Ceph RBD Snapshots: O Mito do Backup Simples e o Custo da Extração
Snapshots no Ceph são instantâneos, mas não são backups. Entenda a mecânica do RADOS, os perigos do `rbd export`, o custo de I/O e como garantir consistência real sem corromper bancos de dados.
No mundo do armazenamento distribuído, existe uma armadilha sedutora: a velocidade instantânea de um snapshot. Um administrador executa um comando, o prompt retorna em milissegundos e a sensação de segurança é imediata. "Está salvo", ele pensa. Como Arquiteto de Soluções, meu trabalho é ser o portador das más notícias: persistência local não é Disaster Recovery (DR).
Se o seu cluster Ceph perder o quorum dos monitores ou sofrer uma corrupção catastrófica no pool de dados, seus snapshots morrem junto com os volumes originais. O snapshot reside no mesmo domínio de falha dos dados produtivos. Para transformar um snapshot em backup real, você precisa extraí-lo. E é na extração que a conta da performance chega.
O que é um Ceph RBD Snapshot? Um snapshot RBD (RADOS Block Device) é uma imagem lógica read-only que preserva o estado de um volume em um ponto no tempo usando mecanismos de Copy-on-Write (CoW). Diferente de um backup, que é uma cópia independente e isolada em outro domínio de falha, o snapshot depende da integridade dos objetos originais no cluster RADOS para existir e ser restaurado.
Anatomia do RADOS: O que acontece durante um Snapshot Ceph
Para entender o custo, precisamos descer ao nível do objeto. O Ceph não "copia" o seu disco de 1TB quando você cria um snapshot. Se fizesse isso, o cluster pararia.
O RBD divide sua imagem de bloco em objetos menores (geralmente 4MB) distribuídos pelo cluster via algoritmo CRUSH. Quando você emite um rbd snap create, o Ceph apenas atualiza os metadados do volume. Ele marca a versão atual dos objetos como "imutável" para aquele snapshot.
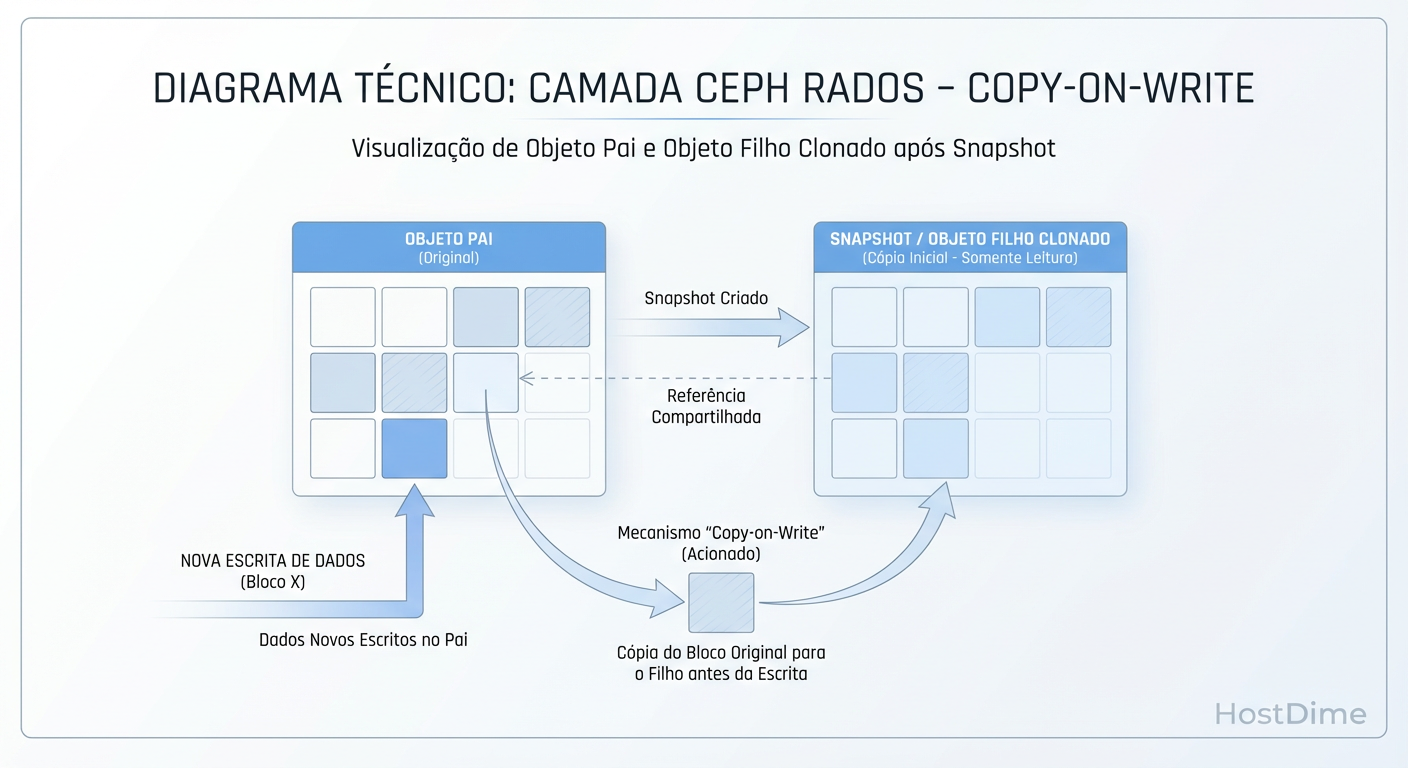 Figura: Mecânica RADOS: O snapshot é apenas metadado até que uma gravação force a clonagem do objeto (CoW).
Figura: Mecânica RADOS: O snapshot é apenas metadado até que uma gravação force a clonagem do objeto (CoW).
O fenômeno real acontece depois, na escrita. O modelo é Copy-on-Write (CoW), mas, sendo purista, no Ceph ele age muitas vezes como um "Redirect-on-Write" lógico dependendo da implementação do backend (BlueStore).
Leitura: Se você ler um dado que não mudou, o Ceph lê o objeto original. Custo zero.
Escrita (O Custo): Quando a VM tenta sobrescrever um bloco que tem um snapshot ativo, o Ceph percebe que não pode tocar no objeto original. Ele clona o objeto original (preservando o estado antigo para o snapshot) e permite a escrita em uma nova versão do objeto.
Isso significa que o snapshot é "grátis" na criação, mas cobra "juros" na primeira escrita subsequente (latência de clonagem) e no consumo de espaço ao longo do tempo.
Consistência de Dados no Ceph: Crash vs. Application
Um erro comum em arquiteturas de virtualização (Proxmox, OpenStack) sobre Ceph é confiar cegamente no snapshot do storage sem avisar o sistema operacional convidado (Guest OS).
Se você tirar um snapshot do RBD enquanto um banco de dados (PostgreSQL, MySQL) está com páginas sujas na memória RAM (não comitadas no disco), você tem um Crash-Consistent Snapshot. É o equivalente digital a puxar o cabo de força do servidor. O banco de dados provavelmente vai se recuperar usando o WAL (Write Ahead Log) ao iniciar, mas não há garantias de integridade lógica da transação.
Para ambientes de produção, exigimos Application-Consistent Snapshots. Isso requer orquestração.
O Papel do QEMU Guest Agent
Para garantir consistência, o hypervisor deve instruir a VM a fazer o quiesce (congelamento) do sistema de arquivos antes do snapshot do Ceph.
# Exemplo do fluxo lógico (geralmente automatizado pelo orquestrador):
# 1. Congelar I/O no Guest (via agente)
virsh qemu-agent-command <vm-id> '{"execute":"guest-fsfreeze-freeze"}'
# 2. Criar o Snapshot no Ceph (agora seguro)
rbd snap create pool_vm/vm-100-disk-0@backup_consistente
# 3. Descongelar I/O no Guest
virsh qemu-agent-command <vm-id> '{"execute":"guest-fsfreeze-thaw"}'
Sem o passo 1 e 3, seu backup é uma aposta, não uma estratégia.
O Custo Oculto da Extração rbd export
Aqui reside o principal trade-off de TCO e performance. Para ter um DR real, você precisa tirar os dados do cluster Ceph e levá-los para um armazenamento secundário (fita, S3, outro cluster Ceph, NAS).
O comando rbd export é brutal. Ele lê todos os objetos alocados da imagem e os envia para a saída padrão (stdout).
Se você tem um volume de 2TB com 1TB ocupado e roda um export completo toda noite:
Você gera 1TB de leitura no seu cluster de produção (Read Amplification).
Você satura a rede de backhaul ou public network do Ceph.
Você aumenta a latência das VMs vizinhas devido à contenção de disco nos OSDs.
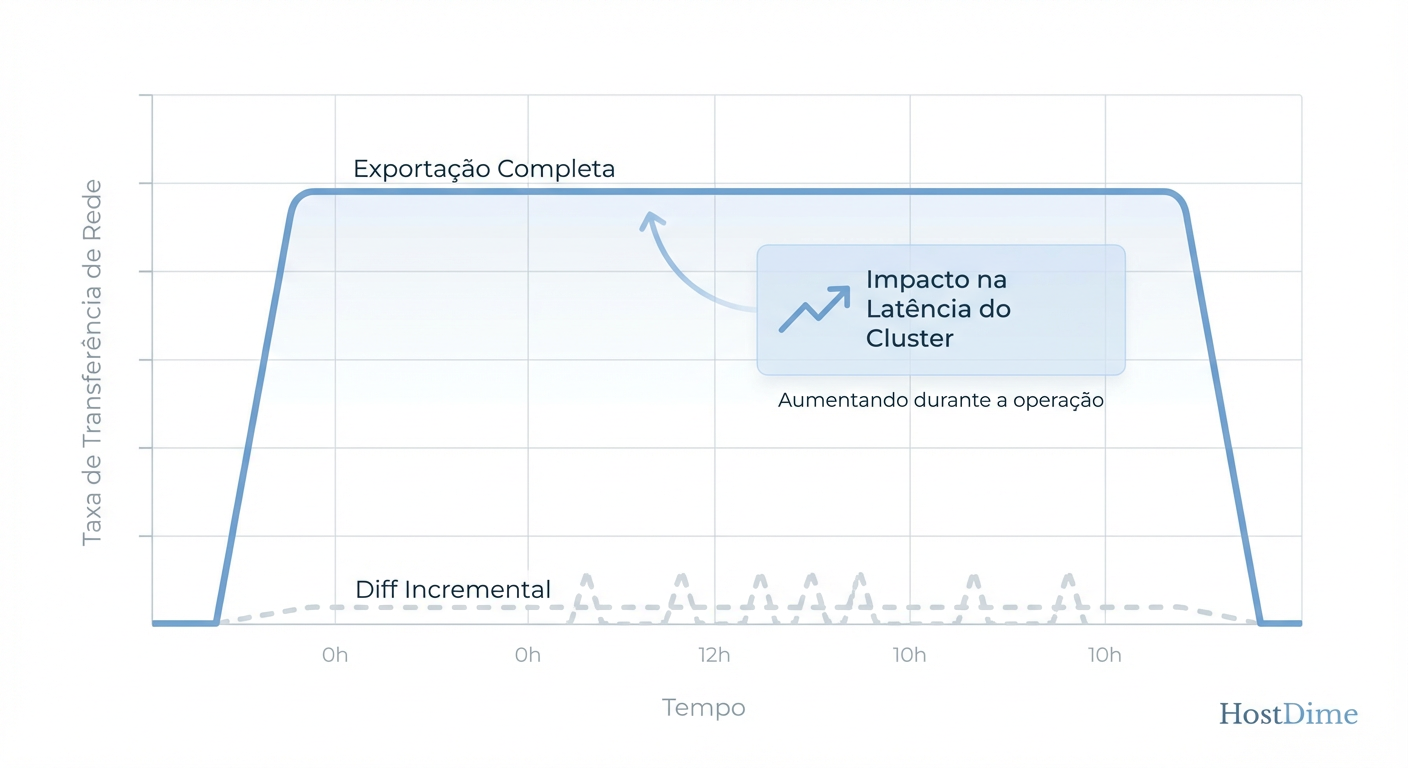 Figura: Impacto na Rede: A diferença brutal de carga entre exportações completas e diferenciais no Ceph.
Figura: Impacto na Rede: A diferença brutal de carga entre exportações completas e diferenciais no Ceph.
A imagem acima ilustra o impacto na rede. O pico de tráfego durante um "Full Export" compete diretamente com o tráfego de latência sensível das aplicações. Em clusters com rede de 10Gbps não segregada, isso derruba aplicações.
A Matemática do Diferencial: Usando rbd export-diff
A solução para a escalabilidade do backup em Ceph é matemática: extrair apenas o delta. O comando rbd export-diff permite exportar apenas os blocos que mudaram entre dois snapshots ou desde a criação da imagem.
Tabela Comparativa: Full Export vs. Export Diff
| Característica | RBD Export (Full) | RBD Export-Diff (Incremental) |
|---|---|---|
| I/O no Cluster | Lê todo o volume ocupado (Alto Impacto) | Lê apenas objetos modificados (Baixo Impacto) |
| Tempo de Janela | Proporcional ao tamanho total dos dados | Proporcional à taxa de mudança (Churn rate) |
| Complexidade de Restore | Simples (Arquivo único) | Alta (Requer reidratação sequencial dos diffs) |
| Uso de Rede | Massivo | Mínimo |
| RTO (Recovery Time) | Rápido | Lento (se houver muitos diferenciais para aplicar) |
Estratégia de Implementação
Para evitar a reidratação lenta no restore (ter que aplicar o Full + 30 diferenciais diários), a arquitetura recomendada geralmente é o "Synthetic Full" no destino ou o uso de rbd mirror para outro cluster, que faz a sincronização diferencial nativamente.
Se for fazer script manual, o fluxo é:
# 1. Exportar apenas o que mudou desde o snap de ontem
rbd export-diff pool/imagem@hoje --from-snap ontem /mnt/backup/imagem_delta_hoje.diff
# 2. No caso de restore, aplicar na ordem:
# rbd import full_base.img
# rbd import-diff delta_1.diff
# rbd import-diff delta_2.diff
Arquitetura de Retenção e Degradação de Performance
Um erro clássico de operação é tratar o Ceph como uma máquina do tempo infinita, mantendo centenas de snapshots antigos "por segurança".
Snapshots órfãos degradam a performance de leitura.
Lembra-se da clonagem de objetos do RADOS? Se você tem uma cadeia longa de snapshots e o objeto foi modificado muitas vezes, o Ceph pode ter que percorrer metadados complexos para determinar qual versão do objeto é a correta para uma determinada leitura, ou gerenciar a fragmentação interna no BlueStore.
Checklist de Saúde de Snapshots
Ao desenhar sua política de retenção, considere:
Limite a profundidade: Evite manter mais de 7-14 snapshots ativos por imagem RBD se o volume tiver alta taxa de escrita (IOPS de escrita aleatória).
Flatten no Clone: Se você criar um clone a partir de um snapshot (ex: para ambiente de Dev/Test), execute o
rbd flattenassim que possível. Isso quebra a dependência do snapshot original (pai) e evita penalidades de leitura cruzada.Trim Automático: Implemente scripts que removem snapshots antigos após a confirmação do export para o backup externo.
Veredito Técnico
Snapshots Ceph são ferramentas operacionais excelentes para rollbacks rápidos (ex: antes de um yum update), mas são péssimos substitutos para backup. O arquiteto deve desenhar a solução considerando o custo da extração.
Se o seu RPO (Recovery Point Objective) exige backups a cada hora, fazer rbd export completo é inviável. Você deve usar export-diff ou rbd mirroring. Se a performance de leitura do cluster começar a degradar misteriosamente, verifique a quantidade de snapshots antigos pendurados nos volumes.
No armazenamento distribuído, não existe mágica, apenas gerenciamento eficiente de metadados e blocos.
Referências & Leitura Complementar
Ceph Documentation - RBD Snapshots: Detalhes oficiais sobre a implementação de camadas e clonagem de objetos.
QEMU Guest Agent Protocol: Documentação sobre os comandos
guest-fsfreezepara consistência de aplicação.Sage Weil et al. (2006): "Ceph: A Scalable, High-Performance Distributed File System" - O paper original que define o algoritmo CRUSH e a distribuição de objetos.
RFC 3720 (iSCSI): Para comparação de mecanismos de snapshot em protocolos de bloco tradicionais vs. distribuídos.

Thiago Moreira
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.