Domine Snapshots e Clones no ZFS: Arquitetura, RAID-Z e Performance
Entenda a mecânica Copy-on-Write dos snapshots ZFS. Descubra como gerenciar clones, evitar overhead em RAID-Z e interpretar métricas de 'Used' vs 'Referenced'.
A maioria dos administradores de sistemas trata snapshots do ZFS como "mágica" ou, pior, como uma estratégia de backup completa. Como Arquiteto de Soluções, meu trabalho é dizer que não é bem assim. Snapshots são primitivas de armazenamento incrivelmente poderosas, mas quando mal compreendidos em escala de Enterprise, tornam-se vetores de fragmentação, latência oculta e custos de armazenamento inexplicáveis.
Para desenhar soluções de armazenamento resilientes, precisamos abandonar a visão superficial e dissecar a mecânica de ponteiros, alocação de blocos e o comportamento assíncrono do ZFS. A resposta para "devo usar snapshots a cada 5 minutos?" é o clássico "depende". Vamos entender do que depende.
O que são Snapshots e Clones ZFS?
Definição Arquitetural: Snapshots no ZFS são representações read-only do sistema de arquivos em um ponto no tempo, criadas via Copy-on-Write (CoW) sem duplicar dados, apenas congelando a árvore de ponteiros atual. Clones são volumes graváveis instanciados a partir de um snapshot, compartilhando os blocos originais até que ocorra divergência (escrita), permitindo provisionamento ágil de ambientes com consumo inicial próximo de zero.
A Arquitetura Copy-on-Write (CoW) e a Árvore Merkle
Para operar o ZFS corretamente, você precisa entender que o ZFS nunca sobrescreve dados no local (in-place). Em sistemas de arquivos tradicionais (como ext4 ou NTFS), alterar um arquivo significa ir ao bloco físico no disco e mudar os bits magnéticos ou a carga da célula flash. Isso cria uma janela de vulnerabilidade onde uma queda de energia corrompe o dado.
No ZFS, o modelo é transacional. Se você altera um bloco de dados:
O ZFS aloca um novo bloco no disco.
Grava os dados modificados nesse novo local.
Atualiza o ponteiro do bloco pai para apontar para o novo endereço.
Essa mudança de ponteiros se propaga para cima na árvore até o "Uberblock" (raiz).
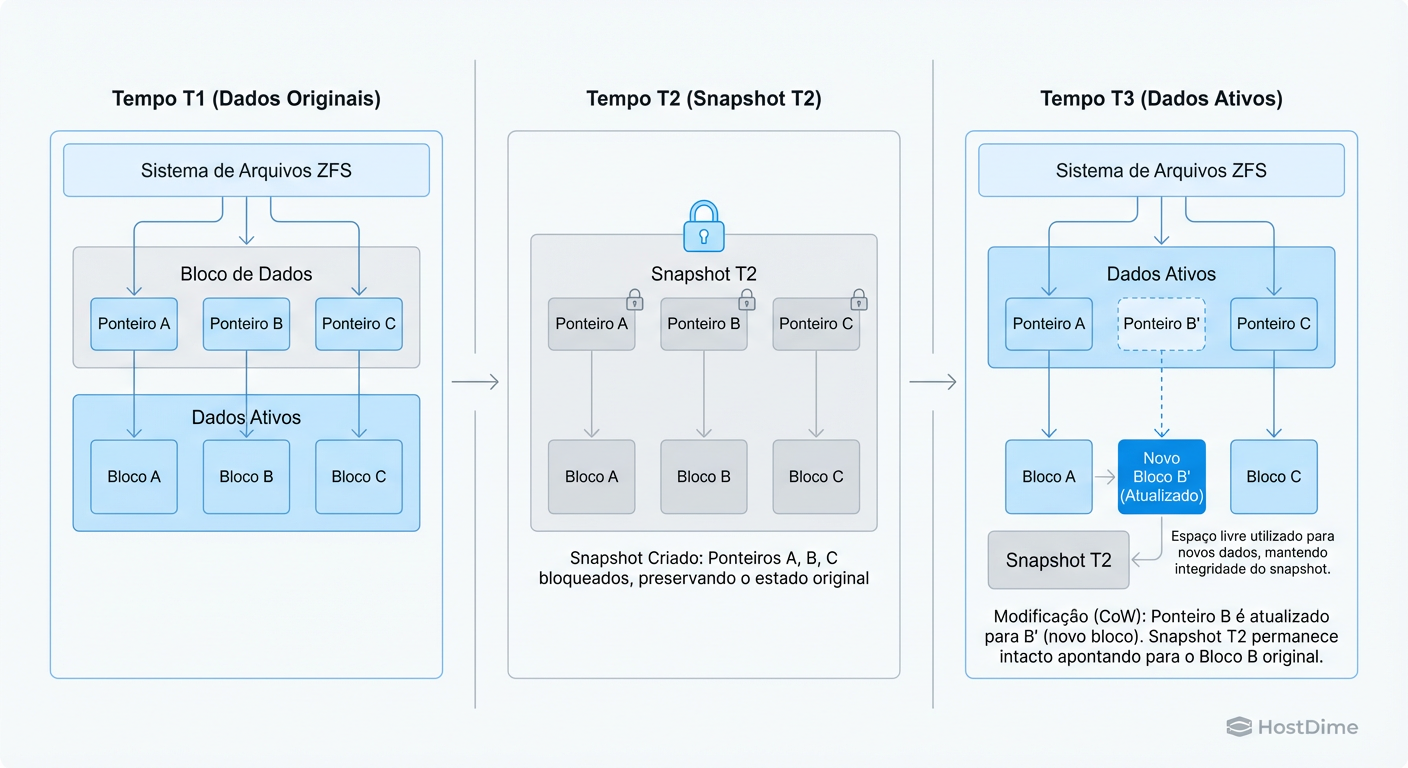 Figura: Diagrama do mecanismo Copy-on-Write (CoW): O snapshot preserva os ponteiros para os blocos originais (B) enquanto o sistema grava novos dados (B').
Figura: Diagrama do mecanismo Copy-on-Write (CoW): O snapshot preserva os ponteiros para os blocos originais (B) enquanto o sistema grava novos dados (B').
Isso significa que o estado anterior dos dados ainda existe no disco até que o ZFS decida que ninguém mais precisa dele. Um Snapshot é simplesmente uma instrução para o ZFS: "Não libere os blocos referenciados por esta versão da árvore Merkle".
Criar um snapshot custa quase zero de I/O e tempo, porque não estamos copiando dados. Estamos apenas persistindo um conjunto de ponteiros.
Como Snapshots ZFS Funcionam: Ponteiros e Transaction Groups (TXGs)
A ilusão de instantaneidade do snapshot é sustentada pelo conceito de Transaction Groups (TXGs). O ZFS agrupa escritas em transações atômicas. Um snapshot é criado exatamente na fronteira entre dois TXGs.
Quando você executa zfs snapshot pool/dataset@backup, o ZFS garante que todas as transações do TXG atual sejam completadas e "trava" a visão do sistema de arquivos naquele momento.
O Custo Oculto: Fragmentação
Embora a criação seja barata, a manutenção a longo prazo tem um custo arquitetural. Como o ZFS grava novos dados em novos blocos (CoW), um sistema de arquivos com muitos snapshots e alta taxa de reescrita (random overwrite) tende a se fragmentar. O arquivo lógico, que antes era sequencial, agora está espalhado pelo disco porque os blocos "velhos" estão presos no snapshot e os "novos" foram gravados onde havia espaço livre.
Risco para Arquitetos: Em discos rotacionais (HDD), snapshots excessivos em workloads de banco de dados (OLTP) podem destruir a performance de leitura sequencial ao longo do tempo. Em All-Flash Arrays, o impacto é menor, mas a amplificação de escrita ainda deve ser monitorada.
Diferenciando Espaço 'Referenced' e 'Used' no ZFS
Uma das maiores fontes de confusão em tickets de suporte e planejamento de capacidade é a saída do comando zfs list. Você apaga 1TB de arquivos, mas o espaço livre não aumenta. Por quê?
A resposta está na distinção entre o que o dataset vê e o que o snapshot segura.
REFERENCED (Referenciado): É a quantidade de dados que você acessaria se montasse aquele dataset ou snapshot agora. Se você tem um arquivo de 10GB, o Referenced é 10GB.
USED (Usado): É a quantidade de espaço que está sendo ocupada exclusivamente por este dataset ou snapshot. É o delta.
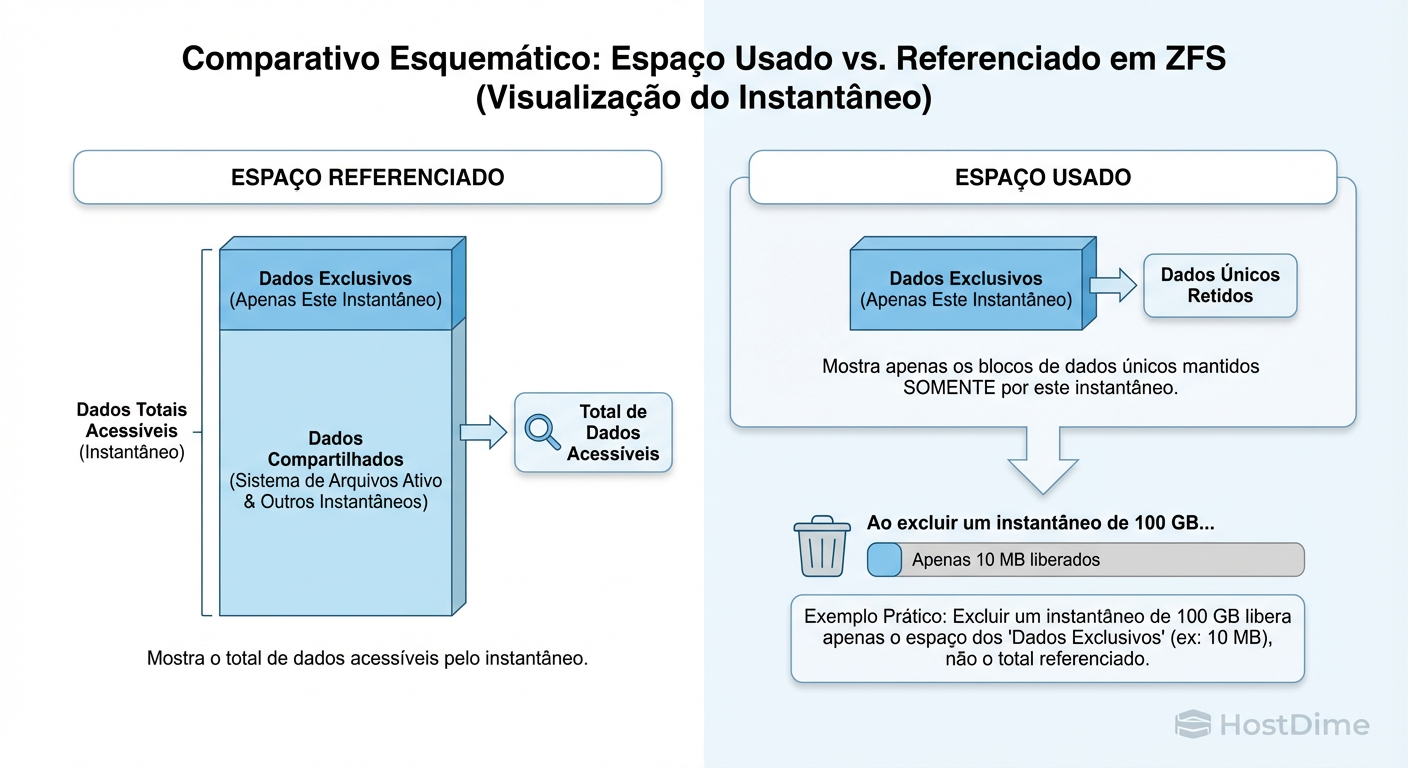 Figura: Diferença visual entre 'Referenced' (total acessível) e 'Used' (dados únicos retidos). Apenas o espaço 'Used' é recuperado ao apagar o snapshot.
Figura: Diferença visual entre 'Referenced' (total acessível) e 'Used' (dados únicos retidos). Apenas o espaço 'Used' é recuperado ao apagar o snapshot.
Se você cria um snapshot de um dataset de 100GB:
Inicialmente, o snapshot tem
Used = 0(ele não segura nada exclusivo, pois os dados também estão no sistema de arquivos ativo).Se você sobrescreve 10GB no sistema ativo, o sistema ativo aponta para novos blocos.
O snapshot agora "segura" os 10GB antigos. O
Useddo snapshot sobe para 10GB.
Para liberar espaço, você deve destruir os snapshots que possuem alto valor na coluna USEDSNAP.
zfs list -o name,used,refer,usedsnap,usedds -t all
O Impacto de Snapshots em Vdevs RAID-Z e Overhead
Aqui entramos em um território onde "Best Practices" genéricas falham. Se você utiliza RAID-Z1, Z2 ou Z3, snapshots podem custar mais caro do que você calcula.
O RAID-Z usa larguras de faixa (stripe widths) variáveis. Quando você grava um bloco, o ZFS calcula a paridade e grava. O problema surge na remoção ou na modificação parcial.
Se você tem um bloco de dados de 128K espalhado em um RAID-Z2 e modifica apenas 4K (criando um novo bloco via CoW), o snapshot mantém o bloco original de 128K vivo. Mas a complexidade aumenta com o padding (preenchimento). O ZFS precisa alinhar as escritas aos setores físicos e aos limites do RAID-Z.
Callout de Risco: Em configurações RAID-Z com
recordsizepequeno (ex: volblocksize de 8k ou 16k para VMs) e muitos snapshots, o overhead de paridade e padding pode causar uma amplificação de espaço significativa. Para workloads de VM e DB com snapshots frequentes, Mirrors (RAID-10) são arquiteturalmente superiores ao RAID-Z em eficiência de espaço efetivo e IOPS.
Arquitetura de Clones ZFS para Ambientes Writable
Clones são a "arma secreta" para CI/CD e ambientes de homologação. Enquanto um snapshot é imutável, um Clone é um sistema de arquivos gravável promovido a partir de um snapshot.
Imagine um banco de dados de produção de 5TB. Copiá-lo para a equipe de QA levaria horas e custaria outros 5TB. Com um Clone ZFS:
Cria-se um snapshot da produção (segundos).
Cria-se um clone a partir desse snapshot (segundos).
O clone consome 0 bytes inicialmente.
À medida que o QA escreve no banco de dados do clone, apenas os blocos alterados consomem espaço novo.
A Cadeia de Dependência (Dependency Hell)
A decisão arquitetural crítica aqui é o gerenciamento do ciclo de vida. Um clone tem uma dependência rígida do snapshot de origem.
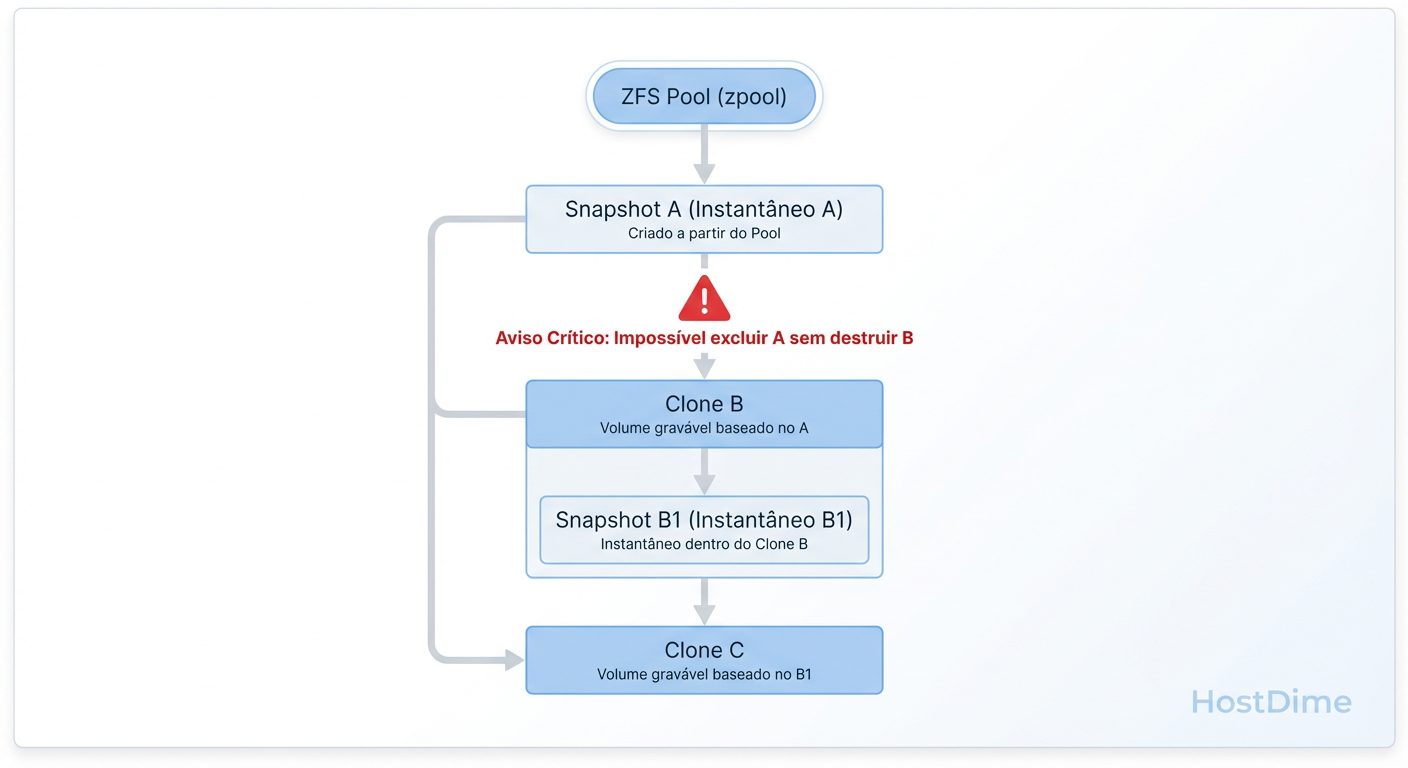 Figura: Cadeia de dependência de Clones ZFS. O snapshot de origem (Pai) não pode ser destruído enquanto o Clone (Filho) existir.
Figura: Cadeia de dependência de Clones ZFS. O snapshot de origem (Pai) não pode ser destruído enquanto o Clone (Filho) existir.
Você não pode destruir o snapshot pai enquanto o clone filho existir. Se você tem uma política de retenção automática que apaga snapshots com mais de 7 dias, e um desenvolvedor mantém um clone ativo por 30 dias, seu script de limpeza falhará ou o espaço não será liberado.
# Criando um clone para teste
zfs snapshot tank/prod/db@hoje
zfs clone tank/prod/db@hoje tank/test/db_qa
# Promovendo um clone (inverte a dependência se o clone virar a nova prod)
zfs promote tank/test/db_qa
Fluxos de Replicação com ZFS Send e Receive
A replicação baseada em snapshots (zfs send / zfs receive) é superior a rsync ou cópias em nível de bloco tradicionais por ser "ciente da estrutura".
O ZFS não percorre o sistema de arquivos procurando o que mudou (o que leva tempo e IOPS). Ele já sabe o que mudou através dos ponteiros de nascimento dos blocos (birth time). Ao enviar um fluxo incremental (-i), o ZFS envia apenas os blocos criados entre o Snapshot A e o Snapshot B.
Tabela Comparativa: Métodos de Cópia
| Característica | ZFS Send/Recv | Rsync | Block Level Copy (dd) |
|---|---|---|---|
| Mecanismo | Serialização de transações/blocos | Comparação de arquivos/checksum | Cópia cega bit-a-bit |
| Delta Transfer | Sim (Instantâneo via ponteiros) | Sim (Lento, requer scan) | Não |
| Consistência | Atômica (Snapshot) | Não garantida (arquivos mudando) | Requer desmontagem/congelamento |
| Overhead na Origem | Baixo (Leitura sequencial de metadados) | Alto (Stat em todos os arquivos) | Alto (Leitura total) |
Estratégias de Pruning e Performance na Remoção
Para o arquiteto, o ciclo de vida do dado é tão importante quanto a criação. Como apagamos snapshots?
Antigamente, o comando zfs destroy era síncrono e podia travar o pool se o snapshot contivesse milhões de ponteiros únicos. O sistema precisava percorrer a árvore e marcar cada bloco como livre.
No OpenZFS moderno, existe a feature flag async_destroy. Quando você destrói um snapshot, o comando retorna quase imediatamente, e o trabalho de liberação de blocos ocorre em background.
Entretanto, cuidado: Ainda existe impacto de performance. O processo de "freeing" compete por IOPS com sua produção.
Evite "Mass Delete": Não configure scripts para apagar 500 snapshots de uma vez às 9h da manhã de segunda-feira.
Monitore a fila de deleção: Use
zpool get freeingpara ver quanto espaço está na fila para ser liberado.
Veredito Técnico
Dominar snapshots e clones no ZFS não é sobre decorar comandos, mas entender o fluxo dos dados no disco.
Se o workload é randômico e o storage é RAID-Z, limite a vida útil dos snapshots para evitar fragmentação e overhead de padding.
Se precisa de ambientes de teste rápidos, use Clones, mas monitore as dependências de snapshots órfãos.
Entenda que
Referencedé o que você vê, eUsedé o que você paga.
O ZFS oferece as ferramentas para uma arquitetura robusta, mas exige que o engenheiro assuma o controle da complexidade que ele abstrai.
Referências & Leitura Complementar
OpenZFS Documentation - zfs-concepts(7): Detalhes oficiais sobre a implementação de transações e snapshots.
Oracle Solaris ZFS Administration Guide: Embora antigo, contém os fundamentos teóricos da estrutura on-disk.
RFC Genérica de iSCSI/NFS: Para entender como snapshots interagem com protocolos de bloco e arquivo em camadas superiores.
"ZFS Mastery" por Michael W. Lucas: Leitura obrigatória para aprofundamento pragmático em administração.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.