Crise de Hardware 2025: Estratégias de Sobrevivência para a Alta de SSDs e RAM
A demanda por IA está canibalizando a produção de NAND e DRAM. Entenda por que os preços vão triplicar e como auditar, otimizar e comprar storage de forma inteligente durante a escassez.
Se você abriu a cotação de hardware para o refresh de 2025 e sentiu um frio na espinha, você não está sozinho. O "novo normal" do mercado de semicondutores não é apenas uma flutuação inflacionária; é uma mudança estrutural na física da produção. O orçamento que comprava 1TB de RAM e 100TB de NVMe em 2023 agora mal cobre a metade disso.
A era do "adicione mais hardware até o problema sumir" acabou. Para o Sysadmin veterano, isso significa voltar às raízes: entender o que o sistema realmente está fazendo, em vez de confiar no que o fornecedor diz que ele deveria fazer. Vamos cortar o hype da IA e olhar para os números frios da infraestrutura.
A Crise de Hardware de 2025 é um fenômeno de escassez de manufatura onde as fundições de semicondutores (Fabs) priorizam a produção de memória de alta margem (HBM) para aceleradores de IA em detrimento da DRAM e NAND commodity. Para sobreviver, equipes de operações devem transicionar de uma filosofia de "superdimensionamento preventivo" para "auditoria forense de recursos", utilizando compressão de memória (ZRAM), tiering de armazenamento agressivo e hardware enterprise recondicionado.
A Física da Escassez: Como a "Guerra dos Wafers" impacta seu Datacenter
Para entender por que seu SSD subiu 40% de preço, você precisa ignorar o vendedor e olhar para a fábrica. Uma fundição de silício (Fab) tem uma capacidade finita de wafers por mês. Não se constrói uma Fab nova em seis meses; leva-se cinco anos.
O problema é físico: a área de silício que antes era usada para imprimir chips de memória DDR5 padrão e NAND Flash barata agora está sendo canibalizada para produzir HBM (High Bandwidth Memory) para GPUs da Nvidia e TPUs. A HBM é mais complexa, ocupa mais espaço no wafer e tem uma margem de lucro obscenamente maior.
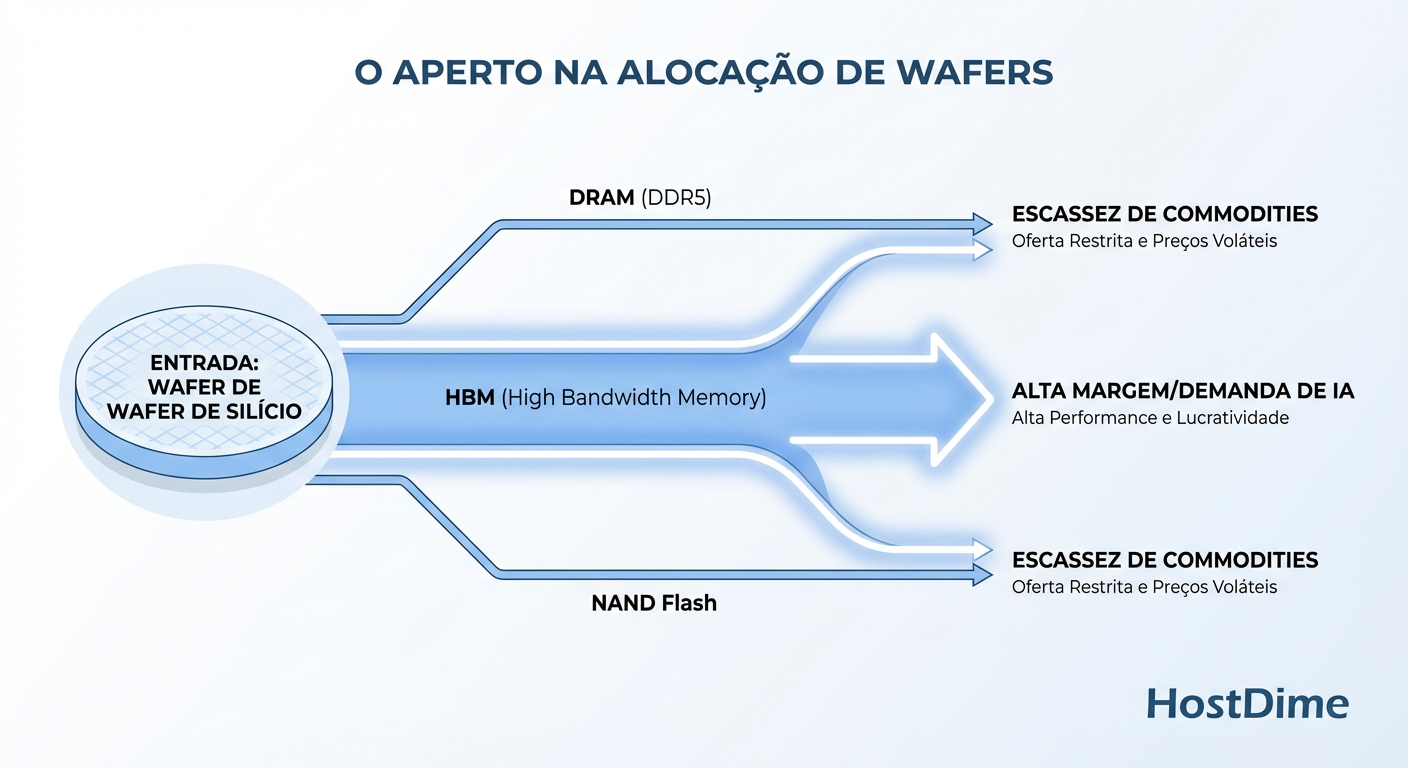 Figura: A Guerra dos Wafers: Como a priorização da memória HBM para IA canibaliza fisicamente a produção de DRAM e NAND para o resto do mercado.
Figura: A Guerra dos Wafers: Como a priorização da memória HBM para IA canibaliza fisicamente a produção de DRAM e NAND para o resto do mercado.
Para a Samsung, SK Hynix e Micron, a escolha é óbvia: vender silício para IA a peso de ouro ou vender DDR5 para seu servidor web a preço de banana? O resultado é uma restrição artificial de oferta no mercado commodity. Se você está planejando comprar hardware novo, entenda que você está competindo por recursos físicos contra os orçamentos infinitos das Big Techs de IA. Você vai perder essa briga de preços. A saída é a eficiência.
Auditoria Forense de I/O: Provando que você não precisa de hardware novo
Antes de assinar qualquer pedido de compra, adote a postura de um médico legista. A maioria dos servidores que alegam estar "sem memória" ou com "disco lento" estão, na verdade, sofrendo de má configuração de software ou vazamento de recursos.
O método de Brendan Gregg (USE Method - Utilization, Saturation, Errors) é sua arma aqui. Não aceite "o sistema está lento". Exija métricas.
1. A Falácia do "Disco Lento"
Muitos administradores veem uma latência alta e pedem SSDs mais rápidos. Errado. Primeiro, verifique se você está limitado por IOPS ou por Throughput. E mais importante: verifique a fila.
Use o iostat (do pacote sysstat) para ver a verdade nua e crua:
iostat -xzm 1
O que procurar na coluna %util e avgqu-sz (Average Queue Size):
Se
%utilestá em 100% mas o throughput (r/s, w/s) é baixo, você tem um padrão de acesso randômico brutal (banco de dados sem índice, logs malucos). SSDs NVMe mais rápidos ajudam, mas corrigir a aplicação resolve de graça.Se
avgqu-szé alto, seu disco não consegue limpar os pedidos rápido o suficiente. Isso é saturação real.
2. A Ilusão da Memória "Livre"
O Linux odeia memória livre. Ele usará tudo o que puder para cache de página. Ferramentas de monitoramento ingênuas mostram "90% de RAM usada" e o gerente entra em pânico.
Você precisa saber o tamanho do Working Set (o conjunto de dados que a aplicação realmente toca com frequência). Use o vmtouch para descobrir quanto dos seus arquivos estão realmente na memória:
# Quanto do arquivo de banco de dados está na RAM agora?
vmtouch -v /var/lib/mysql/ibdata1
Se o seu banco de dados tem 500GB, mas o vmtouch mostra que apenas 4GB estão "residentes" (em cache) e o sistema não está fazendo swap, você não precisa de mais RAM. Você tem um Working Set pequeno. Comprar 1TB de RAM seria jogar dinheiro no lixo para armazenar dados frios que nunca são lidos.
Estratégias de Mitigação de RAM: ZRAM e Tuning de ARC
Se você auditou e realmente está sem memória, e o preço da DDR5 está proibitivo, troque CPU por Capacidade.
ZRAM: A Salvação dos Pobres (e Inteligentes)
O ZRAM cria um dispositivo de bloco na RAM que atua como swap, mas comprime os dados em tempo real (usando lz4 ou zstd).
A Troca: Você gasta ciclos de CPU (que geralmente sobram em servidores modernos) para comprimir dados.
O Ganho: Uma taxa de compressão de 2:1 ou 3:1 efetivamente dobra sua RAM para dados inativos.
Em 2025, ativar o ZRAM deve ser padrão em qualquer servidor web, container host ou hypervisor que não rode bancos de dados in-memory massivos.
ZFS ARC: O Devorador Silencioso
Se você usa ZFS (TrueNAS, Proxmox, Ubuntu), o ARC (Adaptive Replacement Cache) por padrão tentará usar 50% da sua RAM. Em um servidor de virtualização, isso é suicídio. O ZFS acha que é a única coisa rodando na máquina.
Não deixe o ZFS decidir. Limite o ARC. Se você tem SSDs rápidos (L2ARC ou apenas pools rápidos), você precisa de menos RAM para cache do que imagina.
# Exemplo: Limitar ARC a 4GB (em bytes)
echo "4294967296" > /sys/module/zfs/parameters/zfs_arc_max
Dica Pragmática: Monitore o arc_summary. Se o "Cache Hit Ratio" for 98% com 64GB de ARC e continuar 97.5% com 8GB de ARC, você acabou de liberar 56GB de RAM para VMs sem gastar um centavo.
O Dilema da Densidade: QLC Enterprise vs. TLC Usado
Aqui entra a decisão de compra difícil. O mercado está empurrando SSDs QLC (Quad-Level Cell) como a solução para densidade. O problema? A durabilidade (DWPD - Drive Writes Per Day) e a performance após o esgotamento do cache SLC.
Por outro lado, o mercado de usados está inundado de SSDs Enterprise TLC (Triple-Level Cell) de 2-3 anos atrás, vindos de hyperscalers que fazem refresh cíclico.
 Figura: Matriz de Decisão de Compra 2025: Onde alocar orçamento quando o preço do Gigabyte triplica. Note o papel do QLC e do hardware usado.
Figura: Matriz de Decisão de Compra 2025: Onde alocar orçamento quando o preço do Gigabyte triplica. Note o papel do QLC e do hardware usado.
Matriz de Decisão: O que comprar em 2025?
Use esta tabela para guiar sua compra, ignorando o marketing da embalagem:
| Característica | SSD Consumer Novo (TLC/QLC) | SSD Enterprise QLC Novo (Ex: Solidigm) | SSD Enterprise TLC Usado (Ex: Intel DC/Micron) |
|---|---|---|---|
| Custo por TB | Baixo | Médio | Muito Baixo |
| Endurance (DWPD) | 0.3 - 0.6 (Pífio) | 0.5 - 1.0 (Aceitável p/ Leitura) | 1.0 - 3.0 (Tanque de Guerra) |
| Latência sob Carga | Errática (picos altos) | Consistente (até encher o buffer) | Consistente e Baixa |
| Proteção de Energia | Inexistente (PLP) | Completa | Completa |
| Risco Principal | Morte súbita por escrita | Performance de escrita sustentada | Vida útil restante (Smart check) |
| Caso de Uso | Boot, Workstations | Data Lakes, Backups, CDNs | VMs, Bancos de Dados, ZFS SLOG |
Callout de Risco: Jamais use SSDs Consumer (mesmo os "Pro") em arranjos ZFS ou RAID via software pesados sem entender o impacto da falta de Power Loss Protection (PLP). O ZFS vai forçar sync writes, e a performance do seu SSD gamer de 7000MB/s vai cair para 50MB/s. SSDs Enterprise usados com PLP, mesmo antigos, destruirão SSDs novos consumer em sync writes.
O Fim do Overprovisioning Preguiçoso
Até 2023, era comum criar uma VM para um servidor web simples e alocar: 4 vCPUs, 16GB RAM, 100GB Disco. Por quê? "Só para garantir".
Em 2025, isso é negligência financeira. O custo do desperdício triplicou.
Thin Provisioning é Obrigatório: Se o SO ocupa 5GB, não aloque 100GB "thick". O armazenamento backend deve ser inteligente.
Dimensionamento Just-in-Time: Comece com o mínimo viável. Uma VM Linux moderna roda bem com 2GB de RAM para muitas tarefas. Aumente se o monitoramento (ver seção 2) indicar pressão de memória.
Limpeza de Dados: Logs antigos, backups esquecidos em
/tmp, imagens de Docker órfãs (docker system prune). A higiene de dados libera terabytes.
Resumo Operacional
Não lute contra a física da escassez com o cartão de crédito da empresa; você vai perder. Lute com inteligência. Meça antes de comprar, otimize o que já tem e não tenha medo de comprar hardware enterprise usado para cargas de trabalho críticas. O "novo" hardware consumer é frágil demais para a crise atual.
Referências & Leitura Complementar
JEDEC Standard No. 79-5C (DDR5 SDRAM): Para entender as especificações físicas e latências reais da memória atual.
Gregg, Brendan. "Systems Performance: Enterprise and the Cloud, 2nd Edition": A bíblia da metodologia USE e auditoria de performance.
OpenZFS Documentation (ARC & Tuning): Detalhes técnicos sobre como o cache do ZFS gerencia pressão de memória.
Solidigm/Intel Technology Briefs on QLC vs TLC: Whitepapers técnicos detalhando as curvas de latência de escrita em drives de alta densidade (D5/D7 series).
RFC 3720 (iSCSI) & NVMe-oF Specs: Para entender os overheads de protocolo em storage remoto.

Bruno Azevedo
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.