IO Scheduler do Hypervisor e Ceph: O Gargalo do "Double Scheduling"

Seus OSDs virtualizados sofrem com latência alta? O culpado pode ser o IO Scheduler do host. Entenda o conflito de filas, como diagnosticar gargalos e por que 'none' ou 'noop' são essenciais para o desempenho do Ceph.
Você gastou uma fortuna em NVMe. Configurou uma rede de 25GbE ou 100GbE. O seu cluster Ceph mostra saúde "HEALTH_OK". Mas, quando você sobe uma VM de banco de dados e coloca carga real, o iowait dispara e a latência parece de um disco SATA rotacional de 2010. O marketing prometeu milhões de IOPS, mas a realidade entregou uma fila travada.
O problema raramente é o hardware físico. O problema é que o seu sistema operacional está tentando ser "inteligente" demais. Em ambientes virtualizados, a inteligência duplicada é estupidez operacional. Bem-vindo ao inferno do Double Scheduling (Agendamento Duplo).
Vamos dissecar por que deixar o Linux "gerenciar" a fila de IO dentro e fora da VM é a receita perfeita para destruir a performance do Ceph, e como sair do caminho para deixar o hardware trabalhar.
O que é o Double Scheduling no Contexto de Storage?
Double Scheduling (Agendamento Duplo) é um fenômeno de degradação de performance que ocorre quando tanto o Sistema Operacional Guest (VM) quanto o Hypervisor (Host) tentam, independentemente, reordenar, priorizar e fundir requisições de IO. Esse processamento redundante consome ciclos de CPU desnecessários, adiciona latência na entrega dos pacotes de dados e quebra a lógica de sistemas de armazenamento distribuído (como o Ceph), que dependem da ordem cronológica exata de gravação para consistência e performance.
O Caminho Tortuoso do Dado na Pilha de IO Virtualizada
Para entender onde o desempenho morre, precisamos visualizar o caminho que um bloco de dados percorre desde o momento em que o PostgreSQL na sua VM decide gravar um registro até o momento em que ele toca o disco físico (ou OSD do Ceph).
A maioria dos sysadmins trata isso como uma caixa preta, mas a realidade é uma pilha de burocracia computacional.
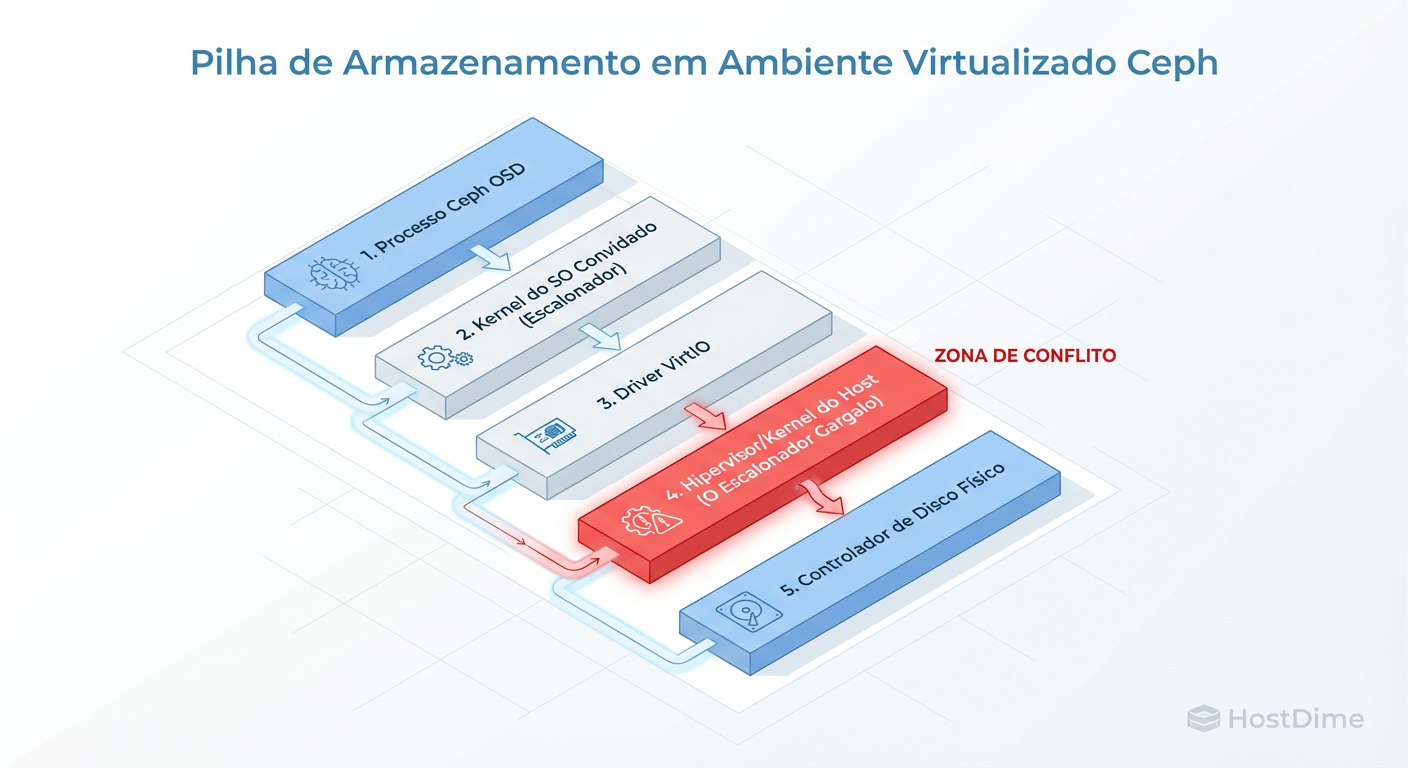 Figura: A Pilha de IO Virtualizada: Onde o Ceph perde a luta contra a latência.
Figura: A Pilha de IO Virtualizada: Onde o Ceph perde a luta contra a latência.
Quando a VM emite uma escrita, ela não vai para o disco. Ela vai para um driver (geralmente VirtIO), que passa por uma interrupção de contexto para o QEMU no espaço do usuário, que chama o Kernel do Host, que passa pelo sistema de arquivos ou gerenciador de volumes, para finalmente entrar na rede e chegar ao Ceph.
Cada uma dessas setas no diagrama acima representa uma oportunidade para um IO Scheduler (Agendador de IO) intervir. O Scheduler foi inventado na era dos discos rígidos mecânicos. O trabalho dele era nobre: reorganizar as requisições de leitura/escrita para minimizar o movimento físico da agulha do disco.
Mas em um mundo de SSDs, NVMe e Ceph (que é, essencialmente, armazenamento via rede), não existe "agulha" para mover. Reordenar pacotes aqui não apenas é inútil; é prejudicial.
A Falácia do Cache Inteligente e o Conflito com o Ceph
O Ceph é um sistema desenhado para consistência. Quando você grava um objeto, o Ceph precisa garantir que ele foi replicado e persistido. Ele tem seus próprios mecanismos internos de journal e WAL (Write Ahead Log).
O problema do Double Scheduling surge quando:
O Guest (VM) usa um scheduler complexo (como BFQ ou MQ-Deadline) tentando otimizar o acesso ao "disco virtual". Ele segura requisições para tentar fundi-las.
O Hypervisor (Host) recebe essas requisições e também usa um scheduler complexo para otimizar a gravação no dispositivo de bloco que sustenta a VM.
O resultado? Latência imprevisível. O Guest acha que gravou, mas o Host está segurando o buffer. Ou pior: o Guest reordena uma sequência de escritas que o Ceph preferiria receber linearmente.
Callout de Risco: Se você usa cache de escrita no Host (
cache=writeback) sem entender os riscos, uma falha de energia no Host antes do flush para o Ceph significa corrupção de dados no Guest. O Ceph não pode proteger dados que ele ainda não recebeu.
Anatomia dos Schedulers de IO Linux
Não existe "melhor prática" universal, mas existem escolhas erradas óbvias. Vamos analisar os candidatos que você encontrará no /sys/block/sdX/queue/scheduler.
Tabela Comparativa de Schedulers de IO
| Scheduler | Foco Principal | Mecanismo | Veredito para Ceph/VMs |
|---|---|---|---|
| CFQ (Completely Fair Queuing) | Equidade entre processos | Timeslices complexos por processo. Tenta ser justo para todos. | Péssimo. Adiciona latência massiva em SSDs e Virtualização. Obsoleto em kernels novos. |
| BFQ (Budget Fair Queuing) | Responsividade de Desktop | Evolução do CFQ. Foca em baixa latência para uso interativo. | Ruim para Servers. Custo de CPU muito alto (overhead) para throughput elevado. |
| mq-deadline | Throughput | Agrupa requisições e impõe prazos (deadlines) para evitar inanição. | Aceitável (Host SATA). Bom para HDDs rotacionais, mas desnecessário para NVMe. |
| Kyber | Latência em Fast Devices | Simples, baseado em tokens para limitar requisições pendentes. | Bom. Uma alternativa válida para NVMe, mas ainda faz algum processamento. |
| None / Noop | "Sair da frente" | FIFO (First-In, First-Out). Apenas funde requisições adjacentes básicas. | Excelente. O padrão ouro para Guests em Hypervisors e Hosts com NVMe/Ceph. |
Por que "none" vence em SSDs e Virtualização?
O scheduler none (ou noop em kernels antigos) assume que o dispositivo subjacente é inteligente o suficiente para lidar com a carga.
No Guest: O dispositivo é virtual. O Host vai gerenciar isso. O Guest não deve perder tempo reordenando.
No Host (NVMe): O NVMe tem filas de hardware massivas e paralelas. O Kernel do Linux não consegue reordenar melhor que o controlador do NVMe.
No Host (Ceph RBD): O Ceph é rede. Reordenar pacotes de rede baseando-se em lógica de disco rotacional é absurdo.
Métricas que não mentem: Provando o Gargalo
Como saber se o seu scheduler é o culpado? A intuição falha, os números não.
1. O Sintoma do Heatmap
Quando usamos schedulers complexos em ambas as pontas, vemos "caudas de latência" (latency tails). A maioria das requisições é rápida, mas algumas demoram 10x ou 100x mais porque ficaram presas em alguma fila de prioridade mal calculada.
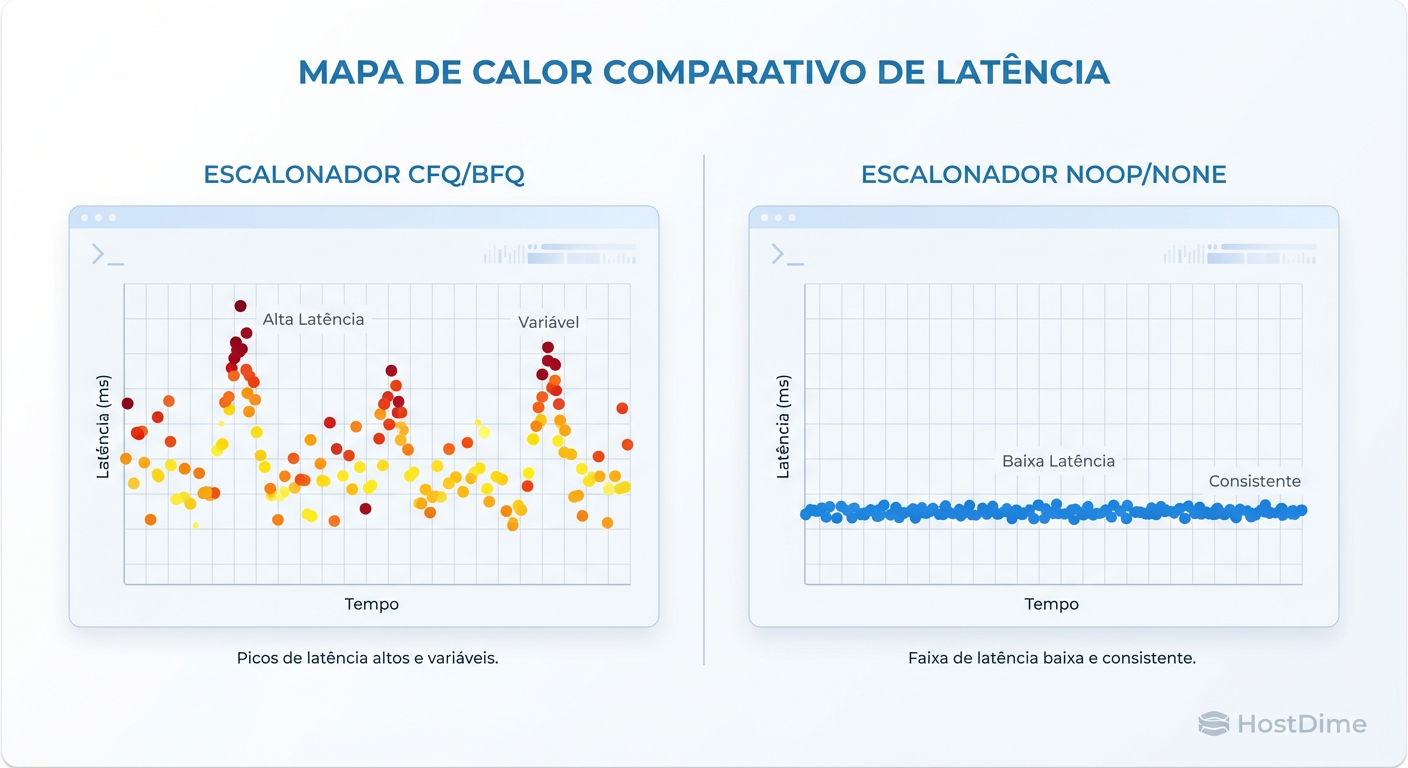 Figura: Comparativo de Latência (Heatmap): Scheduler Complexo vs. Pass-through (None). Observe a consistência na direita.
Figura: Comparativo de Latência (Heatmap): Scheduler Complexo vs. Pass-through (None). Observe a consistência na direita.
Observe na imagem acima (lado esquerdo) a dispersão errática. Isso é jitter causado por processamento de CPU no agendamento. No lado direito (com none), a latência é consistente. Em storage, consistência é mais importante que velocidade de pico.
2. Usando iostat para Diagnóstico
Não olhe apenas para o %util. Olhe para avgqu-sz (tamanho médio da fila) e await (tempo total de espera).
iostat -x -k 1
Sinais de Alerta:
Se o
awaitno Guest é alto (ex: 50ms), mas oawaitno dispositivo correspondente no Host é baixo (ex: 1ms), o gargalo está na camada de virtualização (VirtIO/QEMU) ou no scheduler do Guest.Se o
r_await(leitura) é baixo masw_await(escrita) é altíssimo, você provavelmente está enchendo buffers de escrita que o scheduler não consegue drenar rápido o suficiente.
3. Ceph Performance Dump
O Ceph pode dizer se ele é o culpado ou a vítima.
# Verifique a latência de commit e apply nos OSDs
ceph osd perf
Se o commit_latency_ms do Ceph for baixo (ex: 2-5ms para SSD), mas sua VM sente 100ms, o problema é, sem dúvida, o Double Scheduling ou a configuração do Hypervisor.
A Configuração Pragmática: Saindo do Caminho
Não tente "tunar" o BFQ. Desligue a inteligência. O objetivo é transformar o Linux em um tubo passivo que entrega IO para o hardware.
No Host (Hypervisor com NVMe/SSDs para Ceph)
Você quer que o Kernel passe o IO direto para o driver NVMe ou para o daemon do Ceph.
Crie uma regra udev para garantir que isso persista após o reboot. Não confie em comandos echo manuais que somem na segunda-feira de manhã.
# /etc/udev/rules.d/60-ioschedulers.rules
# Para NVMe: definir como 'none'
ACTION=="add|change", KERNEL=="nvme[0-9]*n[0-9]*", ATTR{queue/scheduler}="none"
# Para SSDs SATA (rotacionais devem usar mq-deadline ou bfq)
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="none"
No Guest (A VM Linux)
A VM sabe que está em um ambiente virtualizado se você usar VirtIO? Geralmente sim, mas nem sempre ela ajusta o scheduler. Force-o.
# /etc/udev/rules.d/60-virtio-scheduler.rules
# Dispositivos VirtIO devem sempre usar 'none'
ACTION=="add|change", KERNEL=="vd[a-z]", ATTR{queue/scheduler}="none"
Depois de aplicar, recarregue as regras ou reinicie:
udevadm control --reload && udevadm trigger
Trade-off Realista: VirtIO-SCSI vs. PCI Passthrough
Às vezes, mesmo ajustando os schedulers, a sobrecarga do QEMU/KVM (context switches) é alta demais para bancos de dados de altíssima performance (ex: Oracle, ScyllaDB com milhões de IOPS).
Aqui entra o dilema arquitetural:
VirtIO-SCSI (Padrão Recomendado):
- Prós: Flexível, permite Live Migration, snapshots fáceis, gerenciamento centralizado.
- Contras: Overhead de CPU no Host. Sofre com Double Scheduling se não configurado como
none. - Uso: 95% dos casos. Web servers, App servers, DBs gerais.
PCI Passthrough (Controladora NVMe dedicada):
- Prós: Performance nativa (Bare Metal). O Guest fala direto com o silício. Zero overhead de scheduler do Host.
- Contras: Perde Live Migration. A VM fica "presa" àquele hardware físico. Configuração complexa (IOMMU groups).
- Uso: Os 5% restantes. Bancos de dados massivos onde cada microsegundo conta e você tem HA na camada de aplicação, não na virtualização.
Veredito Técnico
O "Double Scheduling" é um assassino silencioso de performance. Ele não aparece nos logs de erro, apenas nas reclamações dos usuários sobre lentidão.
Para um cluster Ceph performático:
Use hardware rápido (NVMe).
Use rede rápida.
Mais importante: Configure seus schedulers (Host e Guest) para
none.
Pare de tentar organizar a fila. Deixe o dado fluir.
Referências & Leitura Complementar
Red Hat Enterprise Linux Performance Tuning Guide: Documentação oficial sobre tuning de IO e seleção de schedulers.
Ceph Docs - OSD Configuration: Parâmetros recomendados para OSDs baseados em BlueStore e NVMe.
Linux Kernel Documentation (block/switching-sched.txt): Detalhes técnicos sobre a implementação de multiqueue (blk-mq) e Kyber.
RFC 3720 (iSCSI) / VirtIO Spec: Para entender as limitações de protocolo e encapsulamento de comandos SCSI em ambientes virtuais.

André Bastos
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.