Jbod Vs RAID Como Escolher Em 2025

Para entender por que estamos matando o RAID de hardware, precisamos visualizar o que ele realmente faz....
Jbod Vs RAID Como Escolher Em 2025
Para entender por que estamos matando o RAID de hardware, precisamos visualizar o que ele realmente faz.
Imagine que você é o Sistema Operacional (SO). Você quer gravar um arquivo. No modelo de RAID de Hardware, você entrega esse arquivo a um gerente burocrático (a Controladora RAID). Esse gerente diz: "Deixa comigo, eu cuido dos detalhes". Ele pega seu arquivo, assina um recibo (ACK) dizendo que gravou, mas na verdade ele apenas colocou na memória RAM dele (cache). Depois, ele decide como picotar esse arquivo e espalhar por vários discos que só ele conhece.
Se um disco falha, o gerente tenta esconder isso de você. Ele recalcula bits, faz trocas a quente, tudo nos bastidores. Parece ótimo, certo? O problema é que esse gerente é uma "Caixa Preta".
- Opacidade: Você não vê a saúde real dos discos individuais via ferramentas padrão do SO.
- Ponto Único de Falha (SPOF): Se o gerente (a placa controladora) morre, você não pode simplesmente ligar os discos em outra placa. A "linguagem" (metadados RAID) que ele usou para organizar os dados é proprietária. Você precisa de outra placa idêntica, com firmware compatível, para ler seus dados.
- Mentiras de Cache: Se a bateria da controladora (BBU) falhar e a energia cair, os dados que o gerente disse que gravou (mas estavam na RAM) somem. Corrupção silenciosa.
Agora, contraste isso com o Modelo JBOD/HBA (SDS).
Aqui, o SO (equipado com um sistema de arquivos inteligente como ZFS) é o gerente. A controladora de hardware é rebaixada a um simples "tubo" (HBA - Host Bus Adapter). Ela não pensa, não faz cache, não organiza. Ela apenas passa o comando SATA/SAS diretamente para o disco físico.
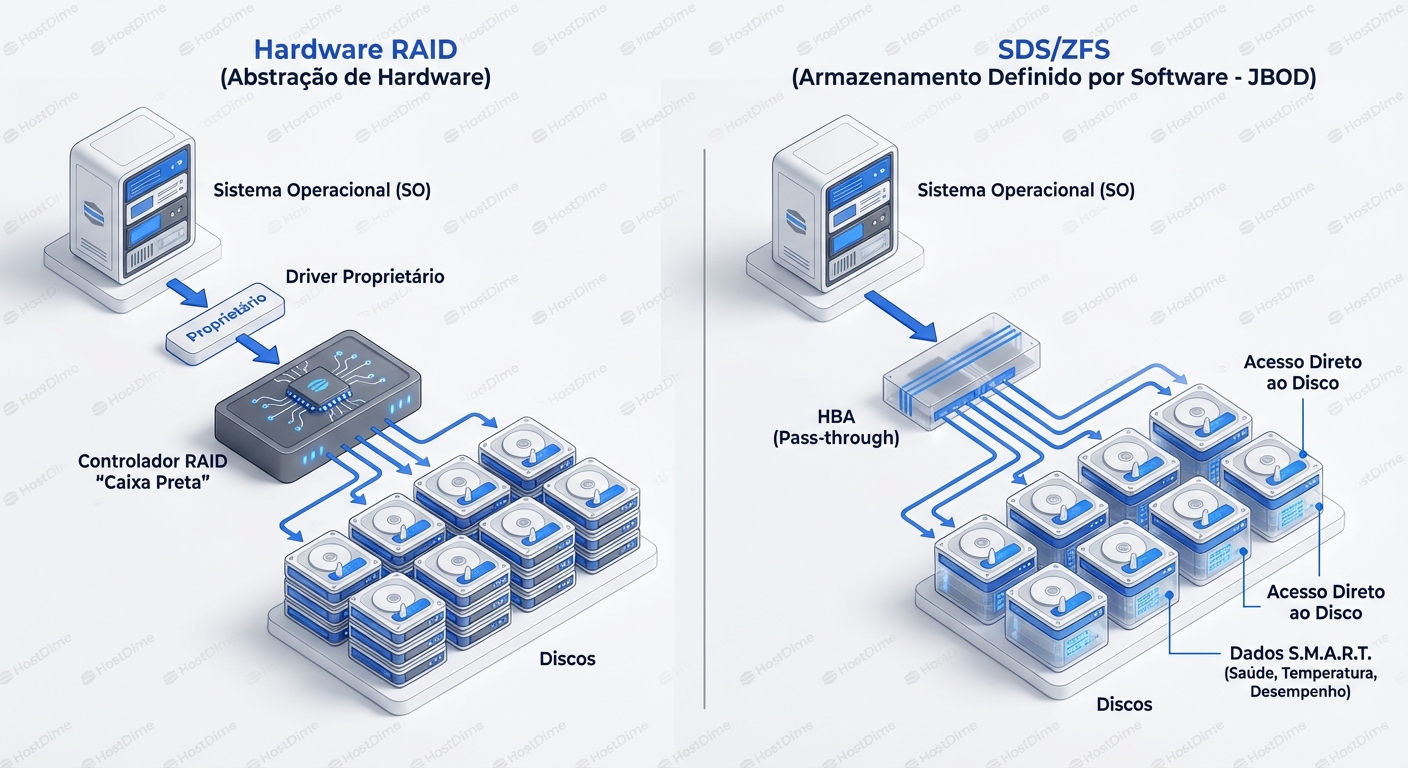
Neste modelo:
- O SO vê cada número de série, cada setor defeituoso, cada temperatura de cada disco.
- Se a controladora HBA queimar, você pega os discos, pluga em qualquer outra controladora (ou portas SATA da placa-mãe), importa o pool (ZFS import) e volta a trabalhar. A inteligência está nos dados, não no silício proprietário.
Under the Hood: Por que o Hardware RAID falha matematicamente em 2025
A "morte" do RAID de hardware não é apenas uma preferência de gestão; é uma necessidade matemática impulsionada pela densidade dos discos modernos.
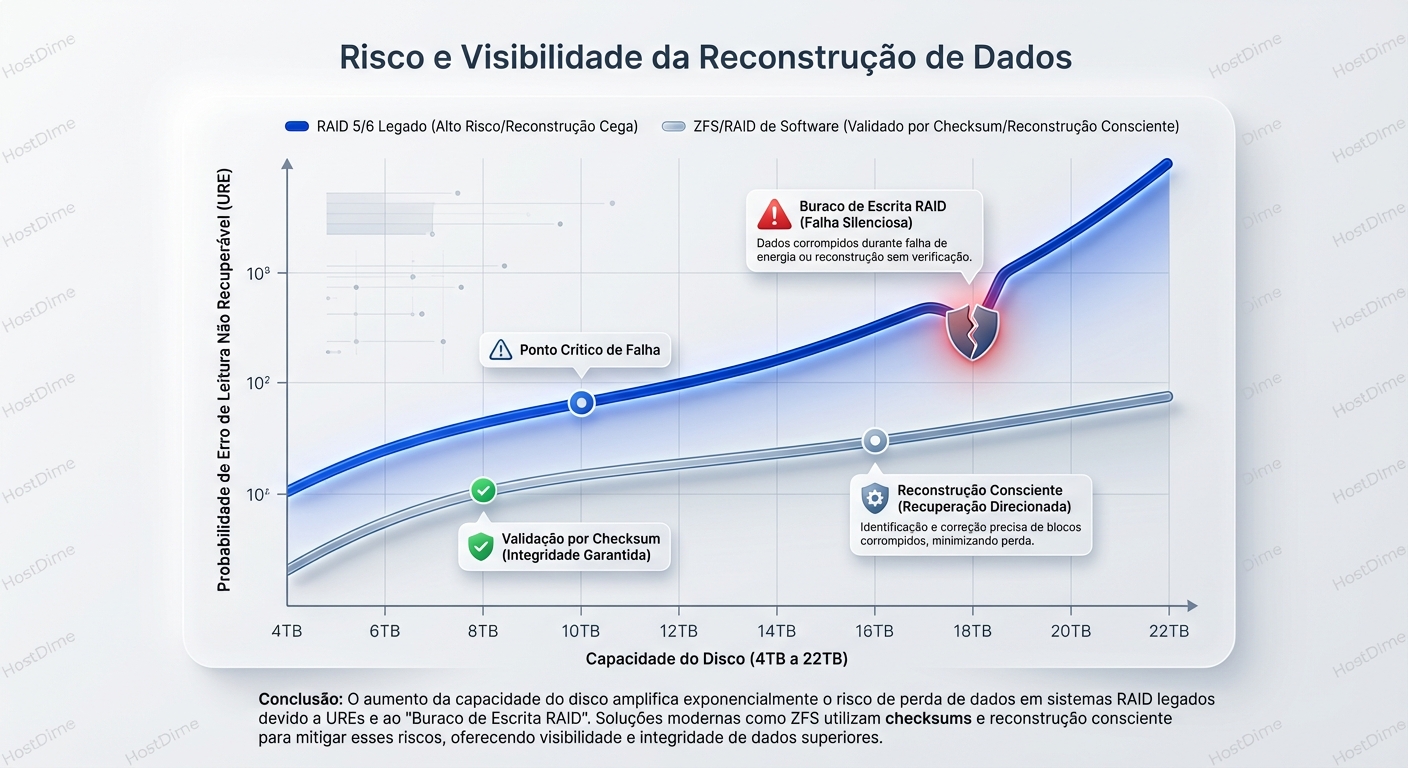
Vamos falar sobre URE (Unrecoverable Read Error).
Discos rígidos de consumo (SATA) geralmente têm uma taxa de erro de leitura não recuperável especificada de 1 em $10^{14}$ bits lidos. Discos Enterprise (SAS), talvez 1 em $10^{15}$.
Antigamente, com discos de 500GB, isso era irrelevante. A chance de encontrar um erro desses durante um rebuild de RAID 5 era estatisticamente baixa.
Hoje, temos discos de 20TB, 22TB.
Quando um disco em um RAID 5 de hardware falha, a controladora precisa ler cada bit dos discos restantes para reconstruir os dados perdidos. Faça as contas: Ler 20TB de dados aproxima-se perigosamente do limite estatístico de $10^{14}$ bits. A probabilidade de encontrar outro erro de leitura durante a reconstrução (o que mataria o array inteiro no caso do RAID 5) é aterrorizante.
O "Write Hole" do RAID Legado
O RAID de hardware clássico sofre do problema do "Write Hole" (Buraco de Escrita).
- O SO envia uma escrita.
- A controladora precisa atualizar o bloco de dados D1 e o bloco de paridade P1.
- A energia cai após D1 ser escrito, mas antes de P1 ser atualizado.
- O sistema volta. A controladora não sabe que P1 não corresponde mais a D1. A paridade está "suja".
- Meses depois, um disco falha. A controladora usa P1 para reconstruir dados. Como P1 estava errado, ela reconstrói lixo no lugar dos dados reais.
Sistemas modernos como ZFS resolvem isso via software com Copy-on-Write (CoW) e Checksums Transacionais.
- CoW: Nunca sobrescreve dados antigos. Escreve o novo dado e a nova paridade em um novo local. Só quando ambos estão seguros no disco é que o ponteiro de metadados é atualizado atomicamente. O "Write Hole" é arquiteturalmente impossível.
- Checksums: O ZFS não confia no disco. Cada bloco de dados tem um checksum (hash). Quando o ZFS lê um dado, ele calcula o hash e compara com o metadado. Se o disco mentir (bit rot), o ZFS sabe, busca a cópia redundante e corrige o erro em tempo real (Self-Healing). O RAID de hardware não pode fazer isso porque ele não entende o sistema de arquivos; ele só entende blocos.
Diagnóstico e Observabilidade: O Confronto
Vamos sair da teoria e ir para o terminal. Como essa diferença se manifesta quando estamos tentando descobrir o que há de errado?
Cenário A: RAID de Hardware (A Escuridão)
Você suspeita de um disco ruim.
# Tentativa padrão
df -h
# Tudo parece normal no tamanho, mas o sistema está lento.
smartctl -a /dev/sda
# SAÍDA:
# /dev/sda: Device does not support SMART
# (Ou mostra o status da controladora virtual, não do disco físico)
Para ver a verdade, você precisa "furar" a camada de abstração. Se tiver sorte e a controladora suportar passthrough de comandos SMART (como -d megaraid):
smartctl -a -d megaraid,0 /dev/sda
Nota: Você precisa saber o ID físico (0) que a controladora atribuiu, que muitas vezes não bate com o slot do chassi.
Se você precisar ver o progresso de um rebuild, você está preso a ferramentas como megacli (LSI/Broadcom) ou perccli (Dell), cujas sintaxes são crimes contra a usabilidade:
# Exemplo real de comando MegaCLI para ver o status do rebuild
/opt/MegaRAID/MegaCli/MegaCli64 -PDRbld -ShowProg -PhysDrv [252:1] -a0
Isso não é intuitivo. Isso é arqueologia.
Cenário B: JBOD + ZFS (A Transparência Radical)
Você suspeita de um disco ruim.
zpool status -v
A saída é gloriosa e humana:
pool: tank
state: DEGRADED
status: One or more devices has experienced an unrecoverable error.
action: Replace the device using 'zpool replace'.
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
wwn-0x5000cca250c... ONLINE 0 0 0
wwn-0x5000cca250d... DEGRADED 12 0 5 <-- Culpado!
wwn-0x5000cca250e... ONLINE 0 0 0
errors: List of errors
/data/production/db_backup.sql <-- O ZFS te diz EXATAMENTE qual arquivo foi afetado!
Olhe para a coluna CKSUM. O ZFS está te dizendo: "O disco disse que gravou, mas quando eu li de volta, 5 vezes o hash não bateu". Isso é Bit Rot ou cabeamento ruim sendo detectado em tempo real. O RAID de hardware teria entregue esses dados corrompidos silenciosamente para sua aplicação.
Para investigar o hardware físico, como temos um HBA em modo IT, o SO vê tudo:
# Listar topologia SAS/SATA
lsscsi -g
# Ver dados SMART reais
smartctl -x /dev/disk/by-id/wwn-0x5000cca250d...
Aqui, procuramos por atributos críticos que o RAID de Hardware costuma esconder até ser tarde demais:
- Reallocated_Sector_Ct: O disco está ficando sem setores de reserva?
- Current_Pending_Sector: Setores que o disco não consegue ler e está esperando uma escrita para tentar remapear.
- UDMA_CRC_Error_Count: Isso quase sempre indica cabo ruim ou backplane com poeira, não falha de disco. No RAID de HW, a controladora apenas derrubaria o disco como "Falha", fazendo você jogar fora um disco bom quando o problema era um cabo de $5.
Hardware: O que comprar (e o que evitar)
Se você decidiu migrar para o modelo SDS/JBOD, o hardware muda. Você não quer a placa RAID mais cara com 4GB de cache e bateria. Você quer a placa mais "burra" e confiável possível.
O Santo Graal: LSI em "IT Mode"
O padrão da indústria são os chips LSI (agora Broadcom).
- SAS2008 / SAS2308 (LSI 9211-8i, 9207-8i): Os clássicos para HDDs mecânicos e SSDs SATA. Baratos, robustos, PCIe 2.0/3.0.
- SAS3008 (LSI 9300-8i): Para SSDs SAS3 de 12Gbps.
O Ritual do Flashing: Muitas dessas placas vêm de fábrica em "IR Mode" (Integrated RAID). Elas tentam fazer RAID 0/1 simples. Isso é ruim para o ZFS. O ZFS quer controle total. Nós, sysadmins, passamos pelo rito de passagem de "flashar" o firmware para "IT Mode" (Initiator Target). Isso remove toda a lógica de RAID do firmware da placa, transformando-a em um HBA puro que apenas apresenta os dispositivos ao SO.
O Problema do NVMe
Em 2025, o jogo mudou novamente com o NVMe. Discos NVMe conectam-se diretamente ao barramento PCIe. Não existe "SATA" ou "SAS" no meio. Colocar uma placa RAID de hardware na frente de discos NVMe (chamado de Tri-Mode RAID) é geralmente uma péssima ideia.
- Gargalo: Uma placa RAID x8 ou x16 PCIe v4.0 torna-se um funil se você tentar pendurar 8 discos NVMe atrás dela. Cada NVMe quer x4 lanes dedicadas.
- Latência: O propósito do NVMe é baixa latência. Adicionar um controlador no meio adiciona microsegundos preciosos.
Para NVMe, o "JBOD" é nativo. Usamos PCIe Bifurcation ou Switches PCIe para conectar os discos diretamente à CPU. O ZFS ou mdadm gerencia a redundância. O conceito de "Controladora RAID" para NVMe é uma tentativa desesperada dos fabricantes de hardware de manter relevância em um mundo que não precisa mais deles.
Análise de Cenários: Quando o RAID de Hardware ainda (talvez) faça sentido?
Sejamos honestos. Eu odeio HW RAID, mas não sou dogmático. Existem nichos.
| Cenário | Veredito | Por quê? |
|---|---|---|
| Boot Drive (Windows/ESXi) | HW RAID 1 | O Windows não boota nativamente de ZFS ou arrays de software complexos facilmente. Um par de SSDs em RAID 1 na controladora da placa-mãe é simples e eficaz para o SO base. |
| Virtualização Legada | HW RAID | Se você está rodando um Hypervisor antigo que não entende HBA passthrough ou não tem suporte a SDS (ex: versões antigas de VMware sem vSAN), o HW RAID é a única forma de apresentar armazenamento protegido. |
| Storage de Arquivos (NAS/SAN) | ZFS/JBOD | Superior em todos os aspectos: integridade de dados, portabilidade, compressão (LZ4/ZSTD), snapshots. |
| Banco de Dados Alta Performance | NVMe Software Mirror | HW RAID adiciona latência. ZFS ou Linux MD RAID (mdadm) sobre NVMe direto entrega IOPS brutos muito maiores. |
| Sistemas sem RAM ECC | Discutível | O mito de que "ZFS precisa de ECC ou vai matar seus dados" é exagerado, mas HW RAID tem sua própria memória ECC interna. Ainda assim, prefiro ZFS sem ECC do que HW RAID. |
O Custo da "Liberdade" (Trade-offs)
Mudar para SDS/JBOD não é gratuito. Você está trocando dinheiro (custo da controladora RAID) por recursos de computação geral (CPU e RAM).
- Uso de RAM: O ZFS ama RAM. O cache de leitura (ARC) é agressivo. Enquanto uma placa RAID tem 2GB ou 4GB de cache, um servidor ZFS moderno deve ter 64GB, 128GB ou mais. A boa notícia? RAM é mais barata e mais versátil que cache proprietário de controladora.
- Ciclos de CPU: O cálculo de paridade (RAIDZ, RAIDZ2) e checksums (SHA-256, Fletcher4) é feito pela CPU principal. Em 2005, isso matava o servidor. Em 2025, com CPUs de 32/64 cores, o custo de calcular checksums é trivial (muitas vezes <3% de CPU) comparado ao benefício da integridade dos dados.
- Complexidade de Gestão: Você não pode apenas "espetar e esquecer". Você precisa configurar
scrubtasks (verificações periódicas de integridade), monitorar o tamanho do ARC, e entender como o ZFS lida com fragmentação. A curva de aprendizado é mais íngreme, mas o controle é absoluto.
O Veredito do Silício
A era da "Caixa Preta" acabou.
O RAID de hardware foi uma solução brilhante para um problema de uma era passada: CPUs lentas e discos pequenos e não confiáveis que precisavam de uma babá.
Hoje, vivemos na era dos dados massivos. Discos de 20TB+ tornam os métodos de reconstrução do RAID tradicional matematicamente perigosos. A opacidade das controladoras proprietárias é um risco operacional inaceitável quando precisamos de observabilidade granular.
A escolha para 2025 é clara:
- Use HBAs em IT Mode. Deixe o sistema operacional ver o disco nu.
- Use Sistemas de Arquivos Modernos (ZFS, Btrfs) que entendem a geometria do disco e garantem integridade ponta-a-ponta via checksums.
- Trate o hardware como commodity descartável. Se o servidor pegar fogo, seus discos devem ser legíveis em qualquer outro computador Linux padrão, sem depender de encontrar uma controladora RAID "PERC H730P Mini" específica no eBay.
A pergunta que deixo para sua próxima arquitetura: Você confia mais em um chip proprietário com firmware fechado de 5 anos atrás, ou no kernel do Linux e na matemática aberta do ZFS para proteger os dados da sua empresa?
Seus dados não pertencem à controladora. Eles pertencem a você. Recupere o controle.
Comandos de Bolso para o SRE Moderno (Linux)
Verificar se sua controladora é RAID ou HBA:
lspci -nn | grep -i LSI
# Procure por "IT mode" ou verifique o firmware via sas2flash/sas3flash
Identificar discos fisicamente (piscar LED) em JBOD:
# Se o backplane suportar SES (SCSI Enclosure Services)
ledmon
ledctl locate=/dev/sdX
Benchmark rápido de IOPS (Sem cache do FS):
fio --name=random-write --ioengine=libaio --rw=randwrite --bs=4k --numjobs=1 --size=4g --iodepth=1 --runtime=60 --time_based --end_fsync=1
Compare rodar isso em um volume HW RAID vs um ZVOL. Observe a latência (clat).
Verificar alinhamento de setores (Crucial para performance em SSDs/4K HDDs):
lsblk -t
# Verifique a coluna 'PHY-SEC' e o alinhamento de partições.
# ZFS faz 'ashift=12' automaticamente, HW RAID muitas vezes esconde isso.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.