Falhas em Controladoras RAID: Diagnóstico, Cache Preservado e Recuperação Segura

Quando o controlador morre, o RAID desaparece. Aprenda a diferenciar falhas de disco de falhas de HBA, gerenciar cache sujo (dirty cache) e realizar a importação de configurações estrangeiras sem corrupção de dados.
O silêncio em um data center é aterrorizante. Quando um disco rígido falha, ele geralmente grita: o LED âmbar pisca, o SMART cospe erros hexadecimais e o sistema operacional reclama de blocos defeituosos. Mas quando a controladora RAID sofre uma morte cerebral, o sintoma muitas vezes é o silêncio absoluto ou o congelamento total. O sistema operacional continua enviando dados para um buraco negro, aguardando confirmações que nunca virão.
Como investigador forense de sistemas, aprendi que recuperar uma controladora morta é uma cirurgia de alto risco. Diferente de trocar um disco, onde a redundância (RAID 1, 5, 6, 10) protege você, trocar a controladora coloca você frente a frente com metadados proprietários e, o mais perigoso de tudo: o cache de escrita não gravado ("Dirty Cache").
Este artigo é uma autópsia do processo de falha e um guia de campo para a ressurreição dos dados sem causar corrupção lógica.
O Que é Falha de Controladora e Cache Preservado?
Falha de Controladora RAID ocorre quando o hardware responsável pela lógica do array (CPU, memória ou barramento) deixa de responder, isolando os discos do sistema operacional. O maior risco na recuperação é o Cache Preservado (Preserved Cache): dados que o SO acredita terem sido gravados, mas que ainda residem apenas na memória volátil (NVRAM) da controladora falha. Recuperar o array sem restaurar esse cache resulta em corrupção silenciosa do sistema de arquivos.
O Silêncio vs. O Caos: Diagnóstico de Falhas em Controladoras RAID
O primeiro passo na investigação é não confundir o mensageiro com a mensagem. Um sistema travado com I/O wait alto pode ser um disco lento, mas uma perda súbita de todos os volumes lógicos aponta para o cérebro da operação.
Quando um disco morre, o subsistema SCSI/SAS tenta reencaminhar o tráfego. Quando a controladora morre, o driver do kernel entra em pânico ou loop de reset.
Sintomas no Kernel (Linux)
Em um cenário de falha de disco, você vê erros de leitura/escrita em setores específicos (sd 0:0:1:0). Na falha da controladora, você vê o colapso da comunicação PCI ou timeouts do adaptador de host.
Analise o dmesg ou /var/log/messages em busca de padrões de "Host Reset":
# Exemplo de log indicando falha na controladora (mpt2sas / megaraid_sas)
kernel: mpt2sas_cm0: diag reset: FAILED
kernel: mpt2sas_cm0: host_reset: FAILED
kernel: sd 0:0:0:0: [sda] tag#0 FAILED Result: hostbyte=DID_NO_CONNECT driverbyte=DRIVER_OK
Se o lspci não listar mais o dispositivo, ou se o comando da CLI da controladora (ex: storcli, perccli, arcconf) retornar "Controller not found", pare de tentar reiniciar serviços. Você tem um cadáver de hardware.
Tabela de Evidências: Disco vs. Controladora
| Indicador | Falha de Disco (Membro do Array) | Falha de Controladora (Cérebro) |
|---|---|---|
| Escopo | Afeta um ou mais LUNs/Volumes degradados. | Todos os LUNs/Volumes desaparecem ou congelam. |
| Logs do SO | Erros de I/O, Sense Key errors, Bad Blocks. | Timeouts de comando SCSI, PCI Bus errors, Driver resets. |
| LEDs Físicos | LED de falha no drive específico (âmbar). | LEDs dos drives podem apagar ou ficar estáticos; LED de status da placa pisca código de erro. |
| Acesso CLI | A ferramenta de gestão ainda abre e vê a controladora. | A ferramenta de gestão falha ao inicializar ou não detecta adaptadores. |
A Armadilha do Write-Back Cache: Onde os Dados Morrem
Para entender o risco da troca de hardware, você precisa entender a mentira que a controladora conta ao sistema operacional.
Em modo Write-Back, quando o SO envia um arquivo para gravar, a controladora o recebe, coloca em sua memória RAM (cache), e imediatamente diz ao SO: "Gravado com sucesso!". O SO segue a vida. Mas o dado ainda não está no disco magnético ou na memória NAND do SSD.
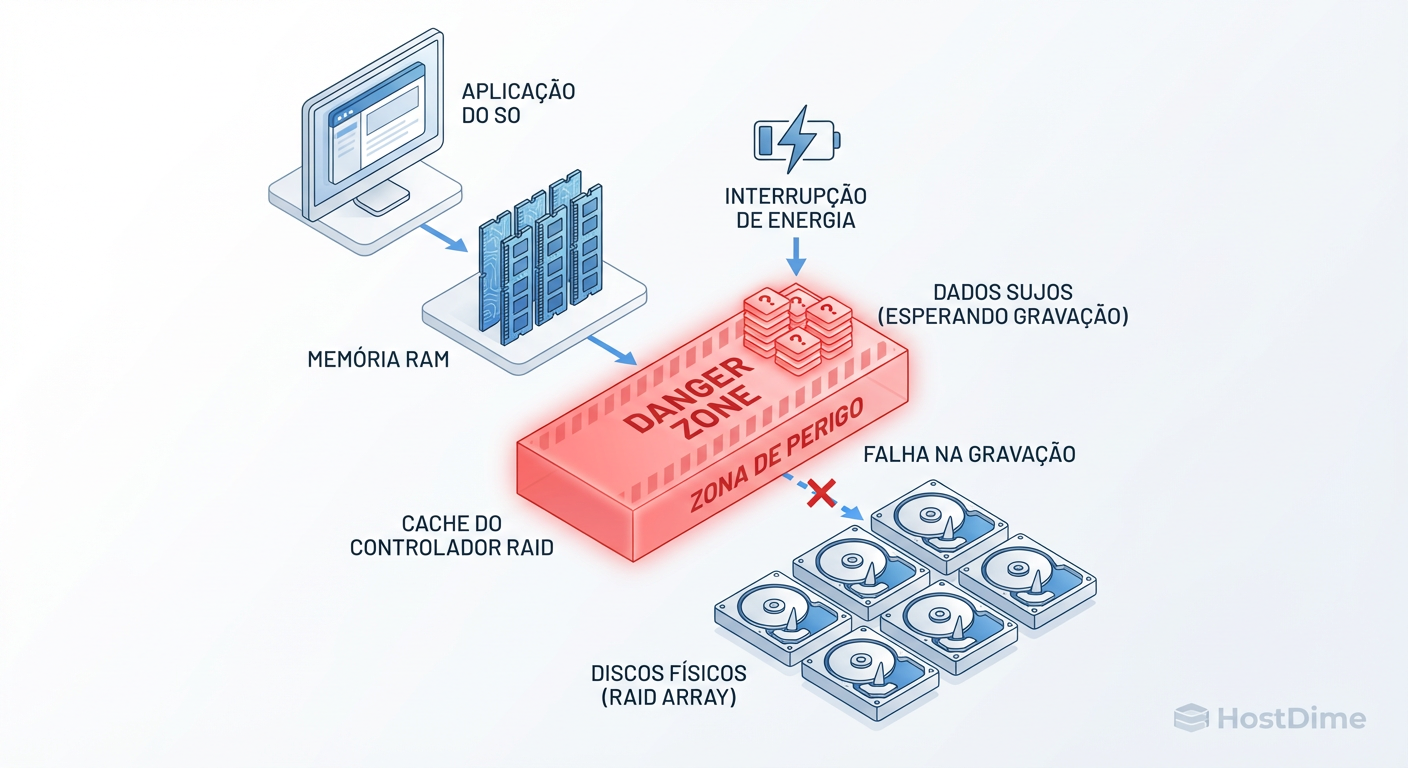 Figura: O Caminho da Escrita: O risco reside nos dados confirmados ao SO, mas ainda retidos no cache volátil da controladora.
Figura: O Caminho da Escrita: O risco reside nos dados confirmados ao SO, mas ainda retidos no cache volátil da controladora.
Se a energia cair e a controladora morrer simultaneamente, esses dados dependem exclusivamente da BBU (Battery Backup Unit) ou de um Supercapacitor para sobreviverem na NVRAM até que a energia volte.
Se você substituir a controladora falha por uma nova e não migrar o módulo de memória/cache (em modelos onde isso é possível) ou não seguir o procedimento de importação de "Cache Preservado", esses dados somem. Para o sistema de arquivos (EXT4, XFS, NTFS), isso é catastrófico: metadados que ele "sabe" que gravou agora não existem. O resultado é um fsck violento e perda de arquivos.
Arquiteturas de Alta Disponibilidade e o Mito do Failover
Em ambientes corporativos (SANs e Storages dedicados), usamos controladoras duplas (Dual-Controller) para mitigar a falha de hardware. A promessa do vendedor é o "Failover Transparente". A realidade forense é bem mais complexa.
Para que o failover funcione, as controladoras precisam estar em sincronia perfeita de cache (cache mirroring) através de um link dedicado.
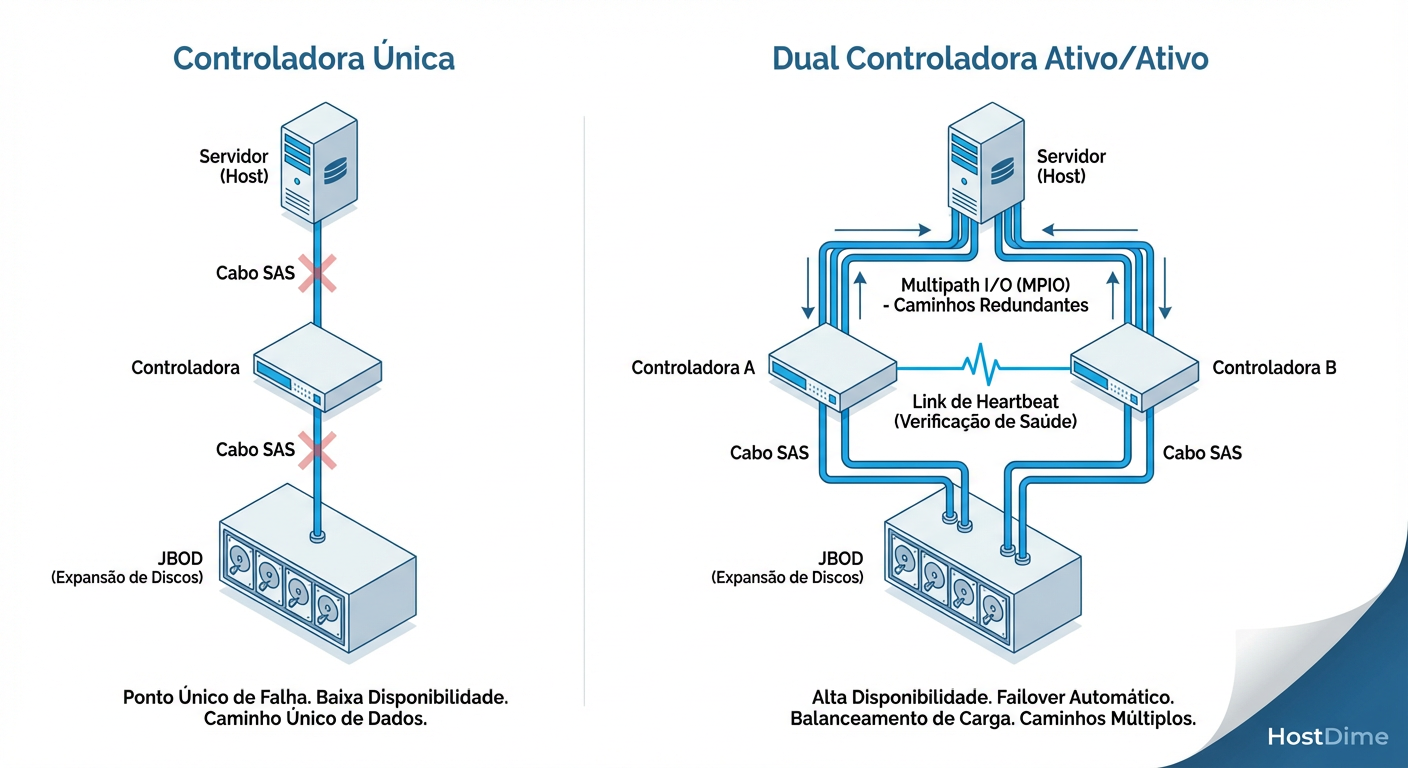 Figura: Topologia de Failover: A complexidade do Dual-Path e a necessidade de comunicação constante (Heartbeat) para evitar corrupção.
Figura: Topologia de Failover: A complexidade do Dual-Path e a necessidade de comunicação constante (Heartbeat) para evitar corrupção.
O Risco do Split-Brain
O pesadelo ocorre quando a comunicação entre as controladoras (Heartbeat) falha, mas ambas continuam ativas.
Cenário: O link de espelhamento rompe.
Ação: A Controladora A acha que a B morreu e assume os LUNs. A Controladora B acha que a A morreu e tenta assumir os mesmos LUNs.
Resultado: Ambas tentam gravar nos mesmos blocos do disco sem coordenação. Corrupção de dados instantânea.
Mecanismos como ALUA (Asymmetric Logical Unit Access) e SCSI Persistent Reservations tentam impedir isso, mas configurações incorretas de Multipath no lado do servidor podem ignorar esses bloqueios.
Controller Roaming e Migração de Hardware (COD)
Assumindo que você não tem um sistema Dual-Controller e precisa trocar uma placa física queimada (Single Point of Failure). Como o novo hardware sabe como os discos estavam organizados?
A resposta é COD (Configuration on Disk) ou DAC (Disk Availability Center). A configuração do RAID (nível, tamanho do stripe, ordem dos discos) não fica apenas na memória da placa; ela é gravada em uma área reservada (geralmente no final) de cada disco físico membro do array.
O Procedimento de Roaming Seguro
Ao mover discos de uma controladora morta para uma nova (do mesmo fabricante/família):
Etiquetagem Física: Embora controladoras modernas consigam ler a configuração independente da posição do slot, nunca confie cegamente nisso. Etiquete cada disco com seu Slot ID original.
Compatibilidade de Firmware: A nova controladora deve ter um firmware igual ou superior à antiga. Se for inferior, ela pode não entender a estrutura de dados COD gravada nos discos.
Power On Sem Discos (Opcional mas Recomendado): Ligue a nova controladora sem os discos primeiro para limpar qualquer configuração residual antiga que ela possa ter. Desligue.
Inserção e Boot: Insira os discos e ligue.
Gerenciando Foreign Configurations e Preserved Cache
Este é o momento crítico. Ao bootar a nova controladora com os discos antigos, a BIOS/UEFI da controladora irá pausar e alertar sobre uma Foreign Configuration (Configuração Estrangeira).
Isso significa: "Encontrei metadados RAID nestes discos que não foram criados por mim (esta placa específica)".
O Dilema da Importação
Você geralmente terá duas ou três opções. A escolha errada destrói os dados.
Import (Safe/Foreign): A controladora lê o COD dos discos e adota aquela configuração. Esta é a opção correta.
Clear / Delete: A controladora apaga os metadados dos discos para criar um novo array. Isso destrói seus dados.
O Passo a Passo do "Cache Preservado"
Se a controladora antiga tinha dados no cache (Dirty Cache) quando morreu, a situação é mais delicada.
Se você moveu o módulo de cache físico (BBU + RAM) para a nova placa, a nova placa detectará "Preserved Cache".
Ela perguntará se você quer Importar ou Descartar o cache.
ALERTA FORENSE: Se você descartar o cache preservado, o array ficará consistente do ponto de vista do RAID, mas o sistema de arquivos terá buracos lógicos. Sempre tente importar o cache se o hardware permitir. Se a placa antiga queimou a ponto de não ser possível recuperar o módulo de memória, você terá que descartar o cache. Nesse caso, prepare-se para rodar
fsckou restaurar backups de banco de dados, pois a integridade transacional foi perdida.
Validação Pós-Trauma: O Consistency Check
Após importar a configuração (e o cache, se tiver sorte), o volume lógico aparecerá como "Optimal" ou "Online". Não abra o champanhe ainda. "Online" apenas significa que a controladora consegue falar com os discos. Não significa que os dados (Paridade vs. Dados) estão matematicamente corretos.
Durante a falha e o transplante, bits podem ter virado ou gravações podem ter sido interrompidas pela metade (write hole).
O Protocolo de Alta Obrigatória
Antes de colocar o servidor em produção total:
Force um Consistency Check (Scrub): A maioria das controladoras (LSI, Dell PERC, HP SmartArray) possui essa função. Ela lê todos os blocos de dados e todos os blocos de paridade.
- Se
Paridade != Dados, ela assume que o dado está certo e reescreve a paridade (em RAID 5/6). - Isso garante que, se um disco falhar amanhã, a reconstrução será possível.
- Se
Validação do Sistema de Arquivos: Rode um
fsck(Linux) ouchkdsk(Windows) em modo de leitura (dry-run) para ver se a estrutura de diretórios sobreviveu intacta.Verificação de Logs de Banco de Dados: Se havia um SQL Server ou PostgreSQL rodando, verifique os logs de transação. O banco de dados é o melhor "canário na mina" para detectar corrupção silenciosa causada por perda de cache de escrita.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Common RAID Disk Data Format Specification" (Entendendo como metadados COD funcionam).
Broadcom/LSI Series User Guides: MegaRAID SAS Software User Guide (Capítulos sobre "Foreign Configuration Import").
RFC 3720: iSCSI (Internet Small Computer Systems Interface) - Para entender timeouts e recuperação de erro em links de storage.
Dell Technical White Paper: "PERC: Preserved Cache Management".

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.