Ceph Recovery e Rebalance: Por que a Latência Explode e Como Controlar
Entenda a física do Ceph Recovery e Backfill. Descubra por que falhas de OSD geram tempestades de I/O e aprenda a ajustar o mClock e throttles para proteger a latência de produção.
A promessa do Software-Defined Storage (SDS) é sedutora: "O hardware falha, o software cura". E, de fato, o Ceph cumpre essa promessa de forma espetacular. Um disco morre, o cluster percebe e começa a reconstruir os dados automaticamente. Mas há um asterisco gigante nesse contrato que raramente aparece nos slides de venda: a física não perdoa.
Quando seu cluster Ceph entra em modo de recuperação (recovery) ou rebalanceamento, ele não cria recursos do nada. Ele "rouba" IOPS, largura de banda e ciclos de CPU que, até um segundo atrás, pertenciam à sua aplicação de produção. O resultado? O disco foi salvo, mas o banco de dados da aplicação está com latência de 500ms e seus usuários estão abrindo chamados.
Neste artigo, vamos desmontar a "mágica" do self-healing, entender onde a latência nasce e, o mais importante, como configurar o Ceph para que a cura não seja pior que a doença.
O QUE É LATÊNCIA DE RECOVERY NO CEPH?
A latência de recovery ocorre quando as operações de background do Ceph (reconstrução de réplicas perdidas ou rebalanceamento de dados) competem por recursos de I/O limitados com as operações do cliente (front-end). Como o Ceph prioriza a integridade dos dados, o tráfego de recuperação pode saturar os discos e as filas de OSD, causando picos de latência ("stall") na aplicação até que o fluxo seja controlado via QoS (mClock) ou limitação manual de backfill.
O Custo Oculto do Self-Healing no Ceph
Para operar o Ceph corretamente, você precisa abandonar a ideia de que o armazenamento é um balde passivo. O Ceph é um sistema distribuído ativo. Cada OSD (Object Storage Daemon) é um pequeno servidor com sua própria inteligência, memória e fila de tarefas.
O erro fundamental de arquitetura é dimensionar o cluster pensando apenas na carga de trabalho nominal (Steady State). Se o seu cluster precisa entregar 10.000 IOPS e seus discos entregam exatamente 10.000 IOPS, você desenhou um sistema que falhará na primeira manutenção.
Quando um OSD falha, o cluster precisa ler os dados dos OSDs sobreviventes e gravá-los em novos locais para restaurar a redundância (fator de replicação). Isso gera uma amplificação de leitura e escrita. O mesmo disco que está tentando servir o seu cliente agora precisa ler terabytes de dados para enviá-los a um vizinho. Se não houver "headroom" (folga) de IOPS, a fila do disco enche, e a latência explode.
Anatomia da Falha: Peering, Recovery e Backfill
Muitos administradores usam os termos de recuperação de forma intercambiável, mas entender a distinção é vital para saber quando o cluster vai travar. O Ceph passa por fases distintas após uma falha.
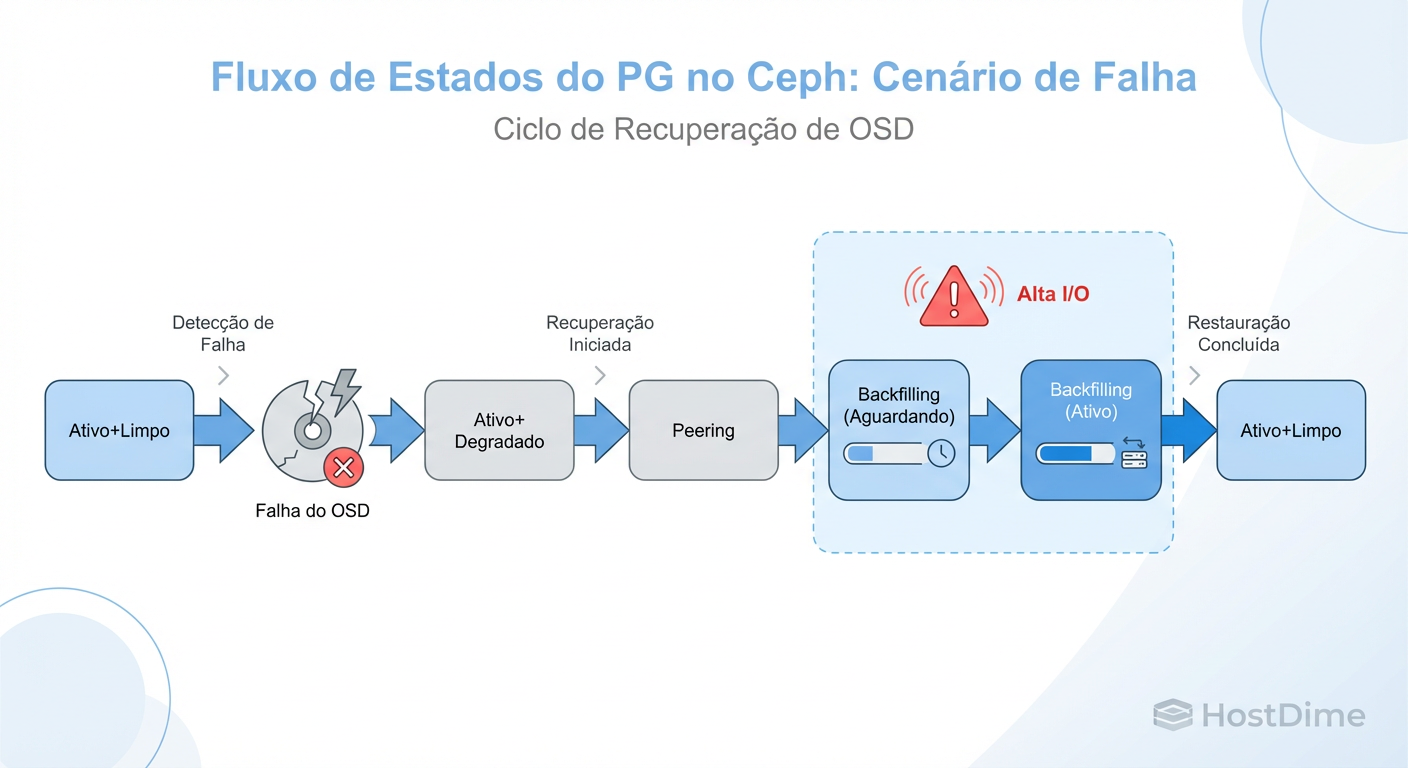 Figura: Fluxo de Estados do PG no Ceph: Onde a latência acontece.
Figura: Fluxo de Estados do PG no Ceph: Onde a latência acontece.
1. Peering (O Bloqueio Silencioso)
Antes de mover um único byte de dados, os OSDs precisam concordar sobre o estado do mundo.
O que acontece: Os OSDs trocam metadados (PG Logs) para saber quais objetos estão atualizados e quais estão faltando.
Impacto: Durante o peering, o I/O para os Placement Groups (PGs) afetados é bloqueado. Se o peering demorar (devido a logs gigantes ou CPU lenta), sua aplicação para.
Sintoma: I/O cai a zero, latência vai ao infinito momentaneamente.
2. Recovery (A Cirurgia de Precisão)
Ocorre quando há apenas uma divergência pequena. Por exemplo, um OSD reiniciou e ficou fora por 5 minutos.
O que acontece: O Ceph reenvia apenas as operações de escrita perdidas durante a queda.
Impacto: Alto uso de CPU para replay de logs, mas geralmente rápido.
3. Backfill (A Carga Pesada)
É aqui que os problemas de performance começam de verdade. Ocorre quando um novo OSD é adicionado ou um OSD antigo é declarado permanentemente morto.
O que acontece: O Ceph copia PGs inteiros de um lugar para outro. É uma cópia bruta de dados.
Impacto: Saturação massiva de rede e disco. É um processo longo (horas ou dias) que compete diretamente com a produção.
Por que o Rebalanceamento Derruba a Performance
O problema não é apenas a quantidade de dados, mas a natureza aleatória do I/O no Ceph.
Imagine um cenário clássico: você adiciona um novo nó ao cluster para aumentar a capacidade. O algoritmo CRUSH recalcula a distribuição e decide que 10% dos dados devem se mover para o novo nó. Imediatamente, todos os OSDs existentes começam a ler dados aleatórios (porque os objetos estão espalhados) para enviar ao novo nó.
Se você usa HDDs (spinning rust), isso é mortal. O seek time (tempo de busca) dos HDDs é o recurso mais escasso. O backfill força os cabeçotes dos discos a dançarem freneticamente entre ler dados do cliente e ler dados para migração. O resultado é que o throughput efetivo do disco cai drasticamente, e as filas de operação do OSD (OpQueues) crescem.
Métricas para Diagnosticar Saturação e Filas
Não culpe a rede sem provas. A maioria dos problemas de latência no Ceph durante o recovery é saturação de disco.
Para confirmar se o recovery está matando sua performance, olhe para as filas.
O que medir no terminal:
Latência do OSD (Commit vs Apply): Use o comando
ceph osd perf.commit_latency: Tempo para persistir no disco (journal/WAL). Se estiver alto, seu disco/SSD está engasgado.apply_latency: Tempo total da transação (incluindo replicação). Se estiver alto, mas o commit estiver baixo, o problema pode ser a rede ou o disco do OSD secundário.
Filas de Disco (Hardware): Vá até o nó Linux e rode
iostat -x 1.- Olhe a coluna
%util. Se estiver colada em 100% nos discos de dados durante um recovery, não adianta mexer em software de rede. Você atingiu o limite físico. - Olhe
avgqu-sz(tamanho médio da fila). Valores altos indicam que o kernel está empilhando pedidos que o disco não consegue atender.
- Olhe a coluna
Filas do Ceph (Software): Verifique o "dump" de performance de um OSD específico:
ceph daemon osd.10 perf dump | grep -A 5 op_w_latencyProcure por métricas de
queue_latency. Isso diz quanto tempo o pedido ficou parado dentro do software Ceph esperando para ser processado.
A Arte do Tuning: mClock vs Flags Legados
Historicamente, controlar o impacto do recovery era um jogo de "adivinhação" usando flags estáticas. Nas versões modernas (Quincy em diante), o Ceph introduziu o algoritmo mClock (MFI Clock) para tentar resolver isso com QoS (Qualidade de Serviço).
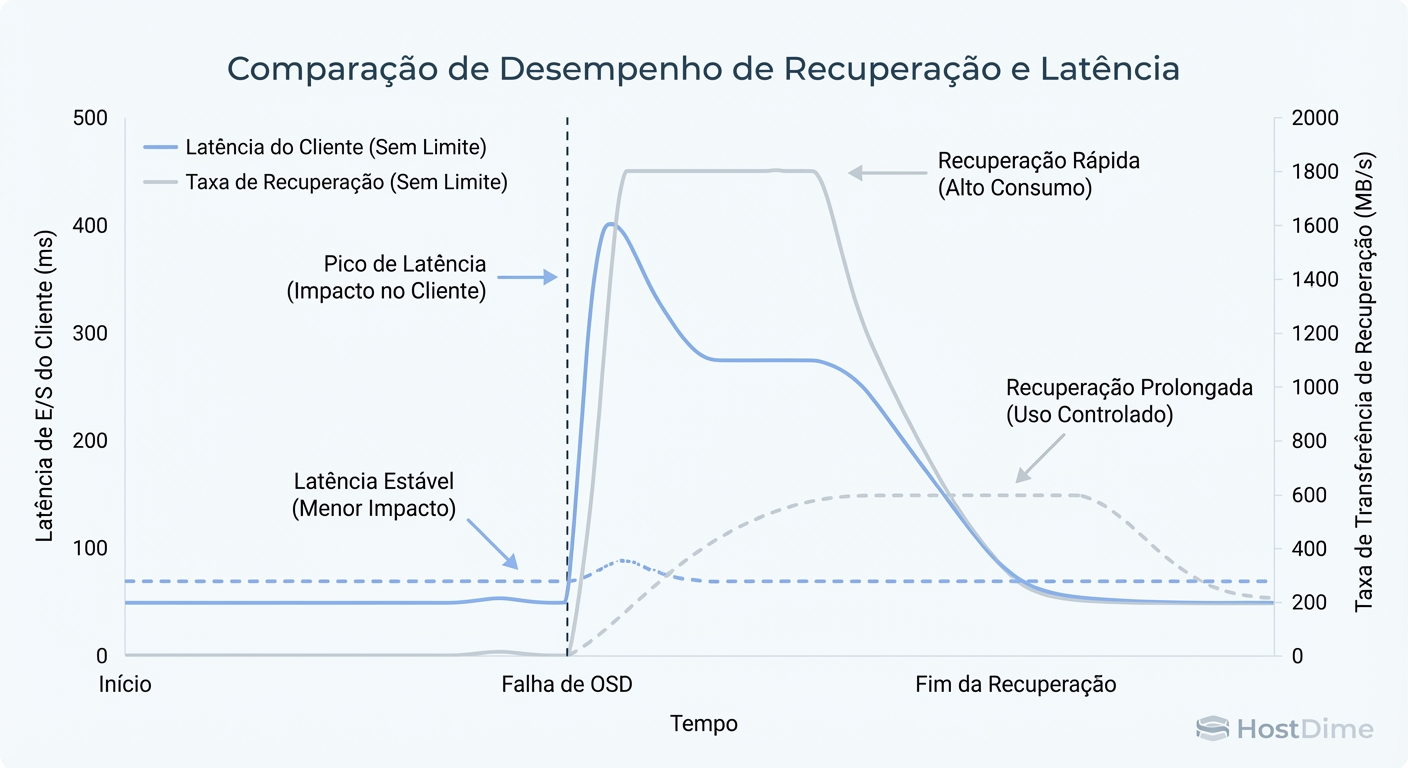 Figura: Trade-off de Tuning no Ceph: Velocidade de Recuperação vs. Latência do Cliente.
Figura: Trade-off de Tuning no Ceph: Velocidade de Recuperação vs. Latência do Cliente.
Comparativo: Abordagem Legada vs. mClock Scheduler
| Característica | Tuning Legado (WeightedPriorityQueue) |
Tuning Moderno (mClockScheduler) |
|---|---|---|
| Mecanismo | Define número máximo de operações simultâneas. | Define reservas (min) e limites (max) de IOPS/Banda. |
| Principal Flag | osd_max_backfills (Padrão: 1) |
osd_mclock_profile (high_client_ops, balanced, high_recovery_ops) |
| Comportamento | Estático. Se definido como 1, o recovery é lento mesmo com cluster ocioso. | Dinâmico. Acelera o recovery se o cliente não estiver usando o cluster. |
| Risco | Se muito baixo: recovery demora semanas (risco de dados). Se muito alto: clientes travam. | Complexidade de configuração se sair dos perfis padrão. |
| Caso de Uso | Clusters antigos ou hardware muito heterogêneo/imprevisível. | Padrão recomendado para clusters modernos (BlueStore). |
Estratégia Prática
Se você está em versões antigas (pré-Quincy) ou não usa mClock:
O parâmetro mais crítico é o osd_max_backfills.
Valor Padrão (1): Conservador. Seguro para HDDs.
O Perigo: Muitos administradores aumentam para 10 ou 20 para "acelerar o rebuild". Isso inunda a fila de operações.
Recomendação: Mantenha em 1 para HDDs. Para SSDs/NVMe, você pode testar 2 ou 4, mas monitore a latência do cliente (
ceph -w).Dica de Ouro: Use também
osd_recovery_sleep. Isso força o OSD a "dormir" por X segundos entre operações de recovery, dando um respiro para o I/O de produção.
Se você usa mClock (Recomendado):
Configure o perfil high_client_ops se sua prioridade absoluta for a latência do usuário.
ceph config set osd osd_mclock_profile high_client_ops
Isso garante que o recovery só use os recursos que sobrarem ("best effort"), mas respeitando um piso mínimo para que a recuperação não pare totalmente.
Estratégia de Capacidade: Quanto 'Headroom' Você Realmente Precisa?
O maior erro de TCO (Custo Total de Propriedade) no Ceph é calcular a capacidade baseada no espaço em disco "bruto" utilizável até 100%.
O Ceph para de escrever quando o disco atinge o full_ratio (padrão 95%), mas começa a reclamar e alterar comportamentos de backfill muito antes, no backfill_full_ratio (padrão 90%) e nearfull_ratio (padrão 85%).
A Regra do N+1 (ou N+2)
Se você tem um cluster com 10 nós e 1 nó falha, os dados desse nó precisam ser redistribuídos nos 9 restantes.
Se os seus 9 nós restantes já estavam 80% cheios, receber a carga do nó morto vai empurrá-los para perto de 90%.
Nesse ponto, o Ceph pode bloquear o backfill para proteger os discos de encherem, deixando seu cluster em estado degradado permanentemente até você adicionar hardware.
Veredito Arquitetural: Você deve projetar seu cluster para operar, no máximo, a 65-70% de ocupação em estado normal. Esse "desperdício" de 30% é, na verdade, o seu seguro de vida. É o espaço necessário para absorver o conteúdo de um nó falho e permitir que o rebalanceamento ocorra sem travar o I/O por falta de espaço contíguo.
Veredito Técnico
Controlar a latência de recovery no Ceph não é sobre encontrar um "comando mágico", mas sim sobre gerenciar física e filas. O self-healing é uma funcionalidade incrível, mas gera uma carga de trabalho brutal.
Meça antes de tunar: Use
ceph osd perfeiostat. Se o disco está saturado, aumentar filas de software só consome mais RAM.Prefira mClock: Se sua versão permite, use o agendador moderno. Ele gerencia os trade-offs melhor que scripts manuais.
Respeite o Headroom: Espaço livre é performance. Um cluster cheio é um cluster lento e frágil.
O Ceph vai recuperar seus dados. A sua função é garantir que a sua empresa continue operando enquanto ele faz isso.
Referências & Leitura Complementar
Ceph Documentation: mClock Config Reference & QoS Studies (docs.ceph.com).
Paper Acadêmico: CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data (Weil et al., SC '06) - Para entender a matemática da distribuição.
Red Hat Storage: Performance Tuning Guide for Ceph BlueStore.
RFC 8881: Network File System (NFS) Version 4 Minor Version 2 Protocol (Contexto sobre latência em protocolos de arquivo sobre Ceph).

Felipe Guimarães
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.