Deduplicacao Quando Vale E Quando E Cilada

A deduplicação é uma técnica tentadora: a promessa de espremer mais dados no mesmo espaço físico, reduzindo custos e simplificando o gerenciamento. Mas a implem...
Deduplicacao Quando Vale E Quando E Cilada
A deduplicação é uma técnica tentadora: a promessa de espremer mais dados no mesmo espaço físico, reduzindo custos e simplificando o gerenciamento. Mas a implementação negligente transforma essa benesse em pesadelo. Este guia destrincha a deduplicação, revelando seus mecanismos internos, cenários ideais, armadilhas de performance e estratégias de diagnóstico.
O Problema Real: Onde Foi Que Eu Errei?
Imagine a cena: você implementou a deduplicação para otimizar o armazenamento de backups, seguindo as melhores práticas. Semanas depois, o sistema de backup começa a falhar, as janelas de backup se estendem indefinidamente e a restauração de arquivos se torna agonizante. A equipe de infraestrutura aponta o dedo para a deduplicação, mas ninguém sabe exatamente o porquê. A causa raiz raramente é óbvia.
Por Dentro da Deduplicação: Hashing, Chunks e Metadados
A deduplicação, em sua essência, é um processo de identificação e eliminação de cópias redundantes de dados. Para entender seu funcionamento, precisamos mergulhar nos detalhes:
Chunking: O primeiro passo é dividir os dados em unidades menores, chamadas "chunks". Existem duas abordagens principais:
- Chunking de tamanho fixo: Divide os dados em blocos de tamanho predefinido (ex: 4KB, 8KB). Simples, mas ineficiente se pequenas alterações em um arquivo resultarem em chunks completamente diferentes.
- Chunking de tamanho variável: Utiliza algoritmos para identificar limites de chunks baseados no conteúdo dos dados. Mais complexo, mas mais resiliente a pequenas modificações. Algoritmos comuns incluem Content Defined Chunking (CDC).
Hashing: Para cada chunk, é gerado um hash (uma "impressão digital") usando um algoritmo como SHA-256 ou MD5. O hash representa unicamente o conteúdo do chunk.
Comparação: O hash do chunk é comparado com um índice (uma tabela hash gigante) de todos os hashes de chunks já armazenados.
Armazenamento (ou não):
- Se o hash já existe no índice, significa que o chunk é uma cópia de um chunk existente. Em vez de armazenar o chunk duplicado, o sistema cria um ponteiro (referência) para o chunk original.
- Se o hash não existe, o chunk é novo e é armazenado, e seu hash é adicionado ao índice.
Metadados: Um sistema de metadados rastreia quais arquivos são compostos por quais chunks e onde esses chunks estão localizados.
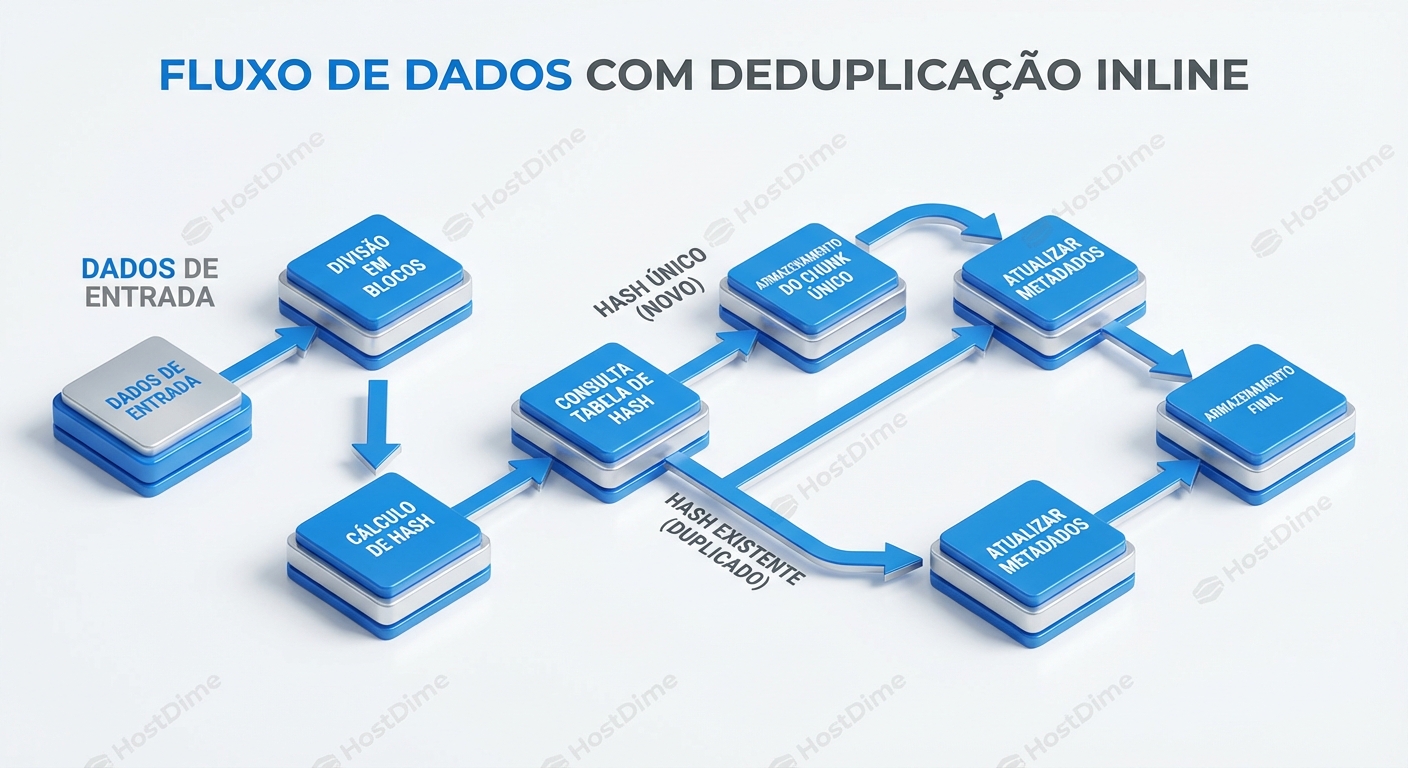
Inline vs. Post-Process Deduplication: A Batalha da Performance
A ordem em que a deduplicação é aplicada tem um impacto significativo no desempenho:
Deduplicação Inline: A deduplicação é realizada antes dos dados serem gravados no disco. Isso economiza espaço de armazenamento desde o início, mas pode introduzir latência, pois cada chunk precisa ser hasheado e comparado com o índice antes da gravação.
Deduplicação Post-Process: Os dados são gravados no disco primeiro e a deduplicação é realizada em um momento posterior (ex: durante a noite). Isso minimiza o impacto na latência de gravação, mas requer espaço de armazenamento adicional para os dados duplicados até que a deduplicação seja executada.
A escolha entre inline e post-process depende da workload. Para backups, onde a latência de gravação é crítica, a deduplicação post-process é geralmente preferível. Para arquivamento, onde o espaço é primordial, a deduplicação inline pode ser mais adequada.
O Índice de Deduplicação: O Calcanhar de Aquiles
O índice de deduplicação é uma estrutura de dados crítica que armazena os hashes de todos os chunks únicos. Seu tamanho e desempenho são fatores limitantes.
- Tamanho: O índice pode consumir uma quantidade significativa de memória e espaço em disco, especialmente em sistemas com grandes volumes de dados.
- Desempenho: A velocidade com que os hashes podem ser pesquisados no índice afeta diretamente a latência da deduplicação. Índices mal projetados ou armazenados em mídias lentas podem se tornar gargalos.
Quando a Deduplicação Brilha (e Quando Ela Queima)
Nem todas as workloads se beneficiam igualmente da deduplicação.
Cenários Ideais:
- Backups: Backups completos e incrementais frequentemente contêm grandes quantidades de dados redundantes, tornando-os um caso de uso ideal para deduplicação.
- Virtualização (VDI): Imagens de máquinas virtuais (VMs) frequentemente compartilham muitos blocos de dados comuns, especialmente em ambientes VDI (Virtual Desktop Infrastructure).
- Arquivos: Arquivos de longo prazo, como documentos e imagens, podem conter duplicatas ou versões antigas que podem ser deduplicadas.
Cenários Problemáticos:
- Bancos de Dados: Bancos de dados são altamente dinâmicos e seus dados mudam constantemente. A deduplicação pode ter pouco ou nenhum impacto e pode até mesmo degradar o desempenho devido à sobrecarga de hashing e comparação.
- Mídia: Arquivos de mídia (vídeos, áudios) são geralmente compactados e não contêm muita redundância interna. A deduplicação pode ser ineficaz.
- Dados Criptografados: A criptografia embaralha os dados, tornando impossível para a deduplicação identificar padrões redundantes.
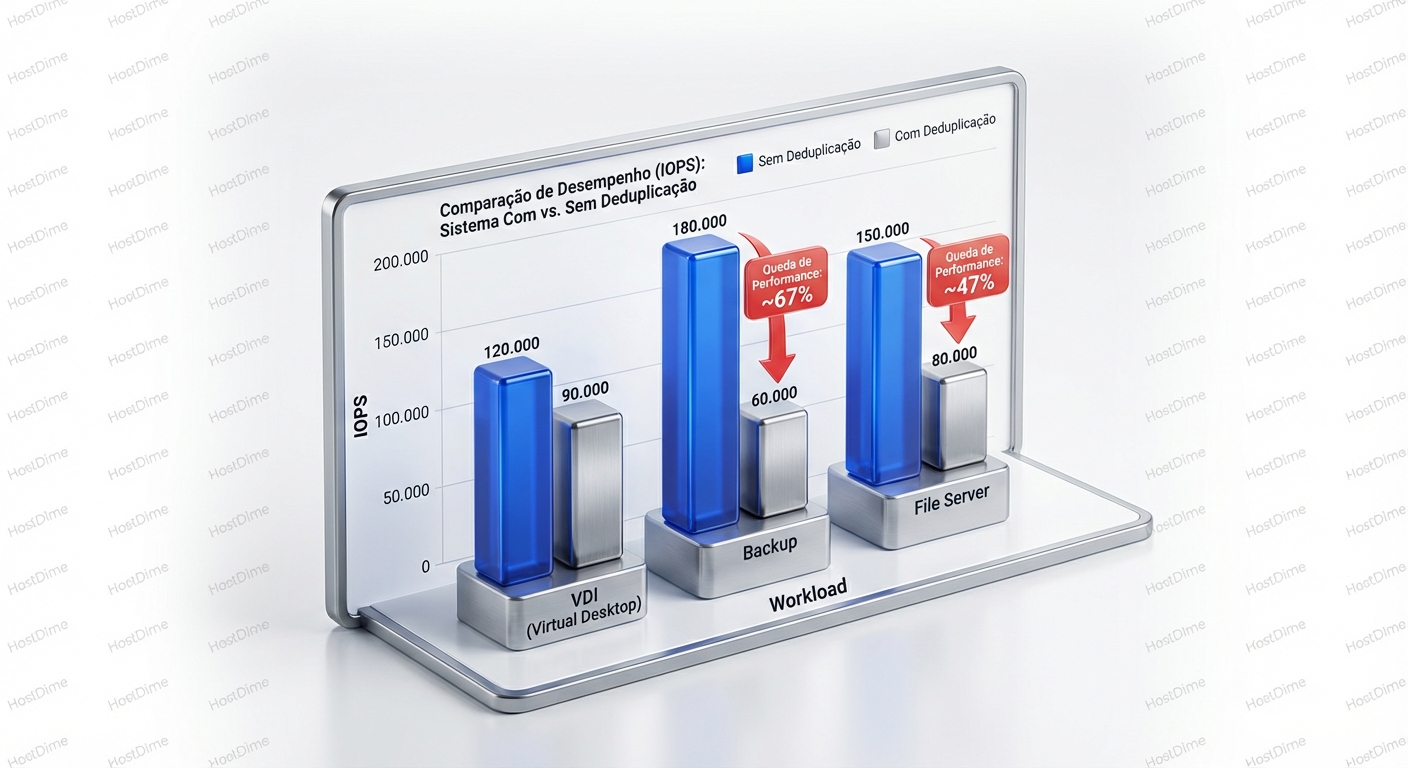
Sinais de Alerta: Diagnóstico e Monitoramento
A implementação da deduplicação exige monitoramento constante para identificar problemas de desempenho e capacidade.
Sinais de Saúde:
- Taxa de Deduplicação: Uma alta taxa de deduplicação (ex: 10:1 ou superior) indica que a deduplicação está funcionando efetivamente.
- Latência de Gravação: A latência de gravação deve permanecer dentro de limites aceitáveis após a implementação da deduplicação.
- Utilização da CPU: A utilização da CPU pelo processo de deduplicação deve ser monitorada para garantir que não esteja sobrecarregando o sistema.
- Utilização da Memória: A utilização da memória pelo índice de deduplicação deve ser monitorada para evitar a exaustão da memória.
Sinais de Perigo:
- Queda na Taxa de Deduplicação: Uma queda repentina na taxa de deduplicação pode indicar um problema com a configuração da deduplicação ou uma mudança no padrão de dados.
- Aumento na Latência de Gravação: Um aumento na latência de gravação pode indicar que o índice de deduplicação está se tornando um gargalo.
- Alta Utilização da CPU: Alta utilização da CPU pelo processo de deduplicação pode indicar que o sistema está sobrecarregado.
- Erros de Deduplicação: Erros de deduplicação (ex: falha ao encontrar um chunk no índice) podem indicar um problema com o índice ou com o sistema de armazenamento.
Ferramentas de Diagnóstico: Desvendando o Mistério
As ferramentas de diagnóstico variam dependendo do sistema de armazenamento e da implementação da deduplicação. Aqui estão alguns exemplos genéricos e específicos:
Monitoramento de Desempenho do Sistema: Ferramentas como
iostat,vmstateperfpodem ser usadas para monitorar a utilização da CPU, memória e disco.Estatísticas de Deduplicação: A maioria dos sistemas de armazenamento com deduplicação integrada fornece estatísticas detalhadas sobre a taxa de deduplicação, o tamanho do índice e o desempenho da deduplicação. Consulte a documentação do seu sistema de armazenamento para obter informações sobre como acessar essas estatísticas.
ZFS (Exemplo): Se você estiver usando ZFS com deduplicação, o comando
zpool statusfornece informações sobre a taxa de deduplicação e o espaço economizado.zpool status seu_poolA saída mostrará algo como:
dedup: DDT entries 4294967295, size 128B pool dedup ditto factor: 1x dedup compression ratio: 1.78xO
dedup compression ratioindica a taxa de deduplicação. Neste exemplo, 1.78x significa que para cada 1.78GB de dados lógicos, apenas 1GB de dados físicos é armazenado.Análise de Logs: Os logs do sistema podem conter mensagens de erro ou avisos relacionados à deduplicação. Analise os logs para identificar problemas.
Trade-offs e Armadilhas: Navegando em Águas Turbulentas
Apesar dos benefícios potenciais, a deduplicação apresenta trade-offs e armadilhas que precisam ser consideradas:
- Sobrecarga de Desempenho: A deduplicação adiciona sobrecarga de processamento devido ao hashing e à comparação de chunks. Isso pode afetar o desempenho, especialmente em workloads com alta taxa de gravação.
- Complexidade: A deduplicação adiciona complexidade ao sistema de armazenamento. O gerenciamento do índice de deduplicação e a resolução de problemas podem ser desafiadores.
- Vulnerabilidade a Corrupção de Dados: Se o índice de deduplicação for corrompido, pode haver perda de dados. É crucial implementar medidas de proteção de dados, como backups regulares e checksums.
- Custo: A deduplicação pode exigir hardware adicional, como mais memória e CPUs mais rápidas.
Dicas para o Sucesso: O Caminho do Meio
- Avalie a Workload: Antes de implementar a deduplicação, avalie cuidadosamente a workload para determinar se ela se beneficiará da deduplicação.
- Escolha a Implementação Apropriada: Escolha a implementação de deduplicação (inline vs. post-process) que melhor se adapta à sua workload.
- Monitore o Desempenho: Monitore o desempenho do sistema de armazenamento após a implementação da deduplicação para identificar problemas.
- Planeje a Capacidade: Planeje a capacidade do índice de deduplicação para garantir que ele possa acomodar o volume de dados.
- Implemente Proteção de Dados: Implemente medidas de proteção de dados para proteger contra a corrupção do índice de deduplicação.
Veredito: Use com Moderação e Consciência
A deduplicação é uma ferramenta poderosa que pode economizar espaço de armazenamento e reduzir custos. No entanto, ela não é uma bala de prata. A implementação negligente pode levar a problemas de desempenho e até mesmo perda de dados. Antes de implementar a deduplicação, avalie cuidadosamente sua workload, escolha a implementação apropriada e monitore o desempenho do sistema. E lembre-se: backups regulares são sempre essenciais, independentemente de você estar usando deduplicação ou não.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.