Controladoras Dual Controller Como Evitar Single Point Of Failure

O termo de marketing mais perigoso em armazenamento é "Active-Active". Quando um vendor diz isso, você imagina dois processadores somando forças para dobrar a p...
Controladoras Dual Controller Como Evitar Single Point Of Failure
O termo de marketing mais perigoso em armazenamento é "Active-Active". Quando um vendor diz isso, você imagina dois processadores somando forças para dobrar a performance, certo?
Errado. Na grande maioria dos storages de médio porte (e até alguns enterprise), "Active-Active" refere-se à disponibilidade do chassi, não necessariamente ao acesso ao mesmo LUN (Logical Unit Number).
Imagine um avião com dois pilotos.
- Modelo Active-Passive: O Piloto A voa. O Piloto B dorme. Se A tiver um infarto, B acorda, toma um café, lê os instrumentos e assume. Tempo de inatividade: alto.
- Modelo Symmetric Active-Active (Raro/High-End): Ambos seguram o manche ao mesmo tempo. É complexo, caro e exige uma sincronização absurda.
- Modelo ALUA (O padrão da indústria): O Piloto A controla os motores da esquerda. O Piloto B controla os motores da direita. Ambos estão trabalhando, mas em coisas diferentes.
A maioria dos arrays modernos funciona no modelo 3. A Controladora A é "dona" do LUN 1. A Controladora B é "dona" do LUN 2. Se você tentar escrever no LUN 1 através da Controladora B, ela tem que pedir permissão para a A.
Isso cria uma complexidade de engenharia: Coerência de Cache. Se o servidor escrever dados na Controladora A, e a Controladora A confirmar a gravação (ACK), esses dados estão na RAM da A. Se a Controladora A explodir um milissegundo depois, a Controladora B precisa ter esses dados, ou você acabou de corromper seu banco de dados.
O Pacto de Sangue: Cache Mirroring e Write Penalty
Aqui é onde a performance morre para que a segurança viva. Em um sistema de armazenamento corporativo, a gravação em disco (HDD ou SSD) é lenta demais. O storage sempre mente para o sistema operacional: ele diz "gravação concluída" assim que o dado atinge a RAM (Write-Back Cache).
Mas, para evitar perda de dados em caso de falha da controladora, essa RAM precisa ser espelhada.
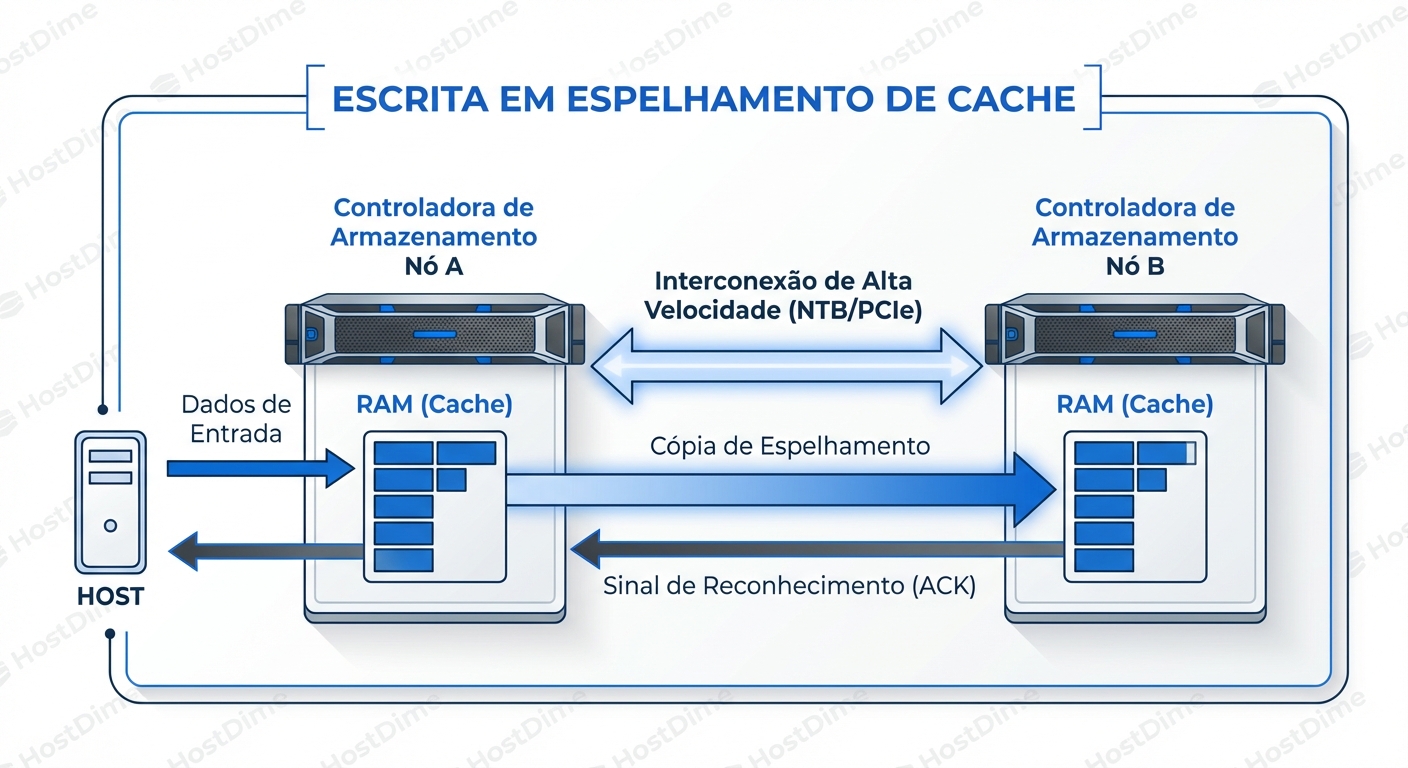
A Dança da Escrita (Write Flow)
Quando seu servidor envia um bloco de dados para ser escrito:
- Ingestão: O dado chega na HBA da Controladora A (a dona do LUN).
- Locking: A Controladora A aloca um espaço na sua memória NVRAM.
- A Ponte (O Gargalo): Antes de responder ao servidor, a Controladora A envia uma cópia desse dado através do Interconnect (geralmente uma ligação PCIe proprietária ou NTB - Non-Transparent Bridge) para a Controladora B.
- Confirmação do Espelho: A Controladora B grava na sua própria RAM e diz "Recebido, chefe".
- Acknowledge: Só agora a Controladora A diz ao servidor "Dado gravado com sucesso".
Se o Interconnect entre as controladoras estiver saturado, com latência alta ou falhando, a performance de escrita do seu array inteiro degrada para a velocidade desse link.
O Perigo do "Write-Through": Se a bateria do cache (BBU) falhar ou o espelhamento cair, o storage entra em modo "Write-Through". Ele para de mentir. Ele só confirma a gravação depois de escrever no disco físico. A performance cai de 50.000 IOPS para 500 IOPS instantaneamente. É um modo de proteção que parece uma falha total para a aplicação.
ALUA: O Guarda de Trânsito Invisível
ALUA significa Asymmetric Logical Unit Access. A palavra chave é Assimétrico.
Em um array ALUA, embora você possa ver o LUN através de todas as portas de todas as controladoras, nem todos os caminhos são iguais.
- Caminhos Otimizados (Active/Optimized): São os caminhos conectados diretamente à controladora que "possui" o LUN. O I/O vai direto para a memória e processador corretos.
- Caminhos Não-Otimizados (Active/Non-Optimized): São os caminhos conectados à outra controladora. Se o I/O chegar aqui, essa controladora age como um proxy, enviando os dados pelo Interconnect para a dona real.
O Cenário de Pesadelo (LUN Thrashing): Se você configurar seu servidor incorretamente (ex: Round-Robin sem considerar ALUA), o servidor pode enviar o Pacote 1 para a Controladora A e o Pacote 2 para a Controladora B. O storage percebe que a Controladora B está recebendo muito tráfego e decide: "Ei, vamos mover a posse desse LUN para a B". Segundos depois, o servidor manda tráfego para a A. O storage move a posse de volta para a A. Isso se chama Ping-Pong Effect ou LUN Thrashing. O resultado é latência maciça e timeouts, pois o storage gasta mais tempo movendo a posse do LUN do que gravando dados.
| Estado do Caminho | Latência | Comportamento Interno | Uso Recomendado |
|---|---|---|---|
| Active/Optimized | Baixa (<1ms) | Acesso direto à CPU/Cache proprietária. | Tráfego Normal. |
| Active/Non-Optimized | Média/Alta | Proxy via Interconnect (latência extra). | Apenas se os caminhos otimizados falharem. |
| Standby | N/A | Porta ativa, mas não aceita I/O (rejeita com SCSI Check Condition). | Storages Active-Passive antigos. |
| Dead/Failed | Infinita | Cabo desconectado ou porta queimada. | Nunca. |
Anatomia Física: Construindo a Imunidade
Você não pode configurar software para corrigir um design físico ruim. A redundância física é a base sobre a qual o ALUA e o Multipath operam.
Muitos administradores conectam a HBA 1 do servidor no Switch 1 e a HBA 2 no Switch 2. Ótimo. Mas aí conectam todas as portas do Switch 1 na Controladora A e todas do Switch 2 na Controladora B.
Se o Switch 1 falhar, você perdeu acesso direto à Controladora A. Se a Controladora A era dona dos LUNs críticos, todo o tráfego agora vai para a Controladora B (caminho não-otimizado), sobrecarregando o Interconnect.
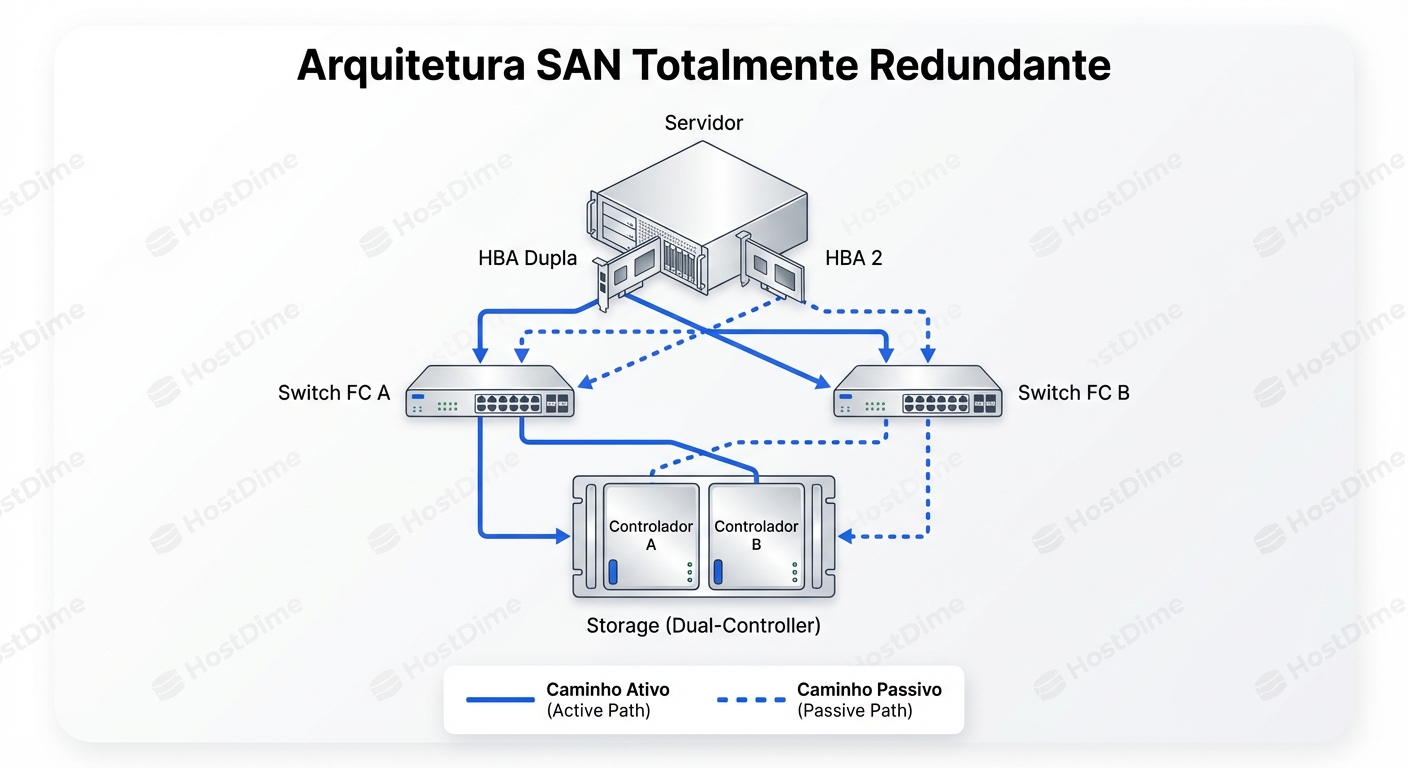
A regra de ouro é o Cruzamento Total (Cross-Looping):
- Servidor HBA 1 -> Switch A
- Servidor HBA 2 -> Switch B
- Switch A -> Controladora A (Porta 1) E Controladora B (Porta 1)
- Switch B -> Controladora A (Porta 2) E Controladora B (Porta 2)
Isso garante que, se qualquer componente único falhar (uma HBA, um cabo, um switch, ou uma controladora inteira), ainda existe um caminho físico viável do servidor até a controladora sobrevivente.
O Cérebro do Host: Multipathing (DM-Multipath & MPIO)
O storage pode ser brilhante, mas o Sistema Operacional é burro. Sem software de multipath, o Linux vê 4 caminhos para o mesmo LUN como 4 discos diferentes (/dev/sdb, /dev/sdc, /dev/sdd, /dev/sde). Se você montar /dev/sdb e o caminho cair, o SO não sabe pular para o /dev/sdc. Ele simplesmente retorna erro de I/O.
O Device Mapper Multipath (DM-Multipath) no Linux ou MPIO no Windows agrupa esses caminhos físicos em um único dispositivo lógico (ex: /dev/mapper/mpatha).
Diagnosticando no Linux: Lendo a Matrix
O comando multipath -ll é seu estetoscópio. Vamos analisar uma saída real e saudável de um storage ALUA:
mpatha (36006016088d0380018692d9c0225e511) dm-0 DGC,VRAID
size=100G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:0 sdb 8:16 active ready running
| `- 2:0:0:0 sdd 8:48 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:0 sdc 8:32 active ready running
`- 2:0:1:0 sde 8:64 active ready running
Como ler isso como um SRE:
hwhandler='1 alua': O kernel detectou corretamente que o storage fala ALUA. Se isso estiver "0" ou algo genérico, verifique o/etc/multipath.conf.- Grupos de Prioridade (
prio):- O primeiro grupo tem
prio=50estatus=active. Estes são seus caminhos Otimizados. O kernel prefere estes. - O segundo grupo tem
prio=10estatus=enabled. Estes são os caminhos Não-Otimizados. Eles estão prontos (ready running), mas o kernel só os usará se o primeiro grupo morrer.
- O primeiro grupo tem
- Policy (
service-time 0): Isso é crucial. Antigamente usávamosround-robin. Hoje,service-time(ouqueue-length) é superior. Oround-robincego envia I/O para um caminho que pode estar engasgado. Oservice-timeenvia para o caminho que está respondendo mais rápido agora.
O Perigo do queue_if_no_path
Note a flag features='1 queue_if_no_path'.
Isso significa: "Se todos os caminhos caírem, não retorne erro para a aplicação. Segure o I/O na memória (queue) e espere os caminhos voltarem."
O Lado Bom: Um reboot rápido do switch não crasha o banco de dados. O I/O congela por 10 segundos e volta.
O Lado Ruim: Se o storage morrer de vez, seu servidor Linux vai travar (hang) indefinidamente tentando escrever, porque nunca recebe um erro. O load average vai para o infinito.
A Correção: Use no_path_retry N. Tente N vezes, depois falhe. É melhor o app cair e o cluster de HA assumir do que o servidor ficar zumbi.
Split-Brain: Quando as Cabeças Batem
O que acontece se o cabo de Interconnect entre as controladoras for cortado, mas ambas as controladoras continuarem vivas?
Este é o cenário de Split-Brain. A Controladora A pensa: "A B morreu. Eu assumo tudo." A Controladora B pensa: "A A morreu. Eu assumo tudo."
Ambas tentam gravar nos mesmos metadados do disco ao mesmo tempo. Resultado: Corrupção catastrófica do sistema de arquivos do storage.
Para evitar isso, storages enterprise usam mecanismos de Fencing ou Quorum:
- Disco de Quorum: Um lugar no disco que ambas leem. "Eu estou viva, se você ler isso, recue."
- STONITH (Shoot The Other Node In The Head): Se a Controladora A detectar falha de comunicação, ela corta a energia da Controladora B via backplane antes de assumir os LUNs. É brutal, mas necessário.
Se você vir logs de "SCSI Reservation Conflict" recorrentes, é um sinal de que o mecanismo de arbitragem de posse está lutando. Investigue o interconnect imediatamente.
Diagnóstico de Combate: Comandos e Sinais
Não espere o vendor te ligar. Aqui está como verificar a saúde da sua redundância.
No Linux
1. Verificar caminhos trêmulos (Flapping Paths):
O dmesg é seu amigo.
dmesg | grep "path.*failed"
Se você vir muitas mensagens de falha e reintegração (reinstating path) em curtos períodos, você tem um cabo de fibra ruim ou uma porta SFP degradada. Isso causa latência intermitente que o monitoramento de média (como Zabbix) não pega.
2. Verificar desbalanceamento de I/O:
iostat -x -p /dev/dm-0 1
Olhe para a coluna %util e await. Se os caminhos físicos subjacentes (sdb, sdd) tiverem latências drasticamente diferentes, você pode ter um problema de "Slow Drain" na SAN (um dispositivo lento afetando a porta do switch).
No Windows
Use o PowerShell para verificar se o MPIO está realmente equilibrando a carga ou se está usando apenas um caminho.
Get-MPIODisk -LunId 1 | Select-Object -ExpandProperty Paths
Verifique o PathState. Se todos estiverem Active/Active mas apenas um tiver NumberReads incrementando, sua política de balanceamento (Load Balance Policy) pode estar configurada como Failover Only em vez de Round Robin ou Least Queue Depth.
O Veredito: Confie, mas Verifique (Brutalmente)
Ter duas controladoras não é uma apólice de seguro; é um contrato de manutenção que exige supervisão constante. A redundância real vive nos detalhes sujos: na integridade do espelhamento de cache, na configuração correta do ALUA e na disciplina do cabeamento físico.
O teste final não é olhar para as luzes verdes no dashboard. O teste final é agendar uma janela de manutenção, ir até o datacenter e puxar fisicamente um cabo de fibra (ou o cabo de interconnect, se você for corajoso) durante uma carga de trabalho de teste.
Se o seu I/O pausar por 5 segundos e continuar, parabéns. Se o seu servidor entrar em kernel panic ou o banco corromper, você descobriu um SPOF lógico antes que ele te acordasse às 3 da manhã.
A tecnologia falha. A redundância complexa falha de formas complexas. Seu trabalho não é impedir a falha, é garantir que o sistema sobreviva a ela com elegância.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.