Ceph Rbd Vs Cephfs Vs Rgw Diferencas E Usos

O Ceph é uma plataforma unificada, mas a performance muda drasticamente dependendo da interface. **RBD** oferece a menor latência e acesso direto aos OSDs (ideal para VMs e DBs). **CephFS** introduz a complexidade do MDS para garantir POSIX (ideal para arquivos compartilhados). **RGW** adiciona o overhead do protocolo HTTP e indexação de buckets (ideal para S3/Backups). A escolha errada da interface pode destruir a performance do seu cluster, independentemente da velocidade dos discos. --- Muitos administradores tratam o Ceph como uma "caixa preta mágica" onde você joga dados e eles ficam seguros. Embora a parte da segurança dos dados (durabilidade) seja verdadeira, a performance é uma história completamente diferente. A maior confusão que vejo em campo é a escolha da interface errada para o workload errado. Não, você não deve montar um bucket S3 via FUSE para rodar um banco de dados. E não, você não deve usar CephFS se precisa apenas de um disco virtual para uma VM. Para entender isso, precisamos dissecar o **Data Path**: o caminho que o bit percorre desde a aplicação até ser gravado no disco físico. Como discutimos no guia sobre [Block, File e Object Storage](/articles/tipos-de-armazenamento-block-file-object), cada tipo tem sua própria "taxa" de processamento. No Ceph, essa taxa é paga antes de chegar ao layer RADOS. ## A Base de Tudo: RADOS e a Ilusão das Interfaces No fundo, o Ceph não sabe o que é um arquivo, um bloco iSCSI ou um objeto S3. O Ceph só entende **Objetos RADOS**. Toda a mágica acontece no **librados**. RBD, CephFS e RGW são apenas "tradutores" que convertem as chamadas da sua aplicação em operações que o cluster entende. 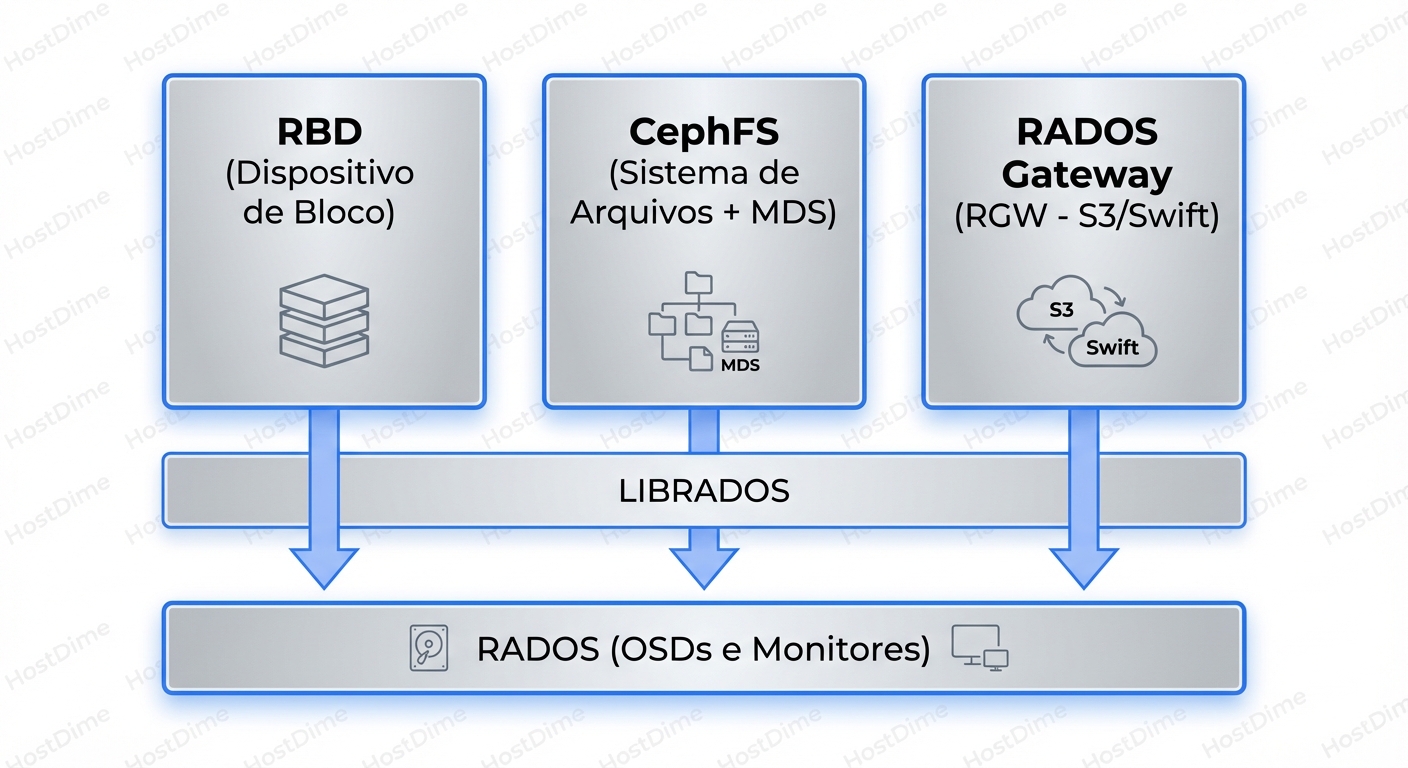 Quando você grava um bloco de 4MB no RBD, ele quebra isso em objetos RADOS. Quando você faz upload de um arquivo no RGW, ele também vira objetos RADOS. A diferença é **como** essa tradução ocorre e quantos "pedágios" (hops de rede e CPU) você paga no caminho. ## 1. RBD (RADOS Block Device): O Caminho Expresso O RBD é, na maioria dos casos, a interface mais performática do Ceph. Por quê? Porque ele é "burro" da maneira certa. O driver do cliente (`librbd`, usado pelo QEMU/KVM, ou o módulo do kernel Linux) faz o trabalho pesado. Ele pega o mapa do cluster (OSD Map), calcula via algoritmo CRUSH exatamente onde os dados devem estar e fala **diretamente com os OSDs**. ### O Data Path do RBD: 1. **Aplicação (ex: VM)** envia write de 4KB. 2. **Librbd** mapeia esse write para um objeto (ex: `rbd_data.1234`). 3. **Librbd** calcula o PG (Placement Group) e os OSDs primários/secundários. 4. **Socket Direto:** O cliente abre conexão TCP direto com o OSD responsável. Não há "servidor de metadados" no meio do caminho para operações de I/O de dados. O overhead é mínimo. **Comandos Práticos:** Para verificar o mapeamento real de um objeto RBD e ver onde ele vive: ```bash rbd ls -l pool_vms/vm-100-disk-0 # Descobrir onde o prefixo do objeto está mapeado ceph osd map pool_vms rbd_data.1025774b0dc51.0000000000000001 ``` **Quando usar:** * Discos de Máquinas Virtuais (Proxmox, OpenStack). * Bancos de dados (via block device montado). * Qualquer cenário onde [IOPS, Throughput e Latência](/articles/iops-throughput-latencia-guia-completo) sejam críticos. ## 2. CephFS: O Custo do POSIX O CephFS é incrível porque é um sistema de arquivos distribuído POSIX-compliant. Isso significa que você pode ter 100 servidores montando a mesma pasta e gravando simultaneamente. Mas a conformidade POSIX custa caro. Para manter a consistência de diretórios, permissões e *locks* de arquivos, o Ceph precisa de um componente extra: o **MDS (Metadata Server)**. ### O Data Path do CephFS: O tráfego é bifurcado (Split-brain architecture): 1. **Metadados (open, ls, chmod):** O cliente fala com o **MDS**. O MDS mantém a árvore de diretórios na RAM (para velocidade) e faz flush para o RADOS. 2. **Dados (read, write):** Uma vez que o cliente sabe onde o arquivo está (graças ao MDS), ele fala **diretamente com os OSDs**, similar ao RBD. **O Gargalo:** Se você tiver milhões de arquivos pequenos, o MDS vira o gargalo. Um `ls -l` em um diretório com 1 milhão de arquivos pode travar sua aplicação, mesmo que seus discos OSD estejam ociosos. **Tuning Crítico:** Você precisa ajustar o cache do MDS e, em clusters grandes, usar *MDS Pinning* para distribuir subárvores de diretórios entre múltiplos MDS ativos. ```bash # Verificar status do MDS e lag ceph fs status # Definir afinidade de cache para diretórios quentes (Pinning) setfattr -n ceph.dir.pin -v 1 /mnt/cephfs/hot_data ``` **Quando usar:** * Pastas compartilhadas (Home directories, Webroot de clusters). * Workloads HPC (High Performance Computing). * Kubernetes RWX (ReadWriteMany) volumes. ## 3. RGW (RADOS Gateway): A Camada Web O RGW é a interface que transforma o Ceph em um "AWS S3 on-premise". Ele é fundamentalmente diferente de RBD e CephFS porque fala HTTP/REST. ### O Data Path do RGW: Aqui o overhead é maior. 1. **Cliente** envia requisição HTTP (PUT/GET). 2. **Load Balancer** (HAProxy/Nginx) recebe e passa para o RGW. 3. **RGW Daemon** processa o HTTP, autentica a request, consulta o **Bucket Index** (metadados do bucket). 4. **RGW** converte o payload em objetos RADOS e envia aos OSDs. Além da latência do protocolo TCP/HTTP, o RGW tem um custo pesado de **Indexação**. Cada bucket mantém um índice (geralmente no RocksDB via OSDs) listando seus objetos. Se você colocar 10 milhões de objetos num único bucket sem *sharding* (fragmentação do índice), a performance de escrita vai despencar. 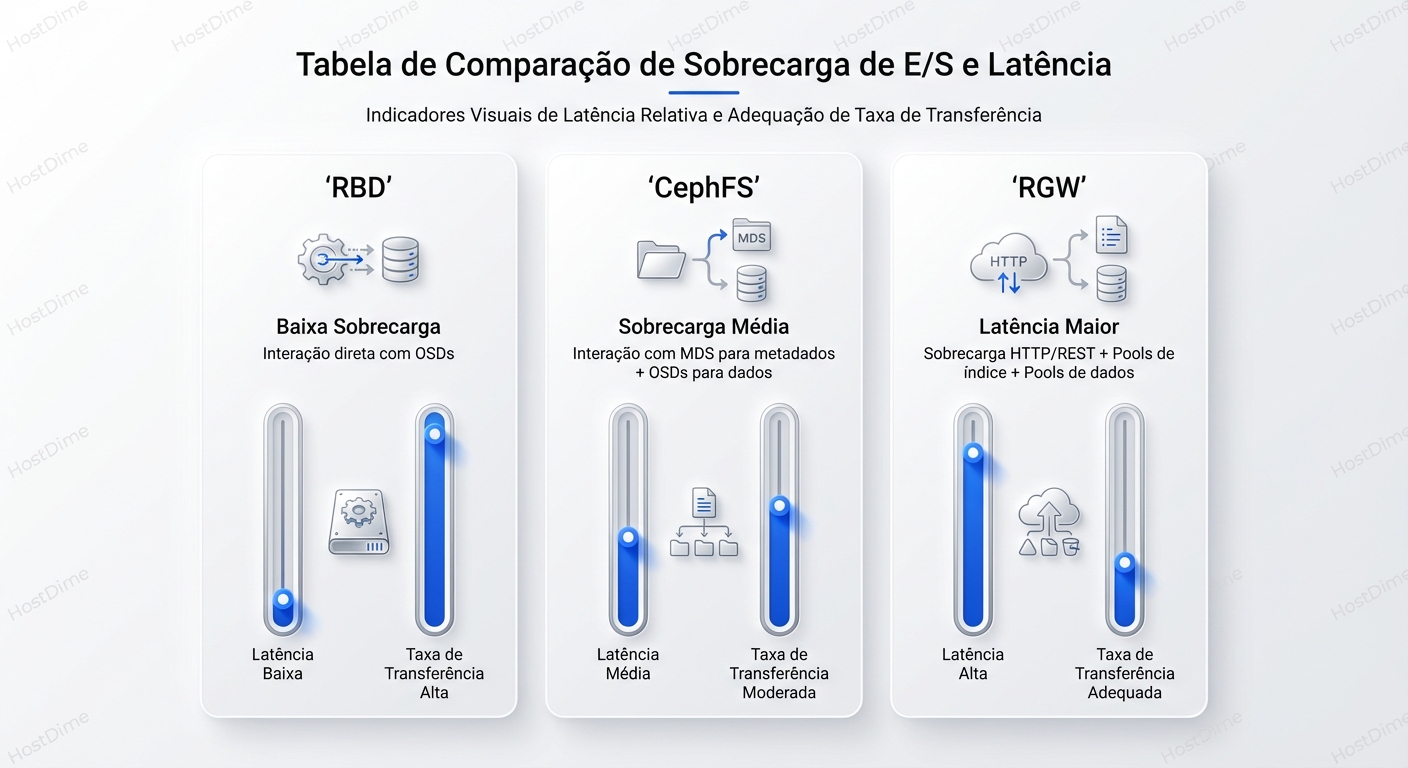 **Estratégia de Backup:** O RGW é o destino clássico para backups. Como discutimos em [Backup Full, Incremental e Diferencial](/articles/backup-full-incremental-e-diferencial-em-storage), ferramentas modernas (Veeam, Kasten, Velero) falam S3 nativamente. O overhead de latência do RGW não importa tanto para throughput de backup, desde que a largura de banda seja alta. **Quando usar:** * Armazenamento de objetos imutáveis (Imagens, PDFs, Logs). * Target de Backup. * Aplicações Cloud-Native. * Federated Storage (Multi-site replication). ## Comparativo Técnico: Overhead e Latência Para decidir a arquitetura, use esta matriz de decisão. Note como o cache do cliente afeta o resultado, um conceito que exploramos em [Read-ahead e Write Buffering](/articles/read-ahead-write-buffering-ajuda-atrapalha). | Característica | RBD (Block) | CephFS (File) | RGW (Object) | | :--- | :--- | :--- | :--- | | **Protocolo** | Nativo Ceph (TCP) | Nativo Ceph (TCP) | HTTP/REST | | **Componente Central** | Librbd (Client-side) | MDS (Metadata Server) | RGW Daemon (Gateway) | | **Latência Típica** | Baixa (< 1-2ms + Network) | Média (Depende do MDS) | Alta (Overhead HTTP) | | **Gargalo Comum** | OSD (Disco/Rede) | CPU/RAM do MDS | CPU do RGW / Bucket Index | | **Cache Client-side** | RBD Cache (RAM do Host) | Kernel Page Cache | Inexistente (Stateless) | | **Ideal para** | IOPS intensivo, Virtualização | Compartilhamento, HPC | Throughput, Web, Archival | ## Veredito: Qual escolher? 1. **Performance Pura (IOPS/Latência):** Use **RBD**. Se você precisa rodar um banco de dados, formate um volume RBD com XFS/Ext4 e monte localmente. Nunca coloque um DB sobre CephFS ou montagens S3 (s3fs/go-ofys), pois a consistência e latência serão terríveis. 2. **Colaboração:** Use **CephFS**. Se múltiplos servidores precisam ler/escrever nos mesmos arquivos simultaneamente, esta é a única opção viável que mantém a sanidade do POSIX. 3. **Escala Infinita e Web:** Use **RGW**. Se a aplicação foi feita para web (GET/PUT), não tente forçá-la a usar arquivos. O RGW escala horizontalmente: precisa de mais performance? Suba mais gateways RGW atrás do Load Balancer. O Ceph é poderoso porque permite misturar esses workloads no mesmo cluster RADOS subjacente. No entanto, isolar pools e definir "Crush Rules" separadas (ex: SSD para RBD, HDD para RGW) é a marca de uma arquitetura madura.
Ceph Rbd Vs Cephfs Vs Rgw Diferencas E Usos
Resumo Executivo (TL;DR): O Ceph é uma plataforma unificada, mas a performance muda drasticamente dependendo da interface. RBD oferece a menor latência e acesso direto aos OSDs (ideal para VMs e DBs). CephFS introduz a complexidade do MDS para garantir POSIX (ideal para arquivos compartilhados). RGW adiciona o overhead do protocolo HTTP e indexação de buckets (ideal para S3/Backups). A escolha errada da interface pode destruir a performance do seu cluster, independentemente da velocidade dos discos.
Muitos administradores tratam o Ceph como uma "caixa preta mágica" onde você joga dados e eles ficam seguros. Embora a parte da segurança dos dados (durabilidade) seja verdadeira, a performance é uma história completamente diferente.
A maior confusão que vejo em campo é a escolha da interface errada para o workload errado. Não, você não deve montar um bucket S3 via FUSE para rodar um banco de dados. E não, você não deve usar CephFS se precisa apenas de um disco virtual para uma VM.
Para entender isso, precisamos dissecar o Data Path: o caminho que o bit percorre desde a aplicação até ser gravado no disco físico. Como discutimos no guia sobre Block, File e Object Storage, cada tipo tem sua própria "taxa" de processamento. No Ceph, essa taxa é paga antes de chegar ao layer RADOS.
A Base de Tudo: RADOS e a Ilusão das Interfaces
No fundo, o Ceph não sabe o que é um arquivo, um bloco iSCSI ou um objeto S3. O Ceph só entende Objetos RADOS.
Toda a mágica acontece no librados. RBD, CephFS e RGW são apenas "tradutores" que convertem as chamadas da sua aplicação em operações que o cluster entende.

Quando você grava um bloco de 4MB no RBD, ele quebra isso em objetos RADOS. Quando você faz upload de um arquivo no RGW, ele também vira objetos RADOS. A diferença é como essa tradução ocorre e quantos "pedágios" (hops de rede e CPU) você paga no caminho.
1. RBD (RADOS Block Device): O Caminho Expresso
O RBD é, na maioria dos casos, a interface mais performática do Ceph. Por quê? Porque ele é "burro" da maneira certa.
O driver do cliente (librbd, usado pelo QEMU/KVM, ou o módulo do kernel Linux) faz o trabalho pesado. Ele pega o mapa do cluster (OSD Map), calcula via algoritmo CRUSH exatamente onde os dados devem estar e fala diretamente com os OSDs.
O Data Path do RBD:
- Aplicação (ex: VM) envia write de 4KB.
- Librbd mapeia esse write para um objeto (ex:
rbd_data.1234). - Librbd calcula o PG (Placement Group) e os OSDs primários/secundários.
- Socket Direto: O cliente abre conexão TCP direto com o OSD responsável.
Não há "servidor de metadados" no meio do caminho para operações de I/O de dados. O overhead é mínimo.
Comandos Práticos: Para verificar o mapeamento real de um objeto RBD e ver onde ele vive:
rbd ls -l pool_vms/vm-100-disk-0
# Descobrir onde o prefixo do objeto está mapeado
ceph osd map pool_vms rbd_data.1025774b0dc51.0000000000000001
Quando usar:
- Discos de Máquinas Virtuais (Proxmox, OpenStack).
- Bancos de dados (via block device montado).
- Qualquer cenário onde IOPS, Throughput e Latência sejam críticos.
2. CephFS: O Custo do POSIX
O CephFS é incrível porque é um sistema de arquivos distribuído POSIX-compliant. Isso significa que você pode ter 100 servidores montando a mesma pasta e gravando simultaneamente. Mas a conformidade POSIX custa caro.
Para manter a consistência de diretórios, permissões e locks de arquivos, o Ceph precisa de um componente extra: o MDS (Metadata Server).
O Data Path do CephFS:
O tráfego é bifurcado (Split-brain architecture):
- Metadados (open, ls, chmod): O cliente fala com o MDS. O MDS mantém a árvore de diretórios na RAM (para velocidade) e faz flush para o RADOS.
- Dados (read, write): Uma vez que o cliente sabe onde o arquivo está (graças ao MDS), ele fala diretamente com os OSDs, similar ao RBD.
O Gargalo:
Se você tiver milhões de arquivos pequenos, o MDS vira o gargalo. Um ls -l em um diretório com 1 milhão de arquivos pode travar sua aplicação, mesmo que seus discos OSD estejam ociosos.
Tuning Crítico: Você precisa ajustar o cache do MDS e, em clusters grandes, usar MDS Pinning para distribuir subárvores de diretórios entre múltiplos MDS ativos.
# Verificar status do MDS e lag
ceph fs status
# Definir afinidade de cache para diretórios quentes (Pinning)
setfattr -n ceph.dir.pin -v 1 /mnt/cephfs/hot_data
Quando usar:
- Pastas compartilhadas (Home directories, Webroot de clusters).
- Workloads HPC (High Performance Computing).
- Kubernetes RWX (ReadWriteMany) volumes.
3. RGW (RADOS Gateway): A Camada Web
O RGW é a interface que transforma o Ceph em um "AWS S3 on-premise". Ele é fundamentalmente diferente de RBD e CephFS porque fala HTTP/REST.
O Data Path do RGW:
Aqui o overhead é maior.
- Cliente envia requisição HTTP (PUT/GET).
- Load Balancer (HAProxy/Nginx) recebe e passa para o RGW.
- RGW Daemon processa o HTTP, autentica a request, consulta o Bucket Index (metadados do bucket).
- RGW converte o payload em objetos RADOS e envia aos OSDs.
Além da latência do protocolo TCP/HTTP, o RGW tem um custo pesado de Indexação. Cada bucket mantém um índice (geralmente no RocksDB via OSDs) listando seus objetos. Se você colocar 10 milhões de objetos num único bucket sem sharding (fragmentação do índice), a performance de escrita vai despencar.

Estratégia de Backup: O RGW é o destino clássico para backups. Como discutimos em Backup Full, Incremental e Diferencial, ferramentas modernas (Veeam, Kasten, Velero) falam S3 nativamente. O overhead de latência do RGW não importa tanto para throughput de backup, desde que a largura de banda seja alta.
Quando usar:
- Armazenamento de objetos imutáveis (Imagens, PDFs, Logs).
- Target de Backup.
- Aplicações Cloud-Native.
- Federated Storage (Multi-site replication).
Comparativo Técnico: Overhead e Latência
Para decidir a arquitetura, use esta matriz de decisão. Note como o cache do cliente afeta o resultado, um conceito que exploramos em Read-ahead e Write Buffering.
| Característica | RBD (Block) | CephFS (File) | RGW (Object) |
|---|---|---|---|
| Protocolo | Nativo Ceph (TCP) | Nativo Ceph (TCP) | HTTP/REST |
| Componente Central | Librbd (Client-side) | MDS (Metadata Server) | RGW Daemon (Gateway) |
| Latência Típica | Baixa (< 1-2ms + Network) | Média (Depende do MDS) | Alta (Overhead HTTP) |
| Gargalo Comum | OSD (Disco/Rede) | CPU/RAM do MDS | CPU do RGW / Bucket Index |
| Cache Client-side | RBD Cache (RAM do Host) | Kernel Page Cache | Inexistente (Stateless) |
| Ideal para | IOPS intensivo, Virtualização | Compartilhamento, HPC | Throughput, Web, Archival |
Veredito: Qual escolher?
- Performance Pura (IOPS/Latência): Use RBD. Se você precisa rodar um banco de dados, formate um volume RBD com XFS/Ext4 e monte localmente. Nunca coloque um DB sobre CephFS ou montagens S3 (s3fs/go-ofys), pois a consistência e latência serão terríveis.
- Colaboração: Use CephFS. Se múltiplos servidores precisam ler/escrever nos mesmos arquivos simultaneamente, esta é a única opção viável que mantém a sanidade do POSIX.
- Escala Infinita e Web: Use RGW. Se a aplicação foi feita para web (GET/PUT), não tente forçá-la a usar arquivos. O RGW escala horizontalmente: precisa de mais performance? Suba mais gateways RGW atrás do Load Balancer.
O Ceph é poderoso porque permite misturar esses workloads no mesmo cluster RADOS subjacente. No entanto, isolar pools e definir "Crush Rules" separadas (ex: SSD para RBD, HDD para RGW) é a marca de uma arquitetura madura.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.