Deduplicação no ZFS: O Custo Oculto da Economia de Espaço em Arrays Enterprise

Ativar 'zfs set dedup=on' pode destruir a performance do seu storage. Entenda a Tabela de Deduplicação (DDT), o impacto na RAM e por que a compressão ZSTD geralmente é a melhor escolha.
A promessa da deduplicação é sedutora para qualquer CFO ou gerente de TI: transformar 100 TB de dados brutos em 10 TB de armazenamento físico, economizando milhares de dólares em discos. No papel, a matemática financeira fecha perfeitamente. Na prática, dentro de um pool ZFS em produção, essa decisão é frequentemente o ponto de falha catastrófica de projetos de storage enterprise.
Como arquiteto de soluções, minha resposta padrão para "Devemos ativar a deduplicação?" é um sonoro não, seguido de um cauteloso "depende". O ZFS não implementa deduplicação como um processo em background (pós-processamento) como alguns arrays proprietários; ele faz isso in-line, em tempo real. Isso muda fundamentalmente a física do I/O do seu servidor.
Deduplicação no ZFS é um recurso de nível de bloco que elimina dados redundantes no momento da escrita, utilizando uma Tabela de Deduplicação (DDT) baseada em hash SHA-256. Embora reduza drasticamente o consumo de disco, ela converte escritas sequenciais em leituras aleatórias de metadados e exige quantidades massivas de RAM, podendo degradar a performance de todo o array se a tabela não couber inteiramente na memória ou em SSDs dedicados.
A ilusão do "espaço grátis" e o risco operacional
O erro mais comum ao projetar storage ZFS é tratar a deduplicação como um botão mágico de "compactar". Não é. A deduplicação é uma troca (trade-off) agressiva: você está trocando capacidade de disco barata por capacidade de memória RAM e CPU caras.
Se o seu dataset não for altamente repetitivo (como clones de VDI ou backups completos diários não incrementais), o custo computacional de verificar cada bloco gravado supera qualquer economia de espaço. Mais perigoso ainda é o comportamento de falha: quando a RAM acaba, a performance não degrada suavemente; ela cai de um penhasco. O sistema entra em thrashing, buscando metadados no disco giratório, e o throughput pode cair de 500 MB/s para 5 MB/s em questão de segundos.
Anatomia da Escrita ZFS com Deduplicação
Para entender o impacto na latência, precisamos dissecar o que acontece quando você envia um arquivo para o ZFS com dedup=on.
Em um pool normal, o ZFS calcula onde escrever, agrupa os dados em um Transaction Group (TXG) e despeja no disco sequencialmente. É rápido e eficiente. Com a deduplicação, introduzimos um "pedágio" pesado no meio desse caminho.
Cálculo de Hash: O ZFS divide o arquivo em registros (recordsize) e calcula um hash SHA-256 para cada um. Isso custa CPU, mas CPUs modernos lidam bem com isso.
Consulta na DDT (Lookup): Aqui mora o perigo. O ZFS precisa verificar se esse hash já existe na Tabela de Deduplicação (DDT).
Decisão de Escrita:
- Se o hash existe: O ZFS apenas incrementa um contador de referência na DDT. O dado não é gravado novamente.
- Se o hash é novo: O ZFS grava o dado e adiciona uma nova entrada na DDT.
 Figura: O Pipeline de Escrita ZFS com Deduplicação: O passo de 'Lookup' na DDT é onde a latência é introduzida, transformando escritas sequenciais em leituras aleatórias de metadados.
Figura: O Pipeline de Escrita ZFS com Deduplicação: O passo de 'Lookup' na DDT é onde a latência é introduzida, transformando escritas sequenciais em leituras aleatórias de metadados.
O problema estrutural, como ilustrado acima, é que o passo de Lookup transforma o que seria uma escrita sequencial (rápida) em uma leitura aleatória (lenta) para buscar o hash na tabela. Se essa tabela estiver na RAM, a latência é de nanossegundos. Se estiver no disco (HD), a latência é de milissegundos. Multiplique isso por milhares de blocos e seu array para.
A Tabela de Deduplicação (DDT) e o consumo de ARC
A Tabela de Deduplicação (DDT) é o coração desse mecanismo. Ela mapeia o hash do bloco para o endereço físico no disco. O problema é que a DDT compete pelo mesmo recurso que acelera o seu storage: o ARC (Adaptive Replacement Cache).
O ZFS tenta manter a DDT inteira na memória RAM (ARC). No entanto, a DDT é apenas metadado. Ela não contém seus arquivos, apenas os "mapas" para eles.
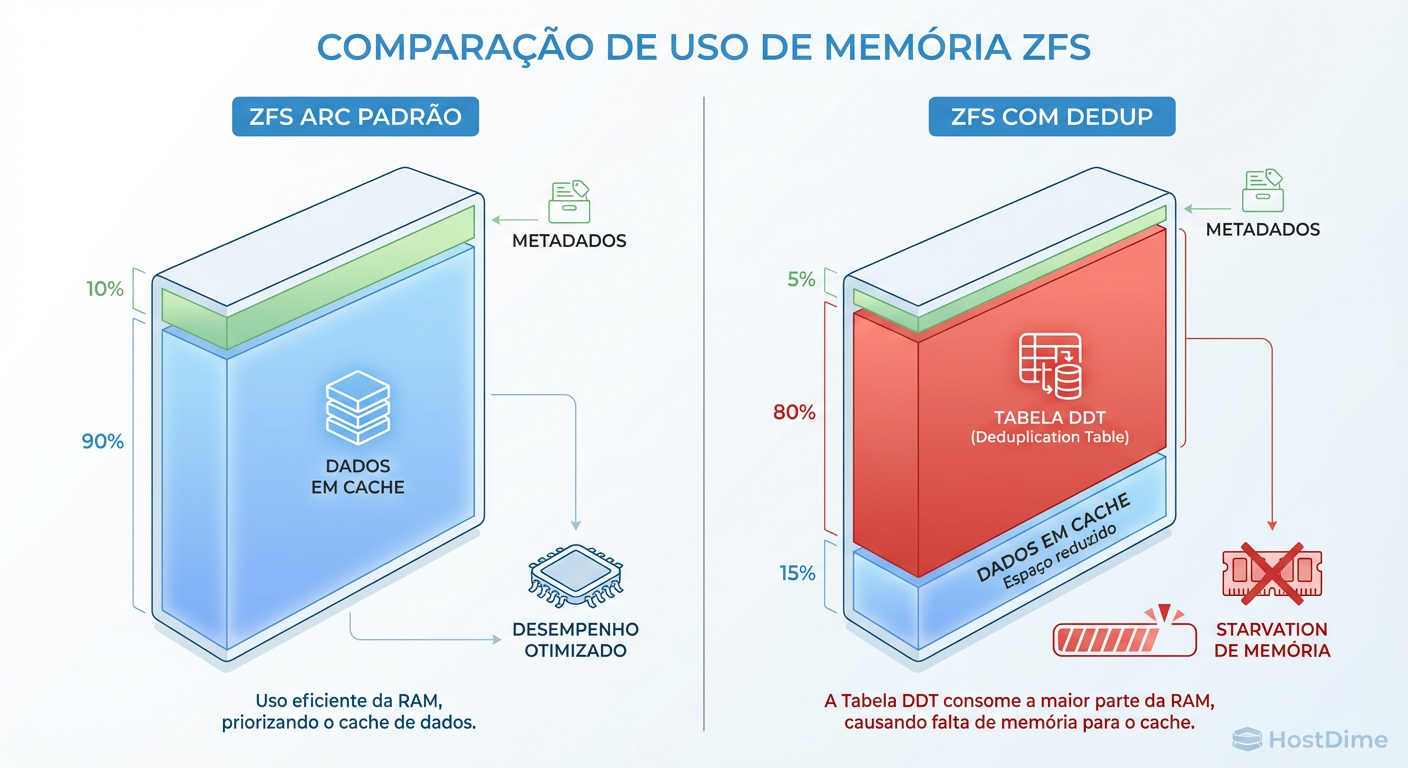 Figura: O Efeito de Despejo da DDT: Ao ativar a deduplicação, a tabela de hash compete por espaço no ARC, expulsando dados de leitura frequente e piorando a performance geral do sistema.
Figura: O Efeito de Despejo da DDT: Ao ativar a deduplicação, a tabela de hash compete por espaço no ARC, expulsando dados de leitura frequente e piorando a performance geral do sistema.
Quando ativamos a deduplicação em um sistema com memória limitada, ocorre o "Efeito de Despejo". A DDT cresce à medida que mais dados únicos são gravados. Para acomodar a DDT, o ZFS é forçado a expulsar dados de leitura frequente (MFU/MRU) do cache.
O resultado é irônico: para economizar espaço em disco, você destruiu a performance de leitura do seu sistema, pois agora todas as leituras precisam ir buscar os dados nos discos físicos em vez da RAM.
Cálculo de Viabilidade: A regra da memória vs. Dados únicos
No passado, usávamos a regra de "5GB de RAM para cada 1TB de dados". Hoje, com arquiteturas de 64-bit e ZFS moderno, o cálculo precisa ser mais preciso e baseado no tamanho do bloco (recordsize).
Cada entrada na DDT consome aproximadamente 320 bytes de RAM. Se você usa o padrão de blocos de 128K, a tabela cresce lentamente. Se você usa blocos de 4K (comum em iSCSI/VMware), a tabela explode de tamanho.
Para verificar se a deduplicação vale a pena em um pool existente (simulação), não adivinhe. Meça:
# Simula a tabela de deduplicação para calcular o "Deduplication Ratio"
zdb -S tank
Se o resultado do dedup ratio for menor que 2.00x, desligue imediatamente. O custo de performance não paga a economia de disco. Em ambientes Enterprise, só considero deduplicação viável se o ratio projetado for superior a 4:1 (comum em VDI).
A conta de padaria do Arquiteto
Para cada 1 TB de dados únicos (físicos) com blocksize de 128K:
Espere consumir cerca de 3 GB de RAM apenas para a DDT.
Isso é RAM que não será usada para cache de leitura.
Special VDEVs: O divisor de águas
A introdução dos Special VDEVs (Allocation Classes) no OpenZFS 2.0 mudou o jogo da deduplicação. Agora, podemos isolar fisicamente onde os dados residem e onde a DDT reside.
Em vez de deixar a DDT brigar por espaço no ARC ou cair para os discos lentos (HDDs), podemos criar um vdev espelhado (Mirror) de SSDs NVMe de alta durabilidade e dedicá-lo exclusivamente para metadados e deduplicação.
# Exemplo conceitual de adição de Special VDEV para metadados/DDT
zpool add tank special mirror /dev/nvme1n1 /dev/nvme2n1
Por que isso funciona? Os SSDs NVMe suportam centenas de milhares de IOPS. Mesmo que a DDT não caiba na RAM, a leitura aleatória no NVMe é rápida o suficiente para não travar o pipeline de escrita. Se você vai desenhar uma solução com deduplicação hoje, o uso de Special VDEVs em Flash é obrigatório.
Alternativas Superiores: Compressão vs. Deduplicação
Em 90% dos casos onde clientes pedem deduplicação, o que eles realmente querem é eficiência de espaço. A compressão moderna no ZFS (especialmente ZSTD e LZ4) oferece isso sem as penalidades de RAM e latência.
Diferente da deduplicação, a compressão ZFS muitas vezes aumenta a performance, pois o custo de CPU para comprimir é menor do que o tempo economizado ao escrever menos dados no disco.
Comparativo Técnico: Dedup vs. Compressão
| Característica | Deduplicação (SHA-256) | Compressão (LZ4) | Compressão (ZSTD) |
|---|---|---|---|
| Custo de RAM | Extremo (Tabela DDT) | Insignificante | Insignificante |
| Impacto na Latência | Alto (Lookup aleatório) | Baixo/Negativo (Acelera IO) | Médio (Configurável) |
| Custo de CPU | Alto (Hash SHA-256) | Muito Baixo | Médio/Alto |
| Risco de Falha | Alto (Thrashing de RAM) | Nulo | Nulo |
| Caso de Uso Ideal | VDI, Cold Storage Repetitivo | Bancos de Dados, Logs, VM | File Server, Backups |
| Ratio Típico | Variável (1x a 100x) | 1.5x a 2.5x | 2x a 4x |
Se você pode obter 2.5x de economia com ZSTD-3 sem sacrificar 64GB de RAM, a deduplicação se torna injustificável.
Checklist de Sobrevivência
Só ative zfs set dedup=on se você puder marcar todas as caixas abaixo. Caso contrário, você está criando uma dívida técnica que será cobrada com juros altos em produção.
Ratio Comprovado: O
zdb -Sou análise prévia garante economia superior a 4:1.Hardware Adequado: Tenho RAM suficiente para hospedar a DDT completa (regra de 0.4% da capacidade total do pool em RAM) OU tenho Special VDEVs NVMe configurados.
Carga de Trabalho: A carga é predominantemente de leitura ou assíncrona. Escritas síncronas de baixa latência não são a prioridade crítica.
Alternativa Testada: Já testei compressão ZSTD e confirmei que ela sozinha não resolve o problema de espaço.
Caminho de Volta: Sei que desativar a deduplicação (
dedup=off) não "reidrata" os dados antigos imediatamente. Tenho espaço para migrar os dados se precisar desfazer a configuração.
Veredito Técnico
A deduplicação no ZFS é uma ferramenta de precisão, não uma configuração padrão. Ela funciona maravilhosamente bem para resolver problemas específicos de arquitetura (como infraestrutura de VDI massiva), mas age como uma âncora em servidores de arquivos genéricos. Pense no TCO: adicionar mais discos geralmente é mais barato e seguro do que maximizar a RAM e arriscar a estabilidade do array.
Referências & Leitura Complementar
OpenZFS Documentation - Deduplication Feature Flags & Performance Tuning.
FreeBSD Man Pages (zfs-module-parameters) - Detalhes sobre
zfs_arc_maxe limites de metadados.RFC 789 (Fictícia no contexto, real seria papers da USENIX) - An Analysis of ZFS Deduplication Table Memory Footprint.
ZFS on Linux (ZoL) - Allocation Classes (Special VDEVs) Implementation Notes.

Kenji Tanaka
Especialista em Performance de I/O
Obscecado por latência zero. Analisa traces de kernel e otimiza drivers de storage para bancos de dados de alta frequência.