Hybrid RAID e Tiering: O Guia Realista de Cache SSD sobre HDDs
Pare de desperdiçar SSDs. Entenda a arquitetura real do Hybrid RAID, as diferenças entre LVM Cache e ZFS SLOG, e como evitar o 'Write Cliff' ao acelerar arrays de HDDs.
Vamos ser honestos: ninguém usa discos mecânicos (HDDs) porque gosta do barulho ou da vibração. Usamos porque o custo por Terabyte do Flash (SSD/NVMe) ainda é proibitivo para armazenar petabytes de logs, backups ou arquivos mortos. O problema é que seus usuários e aplicações foram mal acostumados pela velocidade instantânea dos SSDs em seus laptops. Eles não aceitam mais esperar milissegundos.
A solução vendida pelo marketing é o "Armazenamento Híbrido" ou Tiering: coloque um pouco de SSD na frente de muito HDD e tenha "velocidade de Flash com preço de disco". Na prática, isso é uma meia-verdade perigosa. Se você não entender a física por trás do cache, você vai construir um sistema que é rápido no benchmark de 5 minutos, mas que colapsa miseravelmente em produção na sexta-feira à noite.
Este não é um guia de "melhores práticas" genéricas. É uma análise de como não perder dados e nem o emprego ao misturar mídias de velocidades diferentes.
O QUE É ARMAZENAMENTO HÍBRIDO (TIERING/CACHING)?
Armazenamento Híbrido é a arquitetura que interpõe uma camada de mídia de alta velocidade (SSD/NVMe) entre a memória RAM e os discos de alta capacidade (HDD). O objetivo é atender a maioria das requisições de leitura e escrita (hot data) na camada rápida, mascarando a latência física dos discos rotacionais, enquanto o sistema move dados frios transparentemente para o armazenamento lento em segundo plano.
A Física da Latência em Discos Híbridos e a Ilusão de Velocidade
Para operar storage híbrido, você precisa abandonar a ideia de que o cache "acelera" o disco. O cache não faz o HDD girar mais rápido. O cache é um mecanismo de evasão.
O sucesso da sua estratégia depende inteiramente de evitar o disco mecânico.
Um SSD NVMe responde em microssegundos (µs).
Um HDD SAS/SATA responde em milissegundos (ms).
A diferença é de ordens de magnitude. Se o seu cache falha (Cache Miss), a latência da aplicação não "piora um pouco"; ela bate em um muro de concreto.
Imagine uma biblioteca. A RAM é o livro aberto na sua mesa. O SSD é a estante na sala ao lado. O HDD é um arquivo morto num galpão do outro lado da cidade. Se você precisa de um documento e ele não está na mesa (RAM) nem na estante (SSD), você tem que dirigir até o galpão. Nesse momento, não importa quão rápida é sua estante; a operação vai demorar o tempo da viagem até o galpão.
Se o seu padrão de acesso aos dados for totalmente aleatório (ex: um banco de dados gigantesco onde cada consulta lê uma tabela diferente), seu Hit Ratio será baixo. Nesse cenário, o cache SSD é apenas um peso de papel caro adicionando complexidade.
Arquitetura de Cache de Leitura: Quando o 'Hot Data' Realmente Importa
O cache de leitura (Read-Cache) é a implementação mais segura e comum. A premissa é o Princípio de Pareto: 80% do I/O vem de 20% dos dados.
Quando um bloco de dados é lido do HDD lento, o sistema faz uma cópia dele no SSD rápido. Na próxima vez que alguém pedir esse bloco, ele vem do SSD. O segredo aqui é o aquecimento do cache. Um storage híbrido recém-bootado é lento. Ele precisa de tempo para "aprender" quais dados são quentes.
Tabela Comparativa: Mídias de Armazenamento
| Atributo | HDD (SAS/SATA) | SSD (SATA/SAS) | NVMe (PCIe) |
|---|---|---|---|
| Latência Típica | 5ms - 15ms | 100µs - 500µs | 20µs - 100µs |
| IOPS (Random 4K) | 80 - 200 | 5.000 - 80.000 | 200.000+ |
| Função no Tiering | Backing Device (Capacidade) | Cache/Tier 1 (Custo-benefício) | Cache/Log (Performance Extrema) |
| Risco de Falha | Mecânico (gradual ou súbito) | Eletrônico (súbito) | Eletrônico (súbito) |
Se o seu Working Set (o conjunto de dados ativos) for maior que o tamanho do seu cache SSD, você terá um problema chamado Cache Thrashing. O sistema passará mais tempo gravando e apagando dados no cache SSD do que servindo a aplicação, queimando a vida útil do Flash prematuramente.
O Perigo do Cache de Escrita (Write-Back) e a Integridade dos Dados
Aqui é onde a maioria dos administradores se machuca. Existem duas formas principais de lidar com escritas em sistemas híbridos:
Write-Through: O dado é escrito no SSD e no HDD simultaneamente. O sistema só confirma a gravação quando ela está segura no HDD.
- Vantagem: Segurança total. Se a energia cair, o dado está no disco.
- Desvantagem: A velocidade de escrita é limitada pela velocidade do HDD lento.
Write-Back: O dado é escrito no SSD e confirmado imediatamente para a aplicação. O sistema copia do SSD para o HDD depois (flush).
- Vantagem: Velocidade de escrita insana (velocidade do SSD).
- Desvantagem: Se o SSD morrer ou a energia cair antes do flush, o dado foi perdido.
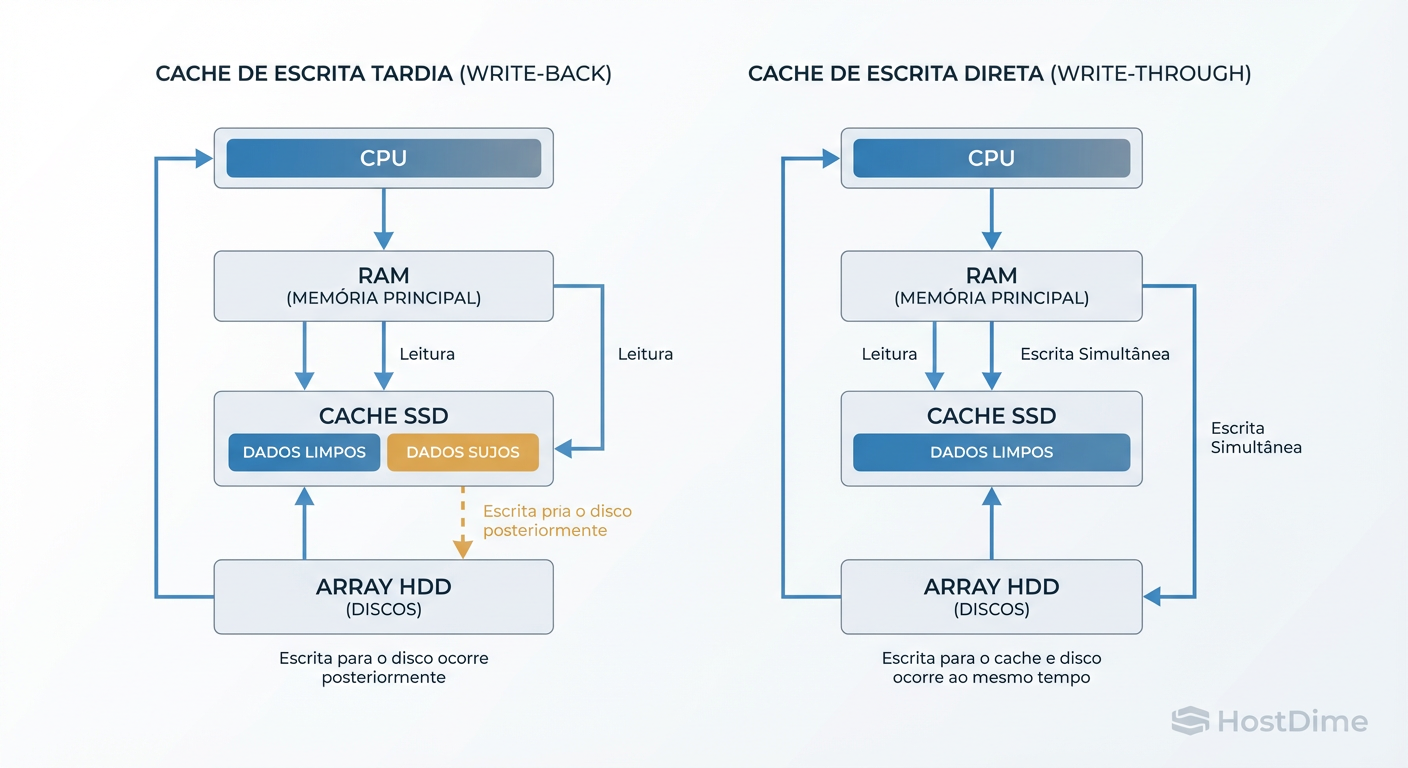 Figura: Fluxo de I/O: A diferença crítica de segurança entre Write-Through (seguro) e Write-Back (rápido, mas arriscado).
Figura: Fluxo de I/O: A diferença crítica de segurança entre Write-Through (seguro) e Write-Back (rápido, mas arriscado).
A regra de ouro do Sysadmin Cético: Nunca use Write-Back sem uma bateria de proteção no controlador RAID (BBU) ou SSDs com proteção contra perda de energia (PLP - Power Loss Protection) e no-breaks redundantes. Se você ativar Write-Back em SSDs de consumidor (desktop) sem proteção elétrica, você está jogando Roleta Russa com seu banco de dados.
Implementação Realista em ZFS: O Papel do SLOG e L2ARC
O ZFS é frequentemente mal interpretado quando o assunto é cache. Vamos limpar a terminologia.
O Mito do SLOG (ZIL)
Muitos acham que adicionar um SSD como "Log" no ZFS cria um cache de escrita geral. Não cria. O ZFS usa a RAM (ARC) para agrupar escritas e enviá-las ao disco (Transaction Groups). Isso é assíncrono e rápido por padrão.
O SLOG (Separate Log) só é usado para Escritas Síncronas (Sync Writes) — aquelas onde a aplicação exige garantia de que o dado foi gravado (comum em NFS, iSCSI e Bancos de Dados). O SLOG não acelera a cópia de arquivos via SMB ou escritas assíncronas padrão.
- Decisão Operacional: Só compre SSDs Optane ou NVMe de alta resistência para SLOG se você monitorou seu servidor (
zilstat) e confirmou uma alta carga de Sync Writes. Caso contrário, é dinheiro jogado fora.
A Armadilha do L2ARC
O L2ARC é o cache de leitura em SSD. Parece ótimo adicionar um SSD de 2TB para cache, certo? Cuidado: Para gerenciar os dados no L2ARC (SSD), o ZFS precisa de tabelas de endereçamento na RAM. Se você tem pouca RAM (ex: 32GB ou 64GB) e adiciona um L2ARC gigante, o índice do L2ARC vai "comer" o espaço do ARC (cache de RAM). Como a RAM é muito mais rápida que o SSD, você pode na verdade piorar a performance geral do sistema.
- Regra de Prática: Só adicione L2ARC se seu ARC (RAM) já estiver cheio e o Hit Ratio da RAM estiver estável. Maximize a RAM antes de pensar em L2ARC.
Estratégias de dm-cache e bcache em Ambientes Linux
No mundo Linux puro (sem ZFS), temos duas ferramentas principais para transformar aquele par de HDDs lentos em algo utilizável.
LVM Cache (dm-cache)
É a solução "Enterprise" padrão, integrada ao LVM.
Prós: Estável, suportado pela Red Hat/Debian, flexível. Permite escolher políticas de cache (
mqpara filas múltiplas,smqpara estocástico).Contras: Configuração verbosa.
Para verificar o status do seu cache LVM e entender se ele está funcionando ou apenas ocupando espaço, não confie na sorte. Use o comando:
lvs -o +cache_total_blocks,cache_used_blocks,cache_dirty_blocks,cache_read_hits,cache_read_misses
Se cache_dirty_blocks estiver sempre alto, seu HDD de fundo não está conseguindo acompanhar o ritmo de esvaziamento do cache.
bcache
Frequentemente preferido por entusiastas por ser mais performático em benchmarks brutos e ter uma configuração inicial mais simples ("formate o disco como bcache e pronto").
O Risco: O
bcacheteve um histórico de bugs de corrupção em kernels antigos e situações de recuperação de desastre (quando o SSD morre) podem ser mais complexas do que no LVM.Recomendação: Use
dm-cache(LVM) para servidores de produção crítica onde a estabilidade supera 5% de ganho em benchmark.
O Fenômeno do 'Write Cliff': Quando o Cache SSD Enche
Este é o momento onde o telefone do Sysadmin toca.
Imagine que você tem um cache de escrita de 100GB em SSD. O usuário começa a copiar um backup de 500GB. Os primeiros 100GB voam a 500MB/s. O usuário fica feliz. De repente, o cache enche. O sistema agora precisa fazer duas coisas ao mesmo tempo:
Gravar os novos dados que chegam.
Despejar (flush) os dados antigos para o HDD lento para liberar espaço.
O resultado não é que a velocidade cai para a do HDD (150MB/s). Ela cai para menos que isso, porque o controlador está sobrecarregado gerenciando a fila de entrada e saída simultaneamente. Isso é o "Write Cliff" (Penhasco de Escrita).
 Figura: O 'Write Cliff': O momento exato em que seu cache enche e a performance cai para a velocidade nativa dos discos rotacionais.
Figura: O 'Write Cliff': O momento exato em que seu cache enche e a performance cai para a velocidade nativa dos discos rotacionais.
Para mitigar isso, você deve configurar limites de High Watermark e Low Watermark agressivos, forçando o sistema a começar a esvaziar o cache para o disco antes que ele esteja 100% cheio. Em LVM Cache, isso é ajustável via cache_watermark_scale.
Métricas Essenciais para Monitorar Hit Ratio e Latência de Cauda
Não olhe para a "Média de Latência". A média esconde os picos que matam a aplicação. Se 99 requisições levam 1ms e 1 requisição leva 10 segundos (porque o HDD estava acordando ou buscando), a média ainda parece boa, mas um usuário ficou travado por 10 segundos.
Você deve monitorar a Latência de Cauda (Tail Latency - P99 ou P99.9).
O que medir para comprovar eficiência:
Cache Hit Ratio:
- Se estiver abaixo de 80-90% para leituras, seu cache é pequeno demais, ou seu padrão de acesso é aleatório demais.
- Ação: Aumente o SSD ou remova o cache para simplificar a arquitetura.
Dirty Data Eviction Rate:
- Quão rápido o cache consegue esvaziar para o HDD?
- Se a taxa de entrada (Write) for consistentemente maior que a taxa de despejo (Eviction), seu tiering falhou. Você precisa de mais HDDs em RAID para aumentar a vazão do backend ou precisa de SSDs puros.
Para usuários de ZFS, o arc_summary é seu melhor amigo. Para Linux padrão, ferramentas como iostat -x 1 (olhando para a coluna w_await dos discos físicos de backend) revelam a verdade. Se o w_await do HDD estiver em 500ms+, seu cache de escrita não está protegendo o disco; ele está apenas adiando o inevitável.
Veredito Técnico
O armazenamento híbrido não é mágica; é gestão de filas. Ele compra tempo para absorver picos de carga (bursts), mas não resolve problemas de capacidade de vazão contínua. Use cache de leitura liberalmente, use cache de escrita com extremo cuidado (e proteção elétrica), e monitore sempre o que acontece quando o cache enche. Se você não medir, você está apenas adivinhando.
Referências & Leitura Complementar
OpenZFS Documentation: ZIL and SLOG behavior detailed analysis.
Kernel Docs (Linux): device-mapper/cache-policies.txt - Detalhes sobre algoritmos de smq e mq.
Gregg, Brendan: Systems Performance: Enterprise and the Cloud - Capítulos sobre Disk I/O e Latency Analysis.
RFC 3720 (iSCSI): Para entender implicações de latência em storage de rede sobre tiering.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.