Ceph vs. SAN Tradicional: Onde a Complexidade Cobra Juros
Pare de comparar apenas o preço por TB. Entenda os trade-offs reais de latência, custo operacional (OpEx) e arquitetura entre Ceph e Storage Area Networks (SAN) antes de migrar.
Todo mundo adora a ideia de "Software Defined Storage" (SDS) no PowerPoint. A promessa é sedutora: livre-se do "vendor lock-in" da EMC, NetApp ou HPE, compre servidores genéricos ("commodity hardware") e deixe o software mágico resolver tudo. O Ceph é o garoto-propaganda dessa revolução. É open source, escala para exabytes e é incrivelmente resiliente.
Mas aqui vai a verdade que o consultor de vendas não te conta: Storage não é apenas sobre guardar bits; é sobre quão rápido e confiavelmente você consegue recuperá-los sob pressão. Quando você troca uma SAN dedicada por um cluster Ceph, você não está eliminando a complexidade; você está apenas movendo-a do firmware proprietário (ASICs) para a sua pilha de CPU, Rede e Kernel Linux. E essa mudança cobra juros altos em forma de latência e horas de engenharia.
Ceph vs. SAN Tradicional é um trade-off entre flexibilidade de escala e determinismo de performance. Enquanto uma SAN utiliza hardware dedicado (ASICs/FPGAs) para processar I/O com latência de microssegundos e consistência garantida, o Ceph distribui essa carga via software em CPUs de propósito geral, introduzindo variabilidade de latência e exigindo uma infraestrutura de rede robusta para manter a coerência dos dados.
A Ilusão do Hardware de Commodity no Ceph
A primeira falácia que precisamos desmontar é a de que o Ceph roda bem em "qualquer lixo". Se você montar um cluster com HDDs SATA de 7.2k, rede de 1Gbps e CPUs de entrada, você não terá um storage; terá um gerador de timeouts.
O Ceph é um sistema distribuído fortemente consistente. Isso significa que, para confirmar uma gravação (write ack) para o cliente, os dados precisam ser replicados através da rede, gravados no journal/WAL (Write Ahead Log) e confirmados pelos OSDs (Object Storage Daemons) secundários.
Isso exige:
Rede de Baixa Latência: 10GbE é o mínimo absoluto para o backend (rede de replicação). 25GbE ou 100GbE é o padrão para produção séria.
CPU Rápida: O Ceph faz cálculos de CRC (checksum) e o algoritmo CRUSH (Controlled Replication Under Scalable Hashing) a cada I/O. Isso come ciclos de CPU.
RAM Abundante: O cache do BlueStore e a manutenção dos mapas de OSD consomem gigabytes de RAM por disco.
A Realidade: Para obter uma performance comparável a uma SAN de médio porte, o "hardware de commodity" do Ceph precisa ser equipado com NVMe para journals, muita RAM e NICs de alta performance. De repente, a economia de custo de hardware não parece tão grande assim.
Latência no Ceph vs. SAN: ASIC Dedicado contra Ciclos de CPU
Aqui é onde a física entra em jogo. Em uma SAN tradicional, o caminho do dado (datapath) é otimizado em silício. O pacote iSCSI ou frame Fibre Channel entra na porta, passa por um chip dedicado (ASIC) que sabe exatamente onde jogar aquele bloco, e vai para o cache ou disco. É um caminho curto e determinístico.
No Ceph, o caminho é uma maratona de software. O dado entra na NIC, gera uma interrupção na CPU, sobe a pilha TCP/IP do Linux, entra no espaço de usuário (userspace), é processado pelo daemon do OSD, calculado pelo CRUSH, e então enviado de volta para a rede para ser replicado em outros nós.
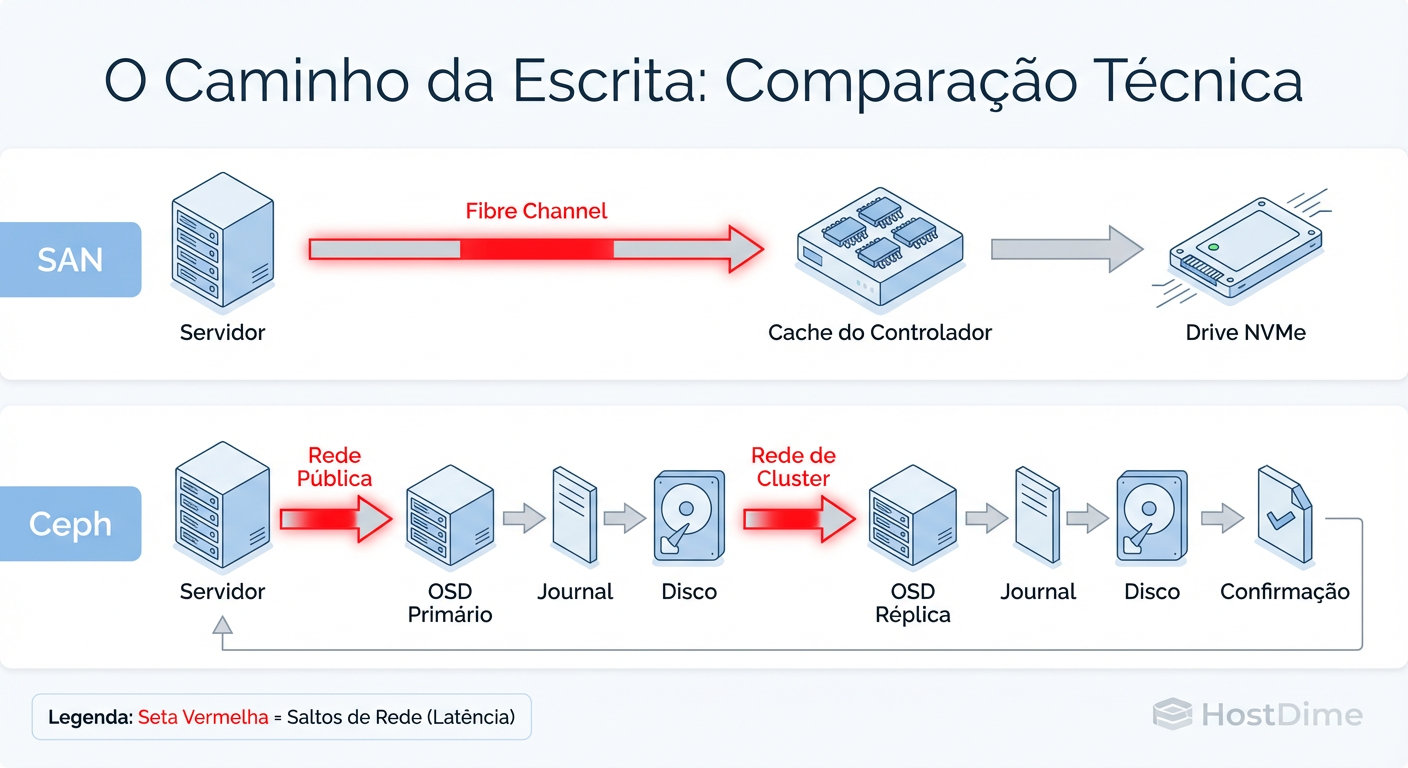 Figura: O Caminho da Escrita (Write Path): Visualizando onde a latência se esconde no Ceph comparado à rota direta de uma SAN.
Figura: O Caminho da Escrita (Write Path): Visualizando onde a latência se esconde no Ceph comparado à rota direta de uma SAN.
Essa imagem ilustra o "Imposto do Software". Cada salto entre Kernel Space e User Space, e cada salto de rede para replicação, adiciona latência.
Em uma SAN, você mede a latência em microssegundos consistentes. No Ceph, a latência média pode ser boa, mas a latência de cauda (tail latency - p99) é onde o pesadelo mora. Um único disco lento ou um pico de CPU em um nó pode fazer com que uma leitura que normalmente leva 2ms leve 500ms.
Para medir isso no mundo real, esqueça o throughput (MB/s). Foque na latência de commit. Se você já tem um cluster, use o comando abaixo para ver a latência de commit real que seus OSDs estão aplicando:
ceph osd perf
Se você vir valores de commit_latency_ms saltando de 5ms para 100ms aleatoriamente, suas aplicações sensíveis (bancos de dados, VM disks) vão engasgar.
Modelos de Falha: Rebuild de RAID Tradicional e Rebalanceamento de Rede
O comportamento em falha é o que separa os sysadmins que dormem à noite dos que vivem de café e ansiedade.
Na SAN (RAID): Quando um disco falha em um RAID 6, a controladora calcula a paridade e reconstrói os dados no disco de spare. O impacto de performance é localizado naquele grupo de discos (RAID Group/Pool). O resto do array continua operando normalmente. O gargalo é a velocidade de escrita do disco novo.
No Ceph (Rebalanceamento): Quando um OSD morre, o Ceph entra em modo de "recovery". Ele percebe que os Placement Groups (PGs) estão degradados e começa a recriar as cópias faltantes. A diferença? Ele não reconstrói em um disco local. Ele move dados através da rede de todos os nós sobreviventes para outros nós sobreviventes para restaurar a redundância.
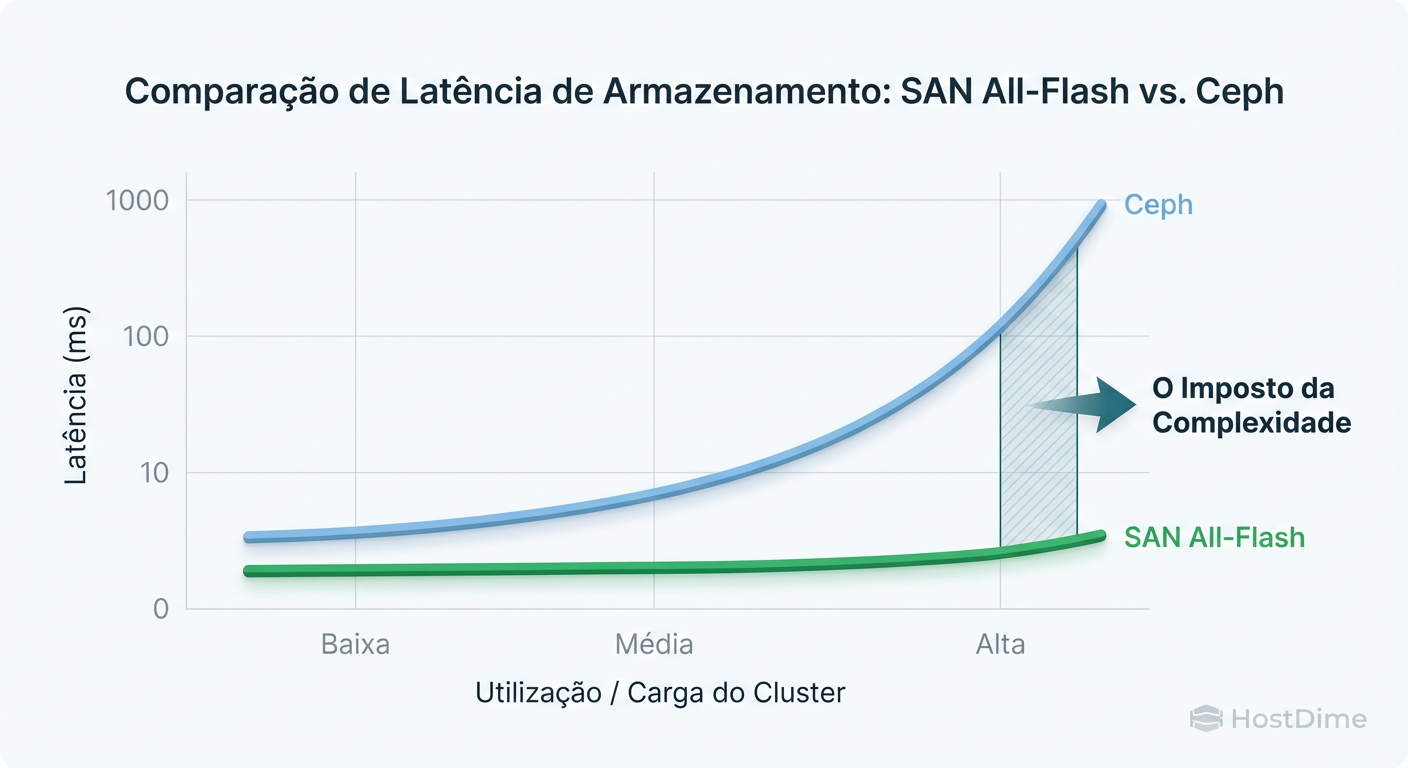 Figura: Curva de Latência vs. Carga: Como o comportamento muda quando o sistema é estressado ou entra em recuperação.
Figura: Curva de Latência vs. Carga: Como o comportamento muda quando o sistema é estressado ou entra em recuperação.
Isso cria o que chamamos de "tempestade de tráfego leste-oeste". Se sua rede já estiver saturada, o tráfego de recuperação compete com o tráfego de produção. Se você não configurar os limites de osd_recovery_max_active e osd_recovery_op_priority corretamente, o cluster pode entrar em uma espiral da morte onde a recuperação derruba a latência da produção, fazendo com que clientes desconectem, gerando mais instabilidade.
O Perigo Oculto: O Ceph é "autocurável", o que é ótimo, até ele decidir se curar no meio do horário de pico. Uma SAN espera você trocar o disco. O Ceph começa a mover Terabytes de dados pela rede automaticamente (a menos que você defina a flag noout).
Custo Operacional: Sysadmin de Storage vs. Engenheiro de Sistemas Distribuídos
Este é o custo que não aparece na planilha de aquisição.
Uma SAN Enterprise é um eletrodoméstico. Você configura LUNs, zonas e esquece. Quando quebra, o suporte do fabricante manda uma peça e um técnico. A complexidade interna é escondida (caixa preta).
O Ceph é uma caixa transparente cheia de engrenagens expostas. Para operar Ceph em produção, você não precisa apenas de um "cara de storage". Você precisa de um engenheiro que entenda profundamente de:
Linux Kernel tuning (gerenciamento de memória, NUMA nodes).
Networking avançado (LACP, Jumbo Frames, Flow Control, TCP congestion algorithms).
Automação (Ansible/Salt, porque você não vai gerenciar 50 nós na mão).
Debugging de Hardware (identificar qual pente de RAM está causando ECC errors silenciosos).
Se o seu time é pequeno e generalista, o Ceph pode se tornar um buraco negro de tempo operacional. Você economizou $50k em licenças da NetApp, mas gastou $100k em horas-homem de engenharia tentando descobrir por que a latência sobe toda terça-feira às 14h.
Matriz de Decisão: Quando Escolher Ceph ou SAN
Não existe "melhor", existe a ferramenta certa para o trabalho. Use esta tabela para ser honesto com seus requisitos.
| Característica | SAN Tradicional (All-Flash/Hybrid) | Ceph (SDS) |
|---|---|---|
| Escala Ideal | 10TB até ~2PB | 500TB até Exabytes |
| Latência (p99) | Baixa e Determinística (Previsível) | Variável (Sensível a ruído de rede/CPU) |
| Custo Inicial | Alto (Hardware Proprietário) | Médio (Hardware + Engenharia) |
| Complexidade Ops | Baixa ("Set and Forget") | Alta (Requer monitoramento constante) |
| Ponto Único de Falha | Controladora (mesmo em HA, é um risco) | Nenhum (Design "Shared Nothing") |
| Caso de Uso Ideal | VDI, Banco de Dados SQL, VMware | Object Storage (S3), Arquivamento, K8s, OpenStack |
Veredito Pragmático
Escolha SAN Tradicional se:
Você precisa de latência sub-milissegundo garantida para bancos de dados transacionais.
Sua equipe é pequena e você quer "alguém para culpar" (suporte do vendor).
Seu volume de dados é inferior a 500TB. A complexidade do Ceph não se paga em escalas pequenas.
Escolha Ceph se:
Você está construindo uma nuvem privada (OpenStack/Kubernetes) e precisa de API-driven storage.
Você precisa de Object Storage (S3) nativo on-premise.
Você tem escala de Petabytes e o custo de licenciamento de uma SAN se tornaria proibitivo.
Você tem engenheiros Linux sêniors na equipe dispostos a manter o sistema.
O Ceph é uma maravilha da engenharia moderna, mas não é mágica. Ele troca dinheiro (hardware proprietário) por tempo (complexidade de gestão) e latência (ciclos de CPU). Certifique-se de que essa é uma troca que seu negócio pode bancar.
Referências & Leitura Complementar
Ceph Documentation - CRUSH Maps: Entendimento fundamental de como o Ceph distribui dados sem uma tabela de alocação central.
"Systems Performance: Enterprise and the Cloud" (Brendan Gregg): Capítulo sobre Disk e File Systems para entender latência de I/O e metodologias de medição.
RFC 3720 (iSCSI): Para entender a diferença de protocolo e overhead comparado ao protocolo nativo do RADOS.
Ceph Bluestore Performance Analysis (Intel/RedHat Whitepapers): Dados empíricos sobre o impacto de NVMe e WAL no desempenho do Ceph.

Marcelo Furtado
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.