Lacp E Bonding O Que Ajuda E O Que Nao Ajuda

Antes de falarmos de *hashing* XOR ou frames Ethernet, precisamos ajustar o modelo mental. A intuição humana diz que se ligarmos dois canos de água em um tanque...
Lacp E Bonding O Que Ajuda E O Que Nao Ajuda
A Rodovia e a Ferrari: Visualizando o Fluxo
Antes de falarmos de hashing XOR ou frames Ethernet, precisamos ajustar o modelo mental. A intuição humana diz que se ligarmos dois canos de água em um tanque, o tanque esvazia duas vezes mais rápido. Isso funciona para fluidos. Dados em rede não são fluidos; são carros em uma rodovia.
Imagine que você tem uma rodovia de uma faixa (1Gbps). O trânsito está engarrafado. Você decide fazer um upgrade e constrói mais três faixas. Agora você tem uma rodovia de quatro faixas (4Gbps LACP Bond).
Aqui está o problema: Uma transferência de arquivo (uma sessão TCP) não é uma frota de carros. É um único veículo, digamos, uma Ferrari transportando um HD gigante.
Não importa quantas faixas a rodovia tenha, a Ferrari só pode dirigir em uma faixa de cada vez. Ela não pode dividir o chassi em quatro pedaços e dirigir em todas as faixas simultaneamente para chegar mais rápido. A velocidade máxima da Ferrari ainda é limitada pelo limite de velocidade daquela única faixa (a interface física).
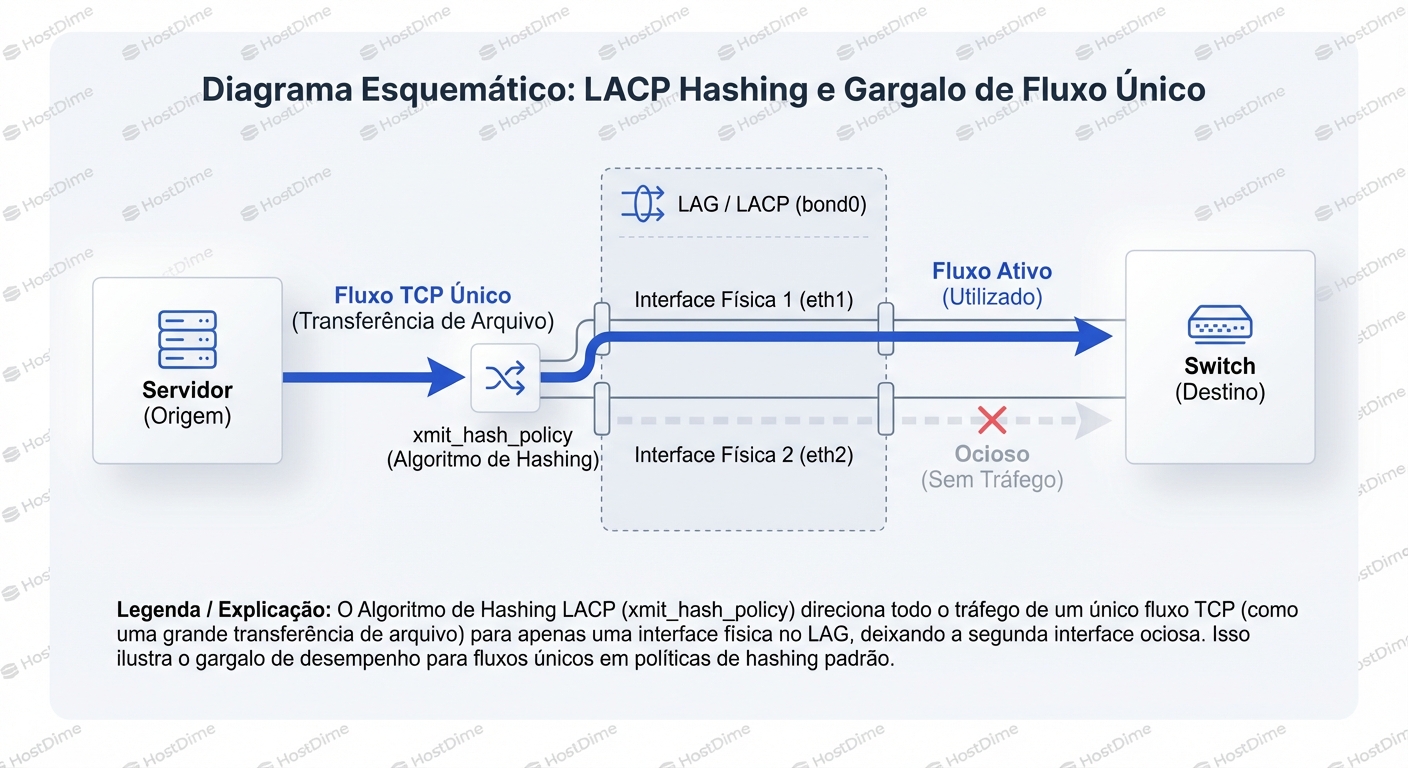
Se você tiver quatro Ferraris (quatro clientes diferentes ou quatro fluxos de dados distintos), aí sim o LACP brilha. Cada Ferrari pega uma faixa diferente. Mas se você tiver apenas uma Ferrari gigante (um backup monolítico), três faixas ficarão vazias.
O Mecanismo: Por que o Switch "Escolhe" um Cabo?
Para entender por que isso acontece, precisamos olhar para o pesadelo de qualquer protocolo de rede: Out-of-Order Packets (Pacotes Fora de Ordem).
O TCP foi desenhado para ser robusto, mas ele odeia receber o pacote #5 antes do pacote #2. Se isso acontece, a pilha TCP do receptor assume perda de pacote, dispara retransmissões, reduz a janela de congestionamento e a performance despenca. O processador do receptor gasta ciclos preciosos tentando reordenar os pacotes antes de passar os dados para a aplicação.
Para evitar o caos da reordenação, os engenheiros de rede criaram uma regra de ouro para Agregação de Links: Uma conversa específica deve sempre trafegar pelo mesmo fio físico.
A Algoritmo de Hashing (O Juiz de Tráfego)
Quando um pacote entra no driver de bonding (no Linux) ou na porta do switch, uma decisão precisa ser tomada: "Para qual das 4 interfaces físicas eu envio este frame?"
O sistema não olha para a carga da interface ("Oh, a eth0 está cheia, vou usar a eth1"). Isso seria caro computacionalmente e causaria reordenação. Em vez disso, ele usa um cálculo matemático determinístico (Hash).
A configuração padrão na maioria dos bonds LACP (mode 4) usa a política layer2 ou layer2+3.
A fórmula simplificada se parece com isto:
Interface_ID = (MAC_Origem XOR MAC_Destino) % Numero_de_Interfaces
Vamos simular o cenário do ticket inicial:
- Servidor de Backup (Origem): MAC
AA:AA:AA:AA:AA:AA - Storage (Destino): MAC
BB:BB:BB:BB:BB:BB - Interfaces Físicas: 4
Sempre que o servidor de backup enviar um pacote para o storage, a matemática MAC_Origem XOR MAC_Destino resultará sempre no mesmo número.
Se o resultado do cálculo aponta para a "Interface 1", todos os pacotes dessa sessão TCP passarão pela Interface 1. As Interfaces 2, 3 e 4 ficarão com 0% de utilização para esse fluxo. É determinístico. É proposital. E é o gargalo.
Diagnosticando o Desequilíbrio
Não confie na minha palavra. Vamos para o terminal. O erro mais comum é rodar um ifconfig ou ip -s link, ver o contador de bytes da interface bond0 subindo e achar que está tudo bem. O bond0 é uma abstração lógica; ele esconde a verdade física.
Para ver a realidade, precisamos interrogar o driver de bonding e as interfaces escravas (slaves) individualmente.
1. O Estado do Bond
No Linux, o arquivo /proc/net/bonding/bond0 (ou o nome do seu bond) é sua fonte primária de verdade.
cat /proc/net/bonding/bond0
Procure por:
- Bonding Mode: IEEE 802.3ad Dynamic link aggregation (Isso confirma LACP).
- Transmit Hash Policy: O padrão geralmente é
layer2(apenas MAC). Isso é ruim para tráfego roteado (através de gateways), pois o MAC de destino será sempre o do gateway, reduzindo a entropia do hash. - Slave Interfaces: Verifique se todas estão "up" e com a velocidade correta.
2. O Teste da "Fumaça" (Observabilidade em Tempo Real)
A melhor maneira de visualizar o problema da "Ferrari na faixa única" é monitorar o tráfego por interface física durante uma transferência pesada.
Ferramentas como sar, iftop ou até mesmo um script com cat /proc/net/dev são essenciais. Eu prefiro o sar pela clareza histórica e instantânea.
Execute isto enquanto o backup lento está rodando:
sar -n DEV 1
O que você vai ver (O Cenário Triste):
| IFACE | rxpck/s | txpck/s | rxkB/s | txkB/s | %ifutil | Análise |
|---|---|---|---|---|---|---|
| bond0 | 80000 | 95000 | 110000 | 980000 | 25.00 | Parece rápido, mas é a soma. |
| eth0 | 100 | 50 | 10 | 5 | 0.01 | Ociosa. |
| eth1 | 80000 | 95000 | 110000 | 980000 | 99.00 | Saturada! O Gargalo. |
| eth2 | 50 | 20 | 2 | 1 | 0.00 | Ociosa. |
| eth3 | 20 | 10 | 1 | 1 | 0.00 | Ociosa. |
Veja a coluna txkB/s e %ifutil. A eth1 está gritando por socorro, enquanto eth0, eth2 e eth3 estão dormindo. O sistema operacional está fazendo exatamente o que foi programado para fazer: manter a ordem dos pacotes colocando todo o fluxo em um único fio.
Tentando Enganar o Sistema: Hash Policies
"Ok", você pensa, "e se eu mudar o algoritmo de hash?"
Você pode alterar a xmit_hash_policy para layer3+4. Isso significa que o cálculo do hash levará em conta:
- IP de Origem e Destino (Layer 3)
- Porta TCP/UDP de Origem e Destino (Layer 4)
Isso ajuda? Depende.
Se você tiver múltiplos clientes acessando o servidor, ajuda muito. Clientes diferentes têm IPs diferentes, o que gera hashes diferentes, distribuindo-os melhor entre os cabos.
Mas voltemos ao nosso problema do backup: Um servidor, um storage, um arquivo gigante.
- IP Origem: Fixo.
- IP Destino: Fixo.
- Porta Origem: Fixa (para aquela conexão).
- Porta Destino: Fixa (ex: 2049 para NFS, 445 para SMB).
O resultado do hash Layer3+4 ainda será constante para essa sessão única. Você ainda estará preso em um cabo. Mudar a política de hash aumenta a entropia (a chance de fluxos diferentes usarem cabos diferentes), mas não divide um fluxo único.
A Armadilha do Round-Robin (Balance-RR)
Algum administrador criativo sempre sugere: "Vamos usar o mode 0 (balance-rr)! Ele envia pacotes sequencialmente em cada interface: pacote 1 na eth0, pacote 2 na eth1..."
Sim, o Round-Robin usa todos os cabos. Você verá 40Gbps de tráfego saindo. Mas o que chega do outro lado é uma salada de frutas. Como os caminhos físicos podem ter latências ligeiramente diferentes, os pacotes chegam fora de ordem.
O resultado? A CPU do receptor dispara para 100% tentando remontar o quebra-cabeça TCP (reordenamento), e a performance efetiva da aplicação muitas vezes é pior do que com um único cabo, devido ao excesso de retransmissões TCP. O Round-Robin só é seguro em cenários muito específicos (geralmente conexão direta back-to-back sem switches no meio, ou com switches configurados de forma muito específica para EtherChannel estático, o que perde a inteligência do LACP).
A Solução Real: Escalabilidade Vertical vs. Horizontal
Se o LACP é sobre escalabilidade horizontal (mais clientes = mais uso), como resolvemos o problema de velocidade de um único cliente (escalabilidade vertical)?
Precisamos sair da Camada 2 (Link) e da Camada 3/4 (Transporte) e subir para a Camada de Aplicação ou Sessão. Precisamos de tecnologias que sejam "Multichannel-aware".
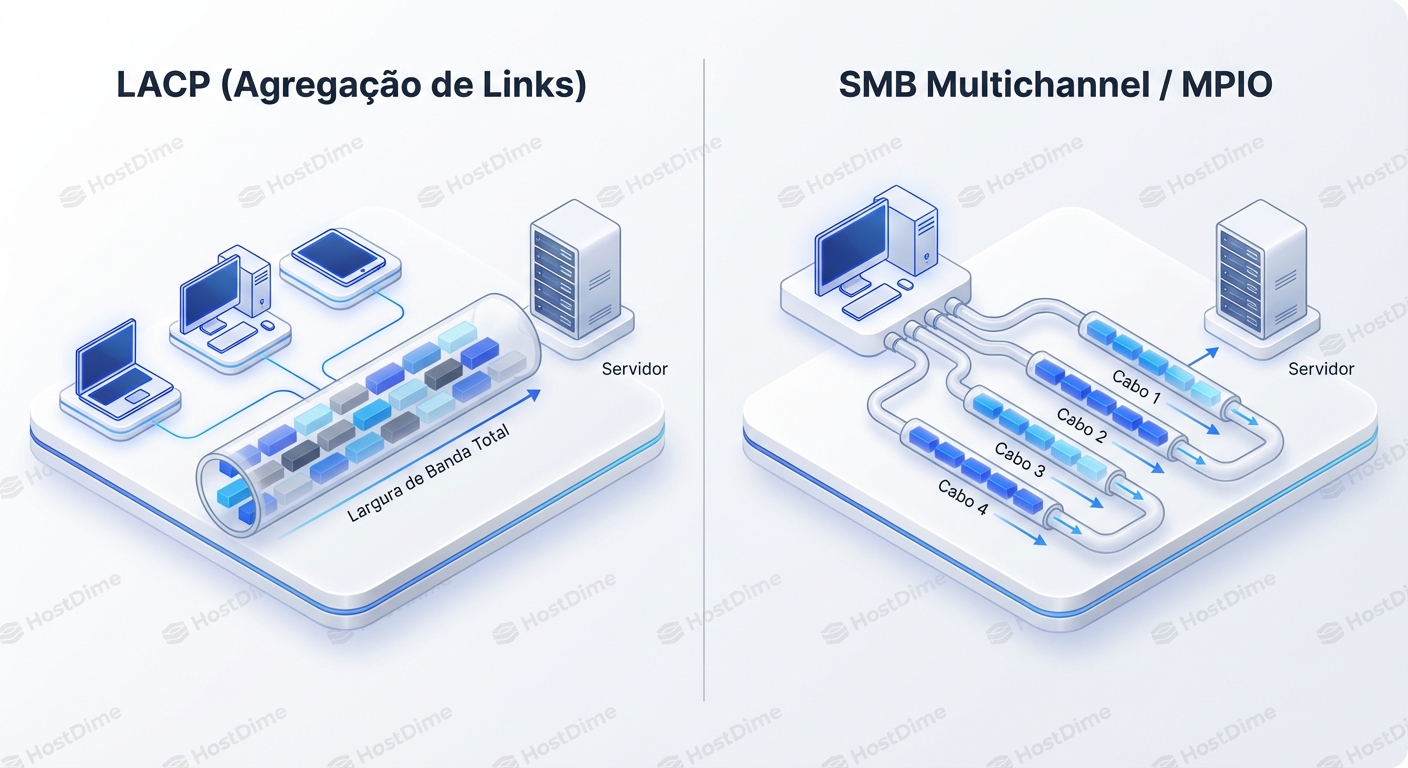
1. SMB Multichannel (O Santo Graal do Windows/Samba)
O protocolo SMB 3.0+ (usado em compartilhamentos Windows e Azure Files) é inteligente. Quando um cliente se conecta a um servidor, o SMB Multichannel escaneia as interfaces de rede disponíveis em ambos os lados. Se ele vê que você tem dois IPs e o servidor tem dois IPs, ele cria múltiplas sessões TCP por baixo dos panos para transferir o mesmo arquivo.
Como são múltiplas sessões TCP (com portas de origem diferentes), o algoritmo de hash do LACP (se houver) ou o próprio roteamento natural vê fluxos distintos e os coloca em cabos diferentes.
- Resultado: Você copia um arquivo no Windows Explorer e vê o gráfico de rede bater 20Gbps ou 40Gbps.
- Requisito: Geralmente não requer LACP. Requer múltiplas interfaces com IPs distintos (ou interfaces com suporte a RSS/RDMA).
2. iSCSI Multipathing (MPIO)
Para armazenamento em bloco, nunca usamos LACP para agregação de banda. Usamos MPIO. O iniciador iSCSI abre múltiplas conexões TCP para o alvo (Target). O driver MPIO no sistema operacional gerencia o envio de blocos de disco via Round-Robin (neste nível é seguro, pois é gerenciado pela aplicação iSCSI, não pelo switch).
- Regra de Ouro: Em iSCSI, configure duas interfaces de rede em sub-redes diferentes (ex: 192.168.10.x e 192.168.20.x) e deixe o MPIO fazer o trabalho. Esqueça o LACP.
3. NFS com nconnect (Linux Moderno)
O NFS historicamente sofria muito com o problema do single-stream. No entanto, kernels Linux mais recentes (5.3+) introduziram a opção de montagem nconnect.
mount -t nfs -o nconnect=4 server:/share /mnt/local
Isso instrui o cliente NFS a abrir 4 conexões TCP para o mesmo mount point. Agora, com 4 fluxos distintos, o hash LACP layer3+4 finalmente tem material para trabalhar e pode distribuir esses fluxos entre as interfaces físicas.
Tabela de Expectativa vs. Realidade
Para consolidar, veja como diferentes cargas de trabalho se comportam com um Bond LACP de 2x 10Gbps (Total 20Gbps teóricos).
| Cenário | Comportamento do Fluxo | Throughput Máximo Real | Por quê? |
|---|---|---|---|
| Cópia de Arquivo Único (SCP/HTTP) | 1 Sessão TCP | 10 Gbps | Hash vincula a sessão a 1 cabo. |
| Backup (Veeam/Rsync) | Geralmente 1 ou poucas sessões | 10 Gbps | Falta de paralelismo no transporte. |
| Virtualização (100 VMs) | Centenas de sessões (IPs/MACs variados) | ~20 Gbps | Alta entropia. O hash distribui bem. |
| Banco de Dados (Muitos Clientes) | Milhares de conexões curtas | ~20 Gbps | Alta entropia. Excelente uso do LACP. |
| iSCSI sobre LACP | 1 Sessão TCP por Target (padrão) | 10 Gbps | Design ruim. Use MPIO sem LACP. |
| SMB 3.0 Multichannel | Múltiplas sessões TCP ocultas | ~20 Gbps | A aplicação quebra o fluxo em pedaços. |
Diagnosticando Hash Collisions (O Fenômeno do "Azar")
Existe um cenário ainda mais frustrante: Você tem 100 clientes, mas a performance ainda é ruim. Ao rodar o sar, você vê:
eth0: 90% de usoeth1: 10% de uso
Isso é uma colisão de hash. O algoritmo matemático, por puro azar estatístico, está jogando a maioria dos seus clientes "pesados" para o mesmo resultado (mesma interface).
Como resolver:
- Mude a política de hash (
layer2paralayer3+4). Isso muda a matemática e redistribui as cartas. - Aumente o número de links (passar de 2 para 3 links altera o divisor da operação de módulo, mudando completamente a distribuição).
O Veredito: LACP é Seguro, não Rápido
Se você tirar apenas uma lição deste artigo, que seja esta: LACP (Bonding) é primariamente uma tecnologia de Redundância e Capacidade Agregada, não de Aceleração de Sessão Única.
Ele garante que se um cabo for cortado, o servidor continua online. Ele garante que se 500 usuários se conectarem, todos terão um bom serviço. Mas ele não fará o backup do seu banco de dados de 10TB terminar na metade do tempo, a menos que você mude a forma como a aplicação fala com a rede.
Da próxima vez que configurar um bond, não pergunte "qual a velocidade total?". Pergunte "quantos fluxos eu tenho?". Se a resposta for "um", economize seu tempo e foque em melhorar a aplicação (SMB Multichannel, NFS nconnect) ou aceite o limite da física de um único cabo.
Para aprofundamento:
- Verifique a documentação do seu switch sobre "Load Balance Hash Algorithm". Alguns switches Enterprise permitem incluir a porta TCP no hash mesmo em tráfego L2, o que pode salvar o dia em ambientes virtualizados.
- Pesquise sobre RSS (Receive Side Scaling). Mesmo que você consiga fazer o tráfego chegar por dois cabos, se todos os pacotes forem processados pela CPU 0 (Core zero), você terá um gargalo de processador antes do gargalo de rede. O RSS distribui o processamento de interrupções de rede entre múltiplos núcleos de CPU.
A rede é honesta. O sar não mente. Pare de brigar com a matemática e comece a arquitetar múltiplos fluxos.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.