Hot Spares Globais vs. Dedicados: Otimizando a Recuperação em Storage Corporativo
Não desperdice discos. Entenda a matemática entre Hot Spares Globais e Dedicados, o impacto no MTTR e por que o Spare Distribuído (dRAID) é o futuro da recuperação.
Chegamos à cena do crime às 03:00 da manhã. O sintoma é clássico: latência disparada, fila de I/O bloqueada e aquele LED âmbar piscando no chassi do storage. Um disco mecânico morreu.
Para o amador, o problema é o disco. Para o investigador forense de sistemas, o disco morto é apenas um fato da vida — silício e óxido de ferro falham. O verdadeiro "crime" aqui não é a falha do componente, mas como a arquitetura do sistema reage a ela. É aqui que entra a estratégia de Hot Spare.
Muitos administradores tratam o Hot Spare como um amuleto de sorte: um disco que fica lá girando, esperando o pior. Mas a escolha entre um modelo Dedicado, Global ou Distribuído define se você vai dormir às 03:15 ou se vai passar as próximas 48 horas rezando para não ocorrer um erro de leitura irrecuperável (URE) durante a reconstrução.
Vamos dissecar a anatomia dessa recuperação.
O que é um Hot Spare?
Hot Spare é um componente de armazenamento em espera (standby), mantido ligado e pronto para assumir imediatamente a função de um disco falho em um grupo RAID. Sua função primária não é fazer backup, mas automatizar o início da reconstrução (rebuild) sem intervenção humana, reduzindo drasticamente o tempo em que o array permanece em estado degradado e vulnerável.
A Função Real do Hot Spare e a Automação do MTTR
Quando investigamos um colapso de dados (Data Loss), raramente é por causa do primeiro disco que falhou. A perda de dados ocorre quando o segundo disco falha antes que o array tenha se recuperado do primeiro.
O Hot Spare é uma ferramenta de redução de MTTR (Mean Time To Repair). A equação de risco é simples:
$$Risco = (Probabilidade_Falha_Disco_2) \times (Tempo_de_Rebuild)$$
Se você não tem um Hot Spare configurado, o "Tempo de Rebuild" inclui:
O tempo para o sistema de monitoramento te alertar.
O tempo para você dirigir até o data center.
O tempo para localizar o disco sobressalente no armário (se houver um).
A troca física.
Um Hot Spare reduz os passos 1 a 4 para milissegundos. O controlador detecta a falha, marca o disco morto como offline, ativa o disco de spare e inicia a sincronização de paridade. Se você opera sem Hot Spares em produção, você está voluntariamente aumentando a janela de vulnerabilidade do seu negócio.
O Dilema do Hot Spare Dedicado: Segurança ou Desperdício de CapEx?
O modelo mais antigo — e o primeiro suspeito em casos de ineficiência financeira — é o Hot Spare Dedicado.
Neste cenário, você atribui um disco específico para proteger apenas um grupo RAID específico. Imagine um storage com 3 grupos de RAID 5. No modelo dedicado, você teria um disco de spare "preso" ao Grupo A, outro ao Grupo B e outro ao Grupo C.
A Evidência da Ineficiência
O problema forense aqui é o desperdício de recursos (CapEx). Se o Grupo A é extremamente volátil e sofre falhas, mas o Grupo B é estável, o spare do Grupo B fica lá, girando, consumindo eletricidade e ocupando um slot valioso, "assistindo" o Grupo A sofrer sem poder ajudar.
Isso cria silos de segurança. É como ter um pneu estepe que só serve para a roda dianteira esquerda. Se furar a traseira direita, você está a pé, mesmo carregando um pneu extra.
Hot Spares Globais e a Lógica de Pool de Discos
Para resolver o desperdício dos dedicados, a indústria moveu-se para os Hot Spares Globais. Aqui, os discos de reserva pertencem ao chassi (ou ao controlador), não a um grupo lógico específico.
Se qualquer array dentro daquela "zona de controle" falhar, o Hot Spare Global é convocado. Isso permite uma taxa de consolidação melhor. Em vez de 1 spare para cada 10 discos (3 spares para 30 discos em 3 arrays), você pode arriscar 1 spare global para 30 discos, liberando 2 slots para produção.
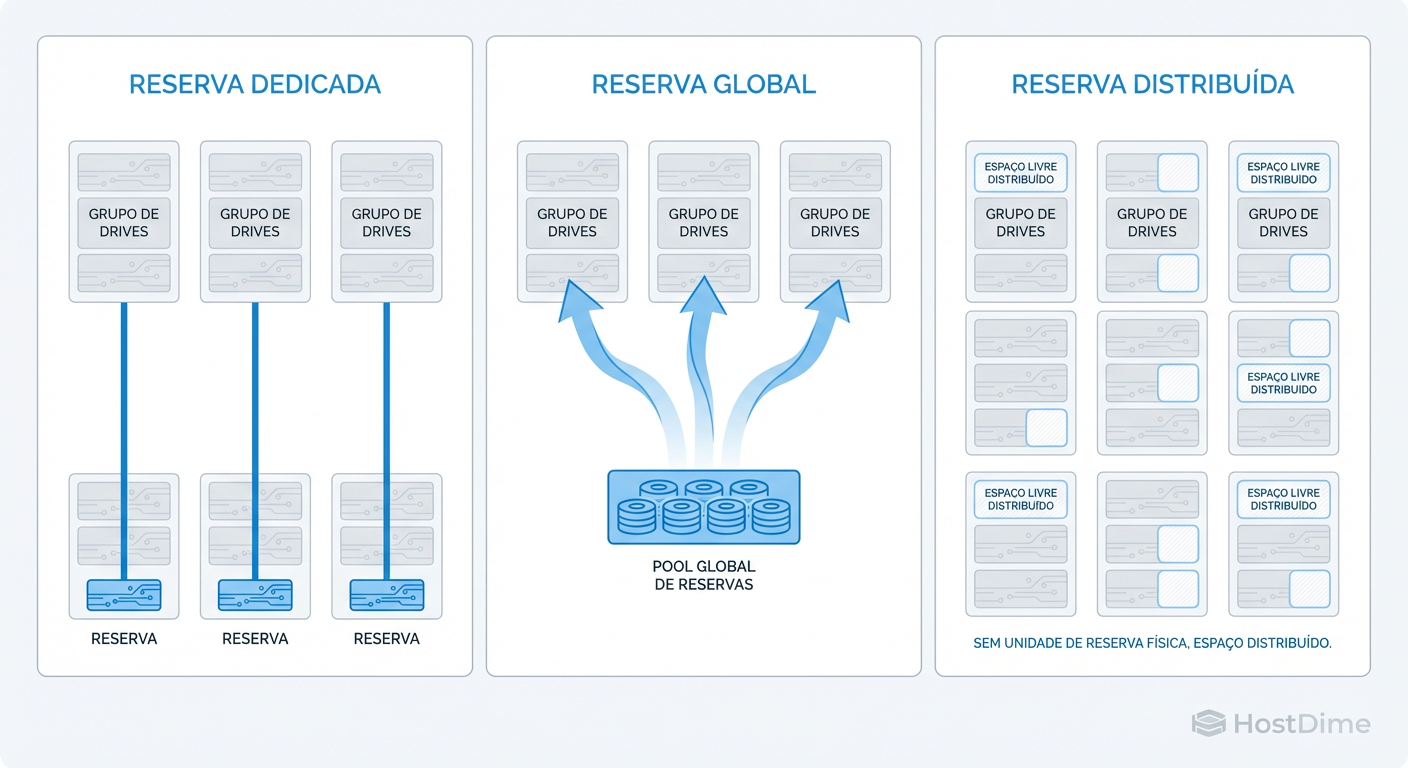 Figura: Evolução da Topologia de Sparing: Do isolamento rígido (Dedicado) à eficiência de pool (Global) e finalmente à paralelização total (Distribuído).
Figura: Evolução da Topologia de Sparing: Do isolamento rígido (Dedicado) à eficiência de pool (Global) e finalmente à paralelização total (Distribuído).
O Risco de Contenção (A Tempestade Perfeita)
Como investigador, preciso alertar sobre o cenário de "falha em cascata". Spares globais introduzem um risco de contenção. Se você tem um spare global para todo o sistema e ocorre uma falha no Array A, o spare é ocupado. Se, durante esse rebuild (que pode levar dias), o Array B sofrer uma falha, não há mais redes de segurança. O Array B fica degradado até que você intervenha fisicamente.
Hot Spares Globais exigem um cálculo de probabilidade mais refinado: qual a chance de duas falhas simultâneas em grupos distintos?
O Gargalo Físico: Por que Rebuilds Tradicionais em Discos Grandes Falham
Aqui chegamos à "causa mortis" da maioria dos arrays modernos. O modelo mental de "um disco substitui outro" funcionava bem quando tínhamos HDDs de 146GB. Hoje, com discos de 18TB ou 22TB, a física se tornou nossa inimiga.
O gargalo é a taxa de transferência de um único disco. Não importa quão rápido seja seu controlador ou seu barramento SAS/NVMe. Para reconstruir um RAID tradicional (seja com spare dedicado ou global), você precisa escrever 20TB de dados em um único disco de destino.
Um HDD Enterprise moderno escreve a cerca de 250 MB/s (em sequencial puro, o que raramente acontece em rebuilds com carga de produção).
Vamos fazer a conta de padaria (que todo admin deve saber fazer):
Capacidade: 20 TB (20.000.000 MB)
Velocidade Média de Escrita (com contenção de produção): 100 MB/s
Tempo: 200.000 segundos = ~55 horas.
São mais de dois dias de "janela de morte". Durante esse tempo, os outros discos do array estão sendo lidos intensamente para recalcular a paridade, estressando componentes mecânicos já velhos. É comum que um segundo disco falhe exatamente durante esse esforço.
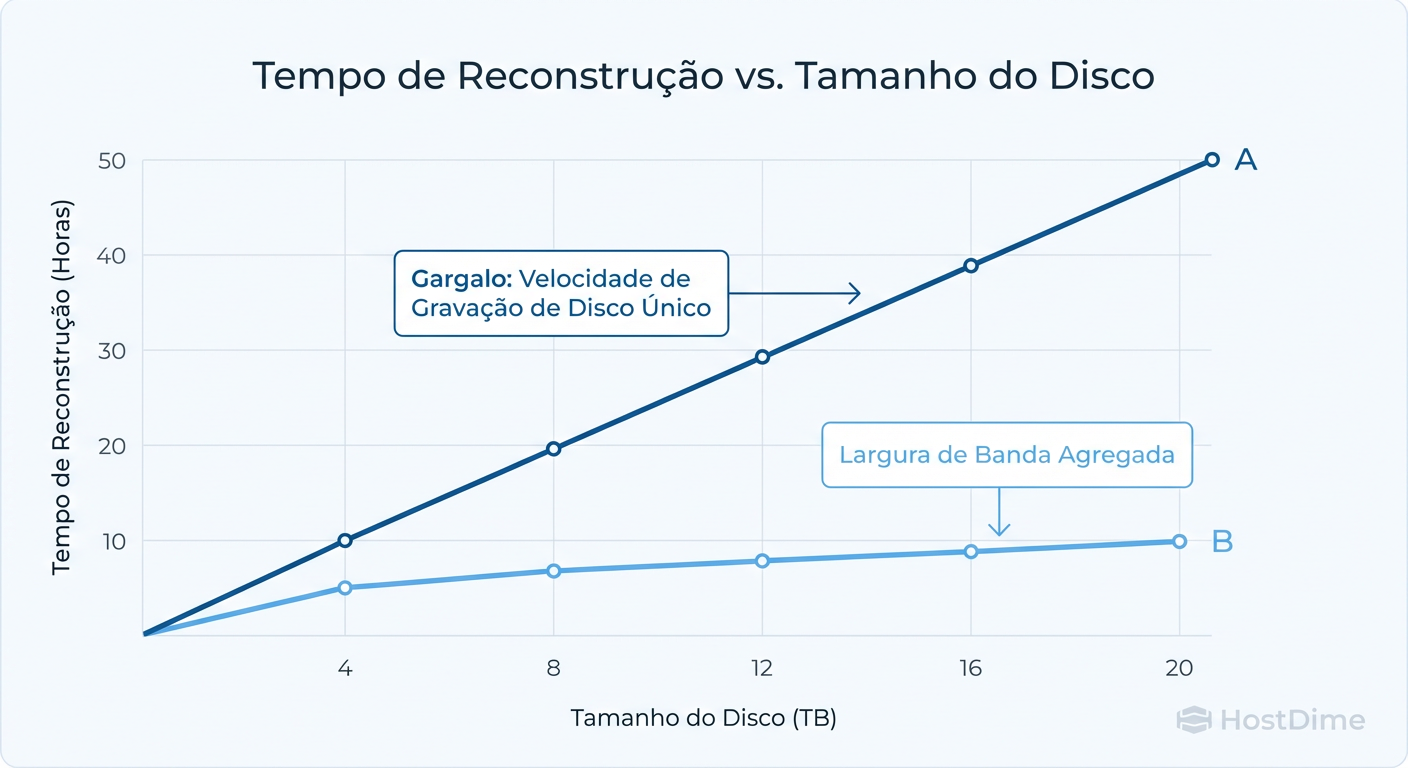 Figura: O Gargalo da Física: Por que discos de 20TB tornam os Hot Spares tradicionais perigosos devido ao tempo excessivo de reconstrução.
Figura: O Gargalo da Física: Por que discos de 20TB tornam os Hot Spares tradicionais perigosos devido ao tempo excessivo de reconstrução.
A Evolução para Spare Distribuído e o Conceito de Spare Space
Se o gargalo é a velocidade de escrita de um único disco, a solução forense é eliminar o "disco" da equação. Entra em cena o Spare Distribuído (conhecido como dRAID no ZFS, ou a arquitetura nativa de vSAN, Ceph e storages enterprise modernos como Infinidat ou IBM FlashSystem).
Neste modelo, não existe um "disco de spare". Existe Espaço de Spare (Spare Space).
Como funciona o Modelo Mental Distribuído
Imagine que você tem 100 discos. Em vez de deixar 5 parados como spares, você usa os 100 discos ativos, mas deixa o equivalente a 5 discos de espaço vazio espalhado por todos eles.
Quando um disco morre:
O sistema percebe que precisa reconstruir os dados daquele disco.
Em vez de copiar tudo para um único disco novo, ele reconstrói os dados usando o espaço livre nos 99 discos restantes.
O Rebuild é paralelo.
O ganho de performance: Escrever 20TB em um disco a 100MB/s = 55 horas. Escrever 20TB divididos entre 99 discos = A velocidade é limitada pela rede ou CPU, não pelo disco individual. Rebuilds que levavam dias caem para minutos ou poucas horas.
Exemplo Prático (Conceitual)
Em sistemas como ZFS com dRAID, a geometria é calculada para incluir blocos de reserva virtuais. Não há comando mágico para "converter" um RAID tradicional em distribuído; é uma decisão de arquitetura na criação do Pool.
# 10 discos de dados + 2 de paridade + 1 'spare virtual' distribuído
zpool create tank draid2:10d:1s:13c /dev/sd[a-m]
Note no comando acima: 1s indica capacidade de spare distribuída, não um disco físico isolado.
Tabela Comparativa: Dedicado vs. Global vs. Distribuído
Para facilitar sua decisão operacional, compilei as evidências nesta tabela:
| Característica | Hot Spare Dedicado | Hot Spare Global | Spare Distribuído / Declustered |
|---|---|---|---|
| Definição | 1 disco protege 1 array específico. | 1 disco protege qualquer array no sistema. | Espaço reservado em todos os discos. |
| Utilização de CapEx | Baixa (muitos discos ociosos). | Média (menos discos ociosos). | Alta (todos os discos trabalham). |
| Velocidade de Rebuild | Lenta (limitada por 1 disco). | Lenta (limitada por 1 disco). | Explosiva (N-1 discos escrevendo). |
| Impacto na Performance | Alto durante rebuild. | Alto durante rebuild. | Baixo (carga diluída). |
| Risco Principal | Falha em array sem spare associado. | Contenção (múltiplos arrays falhando). | Complexidade de configuração inicial. |
| Cenário Ideal | Sistemas legados, compliance estrito de isolamento. | Arrays tradicionais de médio porte. | Petabytes de dados, HDDs grandes (>10TB), SDS. |
Matemática de Sobrevivência: Quantos Spares Você Realmente Precisa?
Não existe "best practice" universal, existe tolerância ao risco.
Regra do Fabricante (Cética): Geralmente recomendam 1 spare para cada 30 discos. Isso é genérico.
Abordagem Investigativa:
- Verifique a idade dos discos (Batch Aging). Se todos os discos são do mesmo lote e têm 4 anos de uso, a curva de falha ("banheira") indica que eles começarão a morrer juntos. Aumente a proporção de spares.
- Tamanho do Disco. Se usar discos de 20TB+, Hot Spare tradicional não é suficiente. Você precisa de RAID 6 (dupla paridade) E Spares. Com RAID 5 e discos de 20TB, um URE durante o rebuild é matematicamente provável.
Checklist de Decisão: Quando migrar?
Seus discos são maiores que 4TB? Considere fortemente RAID 6 e Spares Globais.
Seus discos são maiores que 10TB? O modelo de Spare Dedicado/Global é perigoso. Migre para arquiteturas de Spare Distribuído (Ceph, vSAN, ZFS dRAID) se possível.
Você tem mais de 50 discos no chassi? Use Spares Globais ou Distribuídos. Dedicados são microgerenciamento inútil.
Veredito Técnico: O Veredito
Como investigador, minha conclusão é técnica e direta: O Hot Spare Dedicado é uma relíquia de uma era onde discos eram pequenos e rápidos de reconstruir. Em data centers modernos, ele representa ineficiência financeira e falsa sensação de segurança.
O Hot Spare Global é o mínimo aceitável para sanitizar a operação, mas o Spare Distribuído é a única resposta viável para a física dos discos de alta capacidade atuais.
Não espere o LED âmbar acender para descobrir que seu plano de recuperação leva 72 horas. Configure seus spares, teste o tempo de rebuild e, acima de tudo, pare de tratar discos como animais de estimação. Eles são gado. Quando um cair, o rebanho deve fechar a lacuna imediatamente.
Referências & Leitura Complementar
SNIA (Storage Networking Industry Association): "Dictionary of Storage Networking Terminology" – Definições formais de RAID e Sparing.
OpenZFS Documentation: "dRAID (Distributed Spare RAID)" – Detalhes técnicos sobre a implementação de paridade declustered.
Google Research (2007): "Failure Trends in a Large Disk Drive Population" – Estudo seminal sobre taxas de falha reais vs. MTBF declarado.
IBM Systems Technical Whitepaper: "IBM Spectrum Virtualize: Distributed RAID" – Análise de performance de rebuilds distribuídos em ambientes enterprise.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.