IOPS, Throughput e Latência: Desvendando o Triângulo Mágico do Storage

"O banco de dados está lento!" Essa frase, ou variações dela, assombram sysadmins, SREs e engenheiros de infraestrutura em todo o mundo. Mas o que *realmente* e...
IOPS, Throughput e Latência: Desvendando o Triângulo Mágico do Storage
"O banco de dados está lento!" Essa frase, ou variações dela, assombram sysadmins, SREs e engenheiros de infraestrutura em todo o mundo. Mas o que realmente está lento? É o disco? A rede? A CPU? A memória? Para responder essa pergunta com precisão, precisamos entender profundamente três métricas cruciais: IOPS (Input/Output Operations Per Second), Throughput (Vazão) e Latência. Juntas, elas formam um triângulo interdependente que define o desempenho do seu sistema de armazenamento.
Este guia vai desmistificar essas métricas, explicar como elas se relacionam, como medi-las corretamente e, o mais importante, como interpretar os resultados para diagnosticar gargalos e otimizar seu ambiente. Prepare-se para mergulhar fundo no mundo do I/O!
O Problema Real: "O Banco Está Lento"
Antes de começarmos a falar sobre métricas, vamos aterrizar o problema. Imagine a seguinte situação: usuários estão reclamando que o sistema está lento, especialmente durante horários de pico. O banco de dados é apontado como o culpado. A primeira reação pode ser culpar a CPU ou a memória, mas e se o problema estiver no armazenamento?
Para responder a essa pergunta, precisamos de dados. Não podemos simplesmente olhar para o uso geral do disco e tirar conclusões. Precisamos entender como o banco de dados está usando o armazenamento. Ele está fazendo muitas operações pequenas e aleatórias? Ou poucas operações grandes e sequenciais? É aí que IOPS, Throughput e Latência entram em jogo.
IOPS (Input/Output Operations Per Second): A Taxa de Operações
IOPS, ou Operações de Entrada/Saída Por Segundo, mede a quantidade de operações de leitura ou escrita que um dispositivo de armazenamento pode realizar em um segundo. É uma métrica fundamental para entender o desempenho de aplicações que dependem de muitas operações pequenas e aleatórias, como bancos de dados transacionais, servidores de e-mail e virtualização.
Tamanho do Bloco: Um fator crucial que afeta o IOPS é o tamanho do bloco. Cada operação de I/O envolve a leitura ou escrita de um bloco de dados. Quanto menor o bloco, mais operações podem ser realizadas por segundo, e vice-versa. Por exemplo, um disco que consegue realizar 1000 IOPS com blocos de 4KB terá um IOPS menor com blocos de 64KB.
Random vs Sequential: Outro fator importante é o padrão de acesso aos dados. Acesso random (aleatório) significa que as operações de leitura/escrita são espalhadas por todo o disco, exigindo que o cabeçote de leitura/escrita se mova constantemente. Acesso sequential (sequencial) significa que as operações são realizadas em blocos contíguos, permitindo uma leitura/escrita mais eficiente. Discos mecânicos (HDDs) sofrem muito com acesso random, enquanto SSDs (Solid State Drives) são muito mais eficientes nesse tipo de acesso.
A Analogia do Carteiro: Para entender melhor o IOPS, imagine um carteiro.
IOPS: É o número de cartas que o carteiro consegue entregar por hora. Se ele tiver que entregar muitas cartas em endereços diferentes (acesso random), ele conseguirá entregar menos cartas por hora. Se ele tiver que entregar poucas cartas em endereços próximos (acesso sequential), ele conseguirá entregar mais cartas por hora.
Tamanho do Bloco: É o tamanho de cada carta. Se o carteiro tiver que entregar cartas grandes (blocos grandes), ele conseguirá entregar menos cartas por hora. Se ele tiver que entregar cartas pequenas (blocos pequenos), ele conseguirá entregar mais cartas por hora.
Throughput (Vazão): A Banda Larga do Armazenamento
Throughput, também conhecido como vazão ou banda larga, mede a quantidade de dados que podem ser transferidos por segundo, geralmente expressa em MB/s (megabytes por segundo) ou GB/s (gigabytes por segundo). É uma métrica importante para aplicações que lidam com grandes quantidades de dados, como backup, streaming de vídeo, edição de vídeo e transferência de arquivos grandes.
Quando Importa e Quando é Irrelevante: O Throughput é crucial quando você precisa transferir grandes quantidades de dados rapidamente. Imagine fazer um backup do seu banco de dados. Quanto maior o Throughput, mais rápido o backup será concluído. No entanto, para aplicações transacionais, onde o tamanho das operações é pequeno, o Throughput pode ser menos relevante do que o IOPS e a Latência.
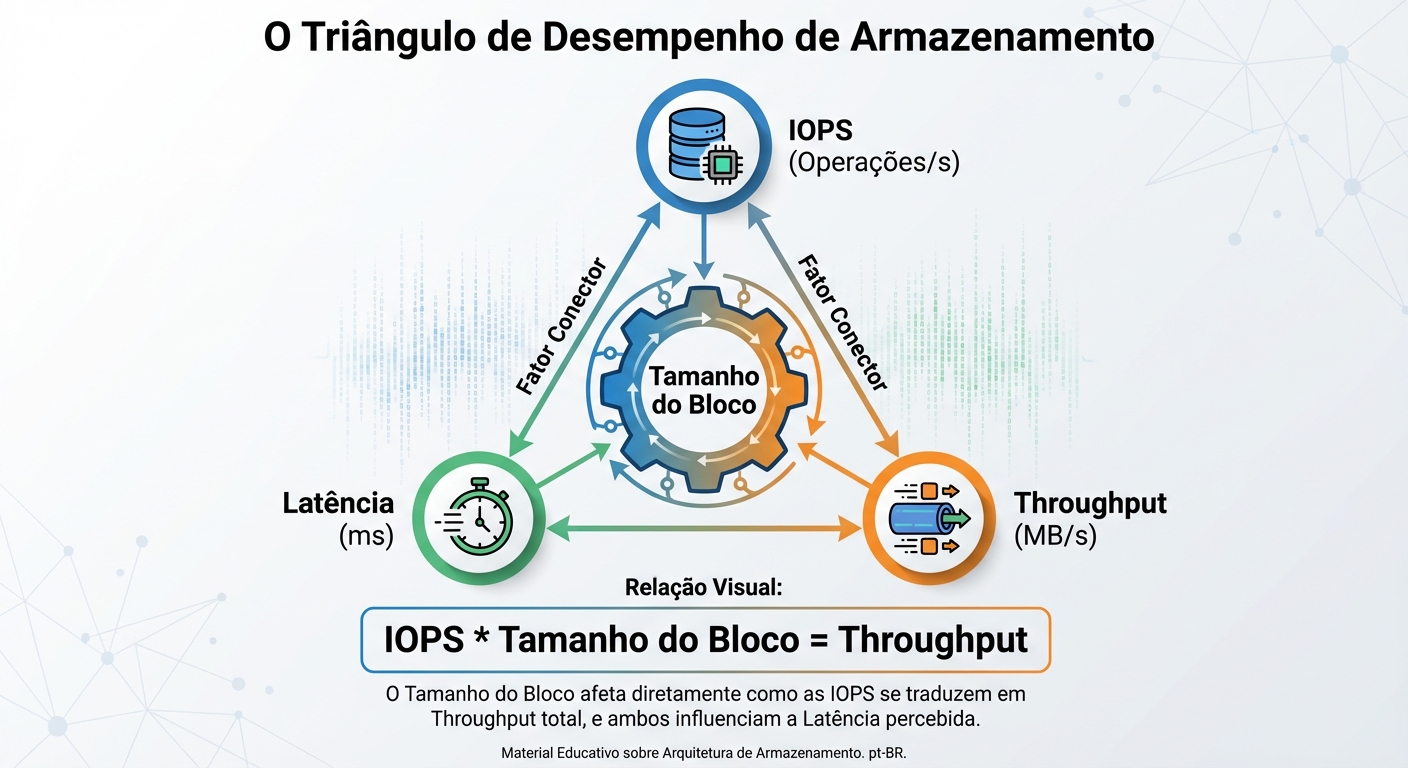
A Relação com IOPS e Block Size: Throughput é diretamente relacionado ao IOPS e ao tamanho do bloco. A fórmula é simples:
Throughput = IOPS * Tamanho do Bloco
Por exemplo, se você tem um disco que consegue realizar 1000 IOPS com blocos de 4KB, o Throughput será de 4MB/s (1000 * 4KB = 4000KB = 4MB). Se você aumentar o tamanho do bloco para 64KB, o Throughput aumentará para 64MB/s (1000 * 64KB = 64000KB = 64MB), mesmo que o IOPS permaneça o mesmo.
Latência: O Tempo de Resposta Crucial
Latência é o tempo que leva para uma operação de I/O ser concluída, geralmente medida em milissegundos (ms) ou microssegundos (µs). É a métrica mais importante para a maioria das aplicações, pois afeta diretamente a experiência do usuário. Uma alta latência significa que as operações de leitura/escrita estão demorando muito, o que pode levar a lentidão e frustração.
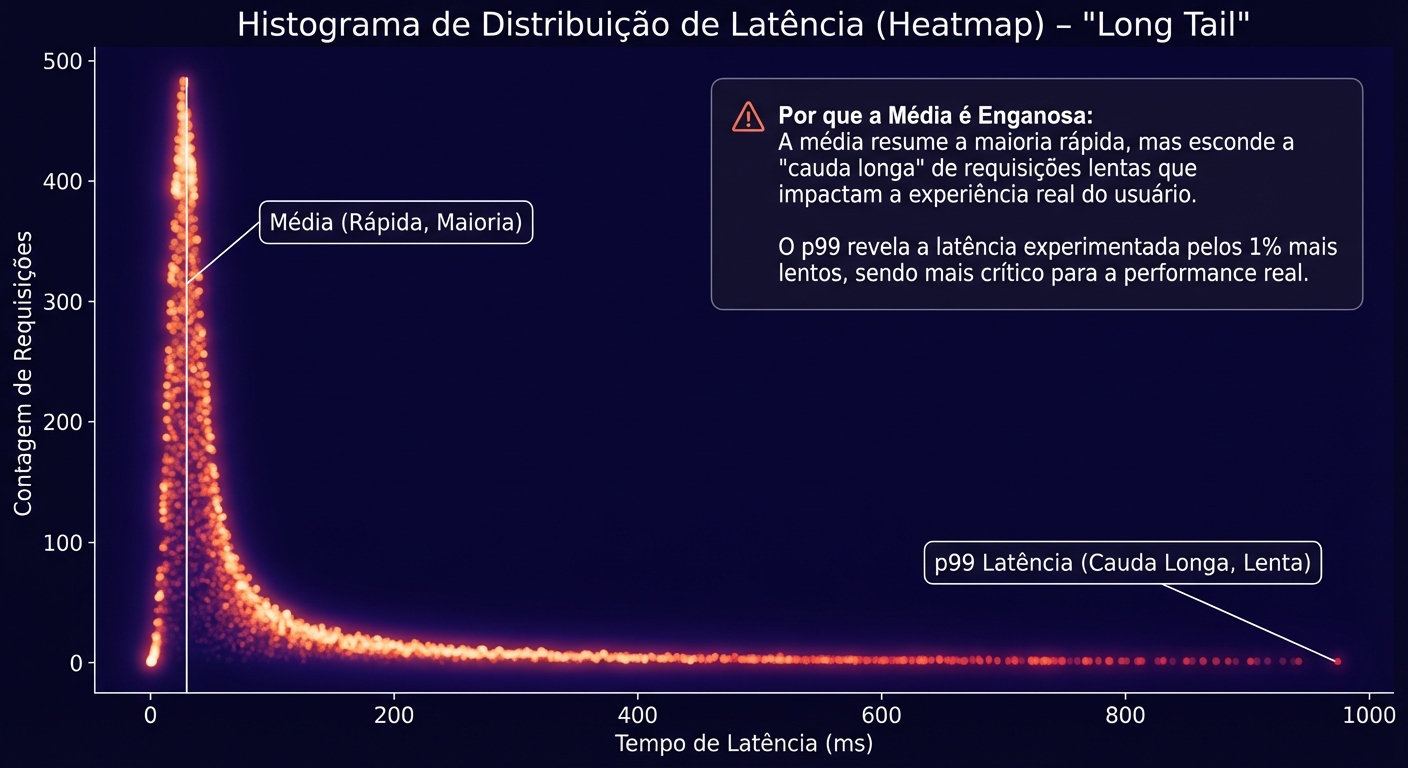
A Métrica Rainha: A latência é a métrica rainha porque ela afeta diretamente a percepção de velocidade de uma aplicação. Mesmo que seu disco tenha um alto IOPS e Throughput, se a latência for alta, a aplicação parecerá lenta.
Média vs Percentis (p95, p99): Por Que a Média Mente: É fundamental entender que a média da latência pode ser enganosa. Uma média baixa pode esconder picos de latência que afetam significativamente a experiência do usuário. Por isso, é crucial analisar os percentis da latência, como p95 (95º percentil) e p99 (99º percentil).
- p95: Significa que 95% das operações de I/O tiveram uma latência menor ou igual a esse valor.
- p99: Significa que 99% das operações de I/O tiveram uma latência menor ou igual a esse valor.
Analisar os percentis permite identificar picos de latência que a média esconde. Por exemplo, se a latência média for de 1ms, mas o p99 for de 10ms, isso significa que 1% das operações estão demorando 10ms ou mais, o que pode ser inaceitável para algumas aplicações.
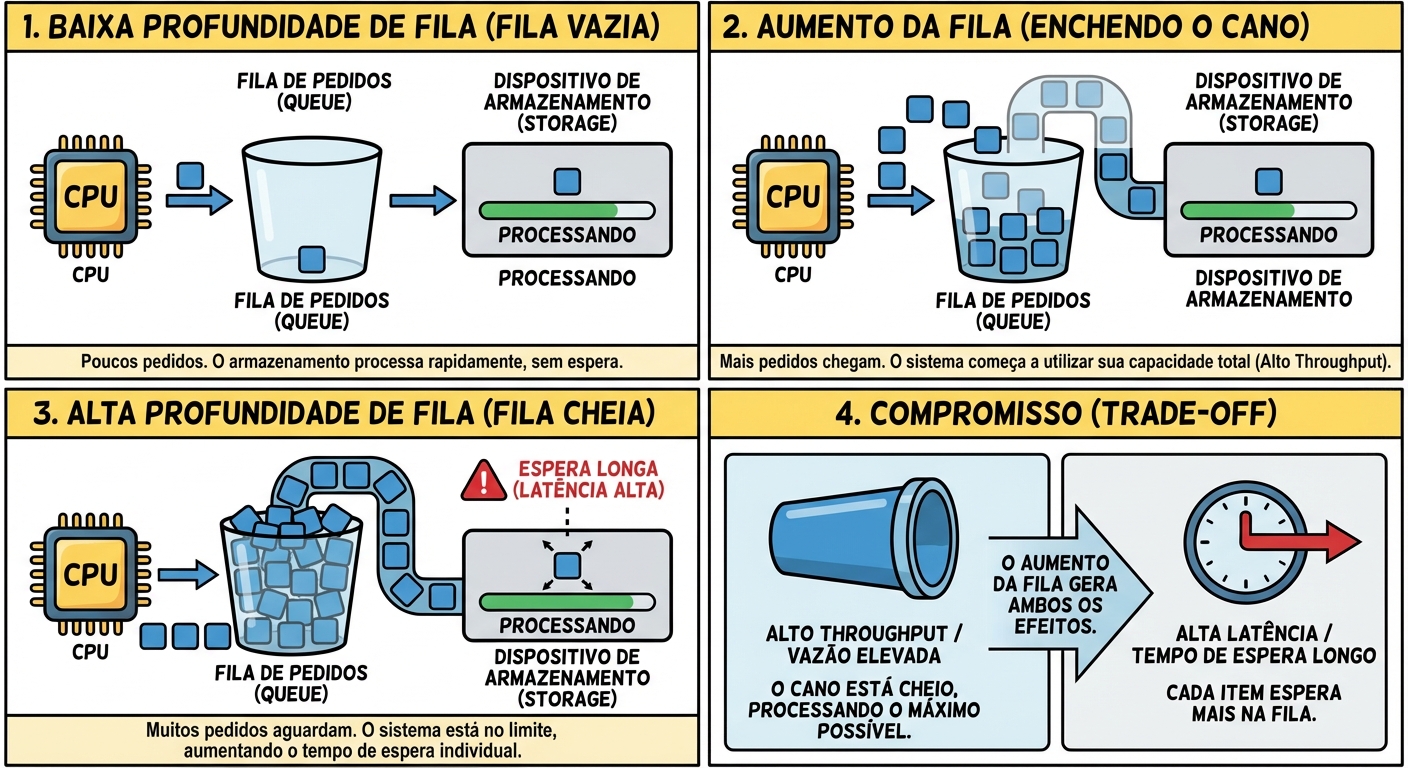
Queue Depth (Fila): O Congestionamento Necessário
Queue Depth, ou profundidade da fila, é o número de operações de I/O que estão aguardando para serem processadas pelo dispositivo de armazenamento. É uma métrica importante para entender o congestionamento do sistema de armazenamento.
Como a Fila Afeta a Latência e o IOPS: Uma fila muito curta significa que o dispositivo de armazenamento está ocioso, o que pode levar a um IOPS abaixo do ideal. Uma fila muito longa significa que o dispositivo de armazenamento está sobrecarregado, o que pode levar a uma alta latência.
A profundidade ideal da fila depende do dispositivo de armazenamento e da carga de trabalho. Em geral, SSDs podem lidar com filas mais longas do que HDDs.
Little's Law Aplicada a Storage: A Lei de Little é uma fórmula fundamental que relaciona a profundidade da fila, a latência e o IOPS:
L = λ * W
Onde:
- L: Profundidade média da fila (número de operações em espera)
- λ: Taxa média de chegada (IOPS)
- W: Tempo médio de espera (Latência)
Essa lei nos diz que, para um determinado IOPS, aumentar a latência aumentará a profundidade da fila. Da mesma forma, para uma determinada latência, aumentar a profundidade da fila aumentará o IOPS.
Como Medir: Ferramentas e Exemplos
Agora que entendemos as métricas, vamos ver como medi-las na prática. Existem diversas ferramentas disponíveis para monitorar o desempenho do armazenamento, incluindo:
- iostat: Uma ferramenta de linha de comando padrão em sistemas Linux e Unix que fornece estatísticas sobre o uso do disco.
- fio: Uma ferramenta de benchmark flexível e poderosa que permite simular diferentes cargas de trabalho e medir o desempenho do armazenamento.
- Monitoramento de Infraestrutura: Ferramentas como Prometheus, Grafana, Datadog e New Relic podem ser configuradas para coletar e visualizar métricas de armazenamento.
Exemplos de Saída e Interpretação:
iostat:
iostat -xz 1
A saída do iostat fornece diversas métricas, incluindo:
- rrqm/s, wrqm/s: Número de solicitações de leitura/escrita que foram mescladas por segundo. Um valor alto pode indicar que o sistema está fazendo muitas operações pequenas e sequenciais.
- r/s, w/s: Número de operações de leitura/escrita por segundo (IOPS).
- rkB/s, wkB/s: Quantidade de dados lidos/escritos por segundo (Throughput) em KB/s.
- avgrq-sz: Tamanho médio das solicitações em setores.
- avgqu-sz: Profundidade média da fila.
- await: Tempo médio de espera para as operações de I/O serem concluídas (Latência).
- %util: Porcentagem de tempo que o dispositivo está ocupado. Próximo de 100% indica gargalo.
fio:
fio --name=test --ioengine=libaio --filename=/dev/sdb --bs=4k --direct=1 --rw=randrw --rwmixread=70 --numjobs=1 --time_based --runtime=60 --group_reporting --iodepth=32
Este comando fio simula uma carga de trabalho de leitura/escrita aleatória com um tamanho de bloco de 4KB, uma proporção de leitura de 70% e uma profundidade de fila de 32. A saída do fio fornece métricas detalhadas sobre o desempenho do armazenamento, incluindo IOPS, Throughput e Latência.
Interpretação: Ao analisar a saída dessas ferramentas, procure por:
- IOPS consistente com as especificações do dispositivo: Se o IOPS estiver muito abaixo do esperado, pode haver um gargalo em outro lugar do sistema (CPU, memória, rede).
- Latência alta: Se a latência estiver alta, investigue a profundidade da fila e o uso do dispositivo. Uma fila longa e um alto uso do dispositivo indicam que o dispositivo está sobrecarregado.
- %util próximo de 100%: Indica que o disco está sendo totalmente utilizado, podendo ser um gargalo.
O Que Levar Disso: Diagnóstico e Otimização
Entender IOPS, Throughput e Latência é fundamental para diagnosticar gargalos de desempenho e otimizar seu ambiente de armazenamento. Aqui estão algumas dicas:
- Conheça sua carga de trabalho: Entenda como suas aplicações usam o armazenamento. Elas fazem muitas operações pequenas e aleatórias? Ou poucas operações grandes e sequenciais?
- Monitore as métricas: Use as ferramentas mencionadas acima para monitorar o desempenho do armazenamento em tempo real.
- Analise os percentis da latência: Não se contente com a média. Analise os percentis para identificar picos de latência.
- Considere o tamanho do bloco: Ajuste o tamanho do bloco para otimizar o desempenho da sua carga de trabalho.
- Escolha o dispositivo de armazenamento certo: SSDs são geralmente melhores para cargas de trabalho que exigem alto IOPS e baixa latência, enquanto HDDs podem ser mais adequados para cargas de trabalho que exigem alto Throughput e menor custo.
- Otimize a configuração do sistema: Ajuste as configurações do sistema operacional e do sistema de arquivos para otimizar o desempenho do armazenamento.
Ao dominar essas métricas e ferramentas, você estará bem equipado para diagnosticar e resolver problemas de desempenho relacionados ao armazenamento, garantindo que suas aplicações funcionem de forma rápida e eficiente. E, da próxima vez que alguém reclamar que "o banco de dados está lento", você saberá exatamente por onde começar a investigar.

David Ross
Linux Sysadmin Veterano
Vive no terminal. Mantenedor de diversos módulos kernel de storage. Acredita que GUI é bloatware.