Dcbpfcets Ethernet Sem Perdas E Controversias

Para entender o DCB e o PFC, precisamos primeiro ajustar nosso modelo mental sobre como redes funcionam....
Dcbpfcets Ethernet Sem Perdas E Controversias
O Grande Engodo: "Sem Perdas" não existe
Para entender o DCB e o PFC, precisamos primeiro ajustar nosso modelo mental sobre como redes funcionam.
Na Ethernet clássica (TCP/IP), a rede é considerada não confiável. Se um switch recebe mais pacotes do que consegue processar ou enviar, ele simplesmente os descarta (drop). O buffer enche, o pacote vai para o lixo. O TCP, rodando no servidor, percebe a falta do pacote, reduz a velocidade de transmissão (janela de congestionamento) e reenvia o dado. É robusto, mas custoso em latência e CPU.
Com a ascensão do RDMA (Remote Direct Memory Access) — especificamente RoCEv2 (RDMA over Converged Ethernet) — mudamos a premissa. O RDMA permite que uma aplicação grave dados diretamente na memória de outra máquina, ignorando a CPU e o kernel. É incrivelmente rápido (microssegundos de latência).
Porém, o RDMA nasceu do InfiniBand, uma tecnologia desenhada para nunca perder pacotes. Quando trazemos o RDMA para a Ethernet, temos um problema: o protocolo de transporte do RDMA é frágil. Se ele perder pacotes, ele entra em um estado de recuperação de erro que destrói a performance.
Para fazer o RDMA funcionar na Ethernet, tivemos que mentir para ele. Tivemos que prometer: "Não se preocupe, a Ethernet agora é confiável. Nunca descartaremos um pacote seu".
Para cumprir essa promessa, criamos o PFC (Priority Flow Control - IEEE 802.1Qbb).
O Sinal de "Pare" Granular
Imagine uma rodovia. Na Ethernet clássica, se há um engarrafamento, os carros excedentes são jogados de um penhasco (drop). No Ethernet Lossless com PFC, colocamos um guarda de trânsito que levanta uma placa de "PARE" para os carros que estão vindo antes que o engarrafamento se torne crítico.
Mas aqui está a diferença crucial: o antigo "Pause Frames" (802.3x) parava toda a rodovia. Se o tráfego de Storage estava congestionado, o tráfego de SSH, Web e Banco de Dados também parava.
O PFC é cirúrgico. Ele divide o link físico em 8 faixas virtuais (Classes de Serviço ou CoS, numeradas de 0 a 7). Ele pode enviar um sinal de pausa apenas para a "Faixa 3" (onde roda o RDMA/Storage), deixando as outras faixas fluírem livremente.
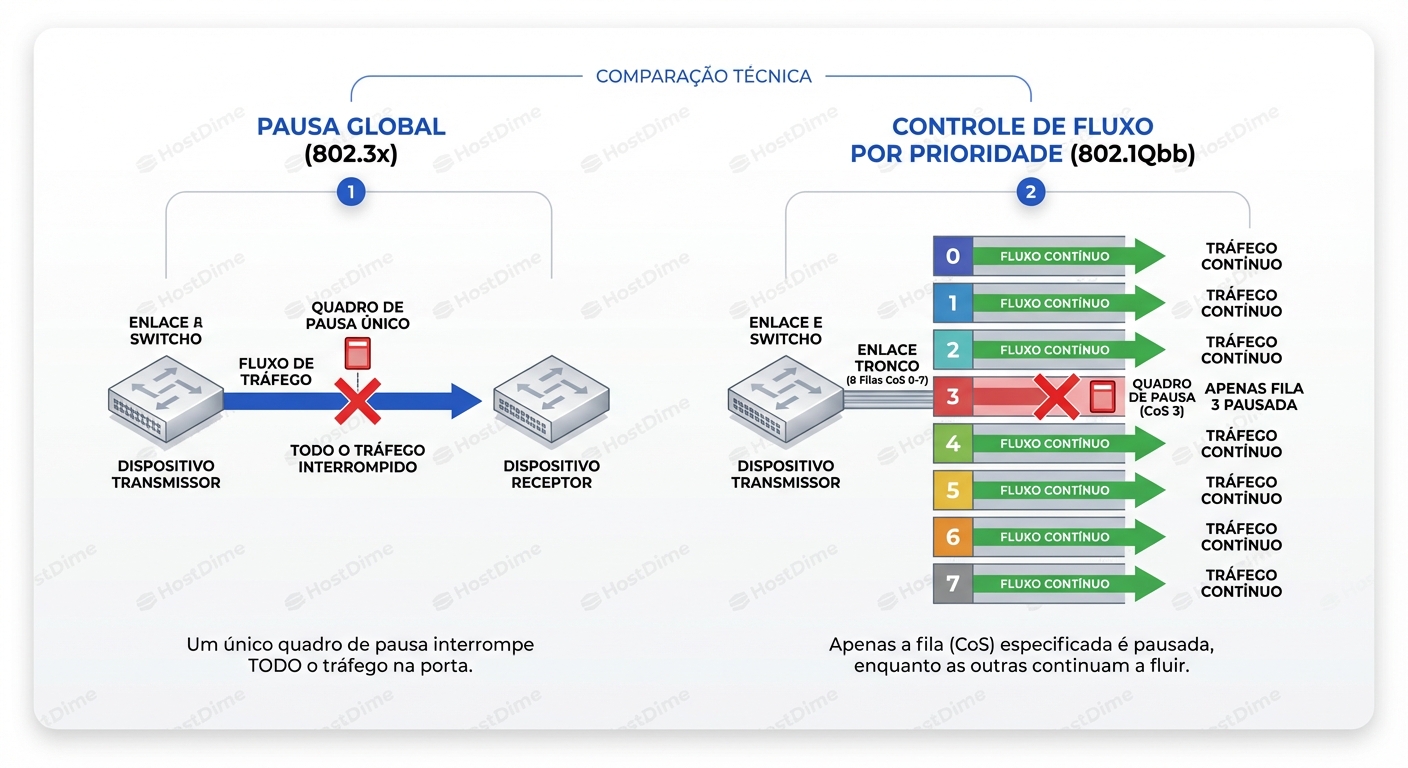
Este diagrama acima é fundamental para visualizar a diferença. À esquerda, o método antigo (bruto). À direita, o PFC. O link físico continua transmitindo (setas verdes), exceto pela fila específica que está congestionada (o 'X' vermelho). Isso é feito enviando um frame especial de controle de volta para o emissor dizendo: "Pare de enviar tráfego na Prioridade 3 por X microssegundos".
Parece perfeito, certo? Resolvemos o problema da perda de pacotes e mantivemos as outras aplicações rodando.
O problema é que transformamos a perda de pacotes em latência de enfileiramento. E quando você empurra o problema para trás, ele acumula.
A Trindade do DCB: PFC, ETS e DCBX
Antes de vermos como tudo quebra, precisamos entender as peças do quebra-cabeça. DCB (Data Center Bridging) não é um protocolo, é um conjunto de extensões.
- PFC (802.1Qbb): O mecanismo de contrapressão. Evita drops pausando o emissor.
- ETS (Enhanced Transmission Selection - 802.1Qaz): O gerenciador de largura de banda. O PFC evita drops, mas o ETS garante que o tráfego de Storage tenha, digamos, 50% da banda garantida, enquanto o tráfego de LAN tem 20%, mesmo que não haja congestionamento para gerar pausas. Sem ETS, o PFC poderia pausar indefinidamente uma classe de baixa prioridade se uma de alta prioridade tomasse todo o link.
- DCBX (Data Center Bridging Exchange): O diplomata. Ele usa o protocolo LLDP para que o switch e o servidor (NIC) negociem: "Ei, eu estou configurado para usar PFC na CoS 3 e ETS com 50% de banda. Você concorda?".
Atenção Sysadmin: O DCBX é a causa número 1 de dores de cabeça na configuração inicial. Se o switch acha que a CoS 3 é "Lossless" e a placa de rede acha que é "Lossy" (normal), o switch nunca enviará PAUSE frames, os buffers estourarão e o RDMA falhará silenciosamente. Ou pior, a NIC enviará PAUSE e o switch ignorará.
Anatomia de um Desastre: Head-of-Line Blocking e Propagação
Aqui entramos no "lado sombrio" que os vendedores de hardware raramente explicam nos slides de PowerPoint.
O PFC cria um sistema de dependência. Se o Switch B está cheio, ele manda o Switch A pausar. Se o Switch A não consegue esvaziar seu buffer porque parou de enviar para B, o buffer de A enche. Então A manda o Servidor X pausar.
Isso é chamado de Congestion Spreading (Propagação de Congestionamento). O congestionamento viaja "para trás", da destino até a origem.
O Cenário da Vítima Inocente
Imagine uma topologia Leaf-Spine.
- O Receiver R1 (ligado ao Leaf 1) está lento processando dados.
- O Leaf 1 enche seu buffer de entrada para a Prioridade 3.
- O Leaf 1 envia um PFC PAUSE para o Spine 1.
- O Spine 1 para de enviar dados para o Leaf 1 na Prioridade 3.
- O buffer do Spine 1 enche rapidamente.
- O Spine 1 envia PFC PAUSE para todos os outros Leafs que estão enviando dados para ele na Prioridade 3 (digamos, Leaf 2 e Leaf 3).
Agora, imagine o Sender S2 (ligado ao Leaf 2). Ele quer enviar dados para o Receiver R2 (ligado ao Leaf 3). Eles não têm nada a ver com o Receiver R1 lento. Mas, como o tráfego deles passa pelo Spine 1 (que está pausado por causa do R1), o tráfego de S2 para R2 para.
Isso é o Head-of-Line Blocking em escala de fabric. Um nó lento pode sequestrar a performance de todo o cluster.
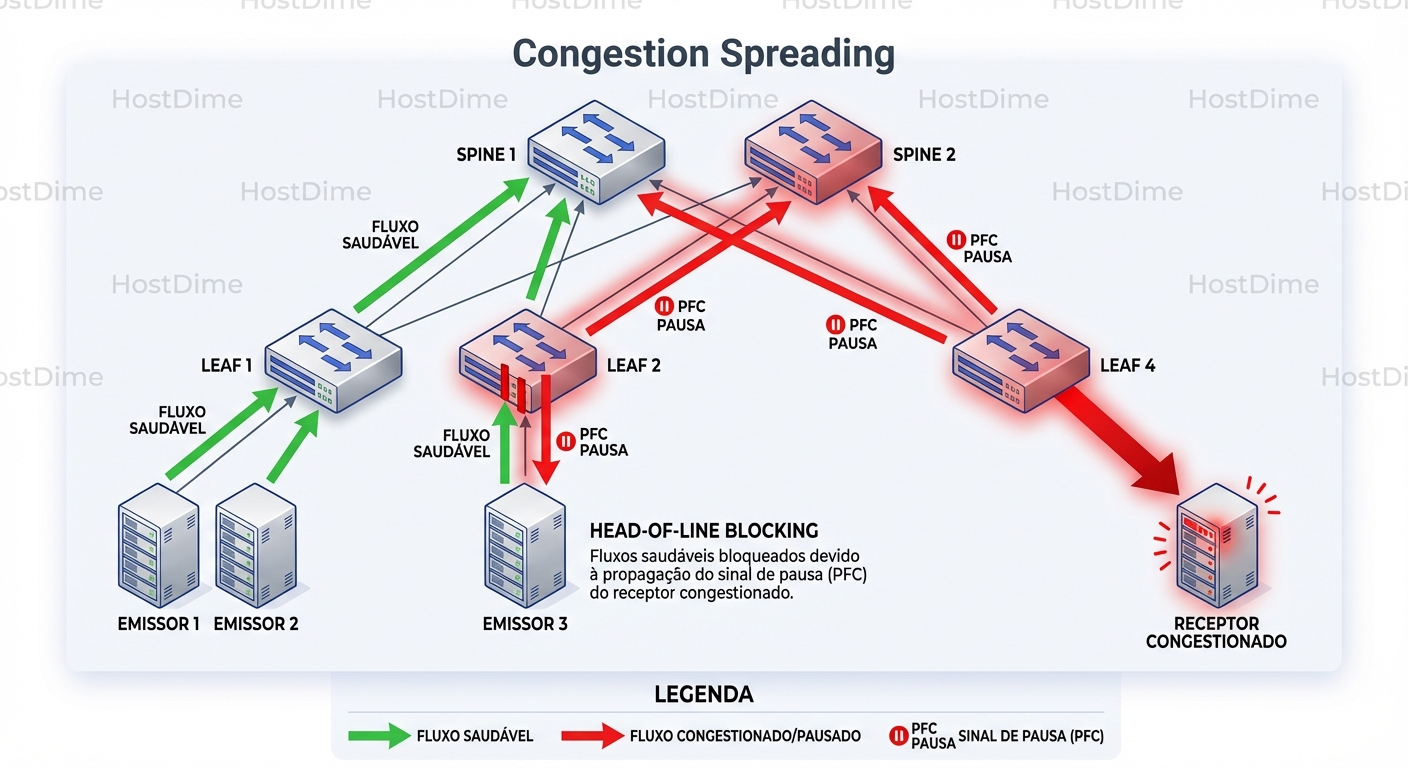
A imagem acima ilustra esse efeito dominó. O congestionamento no canto inferior direito se propaga para cima (setas vermelhas de PFC), infectando o Spine, que por sua vez bloqueia fluxos saudáveis (à esquerda) que apenas tiveram o azar de compartilhar o mesmo caminho e classe de serviço.
O Deadlock (A Morte Silenciosa)
O cenário piora. Em topologias complexas com roteamento dinâmico ou loops acidentais, você pode criar um Deadlock Circular de PFC.
- Switch A espera buffer liberar no Switch B.
- Switch B espera buffer liberar no Switch C.
- Switch C espera buffer liberar no Switch A.
Ninguém se move. O tráfego para perpetuamente. Não há perda de pacotes, apenas silêncio. A única saída é um reboot ou um mecanismo de segurança chamado "Watchdog" (que veremos adiante) que detecta isso e, ironicamente, descarta todos os pacotes para destravar a rede.
Diagnóstico: Como saber se o PFC está te matando?
Você não vai ver isso no top ou no htop. Você precisa descer ao nível da interface e dos contadores do ASIC.
No Linux (Host Side)
O comando ethtool -S é seu melhor amigo, mas você precisa saber o que filtrar. A saída varia conforme o driver (Mellanox/NVIDIA, Intel, Broadcom), mas os padrões são similares.
ethtool -S ens785f0 | grep -E "prio[0-9]+_pause|rx_pause|tx_pause"
O que procurar:
| Contador | Interpretação | Veredito |
|---|---|---|
rx_pause_frames (ou rx_prio3_pause) |
O switch está mandando seu servidor CALAR A BOCA. | O Problema é a Rede. O switch (ou alguém depois dele) está congestionado. Seu servidor está pronto para enviar, mas é impedido. |
tx_pause_frames (ou tx_prio3_pause) |
Seu servidor está mandando o switch PARAR. | O Problema é Você. Seu servidor não está processando os pacotes rápido o suficiente (CPU alta, gargalo de PCIe, app travado). Você está enchendo o buffer da NIC e pedindo clemência. |
rx_pause_duration |
Tempo total (em microsegundos) que a porta ficou pausada. | Se este número cresce rápido, sua latência efetiva está explodindo. |
Cenário Real: Se você vê milhões de rx_pause_frames incrementando por segundo em todos os nós de um cluster, você tem uma tempestade de PFC. A origem (o nó lento) provavelmente terá tx_pause_frames altos ou, contraintuitivamente, nenhum erro, pois ele é o "buraco negro" que está lento mas não pausado.
No Switch (Exemplo Arista/Cisco Nexus)
Nos switches, precisamos olhar para os contadores de fila e, crucialmente, para os descartes do Watchdog.
# Arista EOS
show priority-flow-control
show interfaces counters queue | grep -i drop
show platform trident mmu monitor # (Para ASICs Broadcom Trident/Tomahawk)
Sinais de Perigo:
- Ingress Drops em filas Lossless: Se você configurou PFC, teoricamente não deveria haver drops. Se você vê drops na fila de RoCE (ex: Queue 3), significa que o buffer físico do switch estourou antes que o PFC pudesse agir, ou o PFC Watchdog entrou em ação.
- PFC Watchdog Drops: Este é o contador mais importante em redes modernas. O Watchdog é um temporizador. Se uma fila fica pausada por muito tempo (ex: 500ms), o switch assume que há um deadlock e purga a fila inteira.
- Comando:
show priority-flow-control watchdog - Se este contador > 0, você teve um evento catastrófico onde a rede "sem perdas" jogou dados fora para se salvar.
- Comando:
Buffer Tuning: Onde a mágica (e o erro) acontece
Uma das maiores falácias é achar que habilitar pfc=on resolve tudo. O segredo está na alocação de buffers do switch (MMU - Memory Management Unit).
Um switch tem uma quantidade finita de memória para buffers (ex: 32MB ou 64MB num chip Tomahawk). Esse buffer é dividido em:
- Guaranteed: Reservado para cada porta/fila.
- Shared: Piscina comum para picos de tráfego.
- Headroom: Espaço de emergência exclusivo para tráfego Lossless.
O Modelo Mental do Headroom: Quando o switch envia um frame PAUSE para o vizinho, o vizinho não para instantaneamente. Existe o tempo de propagação da luz na fibra + tempo de processamento do ASIC. Durante esse tempo ("Round Trip Time"), dados continuam chegando. O buffer de Headroom é o "airbag". Ele precisa ser grande o suficiente para absorver os dados que chegam enquanto o freio está sendo acionado.
Se você usa cabos longos (ex: 100m ou 300m) e deixa a configuração padrão de headroom (feita para cabos DAC de 3m), o buffer estourará antes do tráfego parar. Resultado: Perda de pacotes em uma rede configurada para não ter perdas. O RDMA cai, a performance despenca.
Ação: Verifique a configuração de cable-length ou perfis de buffer no seu switch se tiver links longos entre switches.
ECN (Explicit Congestion Notification): A Alternativa Suave
Dado o perigo dos PFC Storms, a indústria (liderada pelos Hyperscalers como Microsoft e Google) moveu-se para um modelo híbrido: DCQCN (Data Center Quantized Congestion Notification).
A ideia é simples: PFC é um freio de mão (Binário: Pare/Siga). ECN é um acelerador suave (Analógico: Desacelere).
Com ECN, quando o buffer do switch começa a encher (digamos, 30%), ele não manda parar. Ele marca um bit no cabeçalho IP do pacote (o bit CE - Congestion Experienced). Quando o receptor vê esse bit, ele avisa o emissor (via CNP - Congestion Notification Packet) para reduzir a velocidade de transmissão.
A Regra de Ouro: O ECN deve agir antes do PFC.
- Limiar ECN (marcar pacote): 30KB de buffer usado.
- Limiar PFC (pausar link): 100KB de buffer usado.
Se configurado corretamente, o emissores reduzem a velocidade suavemente e o PFC nunca é acionado. O PFC fica lá apenas como um seguro de vida catastrófico para micro-bursts que o ECN não conseguiu capturar a tempo.
Se você vê contadores de PFC subindo em uma rede com ECN habilitado, sua configuração de ECN está muito frouxa ou o tráfego é agressivo demais (Incast).
Comparativo de Estratégias
| Característica | TCP/IP Clássico | RDMA com PFC (Lossless) | RDMA com ECN + PFC (DCQCN) |
|---|---|---|---|
| Mecanismo de Controle | Drop de Pacotes | Pause Frames (Stop/Go) | Marcação de Pacotes (Slow Down) |
| Resposta ao Congestionamento | Reativa (após perda) | Proativa (antes da perda) | Proativa (sinalização suave) |
| Risco Principal | Latência alta, Jitter | Deadlocks, Head-of-Line Blocking | Complexidade de Tuning |
| Uso de CPU | Alto | Quase Zero (Offload) | Quase Zero (Offload) |
| Cenário Ideal | Web, App, Genérico | Storage Dedicado, Pequenos Clusters | Hyperscale, AI/ML Training Clusters |
Veredito: Você deve usar PFC?
A resposta, como sempre em engenharia, é: depende da sua escala e tolerância à dor.
Use PFC se:
- Você tem um cluster de Storage NVMe-oF ou um cluster de HPC/AI pequeno/médio isolado.
- Você controla tanto a rede quanto os end-hosts (pode configurar DCB/QoS em ambos).
- Você tem baixa tolerância a latência de cauda (tail latency).
Evite ou Tenha Cuidado Extremo se:
- Você está rodando isso em uma rede compartilhada com tráfego corporativo geral (o risco de um servidor mal configurado parar sua rede LAN é real).
- Você opera em escala massiva (milhares de nós). Nesse nível, o Congestion Spreading é quase garantido. Os gigantes da nuvem estão movendo para protocolos de transporte proprietários (como o SRD da AWS ou Falcon do Google) que rodam sobre Ethernet com perdas (Lossy), justamente para evitar o terror do PFC. Eles preferem lidar com a reordenação de pacotes no silício da NIC do que arriscar travar o data center inteiro.
O que fazer amanhã de manhã?
Não aceite a configuração "auto" dos switches e NICs.
- Audite seus contadores: Configure seu Prometheus/Grafana para monitorar
rx_pause_framesepfc_watchdog. Alerte se forem > 0. - Verifique o Headroom: Seus links entre switches têm a distância configurada corretamente no perfil de buffer?
- Teste o Watchdog: Em um ambiente de homologação, force um congestionamento e veja se o Watchdog dispara e recupera o link. Se não recuperar, você tem uma bomba relógio.
O Ethernet "sem perdas" é uma ferramenta poderosa, mas exige respeito. Sem observabilidade granular, ela transforma sua rede em uma caixa preta onde os pacotes não são perdidos, mas o tempo — e sua sanidade — certamente são.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.