CephFS vs RBD: A Verdade Sobre Performance em Virtualização

Pare de matar a performance das suas VMs. Entenda a arquitetura de I/O, o custo do MDS no CephFS e por que o RBD é o padrão ouro para blocos em ambientes virtualizados.
No mundo do storage definido por software (SDS), a flexibilidade é uma faca de dois gumes. O Ceph, sendo uma solução unificada, permite que você entregue Bloco (RBD), Arquivo (CephFS) e Objeto (RGW) a partir do mesmo cluster RADOS subjacente. Isso cria uma tentação perigosa para arquitetos de virtualização: tratar o storage como uma caixa preta genérica.
Muitos administradores, acostumados com a simplicidade de montar um share NFS em um hypervisor, tentam replicar esse modelo usando CephFS para armazenar imagens de disco de máquinas virtuais (como arquivos .qcow2). O resultado, invariavelmente, é uma degradação de performance que desafia a lógica inicial: "Se os dados estão nos mesmos discos e na mesma rede, por que o CephFS é drasticamente mais lento que o RBD para VMs?"
Como engenheiro de performance, meu trabalho não é aceitar "porque sim", mas isolar as variáveis. Vamos dissecar a arquitetura de I/O, a amplificação de escrita e o custo oculto dos metadados.
Diferença Fundamental entre RBD e CephFS para Virtualização
RBD (RADOS Block Device) é um protocolo de bloco que permite ao cliente calcular deterministicamente a localização dos dados e falar diretamente com os OSDs, eliminando intermediários. CephFS é um sistema de arquivos POSIX que exige uma camada extra de gerenciamento de metadados (MDS) para coordenar permissões, hierarquia e locking. Para virtualização, o RBD oferece o caminho de I/O mais curto e eficiente; o CephFS introduz latência desnecessária e amplificação de escrita.
Entendendo a Diferença entre CephFS e RBD na Camada RADOS
Para entender a performance, precisamos primeiro destruir a ilusão da interface. Seja acessando um bloco RBD ou um arquivo no CephFS, no final da cadeia, tudo vira objetos de 4MB (por padrão) distribuídos em OSDs (Object Storage Daemons). O gargalo não é onde o dado vive, mas como chegamos até ele.
A confusão começa porque humanos pensam em arquivos (pastas, nomes, hierarquia), mas computadores e hypervisors (KVM/QEMU) pensam em blocos (setores, offsets).
O Caminho do I/O no RBD: Acesso Direto aos OSDs
O RBD é o "cidadão de primeira classe" para virtualização no ecossistema Ceph. Sua eficiência reside na ausência de um gateway central.
Quando uma VM escreve em um disco RBD, o driver librbd (no host, via QEMU) não pergunta a um servidor "onde posso escrever isso?". Ele possui uma cópia do mapa do cluster (CRUSH map). O cliente realiza um cálculo matemático local (hashing do nome da imagem + offset do objeto) e determina exatamente qual OSD possui aquele pedaço de dado.
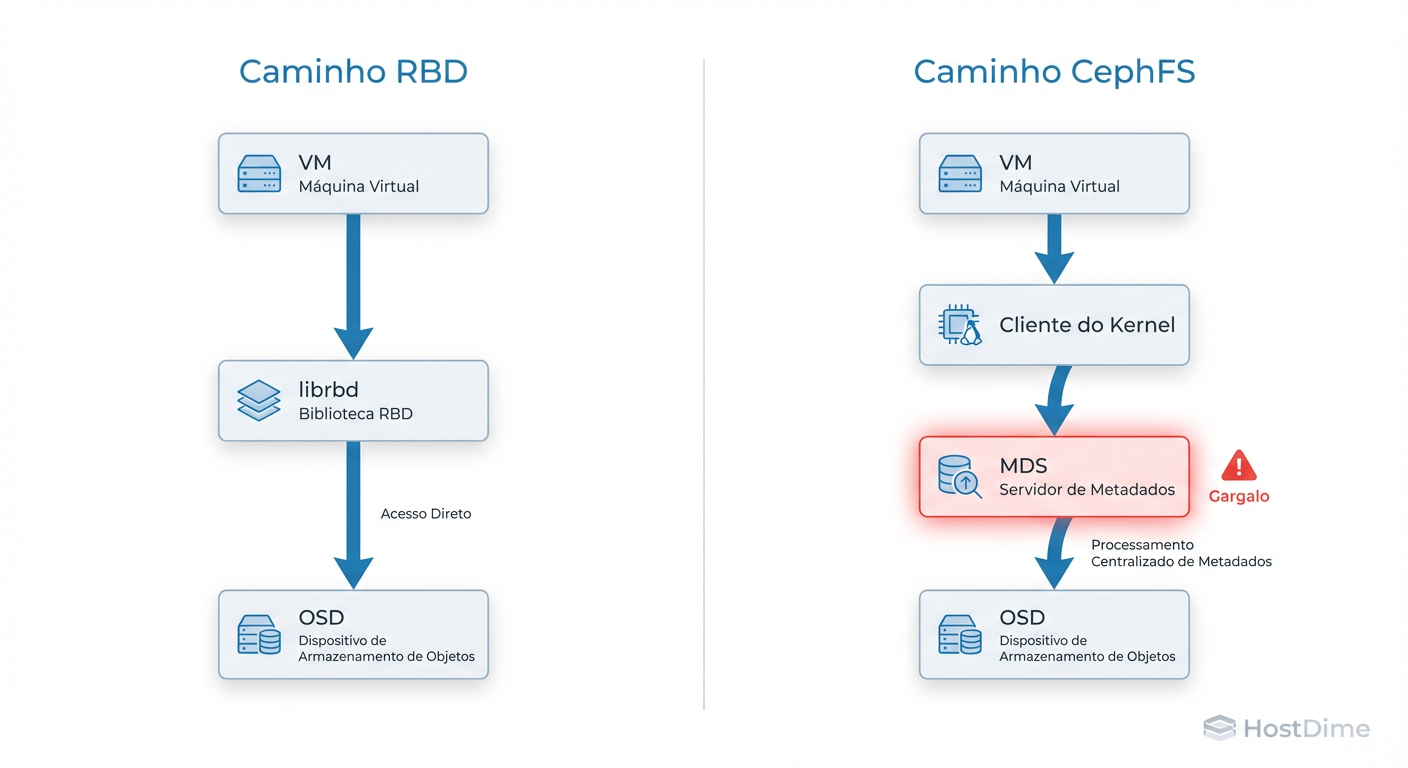 Figura: Fluxo de I/O: O caminho direto do RBD vs. a triangulação de metadados do CephFS
Figura: Fluxo de I/O: O caminho direto do RBD vs. a triangulação de metadados do CephFS
O fluxo é:
VM envia escrita SCSI/VirtIO.
librbdcalcula o OSD primário via algoritmo CRUSH.Socket direto aberto do Host para o OSD.
Ack recebido.
Não há "lookup" de diretório. Não há verificação de permissão POSIX a cada operação. É pura matemática e throughput de rede.
Latência do MDS no CephFS e o Impacto na Virtualização
O CephFS é uma besta diferente. Para ser compatível com POSIX (permitir ls, chmod, diretórios aninhados), ele precisa de um árbitro: o MDS (Metadata Server).
Se você coloca uma imagem de disco (ex: vm-100-disk.qcow2) dentro do CephFS, cada operação de escrita que altera o tamanho do arquivo ou atualiza mtimes (tempos de modificação) exige uma transação com o MDS.
O fluxo se torna triangular:
Cliente quer escrever.
Cliente consulta MDS: "Posso escrever? Onde estão os metadados?" (Latência de Rede #1).
MDS responde e emite um "capability" (cap).
Cliente escreve no OSD (Latência de Rede #2).
Cliente atualiza o MDS sobre a mudança (Latência de Rede #3).
Em workloads de virtualização, que geram milhares de IOPS randômicos, essa triangulação mata a latência. O MDS se torna o gargalo, não os discos.
O Problema do 'Double Filesystem' e Amplificação de Escrita
O argumento mais forte contra o uso de CephFS para armazenar discos virtuais não é apenas a latência de rede, é a amplificação de escrita e o journaling redundante. Chamamos isso de problema do "Double Filesystem" (Duplo Sistema de Arquivos).
Imagine uma VM rodando um banco de dados PostgreSQL sobre um filesystem EXT4 (Guest), que reside em um arquivo .raw ou .qcow2, que reside em um filesystem CephFS (Host), que reside sobre o RADOS.
Quando o PostgreSQL faz um fsync() para garantir a integridade dos dados:
O EXT4 da VM grava no journal do disco virtual.
O CephFS vê isso como uma alteração no arquivo de imagem.
O CephFS precisa garantir a consistência do seu próprio journal de metadados.
O OSD grava no seu journal (BlueStore WAL).
 Figura: O Problema do 'Double Filesystem': Camadas de abstração matam a performance de escrita
Figura: O Problema do 'Double Filesystem': Camadas de abstração matam a performance de escrita
Você transformou uma escrita lógica em múltiplas escritas físicas e atualizações de metadados em camadas diferentes. O RBD elimina a camada do meio (o filesystem do host), passando os comandos de flush do sistema de arquivos da VM diretamente para o bloco do objeto no OSD.
Overhead de Locking: Por que .qcow2 no CephFS Trava
Além da amplificação, existe o gerenciamento de estado. Arquivos .qcow2 não são estáticos; eles crescem. Se você usa CephFS, o cluster precisa gerenciar locks distribuídos para garantir que dois clientes não corrompam o arquivo.
Mesmo que apenas uma VM acesse o arquivo, o overhead de adquirir e renovar "caps" (capabilities) do MDS para operações de escrita exclusivas gera stalls (pausas) no I/O. Em testes de carga alta, é comum ver o I/O da VM congelar por segundos enquanto o MDS processa uma fila de revogação de caps ou lida com flapping de clientes. No RBD, o lock é gerenciado no nível da sessão do header da imagem, muito mais simples e estático.
Como Medir Performance: Fio, RBD Bench e Métricas Reais
Não confie na minha palavra. A engenharia de performance exige evidência empírica. Para validar a superioridade do RBD sobre o CephFS para virtualização, precisamos isolar o throughput e, principalmente, a latência de cauda (P99).
Ferramenta 1: rbd bench (Baseline do Cluster)
Antes de culpar o filesystem, valide se o cluster entrega blocos rapidamente. Execute diretamente de um nó do cluster ou cliente configurado:
# Teste de escrita (Write) - Mede a capacidade bruta dos OSDs
rbd bench --io-type write --pool <nome_do_pool> image_test --io-size 4M --io-threads 16 --io-total 10G
# Teste de leitura (Read) - Valida cache e leitura de disco
rbd bench --io-type read --pool <nome_do_pool> image_test
Se isso estiver lento, seu problema é rede ou disco físico (OSDs), não o protocolo.
Ferramenta 2: Fio (A Prova Real)
Para comparar CephFS vs RBD, você deve rodar o fio dentro da VM.
Crie duas VMs idênticas (CPU/RAM):
VM A: Disco vda rodando sobre RBD.
VM B: Disco vda sendo um arquivo
.rawmontado via CephFS.
Use este job file para simular um workload de banco de dados (Random R/W 4k, Sync):
[global]
ioengine=libaio
direct=1 # Ignora cache de RAM do Guest (CRÍTICO para teste real)
sync=1 # Força flush a cada escrita
bs=4k # Tamanho de bloco pequeno (pior cenário)
size=1G
runtime=60
time_based
group_reporting
[random-rw-test]
rw=randrw
rwmixread=70 # 70% leitura, 30% escrita
iodepth=1 # Latência sensível
numjobs=1
O que observar nos resultados:
lat (usec): Compare a latência média. O CephFS geralmente apresenta 2x a 3x a latência do RBD em escritas síncronas.
clat (99.00th): A latência de percentil 99. No CephFS, você verá picos (spikes) causados pela negociação com o MDS.
Comparativo Técnico: RBD vs CephFS para VMs
| Característica | RBD (Block Device) | CephFS (File System) |
|---|---|---|
| Caminho de I/O | Direto (Cliente -> OSD) | Indireto (Cliente -> MDS -> OSD) |
| Cache | librbd cache (opcional, local) |
Page Cache do Kernel + MDS Cache |
| Overhead | Mínimo (Cálculo CRUSH) | Alto (POSIX Metadata + Locking) |
| Live Migration | Nativo e eficiente (QEMU/KVM) | Complexo (depende do estado do arquivo) |
| Snapshots | Instantâneos (COW no nível do objeto) | Mais lentos (atravessam hierarquia de dir) |
| Caso de Uso Ideal | Discos de VM, Volumes de Banco de Dados | Compartilhamento de arquivos (NFS-like), Home Dirs |
Veredito Operacional: Quando Usar RBD ou CephFS em Proxmox e OpenStack
A decisão operacional deve ser baseada na função do dado, não na conveniência do administrador.
Use RBD Quando:
Você está provisionando discos de Boot ou Dados para VMs (Proxmox, OpenStack Cinder/Nova).
A aplicação exige baixa latência (Bancos de dados, Filas de mensagens).
Você precisa de funcionalidades avançadas de bloco como Thin Provisioning real e Instant Clones.
Regra de Ouro: Se o dado é exclusivo de uma única VM, deve ser RBD.
Use CephFS Quando:
Você precisa de um "Shared Folder" entre múltiplas VMs (ex:
/var/wwwcompartilhado entre webservers).Você está usando Kubernetes (Manila/CSI) e os pods precisam de acesso RWX (ReadWriteMany).
O dado não é estruturado e acessado por humanos ou scripts legados.
Atenção: Mesmo neste caso, monte o CephFS dentro do sistema operacional da VM, não use o CephFS como backing store para o disco da VM.
Conclusão: Tentar rodar virtualização sobre CephFS é lutar contra a física do sistema. Você paga uma taxa de metadados que não traz benefício algum para um bloco de disco opaco. Para performance, estabilidade e sanidade do seu cluster: mantenha suas VMs no RBD.
Referências & Leitura Complementar
Ceph Documentation - Architecture: Explicação detalhada sobre CRUSH map e fluxo de dados.
VirtIO Specification: Detalhes sobre como drivers paravirtualizados interagem com storage de bloco.
Red Hat Ceph Storage - Performance Tuning Guide: Seção específica sobre tuning de RBD vs CephFS.
"Systems Performance: Enterprise and the Cloud" (Brendan Gregg): Metodologia de isolamento de testes de I/O.

Daniel Siqueira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensor do 'Infrastructure as Code' para storage.