Escalabilidade Horizontal: A Realidade da Migração de RAID Local para Storage Distribuído
O RAID local tem um teto físico. Entenda os trade-offs reais de latência, complexidade de rede e consistência ao migrar para storage distribuído (Ceph, GlusterFS, MinIO).
Todo sysadmin chega nesse momento. O servidor de arquivos principal está com 95% de ocupação. O array RAID 6 já tem discos de 18TB e o tempo de rebuild é aterrorizante. O orçamento para uma SAN proprietária nova é risível. Então, você lê sobre Ceph, GlusterFS ou MinIO. A promessa é sedutora: "Hardware commodity", "Escalabilidade infinita", "Autocura".
Parece a bala de prata. Você pega três servidores velhos, instala o software e acha que criou uma SAN Enterprise. Não criou. Você acabou de trocar um problema de gerenciamento de disco por um problema de gerenciamento de rede e consistência distribuída.
A migração de armazenamento local (DAS/RAID) para armazenamento distribuído (SDS - Software Defined Storage) não é uma atualização; é uma mudança de paradigma físico. Vamos dissecar o que acontece quando o cabo SAS sai de cena e o cabo Ethernet assume o comando.
Escalabilidade Horizontal em Storage é a arquitetura que permite expandir a capacidade e performance do sistema adicionando mais nós (servidores) ao cluster, em vez de adicionar mais discos a um único chassi (Escalabilidade Vertical). Diferente do RAID tradicional, que distribui blocos em discos locais fixos, o storage distribuído espalha dados via rede usando algoritmos de hashing, tratando a rede como o barramento de comunicação.
Entendendo o Teto do RAID Local e Gargalos de Controladora
Para entender por que migramos, precisamos ser honestos sobre o que estamos abandonando. O RAID local é incrivelmente eficiente. Uma controladora RAID moderna ou um HBA SAS passando ZFS tem latência quase direta do barramento PCIe. É simples, rápido e previsível.
Mas o RAID local tem um teto físico duro: a Controladora.
Existe um limite de quantos IOPS (Operações de Entrada/Saída por Segundo) uma única controladora consegue processar antes que sua fila de comandos sature. Existe um limite de largura de banda no backplane do chassi. E, o mais crítico: existe o limite do medo.
Quando você tem um RAID 6 de 100TB e um disco falha, o rebuild não é apenas lento; ele é um evento de estresse mecânico intenso em todos os outros discos sobreviventes. Se um segundo disco falhar durante o rebuild (o que é estatisticamente provável devido à carga), você perdeu tudo. O "Teto" do RAID local não é apenas capacidade; é o ponto onde o risco de operação vertical se torna inaceitável para o negócio.
Como o Sharding e Hashing Criam a Ilusão de Disco Infinito
No storage distribuído, não existe um "disco C:". O sistema operacional vê um ponto de montagem ou um target iSCSI, mas por trás disso, há uma mentira matemática elegante.
Quando você grava um arquivo de 1GB em um cluster distribuído, ele não vai para "o servidor 1". O arquivo é fatiado em pedaços menores (objetos ou chunks, geralmente de 4MB), e um algoritmo de Consistent Hashing (como o CRUSH no Ceph ou o Elastic Hashing no Gluster) calcula onde cada pedaço deve morar.
Isso elimina a necessidade de uma tabela central de metadados (que seria um gargalo único). Qualquer cliente pode calcular: "Onde está o objeto X?". A resposta matemática diz: "O objeto X pertence ao OSD 4 no Host B".
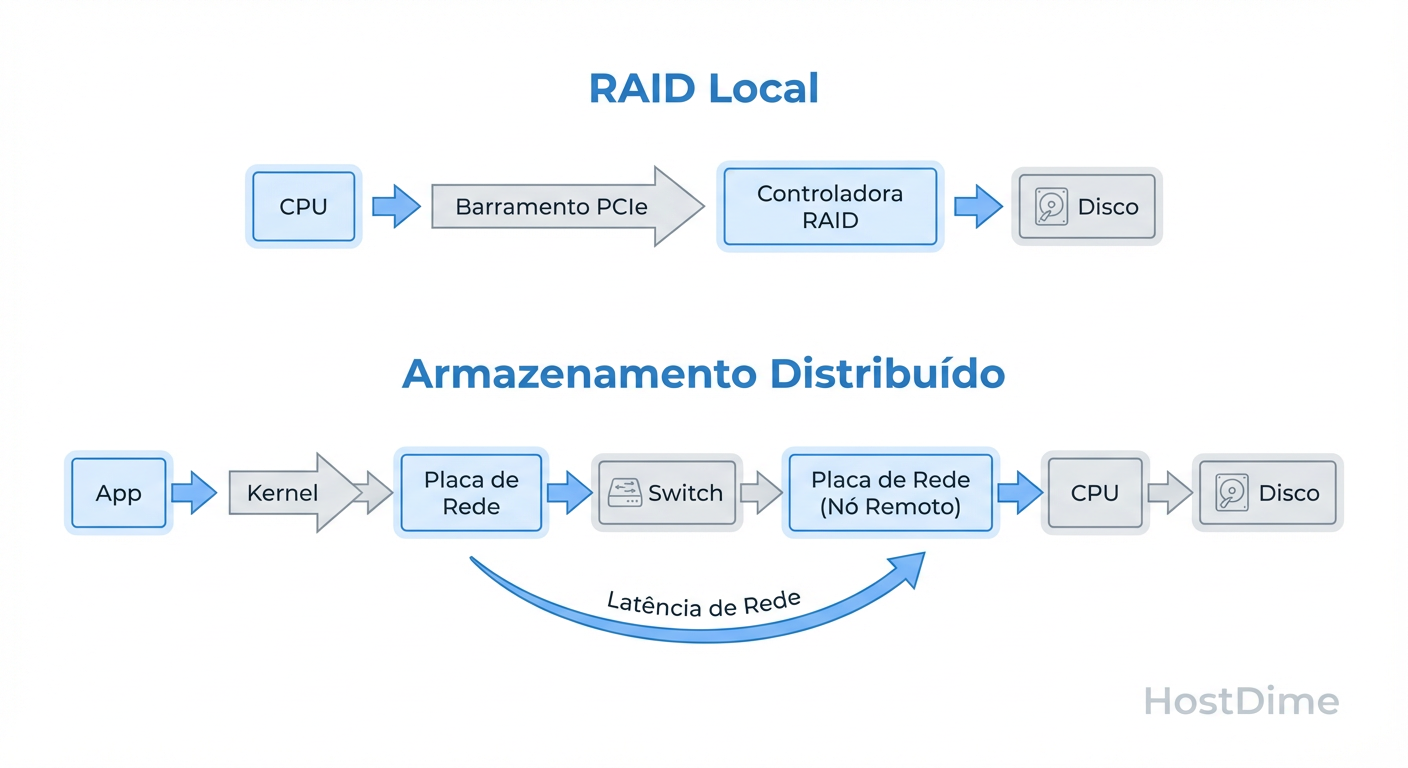 Figura: O Caminho do I/O: Comparativo visual entre a rota direta do RAID Local e os múltiplos 'hops' do Storage Distribuído.
Figura: O Caminho do I/O: Comparativo visual entre a rota direta do RAID Local e os múltiplos 'hops' do Storage Distribuído.
Essa distribuição é o que permite a tal "escalabilidade infinita". Se o cluster enche, você adiciona um novo nó. O algoritmo de hash percebe a nova topologia e rebalanceia os dados automaticamente. Parece mágica, mas o custo é a complexidade computacional. Cada leitura ou escrita exige cálculo de CPU e lookup de mapa de cluster. Não é "grátis".
A Rede como Novo Backplane: Impactos Reais na Latência
Aqui é onde a maioria dos projetos "faça você mesmo" falha. Em um servidor local, o backplane conecta o disco à CPU via PCIe. A latência é medida em microssegundos (ou nanossegundos com NVMe).
No storage distribuído, a sua rede Ethernet é o backplane.
Você trocou trilhas de cobre de 10 centímetros por cabos CAT6 ou Fibra de 20 metros, passando por switches, buffers de porta, filas de driver de rede e a pilha TCP/IP do kernel.
A brutalidade dos números
Não importa se você tem uma rede de 10Gbps ou 40Gbps. Largura de banda (throughput) não é Latência.
Acesso Local (NVMe): ~20 a 100 microssegundos.
Acesso Rede (10GbE otimizado): ~100 a 500 microssegundos (apenas o trânsito).
Acesso Distribuído (Rede + Protocolo + Disco Remoto): 1 a 5 milissegundos.
Se sua aplicação faz muitas escritas pequenas e síncronas (como um banco de dados transacional), mover para storage distribuído sem um cache de escrita local ou hardware de rede de baixíssima latência (RDMA/RoCE) vai destruir sua performance. O banco de dados vai passar a maior parte do tempo esperando o ACK da rede, não gravando dados.
Para provar isso, não confie no vendedor. Meça a latência de rede entre seus nós antes de instalar qualquer coisa:
# Teste de latência TCP sob carga (o cenário real de storage)
qperf -t 10 <IP_DO_NO_DESTINO> tcp_lat
Se sua latência de rede base for instável, seu storage será instável. Ponto.
Teorema CAP na Prática: Gerenciando Consistência e Disponibilidade em Falhas
O RAID local lida com falhas de forma binária: o disco funciona ou não. Storage distribuído vive no mundo nebuloso dos sistemas distribuídos, regido pelo Teorema CAP (Consistência, Disponibilidade, Tolerância a Partição). Você só pode ter dois.
Em storage, geralmente sacrificamos a Disponibilidade imediata para garantir a Consistência (CP), ou aceitamos dados eventualmente consistentes para manter o sistema no ar (AP).
O pesadelo real é o Split-Brain. Se o cabo de rede que liga o Rack A ao Rack B for cortado, mas ambos os racks continuarem ligados, quem detém a verdade?
Se você permitir escrita nos dois lados, corromperá os dados quando a rede voltar.
Se você bloquear a escrita, seu serviço para.
Sistemas robustos usam Quorum (ex: precisa de 2 de 3 votos para confirmar uma escrita). Isso significa que você precisa de, no mínimo, 3 nós para ter um cluster seguro. Com 2 nós, se um cai, o outro entra em modo somente leitura (ou arrisca corrupção) porque não sabe se o parceiro morreu ou se apenas a rede caiu.
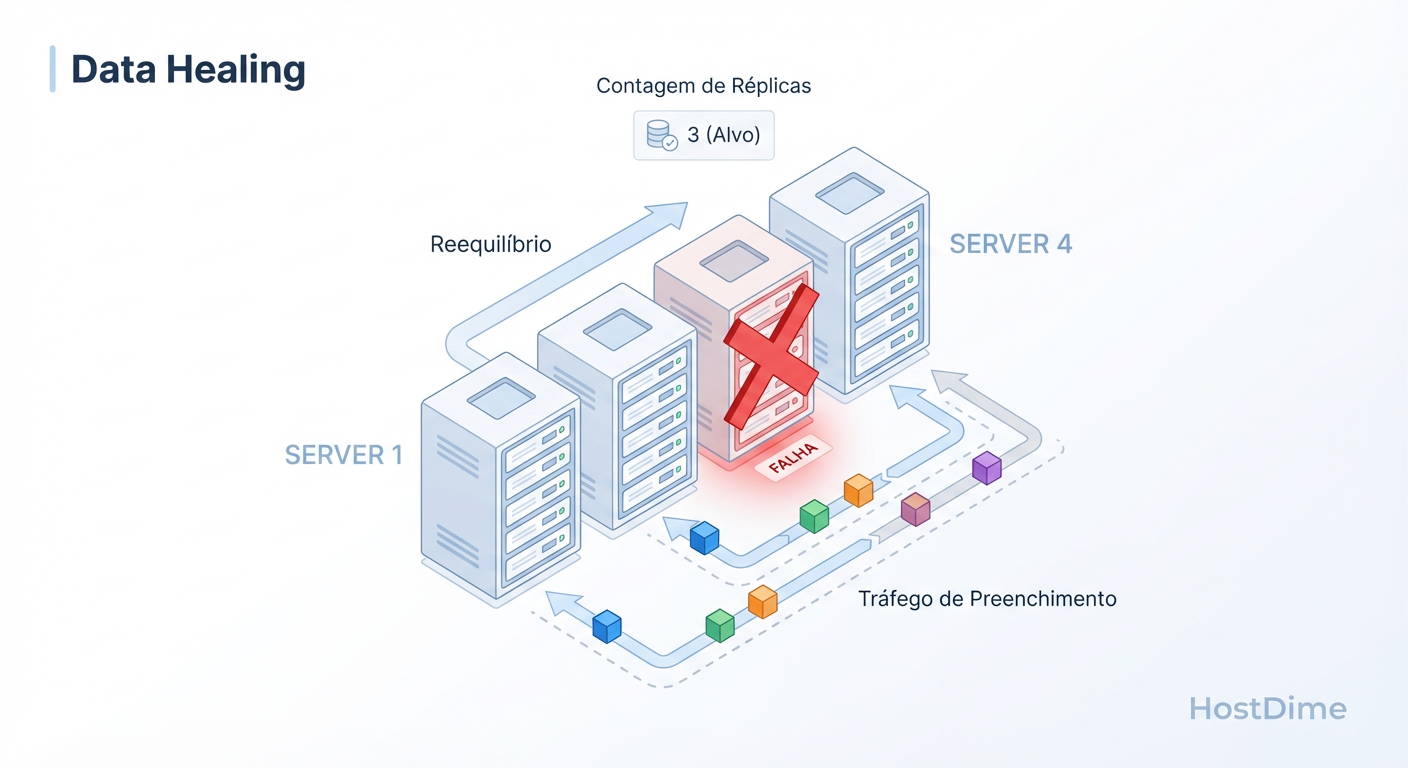 Figura: Autocura vs. Rebuild: Como o cluster reage à falha de um nó movendo dados pela rede, ao contrário do rebuild estático de um RAID.
Figura: Autocura vs. Rebuild: Como o cluster reage à falha de um nó movendo dados pela rede, ao contrário do rebuild estático de um RAID.
A grande vantagem, ilustrada acima, é que a recuperação não exige um disco spare dedicado esperando passivamente. O espaço livre de todos os discos do cluster atua como área de recuperação. A autocura é paralela: 10 discos enviando dados para outros 10 discos é muito mais rápido que 1 disco novo sendo gravado linearmente.
Custos Ocultos de Amplificação de Escrita e Overhead de Metadados
Você orçou 100TB de discos para armazenar 50TB de dados, pensando em usar espelhamento (Replica 2)? Esqueça.
Replica 3 é o Padrão: Em ambientes distribuídos, Replica 2 é perigoso. Se um nó cai (você fica com 1 cópia) e durante a recuperação ocorre um erro de leitura (bit rot) no sobrevivente, o dado foi perdido. O padrão de produção é Replica 3. Isso significa 33% de eficiência de armazenamento. Para guardar 1TB, você gasta 3TB brutos.
Amplificação de Rede: Para escrever 1MB de dados, seu cliente envia 1MB para o nó primário. O nó primário envia 1MB para a réplica secundária e mais 1MB para a terciária. O tráfego interno do cluster (East-West traffic) é massivo.
Erasure Coding (EC): É a alternativa ao espelhamento (parecido com RAID 5/6 via rede). Aumenta a eficiência de espaço (ex: 60-70%), mas destrói a performance de escrita devido ao cálculo de paridade e fragmentação de pacotes na rede.
Tabela Comparativa: A Realidade Operacional
| Característica | RAID Local (Hardware/ZFS) | Storage Distribuído (Ceph/Gluster) | Veredito Pragmático |
|---|---|---|---|
| Latência | Baixíssima (Microsegundos) | Média/Alta (Milissegundos) | RAID vence para Bancos de Dados. |
| Throughput | Limitado pela controladora | Escala com nº de nós | Distribuído vence para Streaming/Arquivos grandes. |
| Falha de Disco | Rebuild lento e arriscado | Rebalanceamento rápido e paralelo | Distribuído é muito mais seguro em escala. |
| Custo Inicial | Alto (Controladora + Shelf) | Médio (Hardware commodity) | Distribuído parece barato, mas exige mais RAM/CPU. |
| Complexidade | "Plug and Play" | Requer Engenharia de Rede | Não use distribuído se não tiver equipe capaz. |
Checklist de Migração: Quando o Storage Distribuído Vale a Pena
Não migre por hype. Migre se você atingiu limites físicos. Use este checklist antes de formatar seus servidores:
Volume de Dados: Você tem mais de 500TB ou 1PB?
- Sim: Distribuído é quase obrigatório. RAID tradicional é ingeriável nesse tamanho.
- Não: Um bom servidor ZFS ou uma SAN básica dão menos dor de cabeça.
Crescimento: Você precisa adicionar capacidade sem parar o serviço (downtime)?
- Sim: Storage distribuído brilha aqui.
- Não: Janelas de manutenção permitem upgrades verticais mais baratos.
Latência da Aplicação: Sua aplicação suporta latência de disco > 2ms?
- Não (ex: VM root disks, DBs antigos): Fique no armazenamento local ou use All-Flash distribuído com rede 25GbE+.
- Sim (ex: Backups, Arquivos de Mídia, Logs): Candidato perfeito.
Infraestrutura de Rede: Você tem switches redundantes, VLANs separadas para tráfego de cluster e Jumbo Frames configurados?
- Não: Pare agora. Construa a rede antes de construir o storage.
Veredito Técnico
Storage distribuído não é sobre discos; é sobre redes e algoritmos de consenso. A "realidade" da migração é que você ganha a capacidade de dormir tranquilo quando um servidor pega fogo, mas perde a simplicidade de saber exatamente onde seus dados estão. Se o seu problema é escala massiva, é o único caminho. Se o seu problema é apenas "meu RAID está cheio", compre discos maiores.
Referências & Leitura Complementar
Google, 2003: The Google File System (O paper que iniciou a era moderna do storage distribuído).
Ceph Documentation: CRUSH Maps - Controlled, Scalable, Decentralized Placement of Replicated Data.
RFC 3720: Internet Small Computer Systems Interface (iSCSI) - Para entender o transporte de blocos via IP.
Brendan Gregg: Systems Performance: Enterprise and the Cloud - Capítulo sobre Latência de Disco vs. Rede.

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.