Ceph Write Amplification: Por que seus SSDs morrem cedo (e como evitar)
Seus SSDs no cluster Ceph estão desgastando rápido demais? Entenda a matemática brutal da Write Amplification, o papel do BlueStore e como tunar seu storage para sobreviver.
Você comprou SSDs NVMe de última geração. O datasheet prometia 500.000 IOPS. Você montou um cluster Ceph, configurou a replicação e, ao rodar o primeiro benchmark de banco de dados, o desempenho despencou para míseros 5.000 IOPS. Pior: em seis meses, o indicador de desgaste (wear level) dos discos atingiu níveis críticos.
Isso não é má sorte. É matemática. No mundo do armazenamento distribuído, existe um fenômeno silencioso que transforma 1GB de dados lógicos em 10GB, 20GB ou até 50GB de gravações físicas no NAND do seu SSD.
Se você opera Ceph, entender a Amplificação de Escrita (Write Amplification) não é opcional; é a diferença entre um cluster performático e uma pilha de lixo eletrônico.
O que é Write Amplification no Ceph? A Amplificação de Escrita (Write Amplification Factor - WAF) é a razão entre a quantidade de dados fisicamente gravados no disco e a quantidade de dados logicamente solicitados pelo cliente. Em um cluster Ceph, o WAF é composto por três camadas multiplicadoras: a replicação de rede (fator de réplica), a arquitetura interna do BlueStore (double-write penalty) e a geometria física do SSD (garbage collection e alinhamento de blocos). Um WAF alto destrói a latência e incinera a vida útil do hardware.
A Matemática do Desastre: Calculando o WAF Real no Ceph
Para resolver um problema de performance, primeiro precisamos quantificá-lo. O erro comum é olhar apenas para o WAF do SSD (interno). No Ceph, o buraco é mais embaixo.
O fluxo de amplificação segue uma cascata multiplicadora. Vamos assumir um cenário padrão: Réplica 3 (3x) e um workload de banco de dados (escritas aleatórias pequenas de 4KB).
Nível Lógico (Aplicação): O cliente envia 4KB.
Nível de Replicação (Ceph): O dado é enviado para 3 OSDs. Total: 12KB.
Nível de Backend (BlueStore): Aqui entra o Double-Write Penalty. Como 4KB é menor que o
min_alloc_sizepadrão, o Ceph escreve primeiro no WAL (Write Ahead Log) para garantir atomicidade, e depois na partição de dados. Total: 24KB (mais metadados).Nível Físico (SSD): Se o disco for Consumer Grade ou se houver desalinhamento, o controlador do SSD precisa ler uma página inteira (ex: 16KB), modificar 4KB e regravar 16KB (Read-Modify-Write), além de mover dados para Garbage Collection.
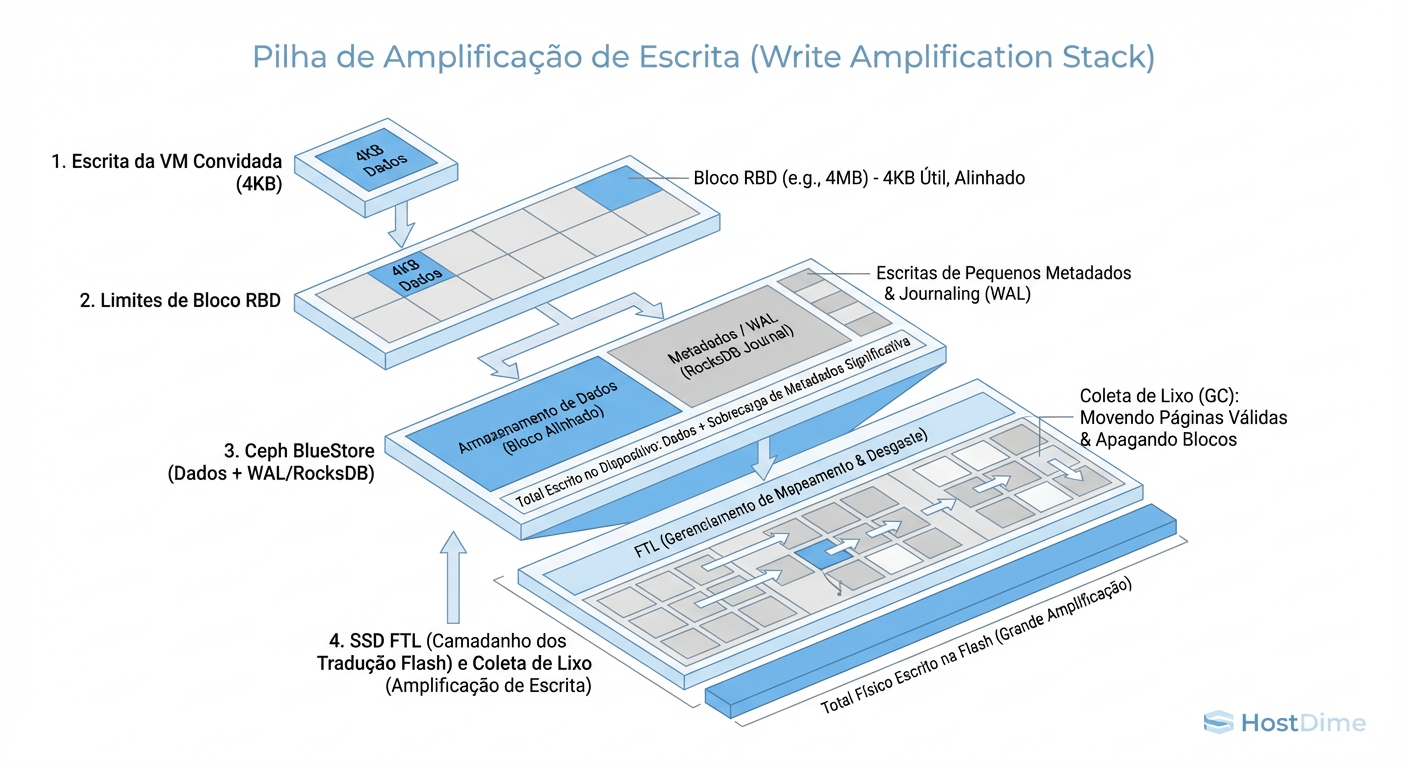 Figura: O Funil da Amplificação: Como 4KB lógicos viram megabytes físicos.
Figura: O Funil da Amplificação: Como 4KB lógicos viram megabytes físicos.
O resultado? Aqueles 4KB iniciais podem gerar 100KB+ de desgaste físico distribuído. Se você não controlar cada etapa desse funil, a latência de gravação sobe de microsegundos para milissegundos.
O "Bolo de Camadas" do BlueStore e o Double-Write Penalty
O BlueStore é o motor de armazenamento padrão do Ceph. Ele é excelente porque fala diretamente com o dispositivo de bloco, ignorando o filesystem local (como XFS ou ext4). Porém, ele precisa garantir consistência ACID.
Para evitar "torn pages" (páginas corrompidas por falha de energia durante a escrita), o BlueStore utiliza um mecanismo de segurança:
Big Writes: Se a escrita for maior que o bloco mínimo de alocação (padrão antigo 64K, novo 4K em SSDs, mas configurável), ele escreve direto no local final e apenas atualiza os metadados no RocksDB. WAF Baixo.
Small Writes (Deferred Write): Se a escrita for pequena (ex: 4KB) e sobrescrever dados existentes, o BlueStore escreve os dados primeiro no WAL (Write Ahead Log) dentro do RocksDB. Só depois, de forma assíncrona, ele move os dados para o local final no disco.
Isso significa que pequenas escritas aleatórias são gravadas duas vezes no disco. Esse é o Double-Write Penalty. Em bancos de dados transacionais (MySQL/PostgreSQL sobre RBD), isso é o padrão, não a exceção.
A Mentira do IOPS: SSD Consumer vs. Enterprise (PLP)
Aqui reside a maior armadilha para quem monta "Home Labs" ou clusters de baixo custo.
Um SSD Samsung 980 Pro (Consumer) e um Micron 7450 (Enterprise) podem ter velocidades de leitura sequencial parecidas. Mas no Ceph, o comportamento é diametralmente oposto.
O Ceph é paranoico com a segurança dos dados. Ele envia comandos de flush (sincronização forçada) constantemente para garantir que o dado esteja no NAND e não na RAM do disco.
SSD com PLP (Power Loss Protection): Possui capacitores físicos. Quando recebe um
flush, ele joga o dado para sua DRAM protegida, diz "OK" para o Ceph imediatamente e grava no NAND com calma. Latência baixa.SSD sem PLP (Consumer): Não tem capacitores. Quando recebe um
flush, ele é obrigado a parar tudo e gravar no NAND lento imediatamente para não perder dados em caso de corte de energia. Isso ignora otimizações internas do controlador.
Resultado: Um SSD Consumer que promete 500k IOPS pode cair para 500 IOPS sob a carga de fsync do Ceph. O WAF interno do SSD explode porque ele não consegue agregar escritas pequenas em blocos grandes.
Tabela Comparativa: O Custo Oculto do Hardware
| Característica | SSD Consumer (Ex: Samsung EVO/Pro) | SSD Enterprise (Ex: Intel D7, Micron 7400) | Impacto no Ceph |
|---|---|---|---|
| Proteção de Energia (PLP) | Inexistente | Capacitores de Tântalo | Crítico. Sem PLP, a latência de commit do RocksDB sobe 10x-100x. |
| Endurance (DWPD) | 0.3 a 0.6 | 1.0 a 3.0+ | Longevidade. O WAF do Ceph vai consumir um disco de 0.3 DWPD em meses. |
| Overprovisioning | ~7% | ~28% ou configurável | Mantém a performance estável durante Garbage Collection pesado. |
| Custo por GB | Baixo | Alto | O barato sai caro quando você precisa substituir discos a cada 8 meses. |
O Mecanismo de Read-Modify-Write (RMW)
O desalinhamento é o assassino silencioso da performance. Discos SSD modernos operam internamente com páginas físicas de 4KB, 8KB ou 16KB. O BlueStore também tem seu tamanho mínimo de alocação (min_alloc_size).
Se o min_alloc_size do BlueStore for 16KB, e você tentar gravar 4KB de dados:
O Ceph lê o bloco de 16KB existente.
Modifica os 4KB na memória.
Grava o bloco inteiro de 16KB de volta.
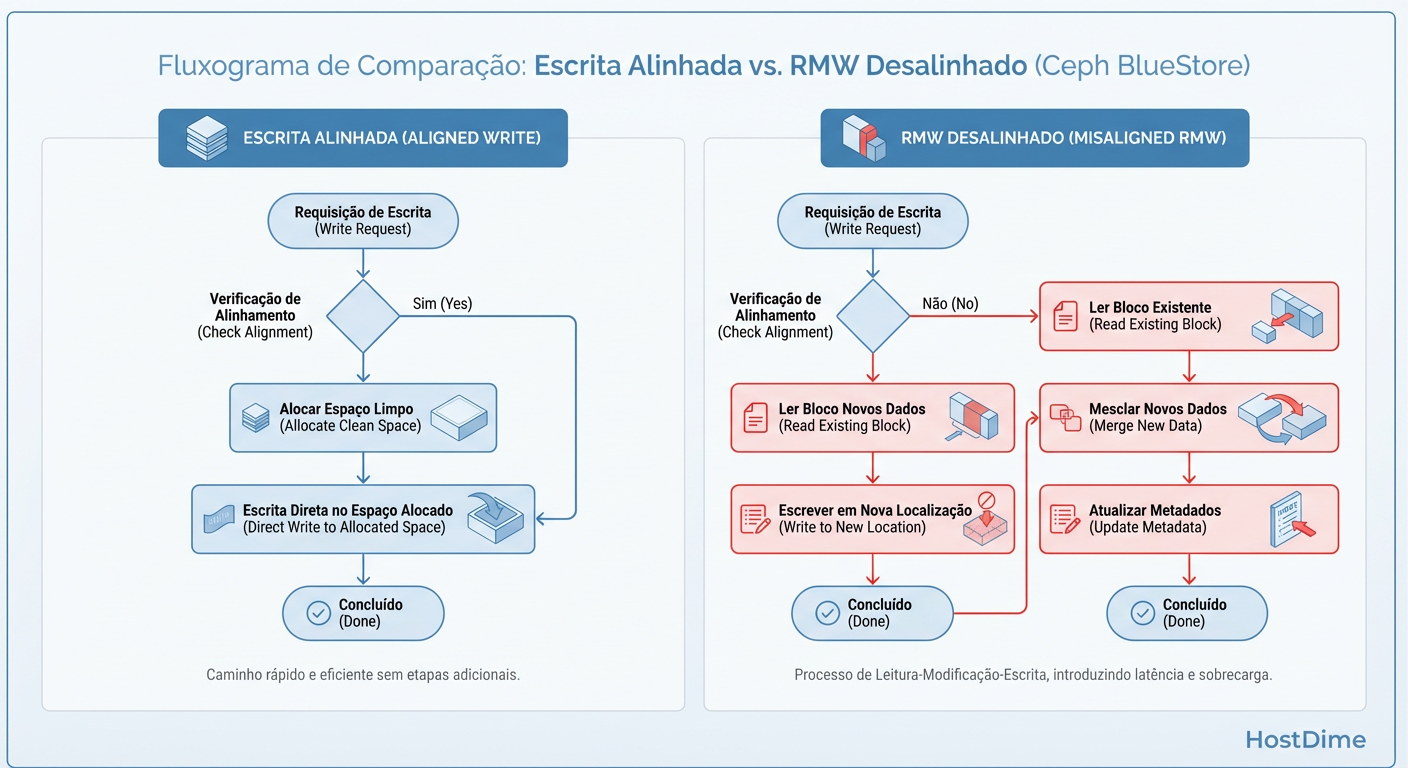 Figura: Read-Modify-Write: O mecanismo que assassina a performance em blocos desalinhados.
Figura: Read-Modify-Write: O mecanismo que assassina a performance em blocos desalinhados.
Você acabou de quadruplicar a quantidade de dados trafegados e aumentou a latência com uma operação de leitura desnecessária.
Diagnóstico: Comandos para medir WAF e Desgaste
Não confie na intuição. Use métricas. Para diagnosticar se você está sofrendo com amplificação massiva, investigue o nível do OSD e o nível do disco físico.
1. Verificando o comportamento do BlueStore
Este comando mostra estatísticas vitais de performance do OSD. Procure por contadores de escritas no WAL.
# Acesse o socket do daemon (exemplo para osd.0)
ceph daemon osd.0 perf dump | grep -A 5 bluestore_writes_with_wal
Se o número de bluestore_writes_with_wal estiver crescendo na mesma proporção que suas escritas totais, seu workload está caindo no cenário de penalidade de escrita dupla.
2. Monitorando o desgaste físico (Smartctl)
Verifique o que o disco reporta. Compare Data Units Written (o que o host enviou) com a saúde do disco.
# Exemplo para um drive NVMe
smartctl -a /dev/nvme0n1 | grep -E "Data Units Written|Percentage Used|Media_Wearout_Indicator"
Análise: Se o Percentage Used sobe 1% a cada poucos dias em um cluster novo, pare tudo. Seu WAF está fora de controle.
Estratégias de Sobrevivência e Tuning
Não existe "bala de prata", existem trade-offs. Aqui estão as configurações para mitigar o problema.
Ajuste o bluestore_min_alloc_size_ssd
Esta é a configuração mais impactante.
Padrão (Versões antigas): 16KB ou 64KB. Ótimo para throughput, terrível para IOPS de bancos de dados (muito RMW).
Padrão (Quincy/Reef): 4KB. Ótimo para IOPS e WAF, mas pode aumentar a fragmentação dos metadados e uso de RAM.
Se seu workload é puramente banco de dados (4KB/8KB random writes), force o alinhamento para 4KB:
ceph config set osd bluestore_min_alloc_size_ssd 4096
# Nota: Requer reinício do OSD para valer em novos dados.
# Dados antigos só serão realinhados após reescrita ou compactação.
Compressão: Amiga ou Inimiga?
A compressão LZ4 do Ceph pode reduzir a quantidade de dados escritos no disco (reduzindo o WAF físico), mas aumenta a latência de CPU e pode causar fragmentação.
- Regra: Ative compressão (
mode: aggressive) apenas se seus dados forem altamente compressíveis (texto, logs). Para dados criptografados ou binários comprimidos, desligue. A CPU gasta tentando comprimir ruído aumenta a latência sem ganho de espaço.
Alinhamento da Aplicação
Configure seu workload (ex: innodb_page_size no MySQL ou volblocksize no ZFS sobre RBD) para ser um múltiplo do min_alloc_size do Ceph.
Se Ceph usa 4KB -> Banco deve usar 4KB, 8KB ou 16KB.
Nunca use um tamanho de bloco de aplicação menor que o do Ceph, ou você garantirá 100% de Read-Modify-Write.
Referências & Leitura Complementar
Ceph Documentation - BlueStore Config Reference: Documentação oficial sobre parâmetros de alocação e WAL.
Micron Technical Brief: "Ceph Performance on Enterprise NVMe SSDs" – Análise detalhada sobre o impacto de PLP em workloads distribuídos.
RocksDB Tuning Guide: Detalhes sobre como a compactação e o WAL do RocksDB (backend do BlueStore) influenciam a escrita.
Sebastien Han (Red Hat): Artigos históricos sobre "Ceph Writelog & BlueStore Performance".

André Bastos
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.