Erasure Coding vs. RAID 6: A Matemática da Sobrevivência em Escala

RAID 6 não escala infinitamente. Entenda a matemática do Erasure Coding, o custo real em CPU/Latência e por que discos de 20TB mudaram as regras do jogo.
Se você está gerenciando storage em 2024 como fazia em 2014, você está sentado em uma bomba-relógio. Durante anos, o RAID 6 (dupla paridade) foi o nosso colete à prova de balas. Se um disco morresse, o sistema aguentava. Se outro morresse durante o rebuild, ainda estávamos vivos.
Mas a física mudou. Os discos giratórios (HDDs) não ficaram muito mais rápidos, mas ficaram obscenamente maiores. Um disco de 22TB hoje tem praticamente a mesma IOPS mecânica de um disco de 4TB de uma década atrás.
Isso cria o que chamamos de "O Muro do RAID". Neste artigo, vamos desmontar o marketing de vendors que vendem Erasure Coding (EC) como mágica, olhar para a matemática brutal por trás da durabilidade dos dados e entender quando abandonar o RAID tradicional não é uma opção, mas uma necessidade de sobrevivência.
O Muro do RAID: O Perigo dos 22TB
O problema do RAID 6 em discos modernos não é a falta de redundância; é o tempo de exposição ao risco.
Imagine um array RAID 6 com discos de 22TB. Um disco falha. Você espeta um novo. O controlador precisa ler cada bit dos discos restantes para reconstruir os dados no novo drive. A uma velocidade sustentada otimista de 200MB/s (e lembre-se, o rebuild compete com a I/O de produção), reconstruir 22TB leva cerca de 30 horas. Na prática, com carga de servidor, isso pode levar dias.
Durante esses dias, seus discos restantes estão sendo martelados em 100% de leitura. É aqui que entra o URE (Unrecoverable Read Error). Discos SATA corporativos geralmente têm uma taxa de erro de bits de 1 em $10^{15}$. Ao ler centenas de Terabytes para reconstruir um array, a estatística diz que você provavelmente encontrará um setor ilegível em um dos discos sobreviventes.
No RAID tradicional, isso é catastrófico ou, no mínimo, corrompe arquivos silenciosamente. O RAID 6 protege contra falhas totais de disco, mas luta contra a degradação bit a bit durante janelas de rebuild massivas.
A Álgebra dos Dados: Reed-Solomon sem Dor
Esqueça as matrizes complexas por um minuto. O Erasure Coding (EC) é, em essência, álgebra do ensino fundamental aplicada a blocos de dados.
Pense na equação: $A + B = C$. Se você tem $A$ e $B$, calcula $C$. Se você perde $A$, mas tem $B$ e $C$, você recupera $A$ ($C - B = A$).
O Erasure Coding usa o algoritmo Reed-Solomon para dividir um objeto (arquivo) em fragmentos de dados ($k$) e fragmentos de código/paridade ($m$). A notação comum é $k + m$.
Exemplo prático: EC 4+2
O sistema pega um arquivo e o divide em 4 pedaços de dados.
Ele calcula 2 pedaços de código (paridade).
Total de 6 pedaços distribuídos em 6 discos (ou servidores) diferentes.
Você pode perder quaisquer 2 pedaços (discos ou servidores inteiros) e ainda ler o arquivo original.
A grande diferença mental aqui é que o RAID opera no nível do volume (cega para o que é dado e o que é espaço vazio), enquanto o EC (em Object Storage e sistemas modernos) opera no nível do objeto ou chunk. Se você tem um disco de 20TB com apenas 1TB de dados usado, o EC só precisa reconstruir 1TB. O RAID tradicional estupidamente reconstruiria todos os 20TB.
Matemática da Reconstrução: O Gargalo Geométrico
Aqui é onde o "hype" do Erasure Coding se justifica com física. A maior falha do RAID é a geometria do rebuild.
Em um RAID tradicional, quando um disco falha, todos os discos sobreviventes leem dados, mas apenas um disco (o spare) escreve. A velocidade de recuperação é limitada pela velocidade de gravação desse único disco substituto. É um problema de "Muitos-para-Um".
Em um sistema distribuído com Erasure Coding (como Ceph, MinIO ou Swift), a reconstrução é "Muitos-para-Muitos".
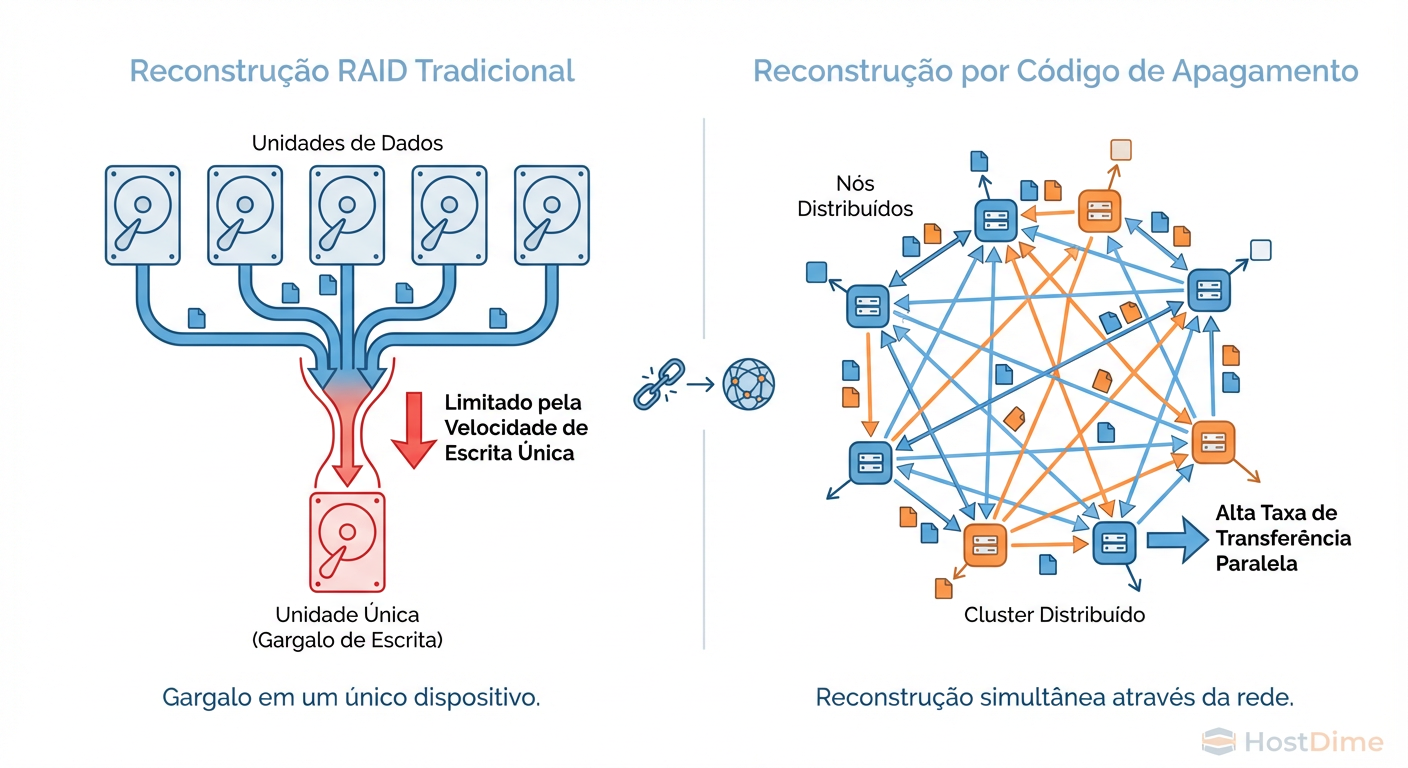 Figura: Geometria do Rebuild: O RAID é limitado pela velocidade de escrita de um único disco. O EC utiliza a largura de banda agregada de todo o cluster.
Figura: Geometria do Rebuild: O RAID é limitado pela velocidade de escrita de um único disco. O EC utiliza a largura de banda agregada de todo o cluster.
Figura: Geometria do Rebuild: O RAID é limitado pela velocidade de escrita de um único disco. O EC utiliza a largura de banda agregada de todo o cluster.
Quando um disco morre em um cluster EC:
O sistema percebe que os chunks daquele disco estão faltando.
Todos os outros discos no cluster começam a ler os pedaços sobreviventes.
Os dados reconstruídos são escritos em todos os discos que têm espaço livre no cluster.
Não existe um "disco de spare" ocioso esperando. O espaço livre em todo o cluster é o seu spare. Isso significa que, quanto maior o seu cluster, mais rápido é o rebuild. Em grandes clusters Ceph bem arquitetados, vi recuperações de drives de 10TB acontecerem em menos de 30 minutos, porque a largura de banda de escrita foi pulverizada entre centenas de OSDs.
CALLOUT: O Risco da Rede No Erasure Coding distribuído, o gargalo sai do disco e vai para a Rede. Se você tentar rodar um cluster Ceph ou MinIO com EC em uma rede de 1Gbps, você vai chorar. 10Gbps é o mínimo absoluto; 25Gbps ou 100Gbps é onde a mágica acontece. Sem largura de banda de rede, o EC é mais lento e perigoso que o RAID local.
Não Existe Almoço Grátis: Latência e CPU
Se o EC é tão bom, por que não usamos em tudo? Porque ele é caro computacionalmente e lento para pequenas gravações.
Penalidade de CPU: Calcular Reed-Solomon exige ciclos de processador. Embora instruções modernas (AVX2/AVX-512) tenham acelerado isso, ainda é muito mais pesado que um simples XOR do RAID 5.
Penalidade de Latência (Write Amplification): Em um RAID 10 (espelhamento), você escreve A e B. Fim. No EC, para alterar um pequeno bloco de 4k em um esquema 4+2, o sistema precisa:
- Ler os dados antigos.
- Ler a paridade antiga.
- Recalcular a nova paridade.
- Escrever os novos dados e a nova paridade.
- Esperar o Ack (confirmação) de múltiplos nós pela rede.
Isso destrói a performance de IOPS aleatórios (Random Write). É por isso que você nunca deve colocar um banco de dados transacional (como PostgreSQL ou MySQL) diretamente sobre um volume com Erasure Coding agressivo sem uma camada de cache robusta ou arquitetura específica.
Eficiência de Armazenamento: O Imposto do Hardware
Onde o EC ganha a discussão na diretoria é no orçamento. O RAID 10 oferece excelente performance, mas você joga 50% do seu dinheiro no lixo (overhead de 50%). O RAID 6 melhora isso, mas com 2 discos de paridade por grupo, a eficiência cai drasticamente se os grupos forem pequenos.
O Erasure Coding permite esquemas largos, como 8+3 ou 16+4, mantendo uma durabilidade insana com baixo overhead.
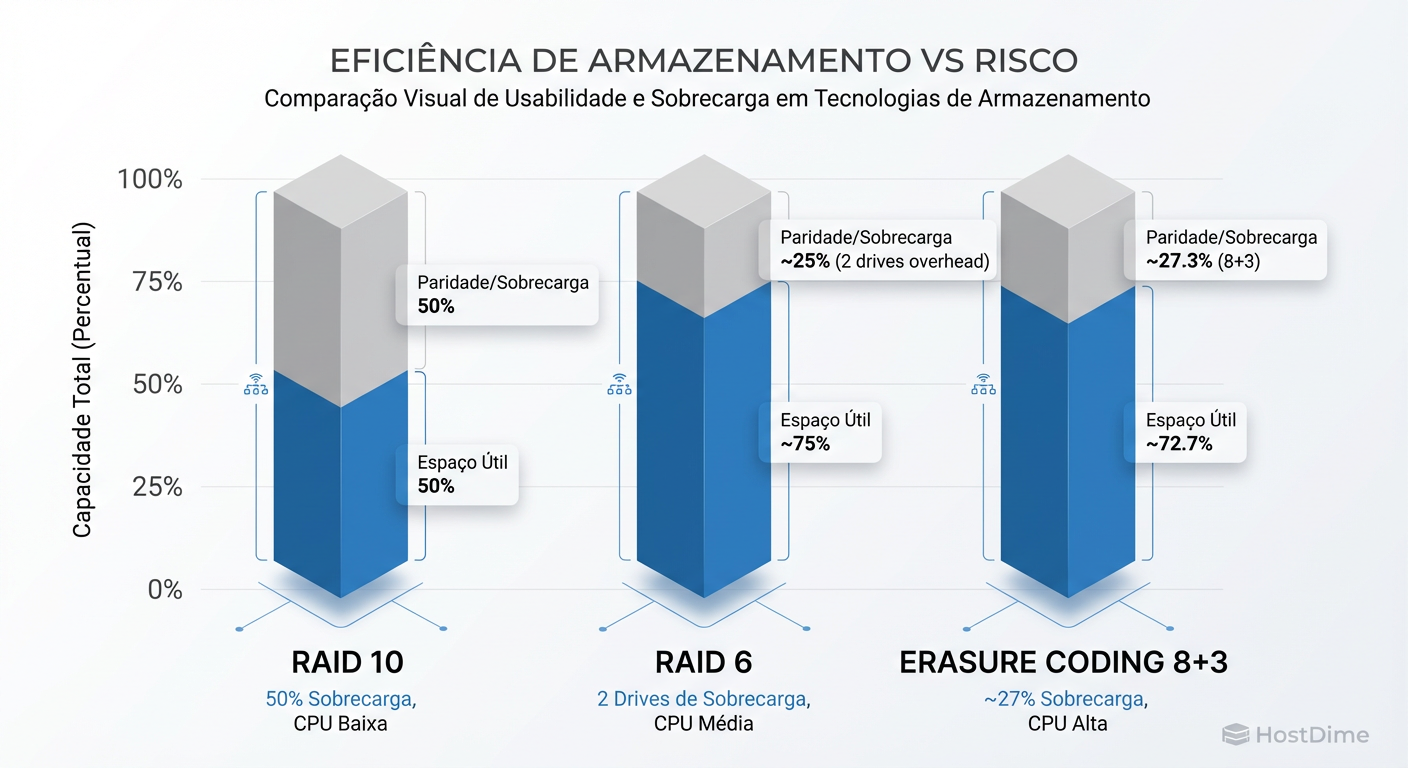 Figura: A Economia do Storage: Quanto maior o cluster, mais caro se torna o 'imposto' do RAID tradicional. O EC permite proteção robusta com menos hardware.
Figura: A Economia do Storage: Quanto maior o cluster, mais caro se torna o 'imposto' do RAID tradicional. O EC permite proteção robusta com menos hardware.
Figura: A Economia do Storage: Quanto maior o cluster, mais caro se torna o 'imposto' do RAID tradicional. O EC permite proteção robusta com menos hardware.
Vamos aos números frios:
| Esquema | Proteção (Falhas Simultâneas) | Overhead (Custo Extra) | Eficiência (Dados Úteis) | Cenário Ideal |
|---|---|---|---|---|
| RAID 10 | 1 (até 50% se tiver sorte) | 100% | 50% | Boot, DBs, VMs de alta IOPS |
| RAID 6 (4+2) | 2 Discos | 50% | 66% | NAS Local, Backup Pequeno |
| EC 4+2 | 2 Discos/Nós | 50% | 66% | Cluster Pequeno (Object) |
| EC 8+3 | 3 Discos/Nós | 37.5% | 72% | Arquivamento, Media Server |
| EC 16+4 | 4 Discos/Nós | 25% | 80% | Big Data, Data Lakes, Cold Storage |
Note que no EC 16+4, você pode perder 4 discos (ou servidores inteiros, dependendo da CRUSH map/topologia) e ainda tem acesso aos dados, pagando apenas 25% de "imposto" de armazenamento. Tentar obter tolerância a 4 falhas com RAID tradicional exigiria arranjos complexos e ineficientes (como RAID 60 ou tripla paridade proprietária).
Para verificar um perfil de EC em um sistema como Ceph, não confie na interface gráfica. Vá ao terminal:
ceph osd erasure-code-profile get default
# Procure por k (data chunks) e m (coding chunks)
# plugin=jerasure
# technique=reed_sol_van
Veredito Prático: Onde usar o quê?
Não existe "melhor". Existe a ferramenta certa para o workload certo. Aqui está o guia de decisão para o Sysadmin pragmático:
1. Fique com ZFS RAIDZ2/RAIDZ3 (Local) Se:
Escala: Você tem apenas um ou dois servidores de storage (Scale-up).
Latência: Você precisa de baixa latência de acesso a arquivos (SMB/NFS tradicional).
Simplicidade: Você não tem uma equipe dedicada para gerenciar a complexidade de um sistema distribuído como Ceph.
Nota: O RAIDZ do ZFS é tecnicamente um Erasure Coding, mas limitado a um chassi local. Ele resolve o problema do "write hole", mas ainda sofre com o tempo de rebuild limitado pela performance do disco único local.
2. Migre para Object Storage com EC (Distribuído) Se:
Escala: Você está cruzando a barreira de 500TB - 1PB.
Durabilidade: Você não pode tolerar a queda de um storage server inteiro (com RAID local, se o servidor cai, os dados somem até ele voltar; com EC distribuído, o cluster se cura).
Custo: Você precisa armazenar backups de longo prazo, logs, imagens ou documentos onde a eficiência de 80% (EC 16+4) paga o salário da equipe de operações.
Throughput: Você precisa de larguras de banda massivas para streaming ou ingestão de dados que um único controlador RAID não consegue entregar.
Resumo final: O RAID 6 não morreu, mas foi rebaixado para a "segunda divisão" do storage: o boot, o cache e as configurações locais de pequena escala. Para dados em repouso em escala de Petabytes, a matemática do Erasure Coding é a única coisa que separa você de uma perda de dados catastrófica.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.