Kubernetes e RAID: Onde os Dados Realmente Vivem (e Morrem)

Esqueça a abstração mágica. Entenda como integrar RAID com Kubernetes Persistent Volumes, os riscos de Local PVs e como medir o impacto de I/O em seus containers.
Kubernetes é frequentemente vendido como a camada de abstração definitiva: você pede recursos via YAML e o cluster entrega. Para CPU e RAM, isso é verdade; são recursos fungíveis. Se um nó morre, o scheduler move o Pod para outro lugar e o cálculo continua. Mas Storage tem gravidade.
Diferente de um processo de cálculo, os dados não podem ser teletransportados instantaneamente. Quando você define um PersistentVolumeClaim (PVC), você está assinando um contrato com a física do disco subjacente. Muitos arquitetos tratam o storage no Kubernetes como uma "caixa preta" mágica, ignorando que, no final da pilha, existe um cabeçote magnético ou uma célula NAND que precisa ser gerenciada.
Se você ignorar a relação entre o orquestrador (K8s) e a redundância física (RAID), você não terá apenas problemas de performance; você terá perda de dados disfarçada de "erro de timeout".
Persistência de Dados em Kubernetes sobre RAID É a estratégia arquitetural de desacoplar a redundância lógica (réplicas de Pods/bancos de dados) da redundância física (RAID/Erasure Coding). O objetivo é garantir que a falha de um disco físico não cause a indisponibilidade imediata do Pod, gerenciando o trade-off entre latência de I/O local (Local PV) e flexibilidade de agendamento (Network Storage/CSI).
A Ilusão da Abstração no Kubernetes e a Física do Disco
O erro mais comum ao desenhar soluções de storage para Kubernetes é confiar cegamente na StorageClass. Quando um desenvolvedor solicita 100GB de disco "rápido", o Kubernetes delega isso via CSI (Container Storage Interface). O K8s não sabe se esses 100GB são um LUN em uma SAN Enterprise, um arquivo em um servidor NFS ou uma partição em um SSD NVMe local.
Essa cegueira é intencional, mas perigosa para quem opera. O RAID vive abaixo do Kubernetes. Se o seu array RAID 5 local entrar em modo degradado, o Kubernetes não saberá disso nativamente. Ele continuará enviando requisições de I/O para o nó. O Pod não cairá, mas a latência disparará, causando timeouts na aplicação que o K8s interpretará como falha de liveness, reiniciando o Pod em um loop infinito.
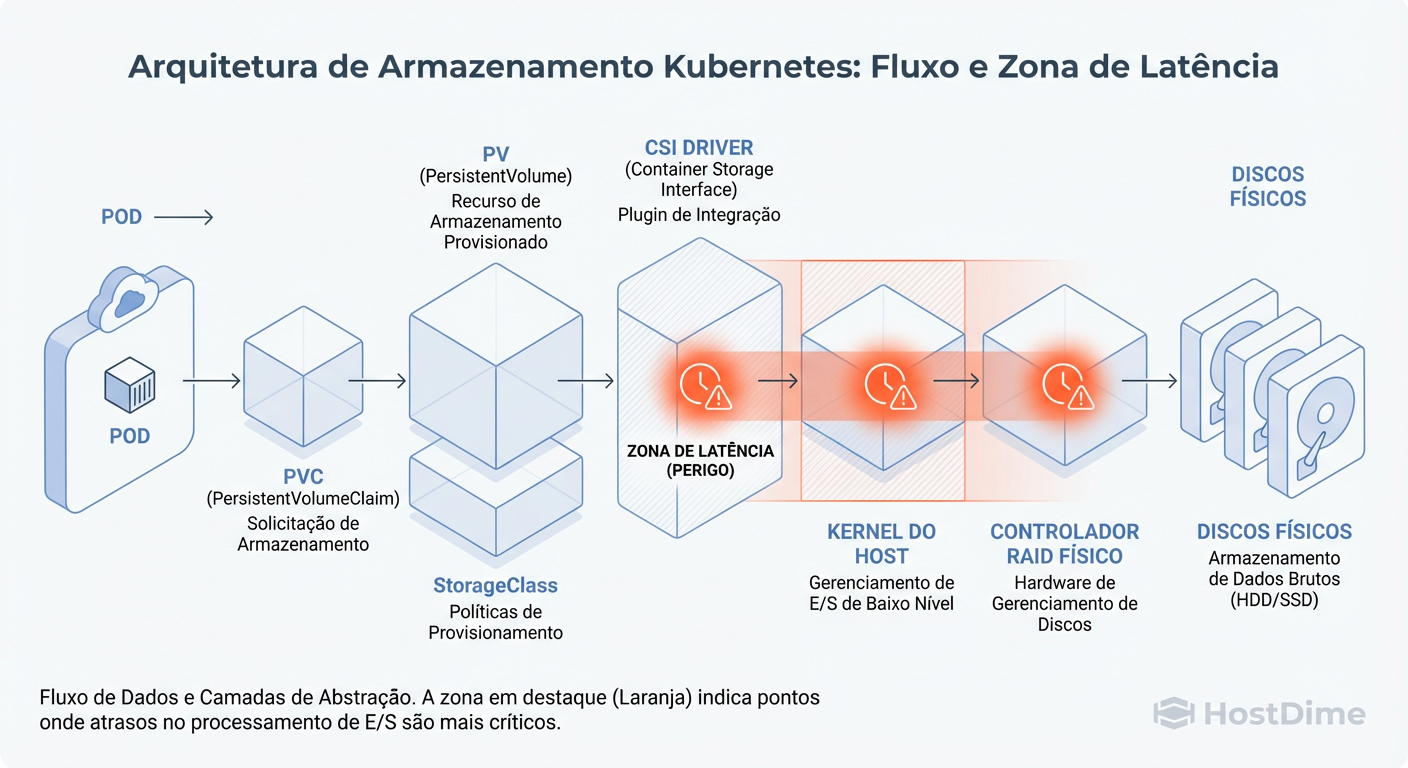 Figura: O Caminho do I/O: Do Pod ao Disco Físico. A camada CSI (Container Storage Interface) é a ponte, mas o RAID é o alicerce.
Figura: O Caminho do I/O: Do Pod ao Disco Físico. A camada CSI (Container Storage Interface) é a ponte, mas o RAID é o alicerce.
Entender essa pilha é vital. O CSI é apenas a ponte. Se a fundação (o RAID) treme, a ponte não cai, mas o tráfego para.
Topologia de Storage: RAID no Host vs. RAID na Rede
A decisão mais crítica de TCO (Total Cost of Ownership) e performance é onde o RAID é processado. Não existe "melhor", existe o que o seu workload exige.
1. RAID no Host (Local Persistent Volumes)
Aqui, você usa o controlador RAID (físico ou software como mdadm/ZFS) do próprio servidor onde o K8s roda. O PV é atrelado a esse nó específico.
Vantagem: Latência imbatível. O dado está no barramento PCIe/SATA local.
Risco: Se a placa-mãe do nó queimar, seus dados estão inacessíveis até você consertar aquele servidor específico. O RAID protege o disco, não o servidor.
2. RAID na Rede (Ceph, EBS, SAN iSCSI)
O armazenamento é externo. O RAID (ou Erasure Coding) acontece em um cluster de storage separado.
Vantagem: O Pod é móvel. Se o nó K8s morrer, o Pod sobe em outro nó e "monta" o volume pela rede.
Risco: Latência de rede e o problema do "I/O Blender" (mistura de I/O de vários vizinhos).
Comparativo de Arquitetura de Storage
| Característica | RAID Local (Local PV) | RAID em Rede (Ceph/EBS/SAN) |
|---|---|---|
| Latência | Baixíssima (Microsegundos) | Média/Alta (Milisegundos) |
| IOPS | Limitado pelo Hardware Local | Escalável (mas custoso) |
| Mobilidade do Pod | Zero (Pod preso ao Nó) | Alta (Pod flutua no cluster) |
| Proteção de Dados | Contra falha de disco apenas | Contra falha de disco e de nó |
| Complexidade | Baixa (Linux padrão) | Alta (Gestão de cluster distribuído) |
| Caso de Uso Ideal | Bancos Distribuídos (Kafka, Cassandra) | Apps Monolíticos, CMS, RWO genérico |
O Anti-Pattern Perigoso: Software RAID dentro do Container
Em minha experiência recuperando clusters "criativos", encontrei tentativas de rodar mdadm ou ZFS dentro de um container privilegiado para agregar discos passados via passthrough. Não faça isso.
Isso viola o princípio de isolamento. O gerenciamento de redundância de disco é uma tarefa de kernel e hardware, não de user space efêmero.
Race Conditions: O container pode morrer enquanto o array está sincronizando.
Resource Starvation: O processo de reconstrução do RAID (rebuild) vai competir por CPU com a aplicação, sem que o
cgroupsconsiga arbitrar isso eficientemente.Complexidade de Boot: Se o container de storage não subir, nenhum outro container que dependa dele subirá. Você criou um ponto único de falha frágil.
A regra é clara: O host (ou o appliance de storage) cuida da proteção física (RAID). O Kubernetes cuida da orquestração lógica.
O Custo Oculto do Rebuild e a Latência do Pod
Imagine um cenário: Você tem um nó Kubernetes com RAID 5 de SSDs locais hospedando um banco de dados crítico. Um SSD falha. O controlador RAID inicia o rebuild (reconstrução) usando o disco de hot spare.
Nesse momento, a performance de leitura do array degrada drasticamente, pois cada leitura em blocos não reconstruídos exige cálculos de paridade em tempo real.
Para o Kubernetes, o nó está "Saudável" (Ready). Mas para a aplicação, o disco que respondia em 0.5ms agora responde em 20ms.
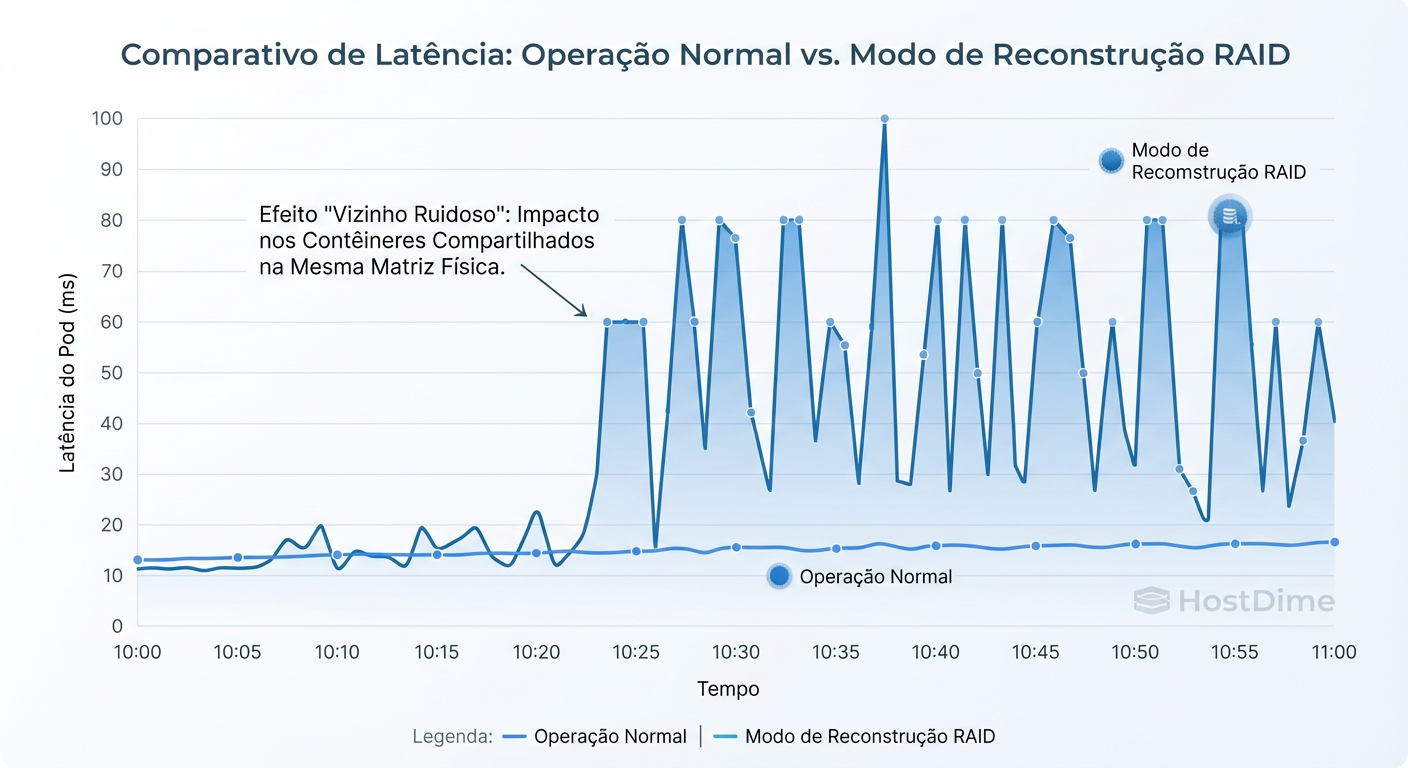 Figura: Impacto do Rebuild: O efeito 'vizinho barulhento' em latência de Pods durante a reconstrução de um array RAID no host.
Figura: Impacto do Rebuild: O efeito 'vizinho barulhento' em latência de Pods durante a reconstrução de um array RAID no host.
Esse é o efeito "Vizinho Barulhento Interno". O processo de reconstrução rouba IOPS da aplicação. Se você não planejou headroom (sobra de capacidade) de IOPS para situações de rebuild, seu cluster entrará em colapso operacional, mesmo sem perda de dados.
Callout de Risco: Em arrays RAID 5/6 grandes (ex: 10TB+ por disco), o tempo de rebuild pode levar dias. Durante esse tempo, um segundo erro de disco significa perda total de dados. Prefira RAID 10 para workloads críticos em K8s para minimizar a penalidade de rebuild.
Métricas que Importam: Monitorando IOPS e I/O Wait
Não olhe apenas para o Prometheus do Pod. O Pod vive uma mentira isolada. Você precisa monitorar o "chão de fábrica" (o Node).
Para provar que o storage é o gargalo, você precisa correlacionar métricas de orquestração com métricas de sistema operacional.
O que medir no Host (Node Exporter):
I/O Wait (%iowait): Indica que a CPU está ociosa esperando o disco responder. Se isso passar de 5-10% constantemente, seus discos (ou seu array RAID) não estão acompanhando a demanda.
Service Time (svctm): O tempo médio que o disco leva para processar um pedido.
Queue Depth: Quantas operações estão na fila esperando para serem gravadas.
Como diagnosticar (Shell):
Se você suspeita de problemas, entre no nó (via SSH ou debug pod) e verifique a realidade:
# Verifique a saturação dos discos físicos
# Olhe a coluna %util e await
iostat -x -d 1
# Verifique se há processos de rebuild de software RAID
cat /proc/mdstat
Se o %util estiver próximo de 100% e o await for alto, adicionar mais CPU ou RAM ao Pod não resolverá nada. Você atingiu o limite físico da sua topologia de storage.
Veredito Arquitetural: Quando usar Local RAID ou SAN
A resposta "depende" é preguiçosa se não for qualificada. Aqui está o guia de decisão baseado em trade-offs de consistência e disponibilidade.
Use RAID Local (Local PVs) quando:
A aplicação resolve a replicação: Bancos de dados distribuídos como Cassandra, Elasticsearch, Kafka ou MongoDB (em Replica Sets). Eles foram feitos para perder nós inteiros. O RAID 0 (performance) ou RAID 10 (segurança) local entrega a velocidade bruta que eles precisam. O K8s gerencia a topologia lógica, o app gerencia a cópia dos dados.
Cache e Logs: Dados efêmeros que precisam de alta velocidade de escrita mas cuja perda não é catastrófica.
Use RAID em Rede (CSI/SAN/Ceph) quando:
Aplicações Legacy/Monolíticas: Sistemas que não sabem se replicar e exigem que o disco "o siga" se o nó mudar (ex: um MySQL single-instance antigo, CMS como WordPress).
Densidade: Você precisa de volumes maiores do que o disco físico que cabe no servidor de computação.
O segredo não é escolher o "melhor" RAID, mas alinhar a camada de persistência física com a inteligência da sua aplicação. Não pague a "taxa de rede" (latência de SAN) para um software que já sabe replicar dados nativamente (Kafka). E não confie em disco local para um software que morre se o servidor pegar fogo.
Referências & Leitura Complementar
Container Storage Interface (CSI) Spec: Entenda como os drivers expõem storage ao orquestrador.
Google SRE Book - Cap. 26 (Data Integrity): Discussão profunda sobre durabilidade vs. disponibilidade.
RFC 3720 (iSCSI): Para entender os fundamentos de transporte de blocos sobre IP em cenários de SAN.
Manpage
mdadm(8): A bíblia do Software RAID em Linux.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.