Jumbo Frames Mito Vs Realidade E Quando Usar

São 2 da manhã de uma terça-feira. O alerta no PagerDuty toca com uma daquelas mensagens vagas que fazem qualquer sysadmin experiente suspirar: "Latência alta n...
Jumbo Frames Mito Vs Realidade E Quando Usar
São 2 da manhã de uma terça-feira. O alerta no PagerDuty toca com uma daquelas mensagens vagas que fazem qualquer sysadmin experiente suspirar: "Latência alta no cluster de banco de dados" ou "Aplicação web carregando parcialmente".
Você loga no servidor. O SSH conecta instantaneamente. O load average está baixo. A memória está livre. Você dá um ping no servidor de aplicação vizinho: resposta em sub-milissegundos. Tudo parece perfeito.
Mas quando você tenta fazer um curl ou um wget para baixar um arquivo grande, a conexão inicia e... congela. O cursor pisca, zombando de você. O telnet na porta 80 funciona. O handshake TCP completa. Mas assim que os dados reais começam a fluir, a conexão entra em um estado de coma.
Bem-vindo ao inferno do MTU Mismatch.
Em algum lugar entre o seu servidor e o destino, alguém configurou Jumbo Frames (MTU 9000) em uma ponta, mas esqueceu um switch no meio do caminho com MTU 1500. Ou pior: o firewall está bloqueando pacotes ICMP "Fragmentation Needed", quebrando o mecanismo de descoberta de MTU (PMTUD).
Historicamente, nós aceitávamos esse risco operacional em troca de performance. A promessa do MTU 9000 era sedutora: menos interrupções de CPU, maior throughput, menos overhead. Mas estamos em uma nova era de hardware. As placas de rede (NICs) de hoje são computadores completos.
A tese deste artigo é direta, mas polêmica: Para 95% das cargas de trabalho modernas, Jumbo Frames são um débito técnico desnecessário. A tecnologia de Hardware Offloading (TSO, LSO, GRO) tornou a otimização de MTU irrelevante para a CPU, deixando você apenas com a dor de cabeça do gerenciamento de rede.
Vamos desmontar esse mito, camada por camada.
A Matemática da Eficiência (O Sonho Antigo)
Para entender por que Jumbo Frames foram criados, precisamos voltar a uma época em que CPUs de 500MHz lutavam para saturar um link de 1Gbps.
O padrão Ethernet define o MTU (Maximum Transmission Unit) em 1500 bytes. Isso significa que o maior pacote de dados que pode trafegar na rede, incluindo cabeçalhos IP e TCP, é de 1.5 KB.
Vamos olhar para a estrutura de um pacote TCP/IP sobre Ethernet. Cada pacote carrega uma "taxa fixa" de bytes que não são seus dados:
- Ethernet Header + FCS: 18 bytes (14 cabeçalho + 4 checksum)
- IP Header: 20 bytes
- TCP Header: 20 bytes (mínimo)
- Inter-frame Gap + Preamble: 20 bytes (nível físico)
Total de overhead por pacote: ~78 bytes (variável dependendo de opções TCP/IP e camada física, mas vamos simplificar).
Se você envia 1500 bytes, cerca de 97% é carga útil (payload). Se você aumenta o MTU para 9000 bytes (Jumbo), o overhead permanece fixo, mas a carga útil explode. A eficiência sobe para mais de 99%.
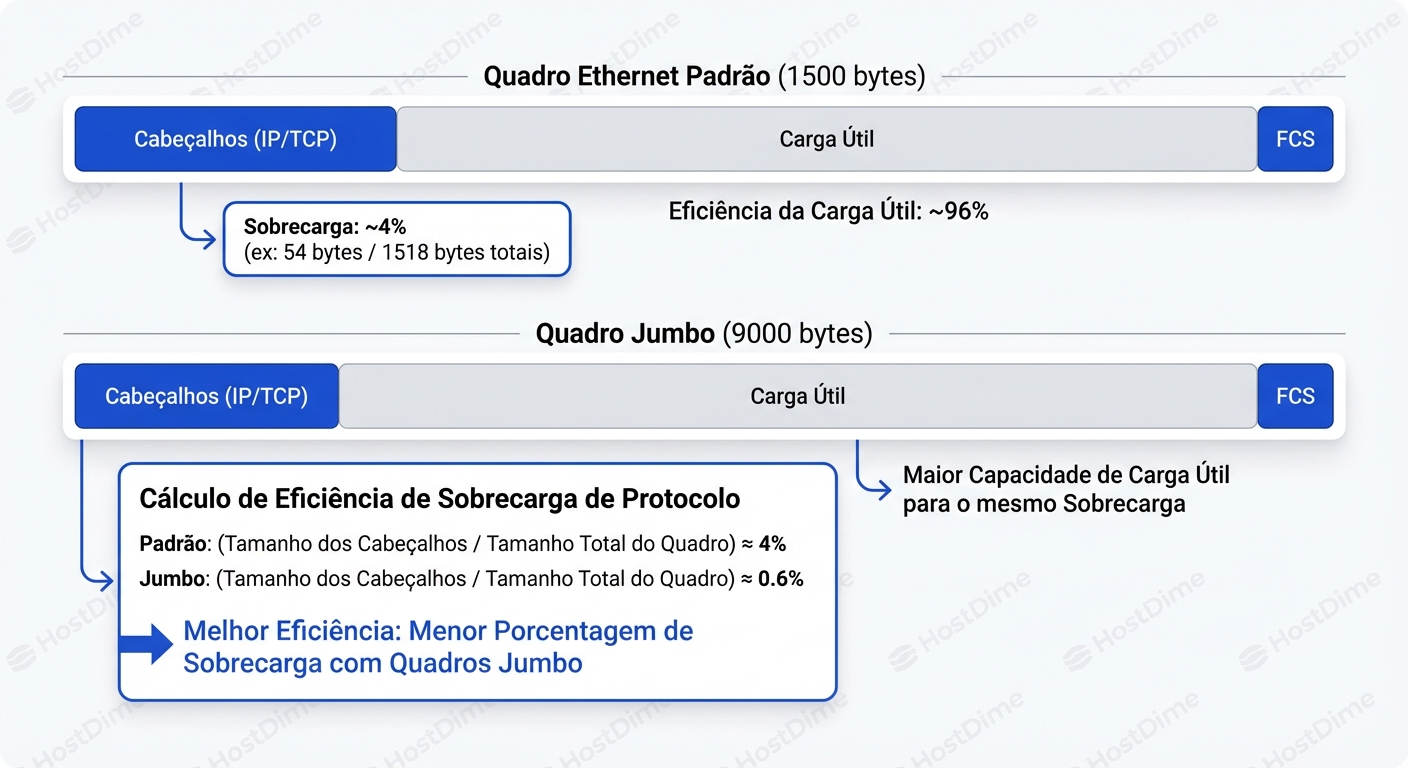
Parece ótimo, certo? Menos pacotes para enviar a mesma quantidade de dados. Mas a verdadeira motivação nunca foi a largura de banda. O cabo de rede não se importa se 3% dele é cabeçalho.
O gargalo real era a Interrupção de CPU.
O Custo da Interrupção
Cada vez que um pacote chega na placa de rede, a NIC gera uma interrupção de hardware (IRQ). A CPU precisa parar o que está fazendo, salvar o contexto, processar o pacote, copiar os dados da memória da placa para a RAM (DMA) e voltar ao trabalho.
Em um link de 1Gbps saturado com MTU 1500:
- ~82.000 pacotes por segundo.
- ~82.000 interrupções por segundo.
Isso triturava as CPUs antigas. Ao mudar para MTU 9000, você reduzia o número de pacotes por um fator de 6:
- ~13.000 pacotes por segundo.
- CPU feliz, sysadmin feliz.
Esse era o modelo mental de 2005. Se você ainda pensa assim hoje, você está otimizando para um problema que o hardware já resolveu para você.
A Revolução Silenciosa: TSO, LSO e GRO
Enquanto debatíamos configurações de switch, os fabricantes de NICs (Intel, Mellanox, Broadcom) e os desenvolvedores do Kernel Linux implementaram uma mágica chamada Offloading.
A ideia é simples: a CPU é cara e genérica; a NIC é barata e especializada. Por que a CPU deveria perder tempo fatiando dados em pedaços de 1500 bytes?
O Modelo Mental do "MTU Virtual"
Imagine que o Kernel do Linux não vê mais a rede como uma série de pacotes de 1500 bytes. Graças ao TSO (TCP Segmentation Offload), o sistema operacional mente para si mesmo. Ele acredita que pode enviar um pacote de 64KB (65.536 bytes) de uma só vez.
O fluxo acontece assim:
- Aplicação (Nginx/Postgres): Escreve 64KB no socket.
- TCP Stack (Kernel): Não fragmenta. Ele cria um "super-pacote" de 64KB.
- Driver da NIC: Recebe esse bloco gigante. A CPU gastou apenas uma operação para processar 64KB.
- A NIC (Hardware): Aqui acontece a mágica. O chip da placa de rede pega esse bloco de 64KB e o fatia em pacotes de 1500 bytes na velocidade do fio (wire-speed), calcula os checksums e os cospe no cabo.
Do ponto de vista da CPU, você já está usando Jumbo Frames gigantescos de 64KB. O trabalho pesado de segmentação foi terceirizado para o silício da placa de rede.
A Sopa de Letras do Offloading
Para diagnosticar problemas ou tunar performance, você precisa distinguir essas siglas. Use ethtool -k <interface> para ver o estado delas.
| Sigla | Nome Completo | Onde Acontece? | Função | Impacto na CPU |
|---|---|---|---|---|
| TSO | TCP Segmentation Offload | Envio (TX) | A NIC fatia grandes buffers em pacotes MTU. | Massivo. A CPU trabalha menos. |
| LSO | Large Send Offload | Envio (TX) | Termo genérico para TSO. | Mesmo do TSO. |
| GSO | Generic Segmentation Offload | Envio (TX) - Software | Se a NIC não suporta TSO, o Kernel emula isso logo antes do driver. | Médio. Adia a segmentação até o último momento. |
| LRO | Large Receive Offload | Recebimento (RX) - Hardware | A NIC junta pacotes recebidos em um "super-pacote" antes de dar a interrupção. | Massivo. Mas quebra roteamento/bridging (não use em roteadores). |
| GRO | Generic Receive Offload | Recebimento (RX) - Software | Versão segura do LRO feita pelo Kernel. Junta pacotes logo após a interrupção. | Alto. Padrão ouro para recebimento hoje. |
Por que isso mata o argumento do MTU 9000?
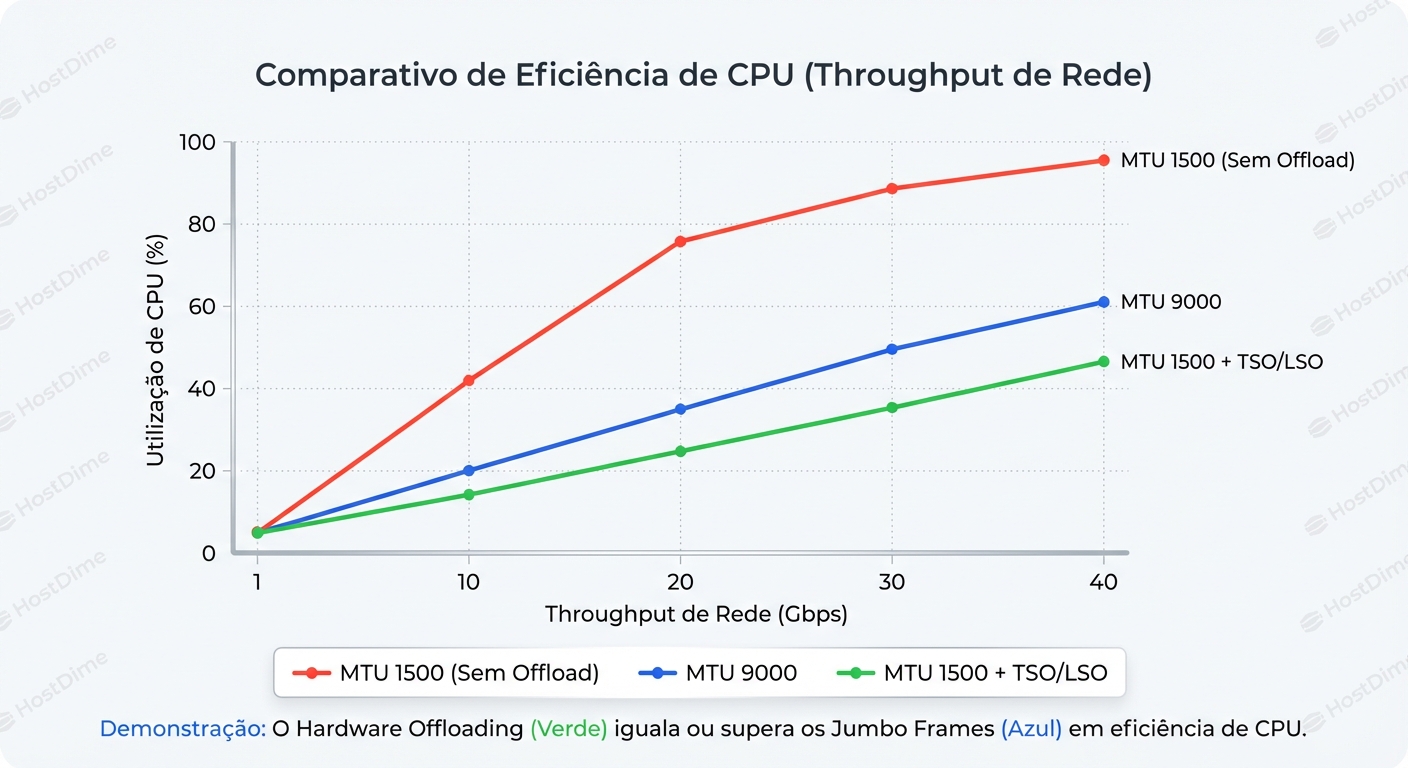
Se você habilitar Jumbo Frames (MTU 9000) em um servidor moderno com TSO ativado, o que muda para a CPU?
- Com MTU 1500 + TSO: O Kernel envia um bloco de 64KB para a NIC. A NIC divide em ~44 pacotes de 1500 bytes.
- Com MTU 9000 + TSO: O Kernel envia um bloco de 64KB para a NIC. A NIC divide em ~7 pacotes de 9000 bytes.
A diferença de trabalho para a CPU é zero. O Kernel entregou o mesmo bloco de 64KB em ambos os casos. A economia de interrupções no recebimento (RX) também é mitigada pelo GRO, que agrupa os pacotes de entrada antes que a stack TCP precise lidar com eles individualmente.
O único ganho real que sobra para o MTU 9000 é a redução do overhead de cabeçalho no fio (aqueles 3% vs 0.5%). Em um link de 10Gbps, isso te dá teóricos ~250Mbps a mais. Vale a pena o risco de quebrar sua rede?
O Campo Minado: Quando o Jumbo Falha
A fragilidade dos Jumbo Frames reside na necessidade de consistência fim-a-fim.
Para que uma conexão MTU 9000 funcione, cada dispositivo no caminho deve suportá-la e estar configurado corretamente:
- NIC do Servidor A
- Switch Top-of-Rack A
- Switch Core / Spine
- Roteadores intermediários
- Switch Top-of-Rack B
- NIC do Servidor B
Se um desses dispositivos estiver com MTU 1500, o pacote é descartado. Não há negociação automática de MTU na camada Ethernet. É um valor estático.
O Mecanismo de Falha: PMTUD e o Buraco Negro
Teoricamente, o IP resolve isso com fragmentação ou PMTUD (Path MTU Discovery). Quando um roteador encontra um pacote de 9000 bytes que precisa passar por um link de 1500 bytes, e o bit "Don't Fragment" (DF) está setado (padrão na maioria dos tráfegos TCP modernos), o roteador descarta o pacote e envia um ICMP Type 3, Code 4 ("Fragmentation Needed") de volta ao remetente, dizendo: "Ei, diminua seu MTU para 1500".
O problema? Firewalls paranoicos.
Muitos administradores de segurança bloqueiam todo tráfego ICMP por "segurança". Se esse pacote ICMP for bloqueado, o servidor remetente nunca saberá que precisa diminuir o tamanho do pacote. Ele continuará reenviando o pacote de 9000 bytes, que continuará sendo dropado silenciosamente.
O resultado é a conexão zumbi:
- Handshake TCP (SYN/ACK): Funciona, pois são pacotes pequenos (60 bytes).
- Request HTTP/SQL: Funciona, pacote pequeno.
- Response (Dados): Falha. O servidor tenta enviar um pacote cheio, o buraco negro o engole. A aplicação fica esperando (hang) até o timeout.
Diagnóstico de Combate: Interpretando os Sinais
Como saber se você é vítima de um problema de MTU ou se o Offload está funcionando? Esqueça as GUIs. Vamos para o terminal.
1. Verificando o Offload
Primeiro, saiba o que sua placa está fazendo.
# Linux
ethtool -k eth0 | grep -i segmentation
# Saída esperada:
# tcp-segmentation-offload: on
# tx-tcp-segmentation: on
# tx-tcp-ecn-segmentation: on
# tx-tcp6-segmentation: on
Se estiver on, sua CPU está protegida, independente do MTU.
2. O Teste Definitivo: Ping com DF Bit
O comando mais importante do seu arsenal. Vamos tentar forçar um pacote através da rede com o bit "Don't Fragment" ativado.
Cenário: Você quer testar se o caminho suporta MTU 9000. Lembre-se da matemática: MTU = Payload ICMP + 8 bytes (ICMP Header) + 20 bytes (IP Header). Então, para testar MTU 9000, o payload deve ser 8972 bytes.
# Linux
ping -M do -s 8972 192.168.10.5
# Windows
ping -f -l 8972 192.168.10.5
Interpretação:
- Sucesso: O caminho inteiro suporta Jumbo Frames.
- "Message too long" (Local): Sua própria interface está configurada com MTU menor que 9000.
- Timeout (Sem resposta): O perigo real. O pacote saiu, mas foi dropado no caminho e nenhum erro ICMP retornou. Você tem um Black Hole.
- "Packet needs to be fragmented but DF set" (Remoto): O PMTUD está funcionando! Um roteador no caminho respondeu que não aguenta o tamanho.
3. Detectando Falhas Silenciosas
Se você suspeita de problemas intermitentes, olhe para as estatísticas de IP e TCP.
# Verifique contadores de fragmentação e erros de PMTU
nstat -az | grep -E 'IpFrag|Pmtu'
Procure por incrementos em:
IpReasmFails: O servidor está recebendo fragmentos mas falhando em remontá-los (comum em redes de alta velocidade onde fragmentos chegam fora de ordem ou o buffer estoura).TcpExtPmtuDiscoveryFailures: O kernel detectou que o PMTUD falhou (ex: detectou retransmissões massivas sem resposta ICMP).
4. Tcpdump: Vendo o MSS
O TCP decide o tamanho do pacote durante o handshake através da opção MSS (Maximum Segment Size). MSS = MTU - 40 (cabeçalhos IP+TCP).
tcpdump -i eth0 -nn "tcp[tcpflags] & (tcp-syn) != 0"
Se você ver um MSS de 8960 no SYN, as máquinas estão tentando falar Jumbo. Se logo depois você ver muitas retransmissões e nenhum dado fluindo, você confirmou o diagnóstico.
O Veredito: Quando (Realmente) Usar Jumbo Frames
Depois de toda essa crítica, existe algum lugar para o MTU 9000? Sim. Mas é um nicho, não o padrão.
O Cenário Ideal: Storage Dedicado (SAN/NAS)
Se você tem uma rede dedicada para iSCSI, NFS ou vMotion, isolada fisicamente ou via VLAN, onde você controla cada porta de switch e cada placa de rede, Jumbo Frames ainda brilham.
Por que?
- Throughput Bruto: Em links de 40Gbps ou 100Gbps, aqueles 3% de eficiência de cabeçalho se tornam gigabits reais de dados.
- Latência de Armazenamento: Storage arrays se beneficiam de receber payloads maiores e contíguos com menos processamento de cabeçalho L2.
- Ambiente Controlado: Não há "internet" no meio, nem firewalls desconhecidos, nem roteadores de terceiros. A chance de quebra de PMTUD é mínima.
O Cenário Obrigatório: Overlay Networks (VXLAN / Geneve)
Este é o uso moderno mais crítico. Em ambientes de Cloud e Kubernetes, usamos redes de sobreposição (Overlay). O pacote original (MTU 1500) é encapsulado dentro de um pacote UDP (VXLAN). Isso adiciona 50 bytes de cabeçalho extra.
Se a sua rede física (Underlay) for MTU 1500, o pacote VXLAN terá 1550 bytes e será fragmentado. Fragmentação em tunelamento mata a performance. Solução: Configure a rede física com MTU 9000 (ou pelo menos 1600) para que ela possa carregar confortavelmente os pacotes encapsulados de 1500 bytes sem fragmentar.
Matriz de Decisão
| Cenário | Veredito | Justificativa |
|---|---|---|
| Tráfego Web / App (LAN) | MTU 1500 | TSO/GRO resolvem a CPU. O risco de misconfiguration não compensa. |
| Tráfego Internet (WAN) | MTU 1500 | A Internet é MTU 1500. Não lute contra isso. |
| Storage (iSCSI/NFS) | MTU 9000 | Ganhos marginais de throughput e latência. Ambiente controlado. |
| Backup / Data Mover | MTU 9000 | Transferências longas e massivas se beneficiam da redução de overhead. |
| Virtualização (Underlay) | MTU 9000 | Necessário para evitar fragmentação de pacotes encapsulados (VXLAN). |
A Complexidade é o Inimigo
A engenharia é a arte do trade-off. Ao habilitar Jumbo Frames, você está trocando compatibilidade e simplicidade por eficiência teórica.
Com NICs modernas de 10/25/100GbE e processadores multicore poderosos, o gargalo raramente é o processamento de pacotes por segundo, a menos que você seja o Google ou a Netflix. O gargalo geralmente é a aplicação, o disco, ou o banco de dados.
Antes de sair alterando o MTU da sua infraestrutura inteira, faça a si mesmo três perguntas:
- Meu
ethtoolmostra que TSO/GRO estão ativos? - Eu controlo todos os switches e roteadores no caminho?
- Eu tenho um problema de performance comprovado que o Jumbo Frames vai resolver?
Se a resposta para qualquer uma for "não" ou "não sei", mantenha o padrão 1500. A melhor configuração de rede é aquela que você não precisa depurar às 3 da manhã.
Para aprofundar
A discussão não termina aqui. Vale a pena investigar como o eBPF e o XDP (eXpress Data Path) estão mudando o jogo novamente, permitindo processamento de pacotes no kernel antes mesmo de alocar estruturas de metadados pesadas (sk_buff), tornando a discussão de MTU ainda mais irrelevante para performance de firewall e roteamento em software. Mas isso é assunto para outro incidente.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.