Escalabilidade no Ceph: O Ponto de Ruptura dos OSDs e a Falácia do Infinito

O Ceph não escala infinitamente sem custos. Entenda como o excesso de OSDs satura os MONs, degrada o OSDMap e cria tempestades de peering que derrubam sua performance.
A promessa do Ceph é sedutora: um sistema de armazenamento unificado, rodando em hardware commodity, capaz de escalar "infinitamente" apenas adicionando nós. O marketing vende a linearidade perfeita — se 10 discos entregam 1.000 IOPS, 10.000 discos entregarão 1.000.000 IOPS.
Como engenheiro de performance, meu trabalho é dizer que a física discorda. Embora o Ceph seja uma maravilha da engenharia distribuída, ele não é mágico. Existe um ponto de inflexão onde a sobrecarga de coordenação supera o ganho de capacidade. Neste artigo, vamos dissecar o que acontece quando um cluster cresce demais, como medir a saturação do plano de controle e por que servidores densos podem ser uma armadilha arquitetural.
O que limita a escalabilidade do Ceph?
A escalabilidade do Ceph não é limitada pela capacidade bruta de armazenamento, mas pela latência de coordenação dos metadados. À medida que o número de OSDs (Object Storage Daemons) aumenta, o tamanho do OSDMap e a complexidade do algoritmo de Peering crescem, sobrecarregando os Monitores (MONs) e gerando latência de cauda (p99) elevada. O limite real é definido pela capacidade do cluster de manter a consistência do mapa via Paxos sem paralisar o I/O do cliente.
A Ilusão da Linearidade na Escalabilidade do Ceph
A maioria dos administradores opera sob o modelo mental de "throughput agregado". Eles visualizam o cluster como uma soma de larguras de banda. No entanto, o modelo correto para entender a escalabilidade do Ceph é o de uma rede de fofoca (gossip protocol) com consistência estrita.
Para que um cliente grave um dado, ele precisa saber onde esse dado deve residir. Isso é determinado pelo algoritmo CRUSH e pelo estado atual do cluster (OSDMap). Quando você tem 100 OSDs, as mudanças de estado (um disco falhando, um rebalanceamento) são eventos raros e leves.
Quando você escala para 5.000 ou 10.000 OSDs, o estado do cluster se torna turbulento. Discos falham estatisticamente a cada poucas horas. Cada falha gera uma atualização de mapa. Se a frequência dessas atualizações exceder a capacidade dos Monitores de processar e distribuir o novo mapa via Paxos, o cluster entra em um estado de "stuttering" (gagueira). O throughput pode parecer alto na média, mas a latência p99 dispara porque os clientes ficam bloqueados aguardando a confirmação de que o mapa que possuem ainda é válido.
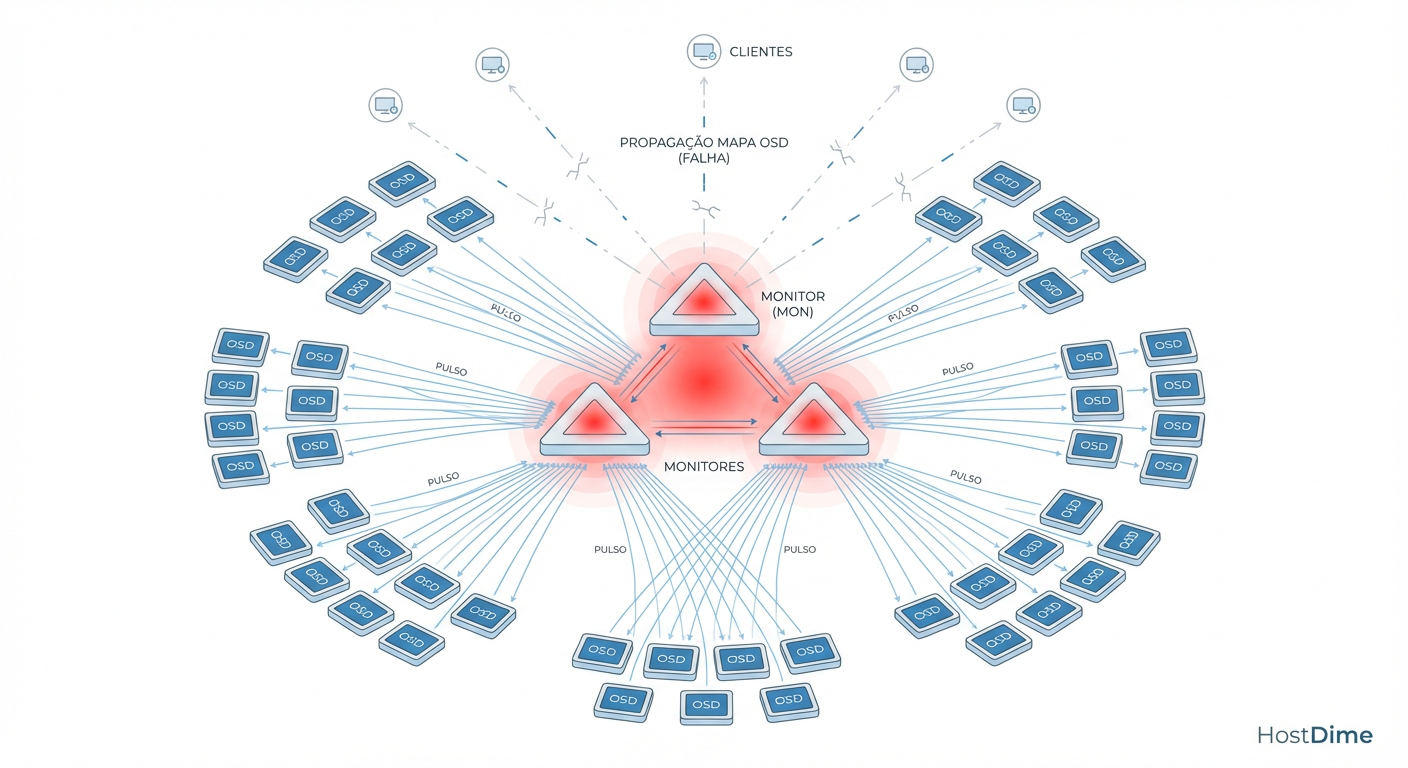 Figura: O Ciclo Vicioso do OSDMap: Quanto mais OSDs, maior o mapa e mais pesado o processo de atualização via Paxos nos Monitores.
Figura: O Ciclo Vicioso do OSDMap: Quanto mais OSDs, maior o mapa e mais pesado o processo de atualização via Paxos nos Monitores.
O Gargalo dos Monitores (MONs) e o Algoritmo Paxos
O coração do problema reside nos Monitores. Eles mantêm a "verdade" sobre a topologia do cluster. Eles operam usando o algoritmo Paxos para garantir consenso. Paxos é robusto, mas não é rápido em escala massiva quando submetido a escritas frequentes.
Como o tamanho do OSDMap afeta a performance
Cada vez que um OSD sobe ou desce, o mapa é atualizado. O tamanho desse mapa é proporcional ao número de OSDs. Em clusters pequenos, um mapa de alguns kilobytes é trivial. Em clusters com milhares de OSDs, o mapa pode crescer para megabytes.
O problema não é apenas a transferência de dados, mas a serialização e o commit no banco de dados dos Monitores (RocksDB).
CPU Bound: O processo de codificar/decodificar mapas gigantes consome ciclos preciosos de CPU do Monitor.
Latência de Rede: Propagar um mapa grande para milhares de OSDs e clientes consome largura de banda da rede pública e de cluster, criando micro-bursts que podem saturar links.
Se você observar que seus Monitores estão com alta utilização de CPU mesmo sem tráfego intenso de clientes, é um sinal claro: o custo de manter o cluster coeso está se tornando insustentável.
Tempestades de Peering: O Impacto de 10.000 OSDs
O momento mais crítico para a performance do Ceph não é durante a operação normal, mas durante a recuperação. Quando um OSD falha, os Placement Groups (PGs) que residiam nele precisam encontrar um novo lar ou, no mínimo, eleger um novo primário.
Esse processo chama-se Peering. É uma conversa complexa entre OSDs para concordar sobre o estado dos objetos.
Em um cluster massivo, a falha de um rack inteiro (ou um switch Top-of-Rack) pode desencadear uma "Tempestade de Peering". Dezenas de milhares de PGs tentam fazer peering simultaneamente. Isso gera:
Consumo excessivo de RAM nos OSDs: Cada processo de peering consome memória.
Bloqueio de I/O: Enquanto um PG está em estado de
peering, ele não aceita I/O.
A relação aqui não é linear. O tempo para o cluster convergir (ficar saudável novamente) cresce exponencialmente com a complexidade da topologia e o número de PGs.
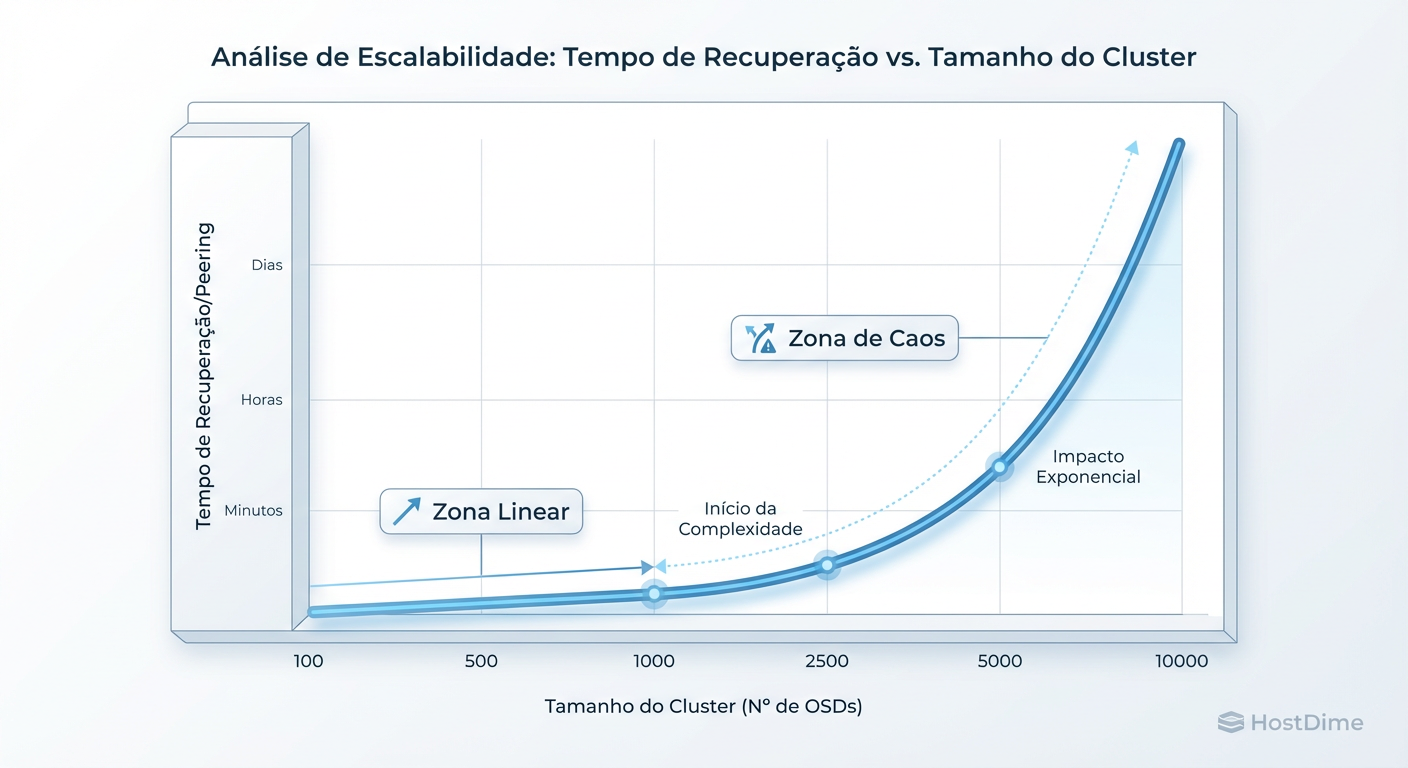 Figura: Impacto da Escala no Tempo de Convergência: A relação entre número de OSDs e tempo de peering não é linear em cenários de falha.
Figura: Impacto da Escala no Tempo de Convergência: A relação entre número de OSDs e tempo de peering não é linear em cenários de falha.
O Risco dos "Fat Nodes" (Servidores de Alta Densidade)
Há uma tendência econômica de comprar servidores 4U com 60 ou 90 baias de disco para reduzir o custo por TB. Do ponto de vista de CapEx, é brilhante. Do ponto de vista de engenharia de performance e risco, é uma bomba-relógio.
Abaixo, comparo o impacto operacional de diferentes densidades de nós no Ceph:
| Característica | "Pizza Box" (1U, 10-12 OSDs) | "Fat Node" (4U, 60+ OSDs) | Veredito de Performance |
|---|---|---|---|
| Domínio de Falha | Pequeno (~10-160 TB) | Enorme (~1 PB+) | Fat Nodes aumentam drasticamente o impacto de uma falha de servidor. |
| Recuperação (Backfill) | Rápida, tráfego distribuído. | Violenta. Satura o link de rede do nó. | Fat Nodes exigem links de 100GbE+ dedicados apenas para recuperação. |
| Impacto no OSDMap | Falha gera 12 atualizações. | Falha gera 60+ atualizações simultâneas. | Fat Nodes causam picos de carga no Paxos dos Monitores. |
| Uso de RAM | Gerenciável. | Crítico (60 OSDs competem por RAM). | OOM Killer é um risco real em Fat Nodes durante rebalanceamento. |
A "densidade" economiza dinheiro em rack e energia, mas cobra o preço em disponibilidade. Perder um nó de 60 discos força o cluster a replicar petabytes de dados através da rede para restaurar a redundância. Se o cluster já estiver grande, essa carga adicional pode empurrar a latência para níveis inaceitáveis, causando timeouts nas aplicações.
Sinais de Saturação: Métricas para Identificar o Limite
Não espere o cluster parar para agir. Você precisa de instrumentação para detectar quando a coordenação está se tornando o gargalo. Esqueça o ceph -s por um momento; precisamos olhar para dentro dos daemons.
1. Latência de Commit do Paxos
Essa é a métrica número um para a saúde dos Monitores. Ela mede quanto tempo leva para um Monitor persistir uma atualização de mapa.
# Comando para verificar a performance do Monitor (execute no host do MON)
ceph daemon mon.$(hostname) perf dump | jq '.paxos'
Procure por commit_latency. Se a média estiver subindo consistentemente acima de 100ms ou se houver picos frequentes de segundos, seus Monitores não estão acompanhando a taxa de mudança do cluster.
2. Frequência de Epochs do OSDMap
Se o número da versão do seu mapa (epoch) está crescendo em milhares por hora sem que haja intervenção administrativa, seu cluster está instável (flapping OSDs). Isso gera ruído constante na rede.
3. Latência de "Subop" nos OSDs
Nos OSDs, verifique se há latência interna causada por filas de operações.
# Verificando latência histórica nos OSDs
ceph daemon osd.0 perf dump | jq '.osd.op_latency'
Se a latência de processamento interno do OSD aumenta desproporcionalmente ao throughput, o OSD pode estar sobrecarregado com metadados ou compactação do RocksDB (BlueStore), comum em nós muito densos.
Arquitetura de Sobrevivência: Dividir para Conquistar
Quando você atinge a escala de petabytes (frequentemente acima de 5-10 PB ou 2.000+ OSDs, dependendo do workload), a solução não é otimizar parâmetros, é mudar a topologia.
Zonas de Disponibilidade e Múltiplos Clusters
A única maneira de mitigar a "Falácia do Infinito" é aceitar que o infinito é composto por múltiplos finitos.
RBD Mirroring: Em vez de um cluster gigante de 10.000 OSDs, crie dois de 5.000 ou quatro de 2.500. Use RBD Mirroring para replicação assíncrona entre eles para Disaster Recovery. Isso isola os domínios de falha do Paxos.
RGW Multisite: Para Object Storage, a federação é nativa. Você pode ter uma visão global unificada (namespace único) enquanto os dados residem em clusters fisicamente separados (zonas).
Sharding no Nível da Aplicação: Se estiver usando CephFS ou RBD diretamente, orquestradores como Kubernetes ou OpenStack podem ser configurados para provisionar volumes de diferentes clusters de armazenamento, invisível para o usuário final.
Veredito Técnico: O Pragmatismo Vence o Hype
O Ceph é uma ferramenta extraordinária, mas a física de sistemas distribuídos impõe limites rígidos à coordenação centralizada. O "ponto de ruptura" não é um erro de software, é uma consequência do design de consistência forte.
Para escalar com segurança:
Monitore a latência do Paxos como um falcão.
Evite nós excessivamente densos se você preza por tempos de recuperação rápidos.
Planeje a fragmentação (sharding) do seu ambiente em múltiplos clusters antes que o mapa fique grande demais para ser gerenciado.
Escalar não é apenas adicionar; é arquitetar para a falha.
Referências & Leitura Complementar
RADOS: A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters (Weil et al.) - O paper original que define a arquitetura do CRUSH e a distribuição de dados.
Paxos Made Simple (Leslie Lamport) - Para entender a fundo por que a latência de consenso é o gargalo final.
Ceph Documentation: Hardware Recommendations - Focando nas seções sobre dimensionamento de memória para OSDs e CPU para Monitores.
Red Hat Ceph Storage: Architecture Guide - Documentação técnica focada em limites de suporte e topologias recomendadas para produção.

Carlos Menezes
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.