. garantir". Ele permite que você diga ao Ceph: "Garanta 500 IOPS para este volume. Se sobrar espaço, dê a ele o dobro da prioridade dos outros, mas nunca deixe passar de 5000 IOPS".
O Ceph implementa perfis pré-definidos de mClock (high_client_ops, balanced, high_recovery_ops), mas a mágica acontece quando configuramos perfis customizados por pool ou imagem.
Para validar se o mClock está ativo e qual perfil está em uso, não adivinhe. Verifique:
ceph config show-with-defaults osd.0 | grep osd_mclock_profile
# Definir um perfil customizado (exemplo)
ceph config set osd osd_mclock_profile custom
A configuração fina exige manipular as chaves de QoS do RBD. Diferente do limite simples, aqui definimos a reserva:
# Garantir 1000 IOPS mínimos (Reservation)
rbd config image set pool/imagem_gold conf_rbd_qos_read_iops_min 1000
rbd config image set pool/imagem_gold conf_rbd_qos_write_iops_min 1000
# Definir teto máximo de 5000 IOPS (Limit)
rbd config image set pool/imagem_gold conf_rbd_qos_read_iops_limit 5000
rbd config image set pool/imagem_gold conf_rbd_qos_write_iops_limit 5000
Nota Investigativa: Se você define uma "Reserva" maior do que o hardware físico pode entregar, o mClock não fará milagres. A soma das reservas de todos os clientes ativos não pode exceder a capacidade física dos OSDs, ou a latência explodirá do mesmo jeito.
O Teste do Vizinho Barulhento: Bully vs. Victim
Teoria é bonita, mas como investigador, eu preciso de evidência. Vamos montar um cenário de crime para provar se o QoS funciona.
Cenário:
Vítima (Victim): Um banco de dados simulado (Postgres) que precisa de latência baixa e constante.
Valentão (Bully): Um processo de backup ou analytics que faz leituras sequenciais massivas e aleatórias, tentando saturar o link.
Sem QoS no OSD, quando o Valentão começa, a latência da Vítima deve subir proporcionalmente à ocupação da fila. Com mClock configurado corretamente (dando reservation para a Vítima), a latência deve se manter estável.
O Kit de Autópsia (FIO)
Use o fio para simular os dois atores. Não rode testes aleatórios; isole as variáveis.
Job da Vítima (Latência Sensível):
[victim-db]
ioengine=rbd
pool=rbd
rbdname=victim_image
rw=randwrite
bs=4k
iodepth=1
# Limitamos a taxa para simular uma carga constante, mas leve
rate_iops=200
Job do Valentão (Saturação):
[bully-backup]
ioengine=rbd
pool=rbd
rbdname=bully_image
rw=randread
bs=1M
iodepth=64
# Sem limites, queremos sangue
Ao rodar esses testes simultaneamente, monitore a latência de commit da Vítima.
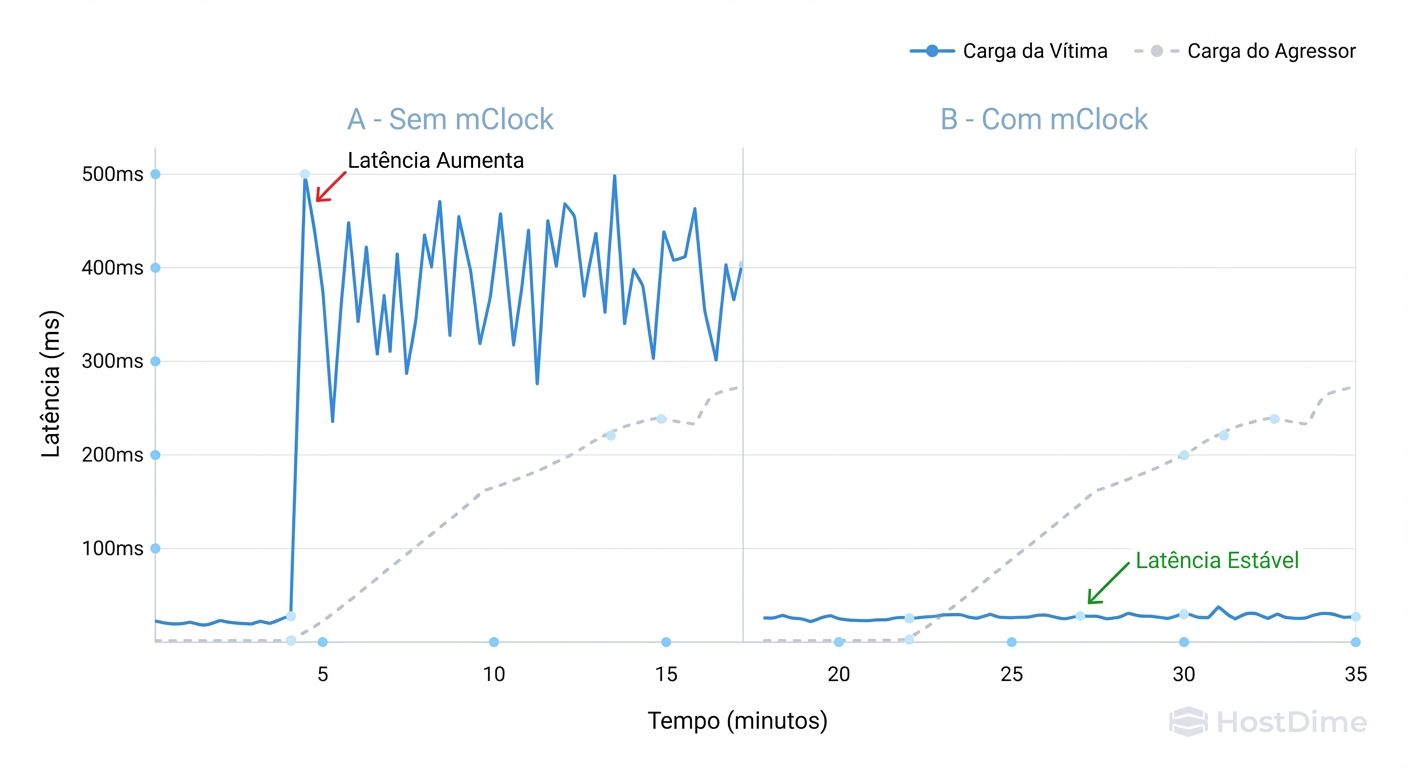 Figura: Evidência de Isolamento: O impacto do algoritmo mClock na estabilidade da latência de uma carga de trabalho sensível quando atacada por um vizinho barulhento.
Figura: Evidência de Isolamento: O impacto do algoritmo mClock na estabilidade da latência de uma carga de trabalho sensível quando atacada por um vizinho barulhento.
A imagem acima deve mostrar o momento exato em que o mClock entra em ação. Observe que, mesmo com o "Bully" tentando consumir 100% dos recursos, a latência da "Vítima" (linha inferior) permanece plana se houver uma reserva configurada. Sem mClock, ambas as linhas oscilariam violentamente.
Onde o QoS Falha: O Fator "Background"
Existe um assassino silencioso de performance no Ceph que o QoS de cliente ignora completamente: Operações de Manutenção.
Scrubbing (verificação de integridade), Recovery (reconstrução após falha de OSD) e Snap Trimming consomem IOPS diretamente no OSD.
No modelo antigo (WPQ), era comum ver o cluster travar quando um OSD voltava online e o recovery começava. O mClock traz uma vantagem tática aqui: ele trata o tráfego de background como apenas mais um "cliente" com seus próprios pesos e reservas.
Entretanto, há um trade-off físico.
Se você prioriza demais o cliente (
high_client_ops), o cluster pode demorar dias para se recuperar de uma falha, ficando em estado degraded (em risco) por muito tempo.Se você prioriza o recovery, seus clientes sentirão a lentidão.
Checklist de Risco de Background:
Verifique
osd_scrub_begin_houreosd_scrub_end_hour. O scrubbing está acontecendo no horário comercial?Se a latência sobe periodicamente sem aumento de carga dos clientes, o culpado provável é o Deep Scrub.
No mClock, ajuste o perfil
osd_mclock_profileparabalancedna maioria dos casos, a menos que você tenha uma SLA de latência zero, ondehigh_client_opsé mandatório (assumindo o risco de recuperação lenta).
Veredito Pragmático: Software vs. Isolamento Físico
Como investigador, minha conclusão sobre o incidente das 3 da manhã raramente é "apenas ligue o QoS". QoS via software (mClock) é excelente para gerenciar a escassez, mas não cria recursos.
Aqui está o guia de decisão para operar no mundo real:
Quando usar QoS de Software (mClock/RBD Limits)?
Ambientes Homogêneos: Todos os clientes são "importantes", mas você quer evitar que um erro de loop infinito derrube o cluster.
Proteção de Cauda: Você quer garantir que o Recovery não mate a produção.
Overprovisioning Controlado: Você vendeu mais IOPS do que tem, mas sabe que nem todos usarão ao mesmo tempo (o modelo ISP).
Quando Segregar Fisicamente (CRUSH Maps)?
Se você tem um cliente que exige latência de <1ms (ex: High Frequency Trading ou Bancos de Dados em tempo real) e outro cliente que faz Big Data:
Não misture. O QoS não vai salvar a latência de acesso à memória cache do disco ou contenção de CPU no OSD.
Crie regras CRUSH diferentes.
Crie um Pool "Gold" rodando apenas em OSDs NVMe.
Crie um Pool "Bronze" rodando em HDDs.
Isole o problema na camada física.
Conclusão Forense: O QoS no Ceph evoluiu de uma "ilusão de limite" no cliente para um "controle de agendamento" robusto no OSD com o mClock. No entanto, ele não substitui a física. Se o disco está cheio, o QoS apenas decide quem chora menos. Meça a latência de cauda, configure suas reservas mínimas e pare de confiar em limites máximos para garantir performance.
Referências & Leitura Complementar
Ceph Documentation - mClock Config: Detalhes oficiais sobre os parâmetros
qos_read_iops_mine perfis de OSD.DmClock Paper (USENIX): "mClock: Handling Throughput Variability for Hypervisor IO Scheduling" – O paper acadêmico que originou o algoritmo usado no Ceph.
RBD Replay: Ferramenta do pacote Ceph para gravar e reproduzir cargas de trabalho reais, útil para validar regras de QoS com dados de produção.

Bruno Azevedo
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.