Ceph: SSD SATA vs NVMe e o Custo Oculto da Latência Mista
Misturar SSD SATA e NVMe no mesmo pool do Ceph cria gargalos invisíveis. Entenda a diferença de protocolos (AHCI vs PCIe), o impacto na latência de cauda e como arquitetar corretamente.
No mundo do armazenamento corporativo, o termo "All-Flash" tornou-se uma ferramenta de marketing perigosa. Para muitos gestores de TI, substituir HDDs por SSDs parece ser a bala de prata para problemas de performance. No entanto, ao arquitetar clusters Ceph, tratar todo SSD como igual é um erro que custa caro — não apenas em orçamento, mas em latência de produção.
A realidade é que um cluster Ceph é um sistema distribuído onde a consistência e a durabilidade frequentemente competem com a velocidade bruta. Quando misturamos tecnologias de flash com protocolos diferentes (SATA/AHCI e NVMe) no mesmo domínio de falha ou pool de dados, criamos um cenário de degradação de performance que muitas vezes torna o investimento em NVMe inútil.
O problema central não é a mídia (NAND Flash), é o protocolo e como o Ceph gerencia a escrita.
Definição de Latência Mista em Ceph: A latência mista ocorre quando um Pool de armazenamento distribui réplicas de dados entre dispositivos com capacidades de enfileiramento de I/O díspares (como SATA e NVMe). Como o Ceph prioriza a consistência forte, a latência de gravação (Write Latency) do cluster é nivelada pelo dispositivo mais lento envolvido na transação, anulando os benefícios de velocidade dos dispositivos mais rápidos.
A Ilusão do "All-Flash": O Abismo entre AHCI e NVMe
Para entender por que misturar SSDs SATA e NVMe é problemático, precisamos olhar para baixo do capô, na camada de transporte. O protocolo SATA foi desenhado para discos rotacionais (HDD). Ele utiliza a interface AHCI (Advanced Host Controller Interface).
O AHCI possui uma única fila de comandos (Command Queue) com uma profundidade (Queue Depth) de apenas 32 comandos. Isso era suficiente para HDDs que mal conseguiam lidar com 200 IOPS. Para um SSD moderno, isso é um gargalo severo. O SSD passa mais tempo esperando na fila do controlador do que gravando dados.
Em contrapartida, o NVMe (Non-Volatile Memory Express) foi desenhado nativamente para memória flash. Ele suporta 64.000 filas, cada uma com capacidade para 64.000 comandos.
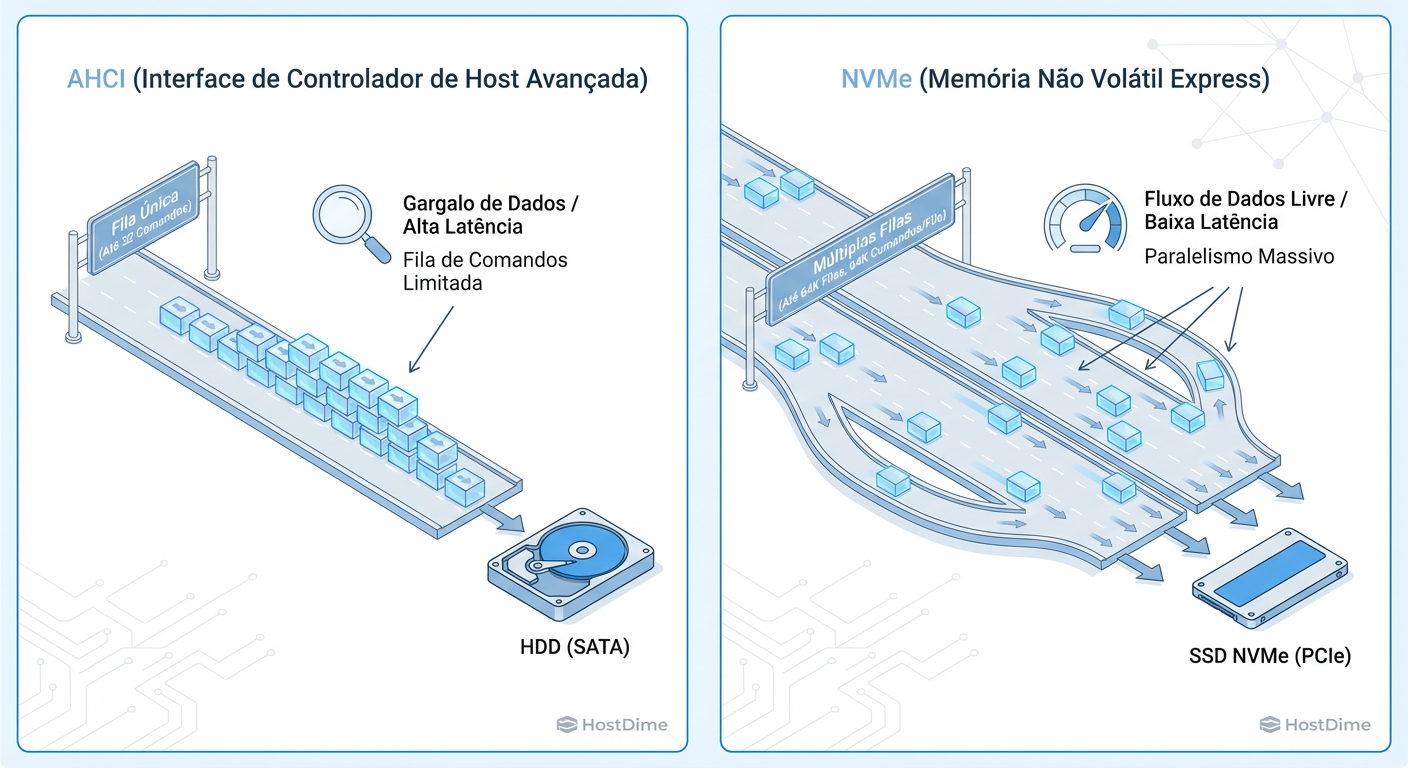 Figura: O gargalo não é apenas a velocidade, é a fila: AHCI (SATA) vs NVMe.
Figura: O gargalo não é apenas a velocidade, é a fila: AHCI (SATA) vs NVMe.
Quando você coloca um SSD SATA ao lado de um NVMe no mesmo servidor Ceph, você não está apenas comparando velocidades de clock; você está comparando uma rodovia de uma pista (SATA) contra uma autoestrada de 64.000 pistas (NVMe). O gargalo do SATA não é apenas a taxa de transferência (throughput), é a latência de submissão e conclusão de I/O.
Tabela Comparativa: O Custo do Protocolo
| Característica | SSD SATA (Enterprise) | NVMe (Enterprise) | Impacto no Ceph |
|---|---|---|---|
| Protocolo | AHCI (Legacy) | NVMe (Nativo) | SATA gera wait time na CPU. |
| Filas de I/O | 1 fila | Até 64k filas | NVMe permite paralelismo massivo do OSD. |
| Profundidade (QD) | 32 cmds | 64k cmds por fila | SATA satura rápido sob carga de rebalance. |
| Latência Típica | ~50-100 µs | ~10-20 µs | NVMe reduz drasticamente o commit do RocksDB. |
| Custo/TB | Baixo/Médio | Médio/Alto | O mix errado desperdiça o custo do NVMe. |
O Mecanismo de Replicação do Ceph: A Regra do Elo Mais Fraco
O Ceph é, por padrão, um sistema de consistência forte (Strong Consistency). Quando uma aplicação envia uma gravação para o cluster, o cliente fala com o OSD Primário. O Primário, então, replica esses dados para os OSDs Secundários e Terciários (assumindo size=3).
O ponto crítico é: O cliente só recebe a confirmação de sucesso (ACK) quando TODAS as réplicas foram gravadas com segurança no disco (journal/WAL).
Se você tem um Pool misto onde o OSD Primário é um NVMe ultrarrápido, mas um dos OSDs Secundários é um SSD SATA ocupado, o NVMe terá que esperar o SATA terminar de escrever para enviar o ACK ao cliente.
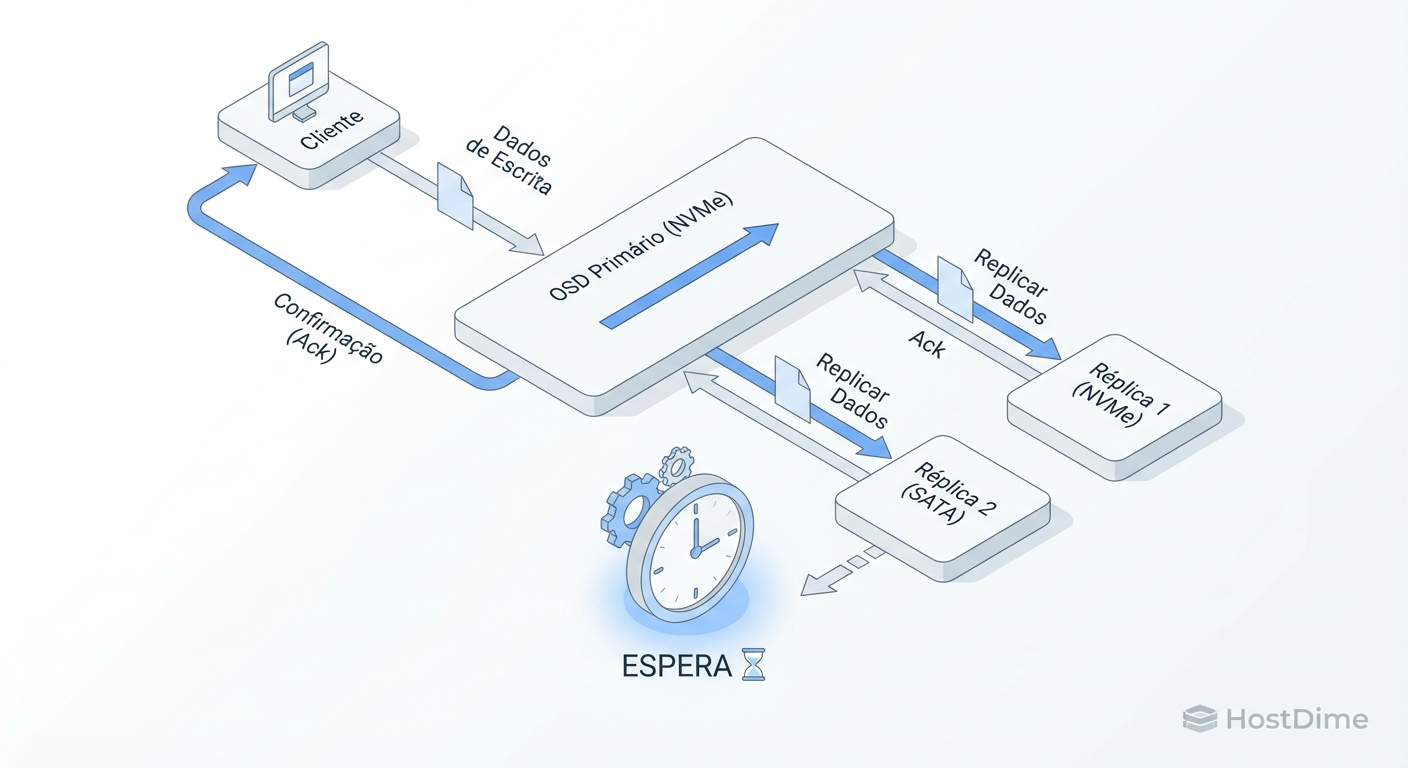 Figura: O Efeito Comboio: O Ceph só confirma a gravação quando o disco mais lento termina.
Figura: O Efeito Comboio: O Ceph só confirma a gravação quando o disco mais lento termina.
Isso cria o que chamamos de "Efeito Comboio". Imagine uma Ferrari e um Fusca viajando juntos, onde a regra é que eles devem cruzar a linha de chegada ao mesmo tempo. A velocidade máxima da Ferrari torna-se irrelevante; ela está limitada à velocidade máxima do Fusca.
Em um ambiente Enterprise, isso significa que você pagou prêmio por NVMe, mas está obtendo performance de SATA (ou pior, devido à contenção de fila).
Latência de Cauda (Tail Latency) em Pools Mistos
A métrica mais enganosa em armazenamento é a "Latência Média". A média esconde os picos que causam timeouts na aplicação. Em arquitetura de soluções, focamos no P99 ou P99.9 (o 1% ou 0.1% das requisições mais lentas).
Em um cluster homogêneo (apenas SATA ou apenas NVMe), a latência é previsível. Em um cluster misto, a latência torna-se estocástica e errática.
Dependendo de como o algoritmo CRUSH distribui os dados (Placement Groups), algumas gravações cairão em um conjunto de 3 OSDs NVMe (rápido), enquanto outras cairão em 2 NVMe + 1 SATA (lento). Isso cria um histograma de latência "bimodal" ou extremamente disperso.
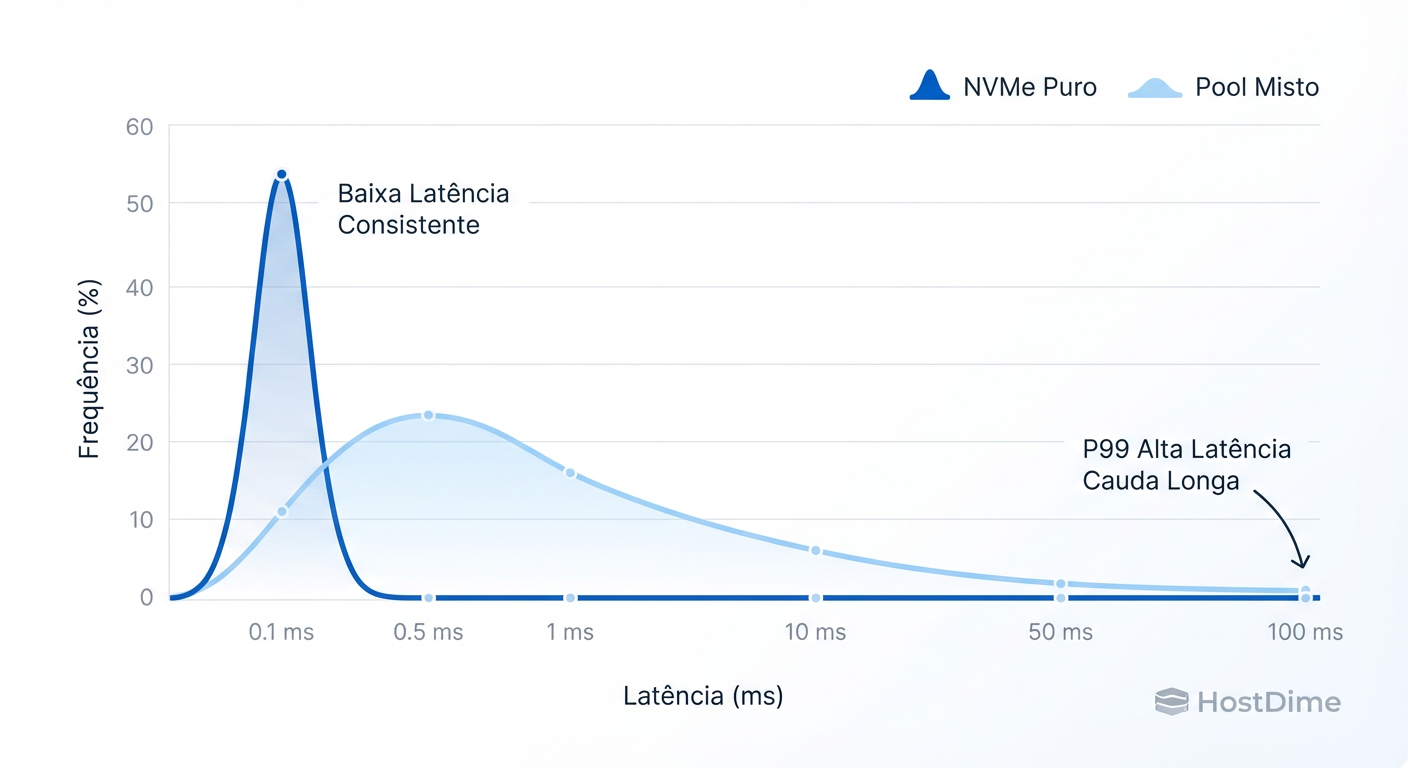 Figura: Média vs P99: Pools mistos destroem a previsibilidade da latência.
Figura: Média vs P99: Pools mistos destroem a previsibilidade da latência.
Para bancos de dados ou virtualização, essa variabilidade é destrutiva. A aplicação percebe "engasgos" aleatórios que são difíceis de depurar, pois não ocorrem em todas as gravações.
O Único Cenário Híbrido Aceitável: NVMe para WAL/DB e SATA para Block
Como Arquiteto, a resposta para "posso misturar?" é geralmente "depende de como você mistura". Existe uma configuração onde a mistura não só é aceitável, como é recomendada para otimização de TCO (Total Cost of Ownership).
No backend de armazenamento atual do Ceph (BlueStore), os dados são divididos em:
Block Data: O dado do objeto em si.
RocksDB/WAL: Metadados internos e Write-Ahead Log.
O RocksDB é extremamente sensível à latência e gera muitas pequenas gravações aleatórias. O SATA sofre muito com isso. O cenário ideal de custo-benefício é usar SSDs SATA grandes e baratos para os dados (Block) e fatiar um NVMe rápido e durável para atuar como WAL/DB para múltiplos OSDs SATA.
A Regra de Ouro do Dimensionamento
Não use partições arbitrariamente pequenas. Se o DB encher, o Ceph começará a escrever metadados no disco lento (Spillover), causando uma degradação de performance catastrófica.
- Block DB: Recomenda-se entre 1% a 4% da capacidade do disco de dados, dependendo do tamanho médio dos objetos. Para um SSD SATA de 2TB, uma partição de 30GB-60GB no NVMe costuma ser segura para cargas gerais.
Risco Operacional: Ao colocar o WAL/DB de 4 ou 5 OSDs SATA em um único NVMe, você cria um ponto único de falha para esses 5 discos. Se o NVMe morrer, você perde 5 OSDs simultaneamente. Certifique-se de que seu domínio de falha (Failure Domain) no CRUSH map suporte a perda de um nó inteiro ou desenhe a solução para mitigar esse risco.
Segregação via CRUSH Map: Isolando Cargas de Trabalho
Se você já possui o hardware misto e não pode reconfigurar o particionamento físico para o modelo WAL/DB, a única saída arquitetural viável é a segregação lógica completa.
O Ceph permite criar "Device Classes". Você deve rotular seus drives NVMe como nvme e seus SSDs SATA como ssd (o padrão do Ceph detecta, mas verifique). Em seguida, crie regras CRUSH distintas.
Isso permite criar dois Pools separados:
Pool Gold (NVMe): Para bancos de dados e cargas de alta IOPS.
Pool Silver (SATA): Para armazenamento de objetos, backups ou VMs de baixa prioridade.
Nunca permita que um Pool espalhe dados entre as duas classes.
# Exemplo conceitual de verificação e criação de regra
# 1. Verificar classes detectadas
ceph osd crush class ls
# 2. Criar uma regra que use APENAS nvme
ceph osd crush rule create-replicated rule-nvme default host nvme
# 3. Associar um pool a essa regra
ceph osd pool set pool-banco-dados crush_rule rule-nvme
Ao fazer isso, você garante a previsibilidade. O Pool NVMe entregará a latência do NVMe, e o Pool SATA entregará a latência do SATA. Sem surpresas.
Diagnóstico Prático: Identificando "Stragglers"
Como saber se você está sofrendo com latência mista ou discos lentos agora? O comando ceph osd perf é seu melhor amigo, mas ele precisa ser interpretado corretamente.
Você deve observar duas colunas principais:
commit_latency: Tempo para persistir o dado no disco (journal/WAL).
apply_latency: Tempo total para a transação estar disponível para leitura (inclui flush para o filesystem/bluestore).
Se você tem um cluster misto mal configurado, verá uma disparidade enorme nesses números entre OSDs do mesmo pool.
# Comando para visualizar latências (em ms)
ceph osd perf
O que procurar:
Se o OSD.1 (NVMe) mostra commit_latency de 2ms, e o OSD.2 (SATA) no mesmo PG mostra 40ms, o OSD.2 está ditando a velocidade de escrita do grupo. O cliente sente 40ms, não 2ms.
Além disso, verifique se há spillover do BlueStore (quando o NVMe DB enche e vaza para o lento):
ceph daemon osd.N perf dump | grep "bluefs_slow_used_bytes"
Se esse valor for maior que zero em uma configuração híbrida, sua performance está comprometida.
Veredito Técnico
A arquitetura de armazenamento não perdoa suposições. Misturar SSDs SATA e NVMe no mesmo pool de dados do Ceph não resulta em uma performance "média"; resulta na pior performance possível entre os componentes, com o custo do componente mais caro.
Para maximizar o TCO e a eficiência:
Homogeneidade é rei: Mantenha pools com hardware idêntico.
Hibridismo inteligente: Use NVMe apenas para descarregar o trabalho pesado de metadados (RocksDB) dos SSDs SATA, mas esteja ciente do risco de falha concentrada.
Segregação: Se tiver que ter ambos, use CRUSH rules para garantir que nunca se encontrem no mesmo PG.
Pensar em storage é pensar no caminho crítico do dado. Remova os obstáculos, não os misture.
Referências & Leitura Complementar
Ceph Documentation - BlueStore Configuration: Detalhes sobre dimensionamento de block.db e block.wal.
RocksDB Tuning Guide: Compreensão profunda sobre como a compactação e write stalls afetam a latência do Ceph.
NVMe Specification (NVM Express): Comparação técnica detalhada sobre filas e comandos vs AHCI.
Google: "The Tail at Scale" (Dean & Barroso): Paper fundamental sobre como a latência de cauda afeta sistemas distribuídos.

Eduardo Nogueira
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ele diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.