Erasure Coding Alternativa A RAID Conceitos E Trade Offs
São 03:00 da manhã de uma terça-feira. O PagerDuty grita. Um disco de 16TB falhou no seu array de armazenamento principal. O sistema, configurado em RAID 6, com...
Erasure Coding Alternativa A RAID Conceitos E Trade Offs
São 03:00 da manhã de uma terça-feira. O PagerDuty grita. Um disco de 16TB falhou no seu array de armazenamento principal. O sistema, configurado em RAID 6, começa o processo de rebuild. Você respira fundo, toma um café e volta a dormir, certo?
Errado. Se você já operou armazenamento nessa escala, sabe que o terror está apenas começando.
Com discos mecânicos modernos atingindo densidades absurdas, a velocidade de leitura/escrita sequencial não acompanhou o crescimento da capacidade. Reconstruir um disco de 16TB em um array carregado pode levar dias. Durante esses dias, o array está em estado degradado, a performance cai drasticamente e, o pior de tudo: a matemática joga contra você. A probabilidade de um erro de leitura irrecuperável (URE - Unrecoverable Read Error) ou de uma segunda (e terceira) falha de disco durante o rebuild não é mais uma "teoria de caos", é uma certeza estatística.
O RAID tradicional, aquele amigo fiel que nos serviu desde os anos 90, tornou-se um passivo técnico perigoso em escala de Petabytes. Ele foi desenhado para um mundo onde falhas eram eventos discretos e isolados, e discos tinham 500MB.
Hoje, vamos dissecar o sucessor inevitável para sistemas distribuídos: Erasure Coding (EC). Não vamos falar sobre como configurá-lo no wizard da GUI, mas sim entender como ele quebra os dados, por que ele salva seu orçamento e, crucialmente, onde ele vai fazer sua latência explodir se você não souber o que está fazendo.
A Matemática Salva o Orçamento (e o Sono)
Para entender Erasure Coding, precisamos abandonar a visualização mental de "blocos espelhados" do RAID 1 ou a paridade simples (XOR) do RAID 5. Precisamos pensar em álgebra.
Imagine que, em vez de guardar seus dados brutos, nós os transformamos em uma equação.
Se eu te disser que $x + y = 10$, você não sabe quanto valem $x$ ou $y$. Existem infinitas possibilidades. Mas, se eu te der uma segunda equação, $x - y = 2$, agora você tem um sistema. Você pode resolver e descobrir que $x=6$ e $y=4$.
O conceito fundamental do Erasure Coding é pegar um objeto de dados (digamos, uma foto ou um backup de VM), quebrá-lo em $k$ pedaços de dados e calcular $m$ pedaços de paridade (códigos) usando polinômios complexos (geralmente Reed-Solomon).
A mágica é: você pode perder quaisquer $m$ pedaços — sejam eles dados originais ou paridade — e ainda assim recuperar o arquivo original perfeitamente.
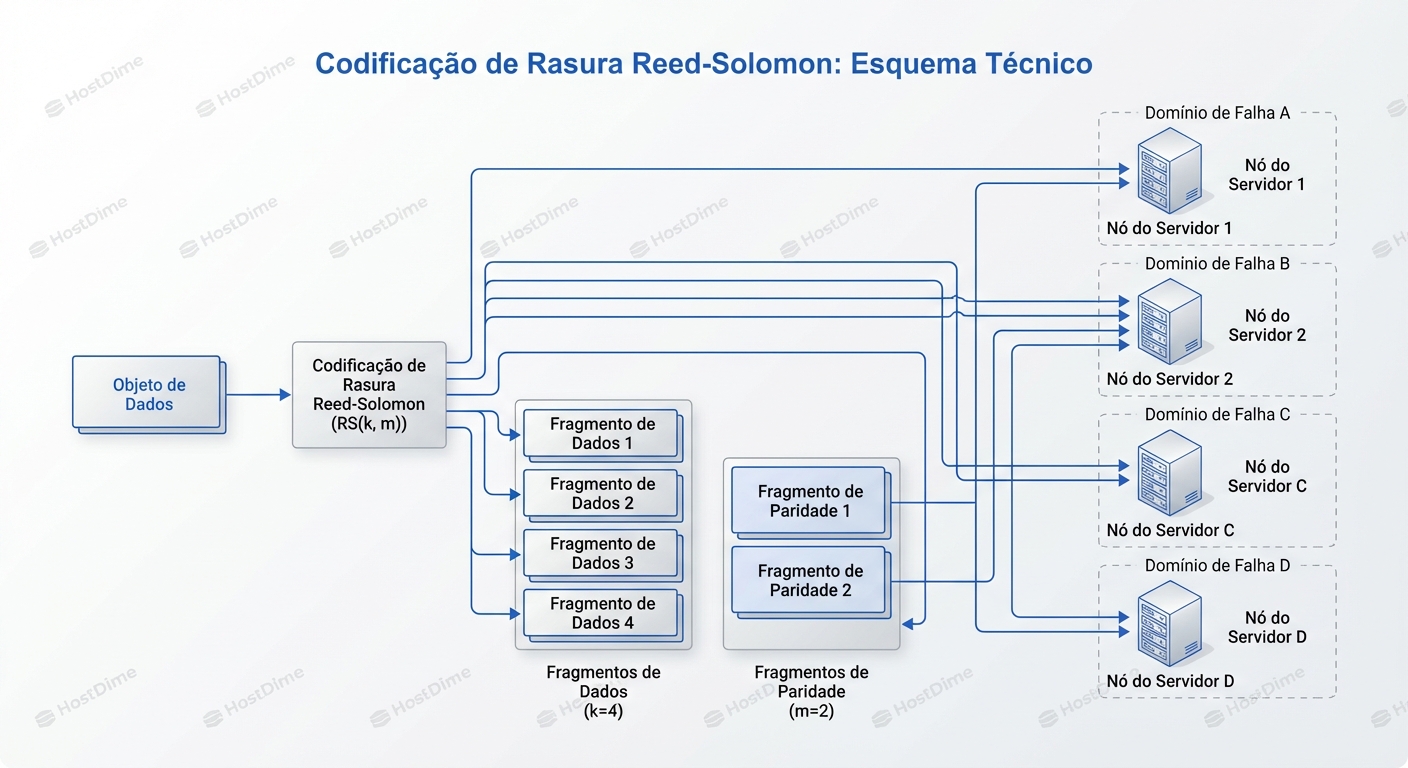
O Esquema $k + m$
Na prática, definimos esquemas como 4+2 (4 pedaços de dados, 2 de paridade).
- O arquivo é dividido em 4 fragmentos.
- Calculamos 2 fragmentos extras.
- Total de fragmentos armazenados: 6.
- Espaço ocupado: 1.5x o tamanho original.
- Tolerância a falhas: Pode perder quaisquer 2 discos (ou servidores inteiros) e o dado sobrevive.
Compare isso com o RAID 1 (espelhamento). Para ter tolerância a falhas, o RAID 1 exige 2x o espaço (200% de overhead). O RAID 6 exige 2 discos de paridade fixos por grupo. O EC permite ajustar essa "alavanca" de durabilidade versus custo com precisão cirúrgica.
Em um cluster de 10 Petabytes, a diferença entre usar Replica x3 (padrão em muitos sistemas distribuídos como Hadoop ou Ceph antigo) e Erasure Coding 8+3 é a diferença entre comprar 30PB de disco ou apenas 13.75PB. Estamos falando de milhões de dólares em hardware, energia e refrigeração.
Por Dentro da Máquina: Reed-Solomon e a Distribuição
O que acontece "under the hood" quando você grava um arquivo em um sistema usando EC (como Ceph, MinIO ou Swift)?
- Ingestão e Buffer: O dado chega ao gateway do sistema. Ele não é escrito imediatamente no disco final. Geralmente, ele é bufferizado na memória.
- Segmentação (Sharding): O algoritmo divide o objeto em $k$ partes iguais.
- Cálculo Polinomial: A CPU entra em ação. Diferente do XOR do RAID 5 (que é uma operação binária baratíssima), o Reed-Solomon envolve aritmética de campo finito (Galois Field). O sistema calcula os $m$ fragmentos de paridade.
- Dispersão (Placement): Aqui está o pulo do gato que torna o EC superior ao RAID de hardware. O sistema não grava esses $k+m$ fragmentos em discos vizinhos no mesmo chassi. Ele consulta um mapa da topologia do cluster (no Ceph, isso é o mapa CRUSH).
- O fragmento 1 vai para o Servidor A, Rack 1.
- O fragmento 2 vai para o Servidor B, Rack 2.
- O fragmento 3 vai para o Servidor C, Rack 3.
- ... e assim por diante.
Isso nos leva a um conceito crítico: Domínio de Falha.
No RAID tradicional, seu domínio de falha é o chassi do servidor. Se a backplane do servidor queimar, ou a controladora RAID fritar, você perdeu o acesso a todos os discos daquele array.
No Erasure Coding distribuído, o domínio de falha é o cluster. Você pode perder um rack inteiro de servidores (digamos que o switch Top-of-Rack morreu). Se o seu esquema de EC for desenhado para espalhar dados entre racks, seu serviço continua de pé, servindo dados, sem perda de integridade. O sistema percebe a falha do rack e começa a reconstruir os pedaços faltantes nos racks sobreviventes.
A Recuperação Paralela (O Fim do Rebuild Lento)
Lembra do pesadelo do rebuild do RAID 6? Ele é lento porque o disco de spare (reserva) é o gargalo. Todo o dado precisa ser escrito em um único disco físico. A velocidade de recuperação é limitada pela IOPS de escrita desse único disco.
No Erasure Coding, a recuperação é Muitos-para-Muitos.
Se um disco morre em um cluster Ceph com EC:
- O sistema detecta que os fragmentos (shards) daquele disco estão faltando.
- Para cada objeto afetado, o sistema lê os $k$ fragmentos necessários de outros discos espalhados por todo o cluster.
- O sistema recalcula o dado perdido.
- O sistema grava o novo fragmento em qualquer outro disco que tenha espaço livre no cluster.
Não existe um "disco de spare" dedicado esperando. Todo espaço livre no cluster é espaço de spare. O tráfego de reconstrução é diluído entre centenas de discos e dezenas de interfaces de rede. Um cluster bem dimensionado pode recuperar um drive de 16TB em questão de horas, não dias, com impacto mínimo na performance global.
O Preço da Eficiência: Latência e CPU
Não existe almoço grátis em engenharia de sistemas. Se o Erasure Coding oferece resiliência extrema e eficiência de armazenamento fantástica, quem paga a conta?
A resposta é: Sua CPU e sua Latência de Cauda.
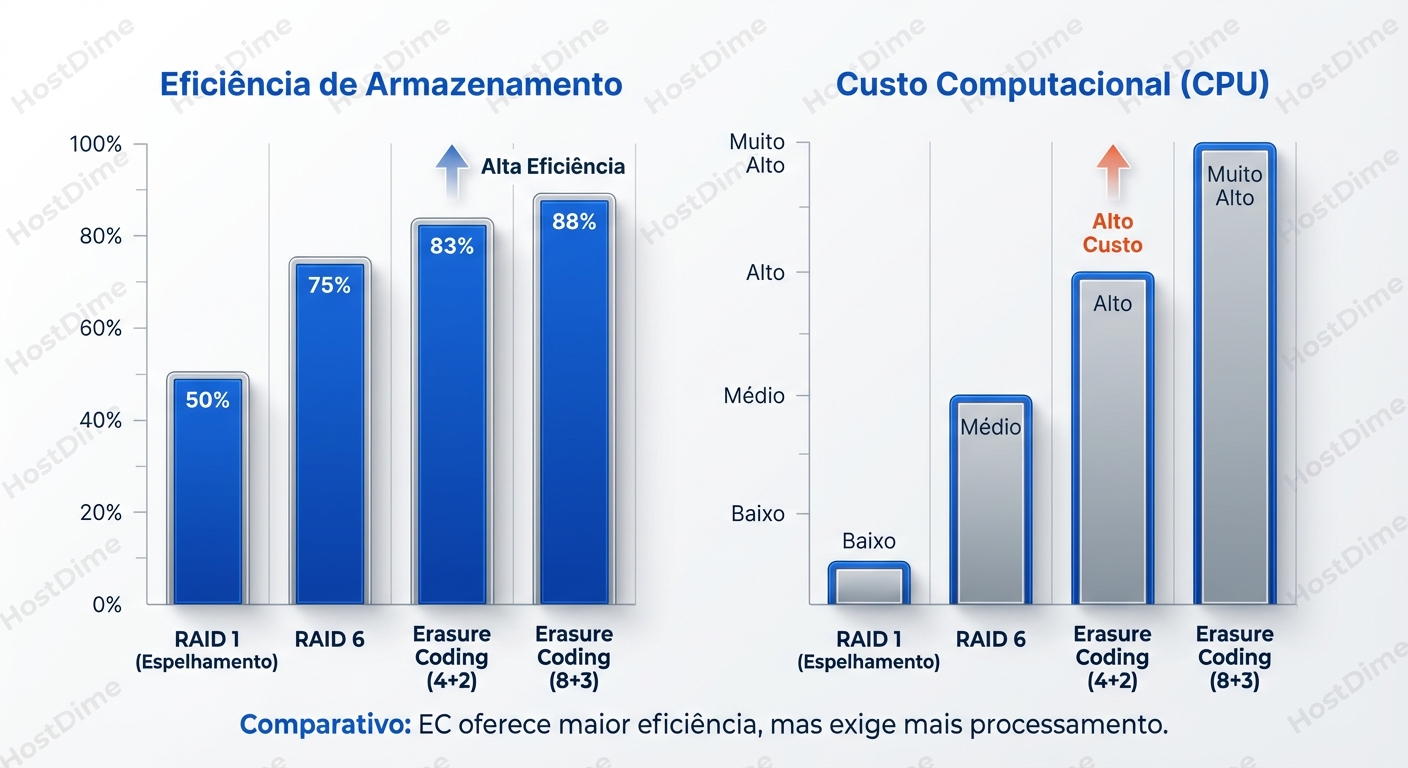
O Custo Computacional
Calcular paridade Reed-Solomon é intensivo. Enquanto o espelhamento (Replica) é apenas uma cópia de memória para rede, o EC exige ciclos de processador para cada byte escrito.
- Escrita: O cliente envia o dado -> CPU calcula paridade -> Envia para $N$ nós.
- Leitura (Cenário Saudável): O sistema lê apenas os $k$ fragmentos de dados. Não há custo de CPU para decodificar, a menos que...
- Leitura (Cenário Degradado): Se um disco contendo um fragmento de dados estiver lento ou morto, o sistema precisa ler os fragmentos de paridade e reconstruir o dado original em tempo real (on-the-fly) antes de entregar ao cliente. Isso causa um pico de latência perceptível.
O Pesadelo da Escrita Pequena (Write Amplification)
Este é o ponto onde a maioria das implementações de EC falha catastroficamente se o Sysadmin não estiver atento. EC odeia escritas pequenas e aleatórias.
Imagine que você tem um esquema 4+2 e seus objetos são "stripados" em blocos de 4MB (1MB por fragmento de dados). Se você precisa alterar apenas 4KB dentro desse arquivo:
- O sistema não pode apenas escrever os 4KB.
- Ele precisa Ler o stripe inteiro (os 4MB originais + paridade).
- Ele modifica os 4KB na memória.
- Ele Recalcula a nova paridade para todo o conjunto.
- Ele Reescreve os novos fragmentos e a nova paridade.
Isso é o clássico Read-Modify-Write. Uma escrita de 4KB transformou-se em megabytes de leitura e escrita na rede e disco. A latência vai para o espaço.
Regra de Ouro: Nunca use Erasure Coding direto para hospedar discos virtuais de VM (RBD/EBS) ou bancos de dados transacionais de alta performance, a menos que você tenha uma camada de cache de escrita (Write-Log ou WAL) muito robusta em SSDs/NVMe na frente (como o BlueStore RocksDB no Ceph). EC é rei para Object Storage (S3, backups, vídeos, logs), mas é um plebeu para Block Storage aleatório.
Diagnóstico e Observabilidade: O Que Procurar
Como Sysadmin, você não quer apenas confiar na teoria. Você precisa ver o sistema funcionando. Vamos usar o ecossistema Ceph como base para os exemplos, pois é a implementação open-source de referência, mas a lógica se aplica a MinIO, Swift e outros.
1. Identificando o Perfil de EC
Primeiro, verifique se o seu pool está realmente usando EC e qual o perfil.
# No Ceph
ceph osd pool ls detail
Procure na saída algo como erasure_code_profile=k4m2. Isso confirma que você está operando em 4+2. Se você ver replicated size 3, você está gastando o dobro do disco necessário para dados frios.
2. O Estado "Degraded" vs "Undersized"
No mundo RAID, "Degraded" é pânico. No mundo EC, precisamos de nuances.
Use:
ceph health detail
Se você ver PGs (Placement Groups) marcados como degraded, significa que alguns fragmentos estão faltando, mas o dado ainda pode ser reconstruído (você tem shards suficientes > $k$).
Se você ver undersized, o sistema tem menos cópias do que o desejado, mas talvez ainda tenha todas os dados, só faltam paridades.
O perigo real é incomplete ou unfound. Isso significa que você perdeu mais fragmentos do que a paridade ($m$) consegue cobrir. Nesse ponto, a matemática falhou. O dado foi perdido.
3. Latência de Recuperação (Slow Requests)
Quando um nó falha e a recuperação começa, o tráfego de rede explode. Diferente do RAID, onde olhamos o LED do disco, no EC olhamos para a saturação do switch.
Comando útil para monitorar em tempo real se a recuperação está matando a latência do cliente:
ceph osd perf
Ou observe os "Slow ops" nos logs. Se você notar que as operações de leitura estão ficando lentas durante uma recuperação, é sinal de que a CPU dos nós sobreviventes está saturada recalculando hashes e paridades.
Dica de Trincheira: Em sistemas EC, a rede é o backplane de armazenamento. Se você usa EC em uma rede de 1Gbps, você vai sofrer. EC em escala exige 10Gbps, 25Gbps ou mais, com Jumbo Frames habilitados (MTU 9000) para maximizar a eficiência do transporte dos fragmentos grandes.
Comparativo Direto: Quando usar o quê?
| Característica | RAID 10 / Replica x3 | Erasure Coding (ex: 4+2) |
|---|---|---|
| Eficiência de Disco | Baixa (33% a 50% utilizável) | Alta (66% a 90% utilizável) |
| Durabilidade | Alta (tolera falhas de disco) | Extrema (tolera falhas de Rack/Site) |
| Custo de CPU | Insignificante | Alto (cálculo de polinômios) |
| Performance de Leitura | Muito Alta (lê da cópia mais rápida) | Média/Alta (latência maior em degradação) |
| Performance de Escrita | Alta (limitada por disco/rede) | Média/Baixa (penalidade em escritas pequenas) |
| Tempo de Rebuild | Lento (gargalo no disco spare) | Rápido (paralelizado no cluster) |
| Uso Ideal | DBs, VMs, Hot Data | Backups, Arquivos, Mídia, Logs, Big Data |
A Obsolescência Programada do Hardware RAID
A indústria de armazenamento está passando por uma mudança tectônica. As controladoras RAID de hardware (aquelas placas caras da Dell/HPE com bateria de cache) estão se tornando irrelevantes para o armazenamento em escala.
Por quê? Porque o RAID de hardware é "burro" em relação aos dados. Ele vê blocos, não objetos. Ele não sabe que um arquivo JPG é menos crítico que um arquivo de metadados do banco. O Erasure Coding, implementado via software (SDS - Software Defined Storage), tem inteligência contextual.
Além disso, o gargalo mudou. Antigamente, usávamos placas RAID dedicadas para aliviar a CPU principal do cálculo de XOR. Hoje, temos CPUs com tantos núcleos (64, 128 cores) e instruções vetoriais avançadas (AVX-512) que calcular Reed-Solomon via software é trivial para o processador, tornando o hardware dedicado um custo desnecessário e um ponto único de falha.
A Decisão Arquitetural
Se você está desenhando uma infraestrutura hoje e alguém sugere "Vamos comprar um SAN enorme com RAID 6", seu alarme deve soar.
Erasure Coding não é apenas uma forma de economizar dinheiro em discos; é uma mudança de paradigma sobre como garantimos a perenidade da informação. Ele assume que o hardware vai falhar, que os discos vão corromper dados silenciosamente (bit rot) e que a rede é confiável.
No entanto, a armadilha está na implementação. Migrar uma carga de trabalho de banco de dados transacional de um array All-Flash RAID 10 para um cluster EC visando economia de custo é um convite para o desastre de performance.
O modelo mental correto para o Sysadmin moderno é o híbrido:
- Tier Quente (Flash/NVMe com Replica/RAID 10): Para o que precisa de latência de microssegundos e IOPS aleatórios insanos.
- Tier Morno/Frio (HDD/QLC Flash com Erasure Coding): Para os 80% dos dados que ocupam espaço massivo, precisam de durabilidade eterna, mas não exigem latência de tempo real para escrita.
O RAID serviu bem, mas em um mundo onde geramos mais dados em um dia do que gerávamos em um ano na década de 90, a força bruta do espelhamento perdeu para a elegância da álgebra. O futuro é codificado, distribuído e resiliente a falhas catastróficas. Você está pronto para confiar na matemática?

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.