Erasure Coding vs. RAID: O Fim da Redundância Local em Escala Petabyte

RAID 6 não escala. Descubra como o Erasure Coding resolve o dilema de custo vs. durabilidade em Object Storage (Ceph), entendendo a matemática e o preço de performance.
Quando um fornecedor de storage promete "a mesma performance do RAID 10 com a eficiência de espaço do RAID 6" usando Erasure Coding, meu instinto de arquiteto dispara um alerta imediato. A física do armazenamento não negocia, e a matemática da redundância cobra seu preço: ou você paga em capacidade bruta (Replicação/RAID 10) ou paga em ciclos de CPU e latência (Erasure Coding).
Se você está desenhando clusters de armazenamento acima de 500TB ou 1PB, o RAID convencional baseado em controladoras locais já morreu; ele só ainda não sabe disso. O tempo de reconstrução (rebuild) de discos de 18TB ou 22TB tornou o RAID 5 matematicamente suicida e o RAID 6 perigosamente lento.
No entanto, migrar cegamente para Erasure Coding (EC) sem entender o fluxo de I/O da sua aplicação é a receita perfeita para construir um sistema que armazena petabytes de dados, mas não consegue entregar um único IOPS com latência decente. Vamos dissecar essa arquitetura.
Erasure Coding (EC) é um algoritmo de proteção de dados que fragmenta um objeto em $k$ pedaços de dados e $m$ pedaços de paridade, distribuindo-os através de diferentes nós de falha (servidores ou racks). Ao contrário do RAID, que opera no nível do bloco de disco local, o EC opera no nível do objeto ou arquivo distribuído, permitindo a reconstrução de dados via rede sem gargalos de uma única controladora, oferecendo maior durabilidade com menor overhead de armazenamento (ex: 1.5x vs 3x da replicação), mas introduzindo penalidades severas em escritas aleatórias.
A Falácia do RAID em Escala Petabyte
O modelo mental tradicional de "um disco falha, a controladora reconstrói" funcionava bem quando os HDDs tinham 300GB. Hoje, a densidade dos discos cresceu exponencialmente, mas a velocidade de leitura/escrita sequencial dos pratos magnéticos estagnou.
O problema central é a URE (Unrecoverable Read Error). Discos SATA corporativos geralmente possuem uma taxa de erro de bits não recuperáveis de 1 em $10^{15}$. Ao reconstruir um array RAID 6 de 200TB, você está lendo cada bit restante para calcular a paridade. A probabilidade estatística de encontrar um erro de leitura durante o rebuild — o que falharia a reconstrução ou corromperia o volume — aproxima-se de 100% à medida que o volume do array cresce.
Além disso, o "Domínio de Falha" no RAID local é o chassi. Se o backplane do servidor queima, seus dados estão offline, não importa quão bom seja seu RAID. Em escala Petabyte, não nos preocupamos apenas com discos morrendo; nos preocupamos com racks inteiros perdendo energia.
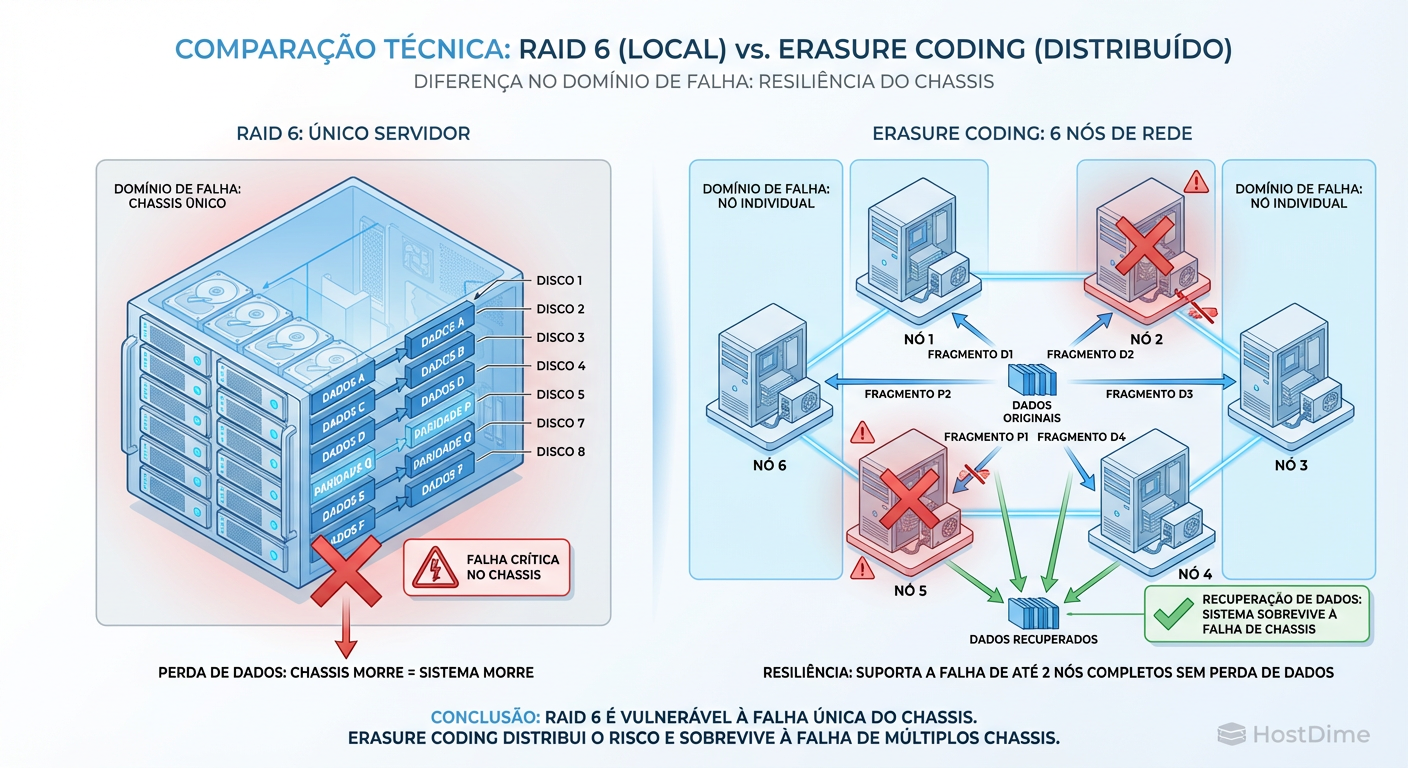 Figura: RAID Local vs. Erasure Coding Distribuído: O isolamento de falhas é a chave da durabilidade.
Figura: RAID Local vs. Erasure Coding Distribuído: O isolamento de falhas é a chave da durabilidade.
A imagem acima ilustra a diferença fundamental: o RAID protege o disco; o Erasure Coding protege o dado, isolando-o da infraestrutura física.
Matemática do Erasure Coding (k+m) Explicada
Muitos arquitetos evitam EC porque parece complexo. Não é. Se você entende álgebra básica, você entende Reed-Solomon, o algoritmo mais comum por trás do EC.
A notação padrão é $k + m$, onde:
$k$: Número de fragmentos de dados (Data Chunks).
$m$: Número de fragmentos de codificação/paridade (Coding Chunks).
Imagine que você tem um arquivo e usamos um esquema 4+2.
O sistema divide o arquivo em 4 pedaços.
Ele calcula matematicamente 2 pedaços extras de paridade.
Total de pedaços gravados: 6.
Total de perdas admissíveis: 2 (qualquer combinação de dados ou paridade).
A Eficiência de Armazenamento
Aqui está o motivo financeiro pelo qual CFOs amam Erasure Coding.
Replicação 3x (Padrão Ceph/Cloud): Para guardar 1TB, você gasta 3TB brutos. Eficiência de 33%.
Erasure Coding 4+2: Para guardar 1TB, você gasta 1.5TB brutos ($6/4$). Eficiência de 66%.
Você dobrou sua eficiência de armazenamento e manteve a tolerância a falhas de dois componentes. Parece mágica? Agora vem a conta.
O Custo Oculto: Latência e a Penalidade Read-Modify-Write
Aqui é onde projetos de storage falham. O Erasure Coding não é "grátis". O custo foi transferido do CAPEX (discos) para a Latência e CPU.
Quando você grava um arquivo novo e grande (Streaming Write), o EC é fantástico. O sistema divide o arquivo em memória, calcula a paridade e despacha os $k+m$ pedaços para os nós em paralelo.
O pesadelo começa com escritas pequenas e aleatórias (Random Writes/Overwrites).
Se você precisa alterar apenas 4KB dentro de um objeto de 4MB que está codificado em EC, o sistema não pode simplesmente gravar esses 4KB. Ele entra no ciclo Read-Modify-Write (RMW):
Read: O sistema precisa ler os dados antigos ($k$) e a paridade antiga ($m$) da rede.
Modify: A CPU precisa subtrair a informação antiga e adicionar a nova para recalcular a paridade.
Write: O sistema grava os novos dados e a nova paridade.
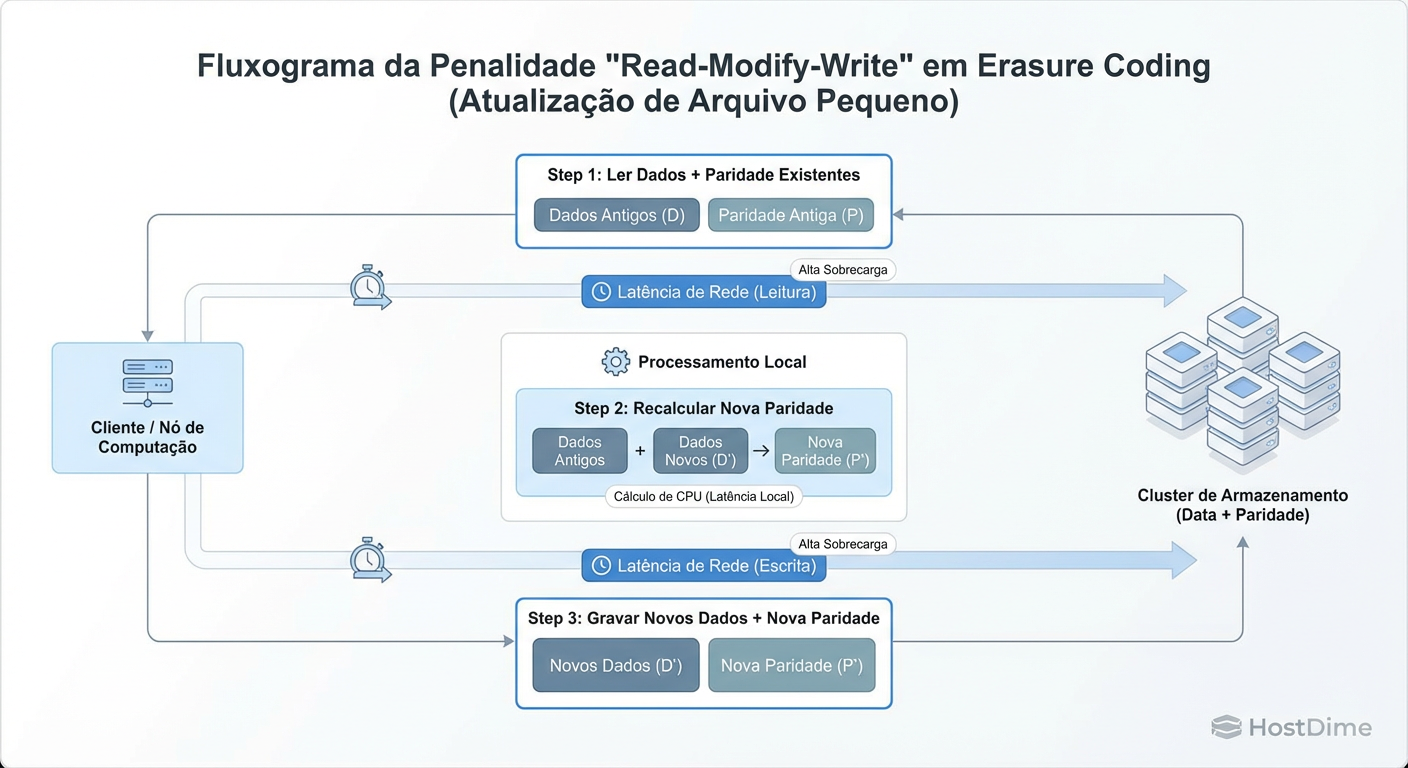 Figura: A Penalidade de Escrita Parcial: Por que pequenos updates matam a performance do Erasure Coding.
Figura: A Penalidade de Escrita Parcial: Por que pequenos updates matam a performance do Erasure Coding.
Isso transforma uma operação de escrita lógica em múltiplas operações de leitura e escrita física, atravessando a rede (RPCs) várias vezes. O resultado é uma latência de cauda (tail latency) altíssima e um consumo voraz de CPU.
Implementação no Ceph: Pools Replicados vs. EC
No mundo Enterprise Linux e OpenStack, o Ceph é o padrão de fato. Entender como ele lida com isso é crucial para a decisão de arquitetura.
O Ceph permite criar Pools com diferentes estratégias. Um erro comum é colocar cargas de trabalho de VM (RBD - Rados Block Device) diretamente em pools com Erasure Coding. O overhead do RMW destrói a performance do disco virtual.
Estratégia Híbrida (Tiering)
A abordagem correta não é escolher um ou outro, mas usar ambos onde fazem sentido:
Hot Storage (Replicação 3x): Discos NVMe/SSD. Usado para índices de banco de dados, discos de boot de VMs e logs ativos. O custo por GB é alto, mas o IOPS é garantido.
Cold/Warm Storage (Erasure Coding): HDDs de alta capacidade. Usado para Object Storage (S3), backups (Veeam/Commvault), imagens médicas e arquivos de vídeo.
Callout de Risco: No Ceph, operações de scrubbing (verificação de integridade) em pools EC são extremamente pesadas para a CPU. Se você dimensionar a CPU dos seus nós de storage "na conta do chá", seu cluster ficará indisponível durante as rotinas de manutenção.
Matriz de Decisão: Quando pagar por Storage ou Computação
Não existe "melhor prática", existe o trade-off correto para o seu SLA. Use esta tabela para guiar seu design:
| Característica | RAID 6 (Local) | Replicação 3x (Distribuída) | Erasure Coding (4+2) |
|---|---|---|---|
| Overhead de Espaço | Baixo (~1.2x - 1.3x) | Alto (3.0x) | Médio (1.5x) |
| Custo de Latência | Médio (Controladora) | Baixo (Rede apenas) | Muito Alto (Cálculo + Rede) |
| Reconstrução (Recovery) | Lento (Gargalo no disco) | Rápido (Muitos para muitos) | Médio (Limitado por CPU) |
| Isolamento de Falha | Disco | Nó/Rack | Nó/Rack |
| Caso de Uso Ideal | Boot de servidor local | Bancos de Dados, VMs | S3, Backups, Data Lakes |
| Risco Principal | URE durante rebuild | Custo proibitivo (TCO) | Performance em small writes |
Benchmark e Evidência: Medindo o Overhead
Não confie na folha de dados. Você deve medir a penalidade de escrita no seu ambiente. Se você utiliza Ceph, o rados bench é a ferramenta mais honesta para testar a performance bruta do objeto, removendo as camadas de sistema de arquivos (como CephFS ou RBD) da equação inicial.
1. Testando Throughput Sequencial (Cenário Ideal para EC)
Este teste simula um backup ou upload de vídeo. O EC deve ter performance aceitável aqui.
rados bench -p ec-pool 60 write --no-cleanup
2. Testando Latência de Escrita Pequena (O Ponto de Falha)
Aqui é onde a "matemática" cobra a conta. Compare os resultados deste comando entre seu pool replicado e seu pool EC.
# Teste de escrita randômica com blocos de 4KB (típico de DBs)
# Observe a latência média e a latência máxima (max_lat)
rados bench -p ec-pool 60 rand --b 4096
Se você rodar o comando acima em um pool EC 4+2 com HDDs, não se assuste se vir latências de 200ms a 500ms ou mais. Isso é a física do braço do disco mecânico somada ao tempo de ida e volta na rede para ler a paridade antiga.
Interpretação dos Dados
Para um Arquiteto de Soluções, o número mais importante não é a "Bandwidth" (MB/s), mas a Latência. Se a latência de escrita no EC for 10x maior que na replicação para blocos pequenos, você não pode colocar um banco de dados transacional ali, não importa quanta economia de disco isso gere.
Veredito Técnico: O Fim da Redundância Local?
Sim, para escalas de Petabytes, o RAID local acabou. Ele é um risco operacional inaceitável.
No entanto, o Erasure Coding não é um substituto direto "drop-in". Ele exige que a aplicação seja "storage-aware" (consciente do armazenamento) ou que você desenhe camadas de cache de escrita (Write Log/WAL) em mídia rápida (NVMe) para absorver o impacto imediato antes de descarregar os dados para o layout EC.
Pense certo: Replicação compra performance. EC compra capacidade. Meça certo: Teste sempre o pior cenário (small random writes). Decida certo: Nunca use EC para cargas de trabalho quentes sem uma camada de cache robusta na frente.
Referências & Leitura Complementar
Plank, J. S. (1997). A Tutorial on Reed-Solomon Coding for Fault-Tolerance in RAID-like Systems. University of Tennessee. (A base matemática explicada).
Weil, S. et al. (2006). Ceph: A Scalable, High-Performance Distributed File System. OSDI '06. (O paper fundamental do Ceph).
Google (2016). Availability in Globally Distributed Storage Systems. OSDI '16. (Análise de falhas em escala massiva).
RFC 9349. Erasure Coding for Bulk Data Transfer. (Conceitos de aplicação em rede).

Thomas 'Raid0' Wright
High-Performance Computing Researcher
Trabalha com supercomputadores. Para ele, velocidade é tudo, e redundância é problema do software.