Ceph Tuning para VMs: Anatomia de Workloads DB, ERP e VDI
Suas VMs no Ceph estão lentas? Esqueça a largura de banda. Aprenda a tunar latência, cache RBD e Bluestore especificamente para Bancos de Dados, VDI e ERPs monolíticos.
Você recebe o chamado às 09:00 da manhã. O sistema de ERP está engasgando, as sessões de VDI estão congelando e o DBA jura que o banco de dados está esperando por I/O. Você olha para o dashboard do Ceph: largura de banda sobrando, CPU dos OSDs em 30%. Tudo parece verde.
Mas o usuário diz que está lento. E na forense de sistemas, o usuário é a testemunha ocular; o dashboard é apenas um relatório policial mal preenchido.
O problema com máquinas virtuais (VMs) rodando sobre Ceph raramente é "quanto dados conseguimos empurrar", mas sim "quanto tempo leva para garantir que o dado foi salvo". Vamos dissecar a cena do crime, isolar as variáveis de latência e entender por que tratar um banco de dados SQL como um desktop virtual é a receita para o desastre.
O Que é Latência de Commit no Ceph? A latência de commit no Ceph é o tempo total decorrido entre o envio de uma solicitação de gravação pelo sistema operacional convidado (Guest OS) e o recebimento da confirmação (Ack). Diferente do armazenamento local, este ciclo inclui a travessia da rede, a gravação no OSD Primário, a replicação síncrona para os OSDs Secundários e a confirmação de persistência em disco (WAL/Journal) de todas as réplicas antes de liberar a VM para a próxima operação.
A Falácia da Largura de Banda: Por que a Latência mata VMs no Ceph
A primeira evidência enganosa em qualquer investigação de storage é o gráfico de throughput. Ver um cluster Ceph operando a 2GB/s parece impressionante, mas para uma VM rodando PostgreSQL ou um ERP legado, isso é irrelevante.
VMs operam, majoritariamente, com I/O randômico e blocos pequenos (4K a 64K). Vamos à matemática forense:
Se sua VM precisa fazer 1.000 IOPS de escrita (4K block size).
Isso gera apenas 4 MB/s de tráfego.
Um link de 10Gbps não resolve o problema se o tempo de viagem (round-trip) de cada um desses 1.000 pacotes for alto. O gargalo é a física, não o cano. Se o seu seek time ou latência de rede adiciona 2ms a cada operação síncrona, sua VM vai parecer uma carroça, mesmo que você tenha 100Gbps de backbone.
O Caminho da Escrita (Write Path): Do Guest OS ao OSD Commit
Para tunar, você precisa visualizar o caminho da dor. Quando uma VM escreve um bloco de dados, ela não está escrevendo num disco; ela está enviando um pedido burocrático que precisa de três carimbos (em um pool com size=3) para ser aprovado.
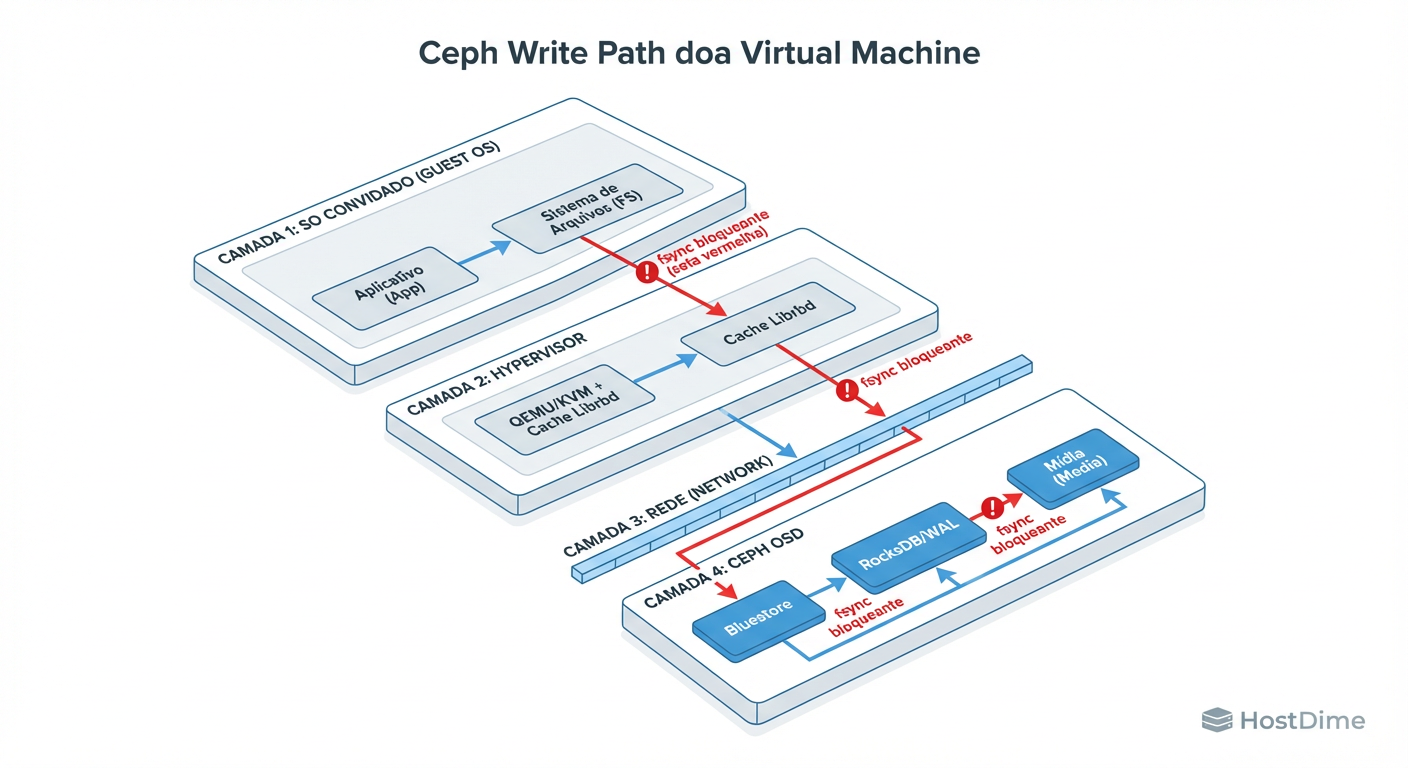 Figura: O Caminho da Dor: Onde sua latência de gravação realmente acontece. Note que o 'Ack' só volta para a VM após a persistência no OSD.
Figura: O Caminho da Dor: Onde sua latência de gravação realmente acontece. Note que o 'Ack' só volta para a VM após a persistência no OSD.
O diagrama acima expõe a realidade crua. O "Ack" (a permissão para o Guest OS prosseguir) só retorna após a persistência física no Journal ou BlueStore WAL de todos os OSDs envolvidos na réplica.
Se você tem dois OSDs em NVMe e um OSD em um HDD girando a 7.2k RPM que está vibrando demais no rack, a performance de escrita da sua VM será nivelada por baixo. O cluster é tão rápido quanto o seu disco mais lento.
Tuning para Bancos de Dados (DB): O dilema do fsync e o WAL
Bancos de dados transacionais (PostgreSQL, MySQL, Oracle) são os inquilinos mais paranoicos do seu cluster. Eles não confiam no sistema operacional. Eles usam chamadas fsync() ou fdatasync() constantemente para garantir que a transação foi gravada no "metal".
O Erro Comum: Cache RBD
Habilitar o cache de writeback do RBD (rbd cache = true) para bancos de dados é frequentemente um placebo. O banco de dados envia um flush logo após a escrita, forçando o RBD a despejar o cache para o OSD imediatamente. Você adicionou uma camada de complexidade (RAM do host) sem ganho real de latência, pois o DB exige a confirmação física.
A Solução Forense: OSD WAL em Mídia Rápida
Se você não pode pagar por um cluster All-Flash, você deve separar o WAL (Write Ahead Log) e o DB (RocksDB do BlueStore).
HDDs para dados (Data): Barato, alta capacidade.
NVMe/Optane para WAL/DB: Baixíssima latência.
Ao mover o WAL para um NVMe, o OSD pode enviar o "Ack" de gravação assim que o dado atinge a memória flash do NVMe, mesmo que o dado final ainda esteja migrando para o HDD lento. Isso reduz a latência de escrita de 10-15ms (HDD) para sub-milissegundos.
Tuning para VDI: Gerenciando Boot Storms e o Cache de Imagem Pai
Workloads de VDI (Virtual Desktop Infrastructure) são o oposto polar de Bancos de Dados. Enquanto o DB é um martelo de escrita constante, o VDI é uma bomba de leitura explosiva, especialmente durante "Boot Storms" (quando todos ligam o PC às 8h) ou "Login Storms".
A maioria dos VDIs em Ceph usa Linked Clones ou Snapshots. Centenas de VMs leem exatamente os mesmos blocos da imagem base (Golden Image).
 Figura: Perfis de Workload: Tuning para VDI (foco em cache de leitura) é o oposto do tuning para DB (foco em latência de escrita).
Figura: Perfis de Workload: Tuning para VDI (foco em cache de leitura) é o oposto do tuning para DB (foco em latência de escrita).
Otimização Crítica: RBD Parent Cache
No lado do Hypervisor (cliente Ceph), o gargalo é a busca repetitiva dos mesmos dados no cluster.
Problema: 500 VMs pedindo o bloco 0 da imagem do Windows 10 simultaneamente.
Solução: Habilitar o
rbd parent cache.
Isso permite que o socket do cliente RBD armazene a imagem "pai" (que é somente leitura) na RAM do host físico onde as VMs rodam. As leituras subsequentes são servidas localmente, sem tocar na rede ou nos OSDs.
Checklist de Configuração VDI:
Habilitar
rbd_cache = true(Seguro aqui, pois o SO do desktop tolera melhor perdas que um DB, e ajuda na percepção de fluidez).Verificar se a Golden Image está achatada (flattened) ou se é uma cadeia longa de snapshots (evite cadeias longas, a latência de busca aumenta).
Tuning para ERP: Monolitos, Block Sizes e Consistência
Sistemas ERP (como SAP ou legados proprietários) muitas vezes operam como monolitos. O perigo aqui é o desalinhamento de blocos.
O Ceph (RBD) tem uma ordem de objetos padrão (geralmente 4MB), mas o sistema de arquivos dentro da VM (ex: NTFS ou XFS) e a aplicação ERP têm seus próprios tamanhos de bloco.
O Fenômeno Read-Modify-Write
Se o seu ERP escreve blocos de 512 bytes, mas o alinhamento do disco virtual ou do sistema de arquivos espera 4K, cada escrita pequena força o sistema a ler o bloco de 4K, modificar os 512 bytes e escrever tudo de volta. Isso duplica ou triplica o I/O no backend (amplificação de escrita).
Ação Investigativa: Verifique se a partição dentro da VM está alinhada. Em Linux modernos e Windows Server 2016+, isso é automático. Em sistemas legados (comuns em ERPs antigos), o setor inicial pode estar desalinhado.
KRBD vs Librbd: Quando o Kernel Mode salva a performance
Há duas maneiras de mapear um disco Ceph em um host Linux: librbd (User space, usado pelo QEMU/KVM) e krbd (Kernel module, mapeia como /dev/rbd0).
| Característica | Librbd (QEMU/KVM) | KRBD (Kernel Mapping) |
|---|---|---|
| Contexto | User Space | Kernel Space |
| Overhead | Maior (Context switches) | Menor (Direto no Kernel) |
| Caching | RBD Cache flexível | Page Cache do Linux |
| Uso Ideal | Virtualização Padrão (Live Migration fácil) | Containers, Bare Metal, DBs de altíssima performance |
| Desvantagem | Latência ligeiramente maior | Atualizar o kernel do host é crítico para features novas |
Para a maioria das VMs, librbd é o padrão. Porém, se você notar que a CPU do host está saturada com context switches e o processo QEMU está lutando, mapear via krbd e passar o block device cru para a VM pode reduzir a latência, eliminando camadas de abstração.
Métricas Forenses: Provando o Gargalo
Você não pode tunar o que não mede. Esqueça o top ou o monitoramento genérico. Use as ferramentas nativas para isolar o ofensor.
1. Quem está matando o cluster?
Use o rbd perf imageiotop para ver, em tempo real, qual imagem está gerando mais IOPS ou Latência.
# Necessita que o mgr module 'rbd_support' esteja ativo
ceph rbd perf imageiotop
Procure por: Uma única VM com latência de escrita (wr_lat) desproporcional.
2. OSD Lento (O "Laggard")
Um único disco com defeito mecânico intermitente pode elevar a latência do percentil 99 (p99) de todo o pool.
ceph osd perf
Analise as colunas: commit_latency_ms e apply_latency_ms.
Se a média é 5ms, mas o osd.42 está marcando 150ms, você encontrou o culpado. Remova-o do cluster (ceph osd out) e veja a performance da VM normalizar instantaneamente.
3. Latência de Rede vs Disco
Se o ceph osd perf mostra latências baixas nos discos, mas a VM sente lentidão, o problema está na rede ou no Hypervisor. Teste a latência de rede pura entre os nós do cluster (sem passar pelo Ceph) usando iperf ou ping com pacotes grandes e flag "do not fragment" para verificar MTU.
Referências & Leitura Complementar
Para aprofundar sua investigação, consulte a documentação original e os estudos fundamentais:
Ceph Documentation - Network Configuration Reference: Detalhes sobre MTU 9000 e separação de redes (Cluster vs Public).
RBD Replay: Ferramenta para gravar e reproduzir workloads reais para teste de carga.
RocksDB Tuning Guide for Ceph: Parâmetros específicos para otimizar a base de dados do BlueStore.
VirtIO Drivers Documentation: Importância dos drivers paravirtualizados para performance de I/O em KVM.

Daniel Siqueira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensor do 'Infrastructure as Code' para storage.