Ceph Replica vs Erasure Coding: O Preço da Latência na Economia de Disco
Economizar 50% de armazenamento com Erasure Coding no Ceph pode custar caro em latência e CPU. Analisamos o trade-off real entre Replica 3x e EC (k+m) para Block Storage e Object.
Esta é uma análise de engenharia, não um panfleto de vendas. Vamos ignorar o marketing de "armazenamento infinito e barato" e olhar para o que acontece nos registradores da CPU e nos pratos do disco quando você toma uma decisão arquitetural no Ceph.
A escolha entre Replica (Replication) e Erasure Coding (EC) é frequentemente tratada como uma decisão financeira (OpEx/CapEx). Isso é um erro. É uma decisão de física e matemática que define se sua infraestrutura vai operar suavemente ou se vai travar sob carga de IOPS aleatórios.
O Dilema Replica vs Erasure Coding no Ceph
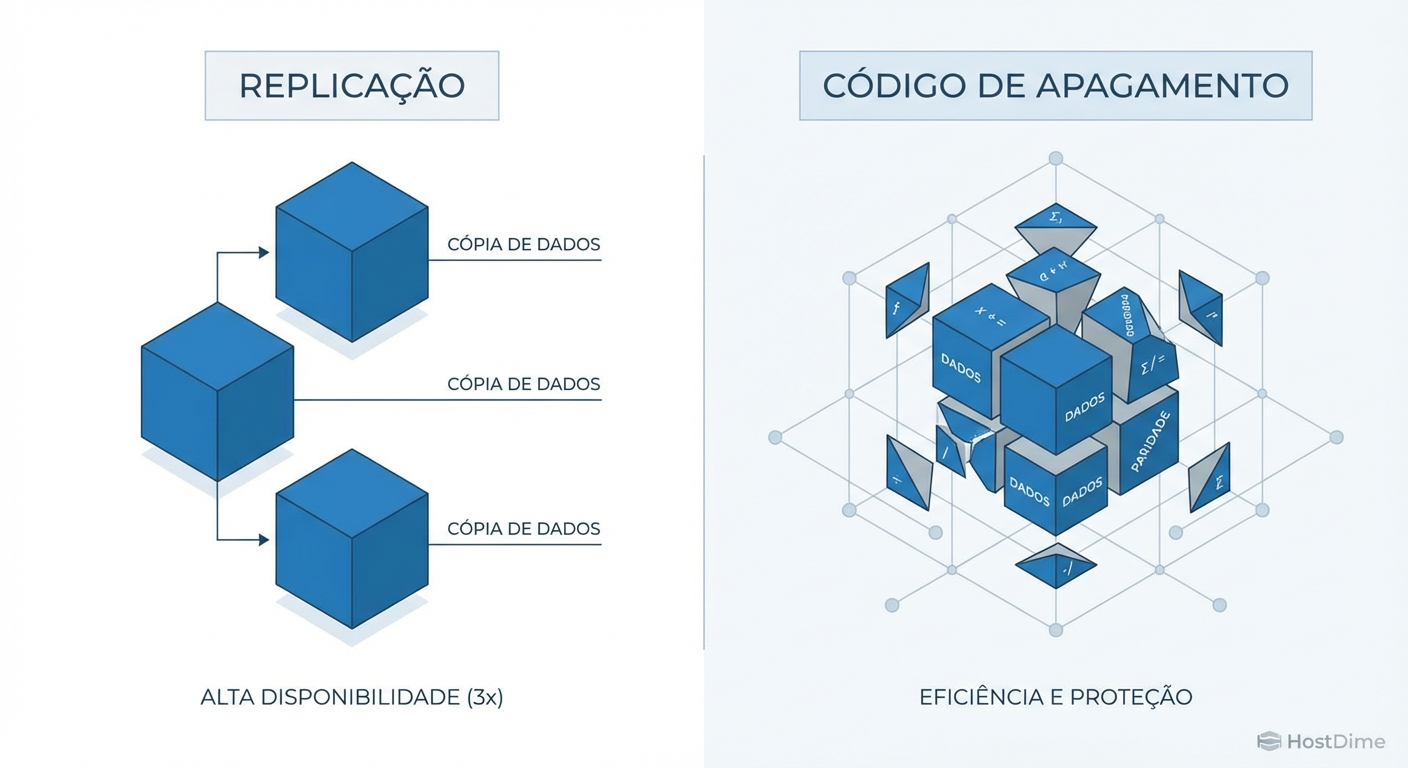
No Ceph, a Replicação (geralmente 3x) prioriza a performance e a segurança ao manter cópias completas dos dados, resultando em baixa latência de escrita e recuperação simples, ideal para RBD e VMs. O Erasure Coding (EC) prioriza a densidade de armazenamento dividindo dados em fragmentos (k) mais paridade (m), oferecendo 66%+ de eficiência, mas introduzindo alta latência de CPU e penalidades severas em escritas pequenas (RMW), sendo indicado para RGW e Object Storage.
A Ilusão do Custo por Gigabyte e a Realidade do Raw vs Usable
O canto da sereia do Erasure Coding é a eficiência. Num pool Replica 3x, você compra 1 PB de disco para ter 333 TB de espaço utilizável. A eficiência é de 33%. Isso dói no orçamento.
No Erasure Coding, digamos um perfil 4+2 (divide o objeto em 4 pedaços de dados e calcula 2 de paridade), você tem 66% de eficiência. De repente, aquele mesmo 1 PB entrega 666 TB utilizáveis. O CFO adora essa matemática.
Porém, em engenharia de performance, não existe almoço grátis. O custo que você economizou em hardware (discos) foi transferido para computação (ciclos de CPU) e tempo (latência). A pergunta que você deve fazer não é "quanto espaço eu ganho?", mas sim "quanto tempo eu posso esperar por uma confirmação de escrita?".
A Matemática do Erasure Coding (k+m) e o Impacto na CPU
Diferente do RAID tradicional que usa XOR simples, o Ceph usa o algoritmo Reed-Solomon para EC. Quando um dado chega para ser escrito num pool EC, o processador não apenas "passa o dado adiante".
O dado é fatiado em
kchunks.A CPU deve resolver equações polinomiais para gerar
mchunks de paridade.Esses
k+mpedaços são distribuídos pela rede para OSDs diferentes.
Isso transforma uma operação de I/O em uma operação intensiva de CPU. Se seus nós OSD têm CPUs modestas (comuns em storage nodes focados em densidade), você verá o wait time subir. O gargalo sai do disco e vai para o silício do processador. Para cold data (backups, arquivos mortos), isso é irrelevante. Para uma base de dados transacional, é suicídio.
O Pesadelo do Read-Modify-Write no Ceph Erasure Coding
Aqui é onde a maioria dos projetos falha. O Ceph, rodando sobre BlueStore, lida com objetos. Se você usa EC para armazenar objetos grandes (ex: vídeos de 1GB no RGW), o EC funciona maravilhosamente bem: ele escreve faixas completas (full stripes).
O problema surge quando você tenta rodar Block Storage (RBD) — como discos virtuais de VMs — sobre um pool EC. Sistemas operacionais e bancos de dados adoram fazer escritas pequenas (4k, 8k).
Em um pool Replica, uma escrita de 4k é apenas uma gravação de 4k (vezes 3). Em um pool EC, uma escrita de 4k (que é menor que o tamanho da faixa completa do EC) dispara o temido ciclo Read-Modify-Write:
Read: O Ceph precisa ler os dados vizinhos e a paridade antiga do disco.
Modify: Ele recalcula a nova paridade com base na diferença.
Write: Ele grava os novos dados e a nova paridade.
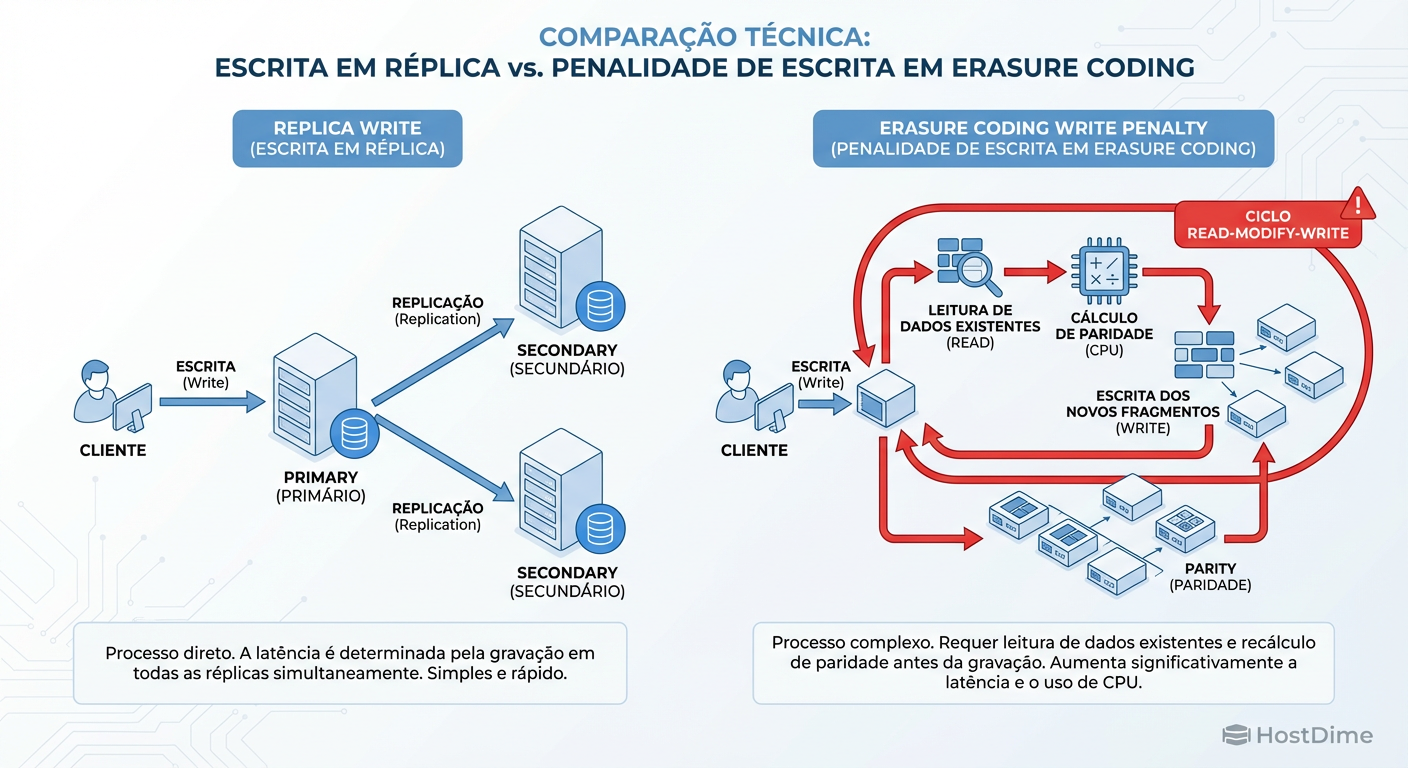 Figura: O ciclo Read-Modify-Write no Ceph Erasure Coding: onde sua latência vai para morrer em escritas parciais.
Figura: O ciclo Read-Modify-Write no Ceph Erasure Coding: onde sua latência vai para morrer em escritas parciais.
O resultado é uma amplificação de escrita brutal. Uma operação que deveria levar milissegundos pode triplicar sua latência, pois depende de leituras de rede prévias antes de poder persistir o dado.
BlueStore e Overwrites: A Granularidade de Alocação
O backend de armazenamento do Ceph, o BlueStore, escreve diretamente no dispositivo raw. No entanto, ele tem uma regra de alocação mínima (min_alloc_size).
Em pools baseados em HDD com Erasure Coding, o BlueStore historicamente precisava fazer deferred writes (usando o RocksDB como um buffer WAL) para lidar com overwrites parciais, ou alocar blocos maiores do que o necessário.
Se o seu min_alloc_size for 64KB (padrão antigo para HDD) e você gravar arquivos de 4KB num pool EC, você está ocupando 64KB fisicamente. Sua eficiência teórica de 66% despenca porque você está guardando "ar" (zeros) no disco. Embora versões recentes do Ceph (Pacific/Quincy) tenham otimizado isso, o trade-off de fragmentação e latência em overwrites permanece uma barreira física para workloads dinâmicos.
Recuperação e Rebalanceamento na Rede
A falha de um disco é inevitável. A diferença está em como a rede sente essa falha.
Replica: Se um disco morre, o Ceph pega a cópia exata que está em outro nó e a copia para um novo local. É um fluxo 1:1. Simples, previsível.
Erasure Coding: Se um pedaço do dado morre, o dado não existe em lugar nenhum. Ele precisa ser reconstruído matematicamente. O OSD primário precisa contatar
koutros OSDs, puxar todos os fragmentos restantes pela rede, recalcular o pedaço perdido na CPU e então gravá-lo.
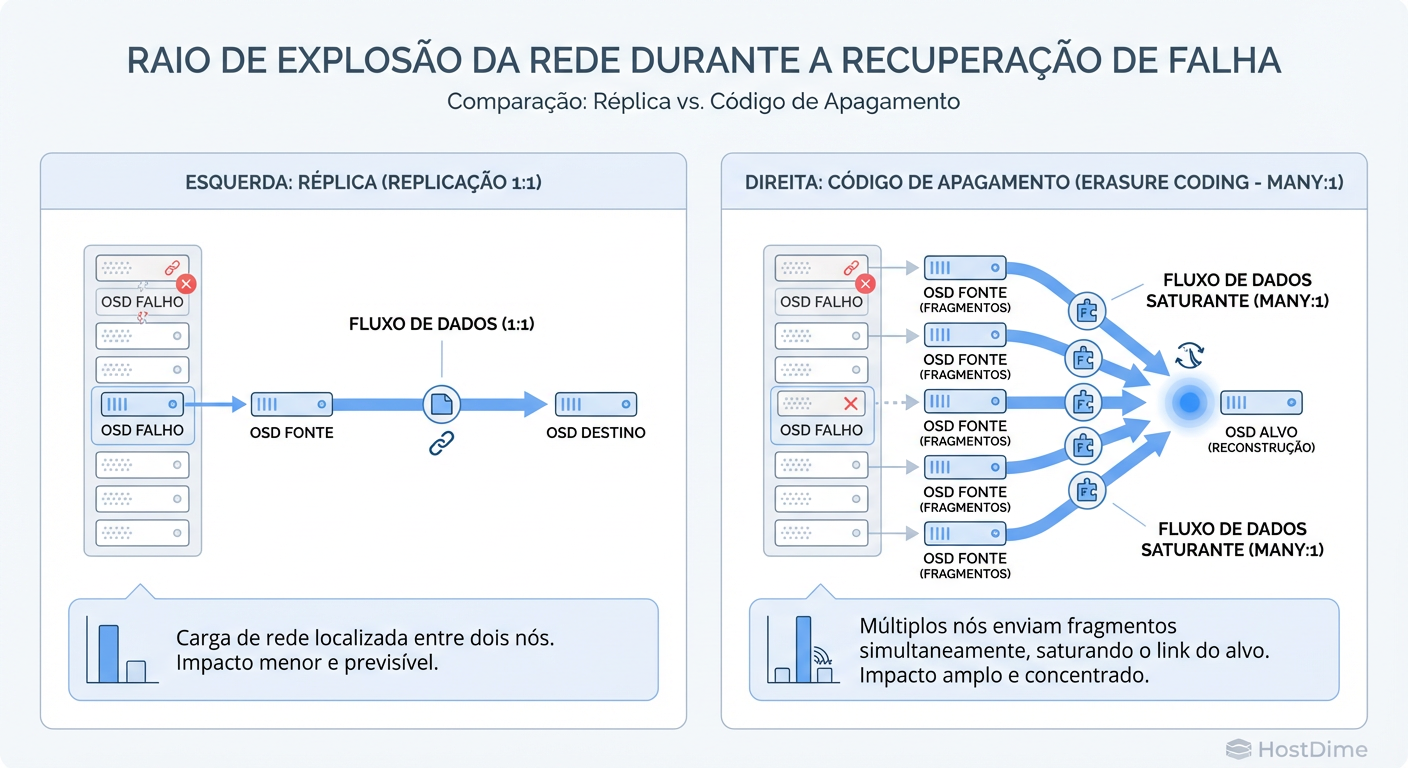 Figura: Impacto na rede durante recuperação: Replica (cópia simples) vs Erasure Coding (reconstrução distribuída).
Figura: Impacto na rede durante recuperação: Replica (cópia simples) vs Erasure Coding (reconstrução distribuída).
Isso gera um evento de "Incast" na rede (muitos para um). Durante uma recuperação de EC, sua rede de cluster (cluster network) sofre uma pressão massiva, o que pode degradar a performance dos clientes que ainda estão tentando ler/escrever dados saudáveis.
Comparativo Técnico: Replica vs Erasure Coding
| Característica | Replica (3x) | Erasure Coding (4+2) | O Veredito |
|---|---|---|---|
| Eficiência de Espaço | 33% (1TB Raw = 333GB Usable) | 66% (1TB Raw = 666GB Usable) | EC vence em custo/GB. |
| Latência de Escrita | Baixa (Network round-trip) | Alta (Cálculo CPU + RMW) | Replica é obrigatório para performance. |
| Custo de CPU | Baixo | Alto (Cálculo de Polinômios) | Replica economiza computação. |
| Risco de Recuperação | Baixo (Cópia 1:1) | Alto (Tráfego N:1 + CPU Load) | Replica é mais seguro em redes congestionadas. |
| Overhead de Small Writes | Mínimo | Crítico (Read-Modify-Write) | EC é proibitivo para DBs e VMs. |
Benchmark e Evidência: O que medir
Não confie na documentação. Valide com fio ou rbd bench. Ao testar um pool EC versus Replica, ignore o throughput máximo (MB/s). O throughput é fácil de saturar com I/O sequencial. O que mata aplicações é a latência em cauda (Tail Latency).
O Teste de Verdade
Você deve procurar por:
IOPS em Random Write 4k: O pior cenário.
Latência de 99th Percentile (clat): Onde os soluços acontecem.
CPU Wait/System Time: Durante o teste, observe o
topoumpstatnos nós OSD.
Exemplo de comando fio para isolar o problema do RMW em EC (execute dentro de uma VM ou montagem RBD):
fio --name=random-write-test \
--ioengine=libaio \
--rw=randwrite \
--bs=4k \
--numjobs=4 \
--size=4G \
--iodepth=32 \
--direct=1 \
--end_fsync=1 \
--filename=/dev/rbd0
Se você rodar isso num pool EC, verá os IOPS despencarem e a latência subir para centenas de milissegundos comparado ao pool Replica.
Veredito Operacional: Quando usar cada um
Não existe "melhor", existe a ferramenta certa para o trabalho. A tentativa de forçar EC em tudo para economizar dinheiro resultará em uma infraestrutura lenta e instável.
Use Replica (3x) Quando:
Workload: Block Storage (RBD), Máquinas Virtuais (Proxmox, OpenStack, VMware), Bancos de Dados (MySQL, PostgreSQL).
Padrão de I/O: Muitas escritas aleatórias, overwrites frequentes, arquivos pequenos.
Prioridade: Latência baixa e recuperação rápida.
Use Erasure Coding Quando:
Workload: Object Storage (RGW/S3), Data Lake, Repositórios de Backup (Veeam, Commvault), Arquivamento de Imagens/Vídeos.
Padrão de I/O: Escritas sequenciais grandes (WORM - Write Once Read Many), dados que raramente mudam.
Prioridade: Custo por Terabyte e densidade máxima.
Nota final: Se você precisa usar EC para Block Storage (por restrição orçamentária extrema), a única saída viável é usar um Cache Tiering com Replica na frente do EC, ou garantir que o hardware subjacente seja 100% NVMe com CPUs de altíssima performance para mitigar o custo matemático. Caso contrário, fique com a Replica. O disco é barato; a paciência do seu usuário não.
Referências & Leitura Complementar
Ceph Documentation: "Erasure Code Profiles & Overhead" - Análise oficial sobre os algoritmos K+M.
James S. Plank: "A Tutorial on Reed-Solomon Coding for Fault-Tolerance in RAID-like Systems" - A matemática por trás do EC.
Ceph BlueStore Performance: Whitepapers detalhando o impacto de
min_alloc_sizeem pools EC.RFC 9000 (QUIC): Relevante para entender como a latência de rede impacta sistemas distribuídos modernos (conceitual).

Rafael Pacheco
Arquiteto de Cloud Infrastructure
Focado em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.