DDR5 vs DDR4 em 2025: O Paradoxo do Preço e o Impacto do HBM no Enterprise

Em 2025, a escassez de wafers para HBM inverte a lógica de mercado: a memória DDR4 torna-se mais cara que a DDR5. Entenda o impacto no TCO de servidores, ZFS e infraestrutura.
Para qualquer profissional que desenhou infraestrutura na última década, a regra de ouro da memória era simples: a tecnologia da geração anterior (N-1) oferece o melhor custo por gigabyte, enquanto a nova geração (N) cobra um prêmio pela performance. Durante anos, compramos DDR3 quando a DDR4 saiu, e DDR4 quando a DDR5 engatinhava. Era a escolha segura, o "sweet spot" do TCO (Total Cost of Ownership).
Em 2025, essa lógica quebrou.
Estamos testemunhando uma tempestade perfeita na cadeia de suprimentos de semicondutores. A demanda insaciável por IA Generativa não está apenas mudando as GPUs; ela está reconfigurando as linhas de produção de DRAM. Se você está planejando um refresh de datacenter ou uma expansão de storage baseada na premissa de que "DDR4 é mais barato", pare agora. Você provavelmente está prestes a cometer um erro financeiro e arquitetural.
O Paradoxo do Preço em 2025: Diferente das transições anteriores, a memória DDR5 atingiu a paridade de preço e, em muitos casos, tornou-se mais barata que a DDR4 de alta densidade devido à economia de escala. A produção de DDR4 está sendo artificialmente sufocada para liberar wafers de silício para a fabricação de HBM (High Bandwidth Memory), essencial para aceleradores de IA, criando um "imposto de escassez" sobre a tecnologia legada.
O Efeito Canibal do HBM e a Escassez de Wafers para DDR4
Para entender o preço do pente de memória no seu servidor, você precisa olhar para a fábrica (Fab). A fabricação de memória é um jogo de soma zero em termos de wafers de silício. A Samsung, a SK Hynix e a Micron têm uma capacidade finita de produção mensal.
Historicamente, quando uma nova memória (DDR5) entrava, a antiga (DDR4) continuava sendo produzida em massa para atender a cauda longa do mercado. Hoje, existe um terceiro jogador faminto na mesa: a memória HBM3e e HBM4.
A margem de lucro de um stack de HBM para uma GPU NVIDIA H100/B200 é exponencialmente maior do que a de um módulo DDR4 commodity. Como resultado, os fabricantes estão convertendo linhas de produção de DDR4 para HBM. A DDR5, sendo o padrão atual para todas as novas CPUs (AMD EPYC Genoa/Turin e Intel Sapphire/Emerald Rapids), mantém sua linha garantida. Quem sobra sem cadeira na dança das cadeiras? A DDR4.
 Figura: Alocação de Wafers em 2025: O HBM canibaliza a capacidade produtiva da DDR4.
Figura: Alocação de Wafers em 2025: O HBM canibaliza a capacidade produtiva da DDR4.
Isso cria um cenário de escassez artificial. Manter infraestrutura legada agora carrega um prêmio de risco. A disponibilidade de peças de reposição de alta densidade (LRDIMMs de 64GB ou 128GB DDR4) está caindo, e os preços estão subindo inversamente à lei de Moore.
A Inversão da Curva de Custo DDR5 vs DDR4
No Enterprise, não compramos "velocidade", compramos densidade e confiabilidade. O problema é que o custo por GB da DDR4 parou de cair e começou a subir em 2024, enquanto a DDR5 despencou conforme o yield (aproveitamento) das fábricas amadureceu.
Se você está orçando um servidor de storage com 1TB de RAM para um cluster Ceph ou ZFS, a conta mudou.
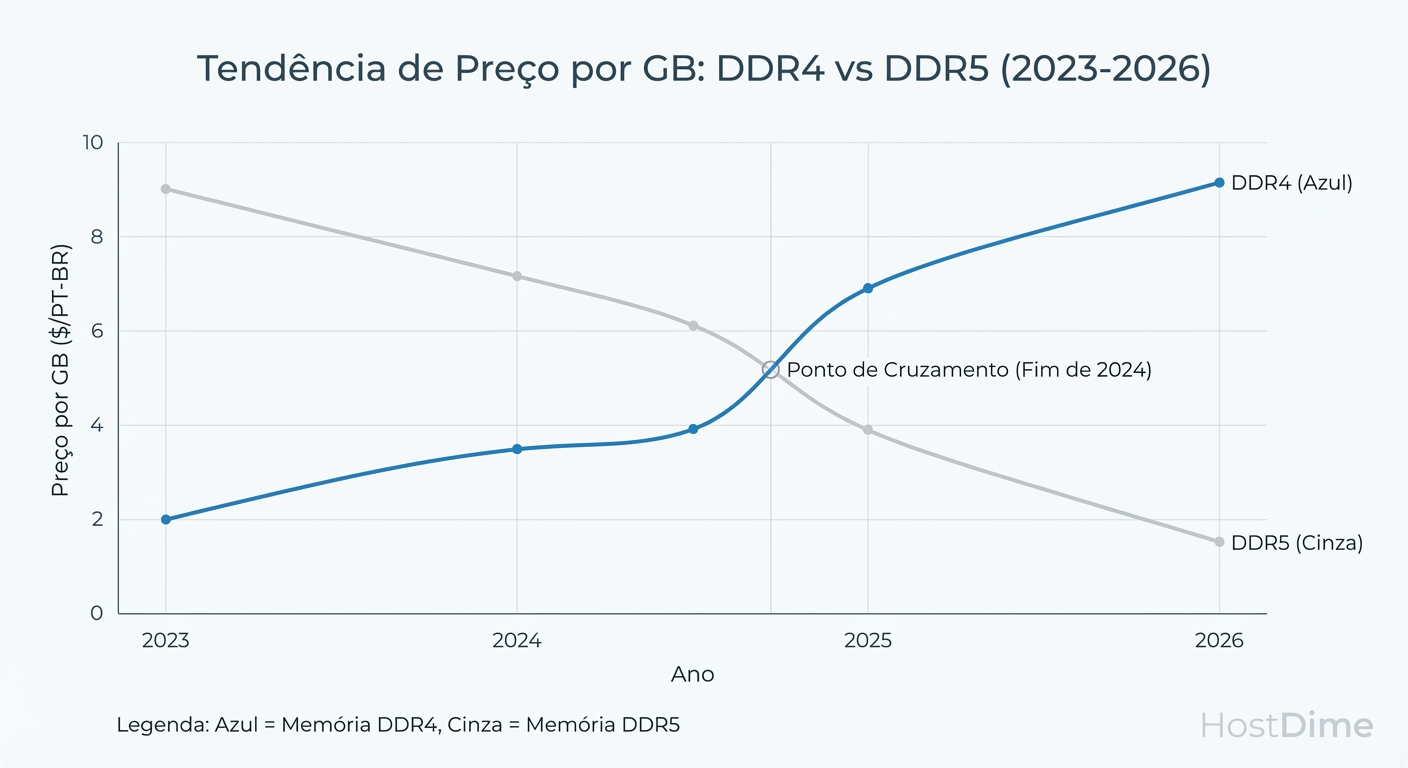 Figura: O 'Crossover' de Preço: Projeção de custo por GB onde a manutenção de legado supera a adoção de nova tecnologia.
Figura: O 'Crossover' de Preço: Projeção de custo por GB onde a manutenção de legado supera a adoção de nova tecnologia.
O Risco do Legado: Ao optar por plataformas DDR4 (como servidores Intel Cascade Lake ou AMD Milan usados/refurbished) para economizar no chassi, você pode acabar gastando a diferença (ou mais) apenas para povoar os slots de memória, além de ficar preso a uma plataforma com ciclo de vida de suporte (EoL) próximo do fim.
Mitos de Latência: CAS Latency, Nanosegundos e a Realidade da DDR5
Um dos maiores bloqueios mentais na adoção da DDR5 é a latência CAS (CL). Arquitetos olham para uma especificação DDR4-3200 CL22 e comparam com uma DDR5-4800 CL40, assumindo erroneamente que a DDR5 é "quase o dobro mais lenta" para responder.
Isso é um erro de física básica. CAS Latency é medida em ciclos de clock, não em tempo absoluto.
Para saber a latência real em nanossegundos ($ns$), a fórmula é:
$$Latência Real (ns) = \frac{CL \times 2000}{Data Rate (MT/s)}$$
Vamos aos números reais de módulos típicos de servidor:
DDR4-3200 CL22: $(22 * 2000) / 3200 = 13.75 ns$
DDR5-4800 CL40 (Primeira geração): $(40 * 2000) / 4800 = 16.66 ns$ (Aqui nasceu o mito da lentidão)
DDR5-6400 CL32 (Padrão atual de performance): $(32 * 2000) / 6400 = 10 ns$
Conclusão: A DDR5 moderna já superou a DDR4 em latência absoluta. E isso é apenas metade da história. A DDR5 possui dois canais de 32-bit por DIMM (contra um de 64-bit da DDR4) e burst length maior. Em cargas de trabalho concorrentes massivas — como bancos de dados transacionais ou virtualização densa — a eficiência do barramento da DDR5 entrega um throughput efetivo que a DDR4 fisicamente não consegue acompanhar, independentemente da latência CAS.
Impacto em Storage: O Dilema do Cache ZFS e Ceph com Memória Cara
Aqui é onde o "Storage-First" encontra a realidade do orçamento. Sistemas como ZFS (TrueNAS) e Ceph amam RAM. O ARC (Adaptive Replacement Cache) do ZFS é, indiscutivelmente, o melhor algoritmo de cache de leitura existente. A regra de ouro sempre foi: "Máximo de RAM possível antes de pensar em L2ARC".
Porém, com a transição de plataforma, o custo inicial do servidor (chassi + CPU DDR5) é alto. Isso nos força a repensar a estratégia de tiering.
Se a memória principal (DDR5) é o recurso escasso no seu novo orçamento, o uso inteligente de NVMe como camada secundária deixa de ser opcional e vira mandatório.
Tabela de Decisão: Estratégia de Cache em 2025
| Recurso | Função no ZFS/Ceph | Custo/GB Est. | Latência | Veredito 2025 |
|---|---|---|---|---|
| DDR5 DRAM | ARC / OSD Map | $$$$ | ~10-15ns | Essencial para metadados. Não super-provisione para dados frios. |
| NVMe (Optane/SLC) | ZIL / SLOG (Write) | $$$ | ~10µs | Obrigatório para escritas síncronas (NFS/iSCSI/DBs). |
| NVMe (TLC/QLC) | L2ARC / BlueStore DB | $$ | ~80µs | O Grande Salvador. Use drives grandes e baratos para estender o cache de leitura. |
| SSD SATA | Storage Tier | $ | ~500µs | Morto para cache. Lento demais para competir com redes 100GbE. |
Como validar se você precisa de mais RAM ou L2ARC? Não adivinhe. Meça. Se o seu hit rate de ARC é alto, mas você está sofrendo despejo de memória (eviction) frequente, verifique o tamanho do seu working set.
# Se 'miss' for alto, mas o 'l2_hits' (se existir) for alto,
# seu L2ARC está fazendo o trabalho que a RAM cara faria.
arc_summary | grep "Cache Hit Ratio"
arc_summary | grep "L2ARC Size"
Em 2025, é financeiramente irresponsável tentar manter todo o working set em DDR5 se ele for massivo (ex: 50TB de dados quentes). Um servidor com 256GB de DDR5 + 4TB de NVMe L2ARC terá um TCO muito melhor e performance indistinguível de um servidor com 1TB de RAM para 95% dos workloads de arquivo.
Matemática de Upgrade vs. Refresh: Quando Migrar para Servidores DDR5
A decisão final recai sobre o Break-even Point. Quando vale a pena abandonar aquele chassi Dell R740 ou HPE Gen10 (DDR4) e comprar um novo?
Não olhe apenas para o custo da memória. Considere o Custo por Core Licenciado e a Densidade de Consolidação.
Consolidação: Um único processador AMD EPYC 9004/9005 (DDR5) pode substituir 3 ou 4 servidores dual-socket da era Xeon Scalable Gen2 (DDR4).
Licenciamento: Se você roda VMware, Oracle ou SQL Server por core, a redução da contagem de núcleos (usando núcleos mais rápidos e alimentados por DDR5) paga o hardware novo em 12-18 meses.
Eficiência Energética: DDR5 opera a 1.1V (com PMIC no módulo), contra 1.2V da DDR4. Parece pouco, mas em escala, somado à eficiência das novas CPUs, o OPEX de energia e refrigeração cai drasticamente.
O Veredito do Arquiteto: Se você precisa apenas adicionar 32GB a um servidor existente para ele sobreviver mais 6 meses, compre DDR4 usada. Mas se você está projetando um cluster que deve durar 3 a 5 anos, DDR4 é uma armadilha. O custo de aquisição está subindo, a disponibilidade está caindo (graças ao HBM) e a performance por watt é inferior.
Em 2025, "economizar" comprando tecnologia legada é a forma mais cara de operar TI.
Referências & Leitura Complementar
JEDEC Standard JESD79-5C: DDR5 SDRAM Specification (Detalhes técnicos sobre burst length e canais).
TrendForce Memory Spot Price Index 2024-2025: Análises de mercado sobre o impacto da produção de HBM nos preços de DRAM commodity.
OpenZFS Documentation: "Performance tuning and ARC strategies for NVMe-based systems".
AnandTech / Tom's Hardware: Deep dives em latência de memória (Ciclos vs. Tempo Real).

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.