Latencia De Switch Por Que Switch E Tudo Igual E Falso

A maior armadilha mental que temos é visualizar um switch como um encanamento passivo. Imaginamos que os bits entram por uma porta e fluem eletricamente para ou...
Latencia De Switch Por Que Switch E Tudo Igual E Falso
O A Lógica por Trás: O Switch não é um cano, é uma Alfândega
A maior armadilha mental que temos é visualizar um switch como um encanamento passivo. Imaginamos que os bits entram por uma porta e fluem eletricamente para outra, como água.
Isso está fundamentalmente errado.
Um switch é um computador especializado. Ele tem CPU (para o control plane - SSH, BGP, STP) e, mais importante, ele tem ASICs (Application-Specific Integrated Circuits) para o data plane.
Pense no switch não como um cano, mas como uma Alfândega Internacional.
- Ingress (Chegada): O caminhão (pacote) chega. Ele precisa ser parado.
- Parsing (Triagem): Alguém precisa ler o manifesto (Headers: MAC, IP, VLAN).
- Lookup (Decisão): O oficial consulta um livro gigante de regras (TCAM/Tabelas de MAC) para saber o destino.
- Queuing (Fila de Espera): Se o portão de saída estiver ocupado, o caminhão vai para o pátio (Buffer).
- Egress (Saída): O caminhão é liberado para a estrada.
A latência do switch é o tempo que leva desde a roda dianteira do caminhão tocar a entrada até a roda traseira sair pela saída. E aqui é onde a arquitetura muda tudo.
Arquitetura de Encaminhamento: A Escolha Invisível
Quando você compra um switch, o vendedor fala sobre "Throughput" (largura de banda total). Ele raramente fala sobre "Forwarding Latency" (tempo de processamento). Existem dois modos principais de operação que definem a "personalidade" do seu switch.
1. Store-and-Forward (O Burocrata Cauteloso)
A maioria dos switches de acesso "baratos" e switches legados operam neste modo. O switch espera o pacote inteiro chegar antes de tomar qualquer decisão. Ele lê o preâmbulo, o cabeçalho, o payload e, crucialmente, o FCS (Frame Check Sequence) no final.
- Vantagem: Ele descarta pacotes corrompidos antes de retransmiti-los. Não propaga lixo na rede.
- O Custo Oculto: A latência depende do tamanho do pacote (MTU).
Se você tem um pacote de 1500 bytes em um link de 1Gbps:
1500 bytes * 8 bits = 12.000 bits
12.000 / 1.000.000.000 = 12 microssegundos
Isso é apenas o tempo para o pacote entrar no buffer (Serialization Delay). O switch só começa a trabalhar depois desses 12µs. Se você estiver usando Jumbo Frames (9000 bytes), a latência aumenta linearmente. Em aplicações sensíveis (HFT, clusters de computação em tempo real, replicação síncrona de banco de dados), isso é uma eternidade.
2. Cut-Through (O Velocista Otimista)
Switches de Data Center modernos (Cisco Nexus, Arista, Juniper QFX) geralmente usam Cut-Through. O switch lê apenas os primeiros bytes (Destination MAC Address) e toma a decisão de encaminhamento imediatamente. Ele começa a transmitir a "cabeça" do pacote na porta de saída enquanto o "rabo" do pacote ainda está entrando na porta de entrada.
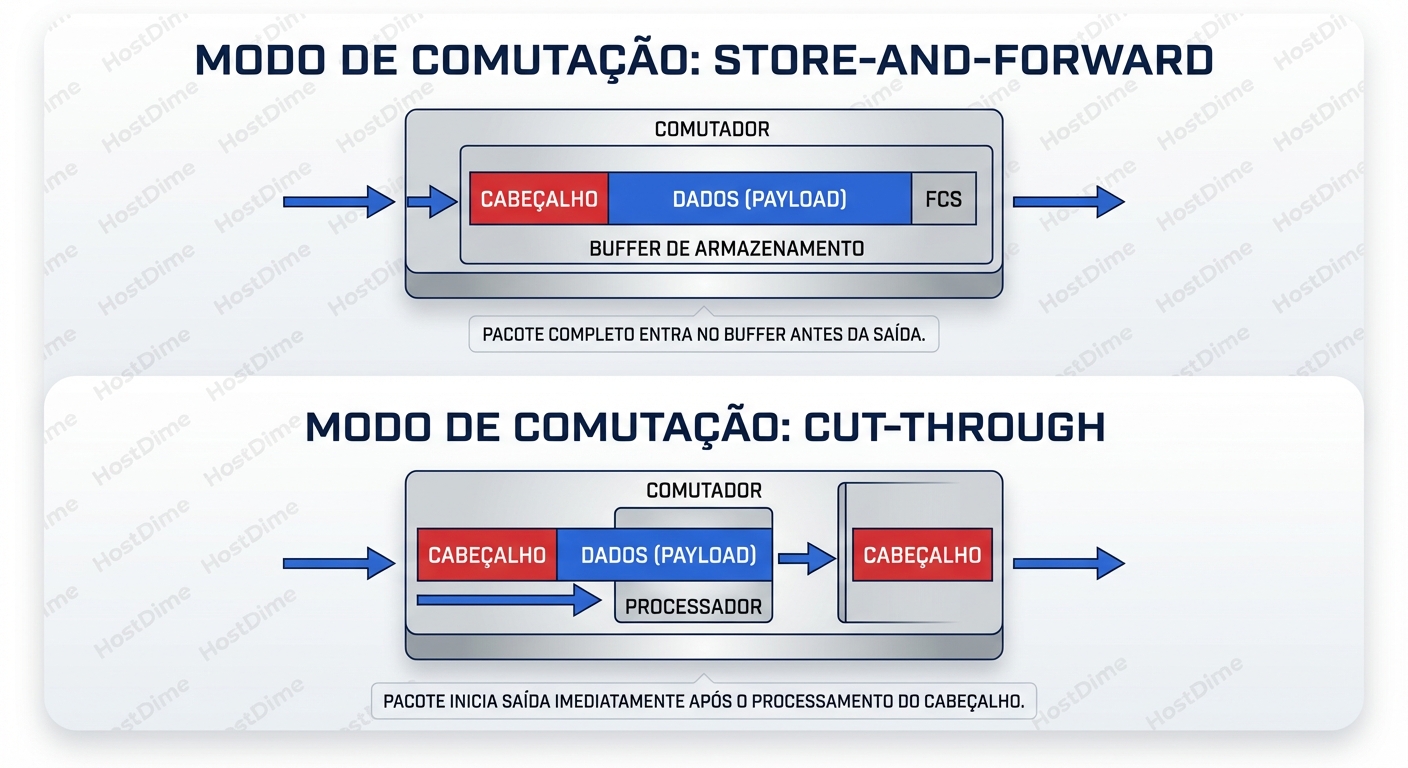
O ganho aqui é brutal. A latência torna-se quase independente do tamanho do pacote. Um switch Cut-Through moderno pode ter uma latência porta-a-porta consistente de 200 a 400 nanossegundos (0.4µs), contra os 12µs+ do Store-and-Forward.
A Pegadinha do Cut-Through: Se o pacote estiver corrompido (CRC erro no final), o switch já enviou a maior parte dele. O switch receptor final terá que descartá-lo. Isso propaga erros, mas em data centers modernos com cabeamento de fibra óptica de alta qualidade, erros de bit são raros, tornando o Cut-Through a escolha padrão para alta performance.
Nota de Diagnóstico: Se você vir contadores de "Runts" ou "CRC Errors" incrementando em interfaces de servidores, mas o switch intermediário não mostra erros na entrada, ele pode ser um switch Cut-Through propagando o erro de um switch anterior.
Microbursts: O Assassino Silencioso de Aplicações
Voltamos ao cenário inicial: o link está em 15% de utilização, mas a aplicação está lenta. Por quê?
Porque você está olhando para a média de 5 minutos, ou talvez de 1 segundo. Redes de computadores são "bursty" (rajadas) por natureza. O tráfego TCP não é um fluxo de água constante; é uma metralhadora.
Imagine um link de 10Gbps. Se durante 900 milissegundos o tráfego é zero, e durante 100 milissegundos o tráfego é 10Gbps, a média do segundo é 1Gbps (10% de utilização). Seu gráfico do Zabbix diz: "Tudo ótimo, 10% de carga".
Mas o que acontece dentro desses 100ms? Se você tem um padrão "Incast" (Muitos-para-Um) — comum em Hadoop, MapReduce, ou escritas de quórum em bancos de dados — onde 40 servidores enviam uma resposta para 1 servidor ao mesmo tempo, você tem um problema de física.
40 portas x 1Gbps entrando = 40Gbps de demanda. 1 porta x 1Gbps saindo = 1Gbps de capacidade.
Durante aquele milissegundo, você precisa armazenar 39Gb de dados em algum lugar. É aqui que entra o Buffer.
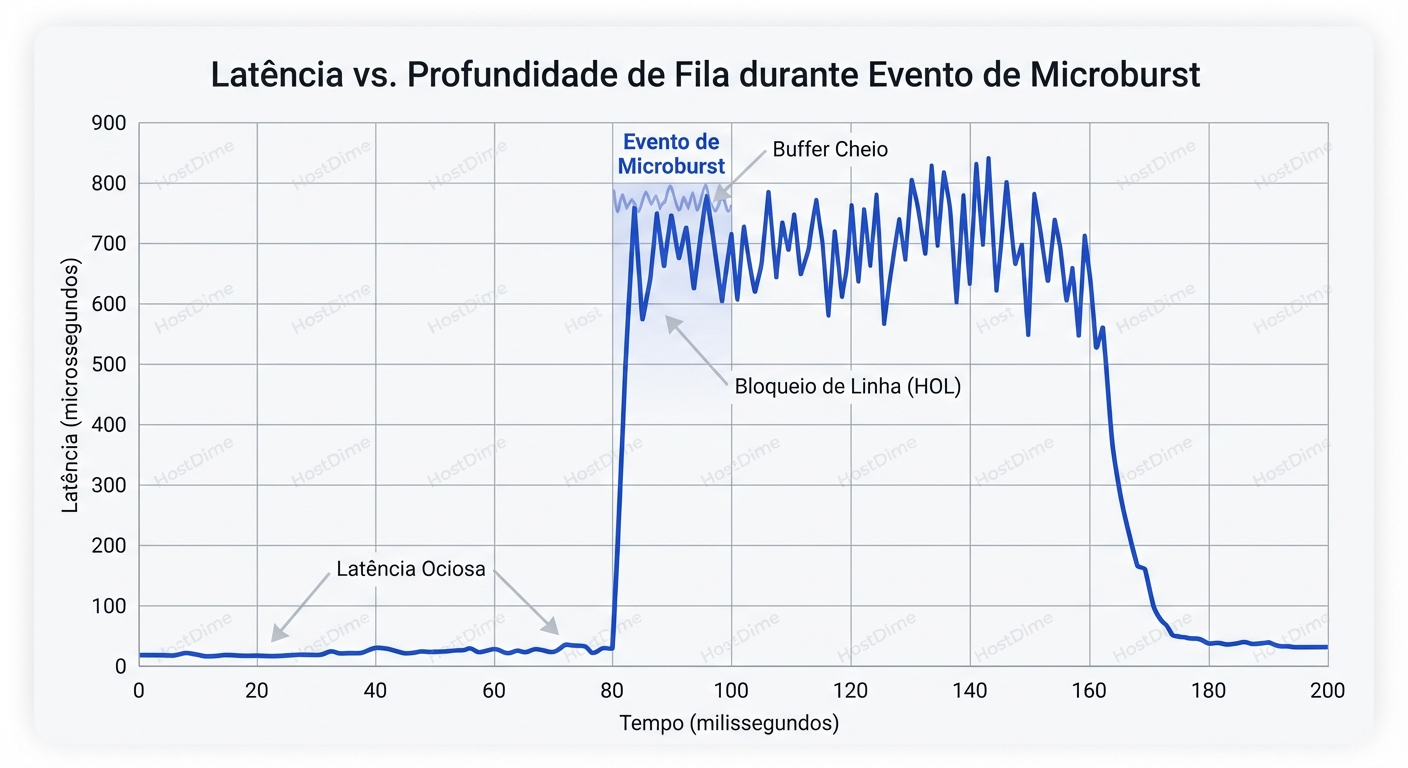
Se o buffer do switch encher, acontece o Tail Drop. O switch simplesmente apaga os pacotes novos. O TCP percebe a perda, espera um timeout (RTO), e retransmite. O que era uma transação de microssegundos vira uma espera de milissegundos ou segundos. Isso é o "Jitter" extremo que mata a performance.
O gráfico acima ilustra o pesadelo de todo SRE: a latência é estável até que o buffer enche. Nesse ponto, a latência não sobe linearmente; ela vira uma parede vertical.
A Guerra dos Buffers: Deep vs. Shallow
Aqui é onde a escolha do hardware (ASIC) define o sucesso ou fracasso da sua arquitetura. Nem todo switch de 10Gbps é igual.
Shallow Buffers (Buffers Rasos)
Exemplos: A maioria dos switches baseados em Broadcom Trident/Tomahawk (Muitos Cisco Nexus 3k/9k, Dell Force10, Arista 7050).
- Característica: Focados em latência ultra-baixa (Cut-Through).
- Memória: Geralmente pequena (ex: 12MB a 32MB compartilhados para todas as portas).
- Cenário Ideal: HFT (High Frequency Trading), HPC (High Performance Computing), tráfego UDP constante.
- Onde Falha: Redes de armazenamento (iSCSI, Ceph), Big Data, situações de muito Incast. Se houver um microburst, o buffer enche em microssegundos e pacotes são dropados.
Deep Buffers (Buffers Profundos)
Exemplos: Switches baseados em Broadcom Jericho ou ASICs customizados (Arista 7280R, Juniper QFX10k, Cisco Nexus 9k-R series).
- Característica: Focados em absorver rajadas.
- Memória: Gigantesca (ex: 4GB a 8GB de buffer).
- Cenário Ideal: Roteamento de borda, interconexão de Data Center (DCI), Storage, Redes de Mídia (Streaming de vídeo 4K sem compressão).
- Onde Falha: Latência base ligeiramente maior (devido à arquitetura de memória externa ao chip).
A Tabela da Verdade:
| Característica | Switch "Commodity" (Shallow Buffer) | Switch "Deep Buffer" | Por que importa? |
|---|---|---|---|
| Tamanho do Buffer | ~16 MB | ~4 GB | 16MB a 10Gbps enche em ~13ms. 4GB aguenta segundos. |
| Latência Base | ~500ns | ~3µs - 5µs | Shallow é melhor para aplicações "chatty" (muitas mensagens pequenas). |
| Arquitetura | On-Chip Memory | Off-Chip Memory (GDDR) | Memória externa adiciona latência, mas salva pacotes. |
| Custo | $ | $$$ | Você paga pela RAM rápida e pelo ASIC complexo. |
Diagnosticando o Invisível: Comandos e Ferramentas
Como provar que o switch é o problema se o SNMP mostra médias inúteis? Você precisa descer o nível da observabilidade.
1. No Linux (O lado da vítima)
Antes de culpar a rede, veja se o servidor está vendo os sintomas de microbursts.
Verificando Retransmissões TCP: Não olhe apenas para erros de interface. Olhe para a pilha TCP.
watch -n 1 "netstat -s | grep -i retran"
# Ou usando nstat (parte do iproute2)
nstat -az | grep TcpRetransSegs
Se esse número está subindo enquanto a utilização do link é baixa, você tem congestionamento (perda de pacotes) em algum lugar no caminho.
Micro-resolução com TC (Traffic Control):
O tcpdump pode ser pesado, mas você pode usar o eBPF ou ferramentas como dropwatch para ver onde o kernel está descartando pacotes, mas para ver a latência de rede externa, ping não serve. Use hping3 para testar sob carga ou mtr com intervalos muito curtos.
# MTR com envio rápido (cuidado, gera carga)
mtr -r -c 100 -i 0.01 <IP_DESTINO>
Se o desvio padrão (stdev) for alto, você tem Jitter, provavelmente causado por filas variáveis nos switches.
2. No Switch (A caixa preta)
Aqui os comandos variam por vendor, mas a lógica é a mesma: procure por "Discards" ou "Drops" que não são erros de CRC.
Cisco Nexus (NX-OS):
# Mostra descartes por fila de hardware.
# "OutDiscards" geralmente significa buffer cheio.
show interface ethernet 1/1 counters errors
# Mergulho profundo no ASIC (Broadcom)
# Isso mostra se o buffer compartilhado está sendo atingido.
show hardware internal broadcom counters | grep -i drop
Arista (EOS): A Arista tem uma ferramenta fantástica chamada LANZ (Latency Analyzer).
# Mostra eventos onde o buffer excedeu um limiar, com timestamps.
show lanz events
Se você tem LANZ, use-o. Ele diz: "Às 14:02:03, a porta Eth15 descartou 500 pacotes devido a congestionamento". É a "arma fumegante" que você precisa para o ticket.
Linux-based Switches (Cumulus/SONiC):
# Acesso direto aos contadores do ethtool
ethtool -S swp1 | grep -i drop
Procure por rx_buffer_full, queue_drop, ou wred_drop.
O Impacto do FEC (Forward Error Correction) em 25G/100G
Aqui está uma armadilha moderna. Você faz o upgrade de 10Gbps para 25Gbps esperando que a latência diminua (o "tubo" é mais largo, a serialização é mais rápida). Mas a latência aumenta. Por quê?
Em velocidades de 25Gbps e superiores (usando modulação NRZ ou PAM4), o sinal elétrico é tão frágil que erros de bits são inevitáveis. Para corrigir isso, os padrões IEEE introduziram o FEC.
O FEC funciona adicionando bits redundantes e usando matemática complexa (Reed-Solomon) para reconstruir dados corrompidos no receptor. O problema: Para fazer a matemática, o switch precisa ler um bloco inteiro de dados (Block Code).
- Sem FEC: Latência de ~300ns.
- Com FEC (RS-FEC 544,514): Latência salta para ~250ns (processamento) + ~100ns (serialização extra) + espera do bloco. Pode adicionar de 100ns a 2500ns dependendo do tipo de FEC.
Em links curtos (Twinax/DAC dentro do rack), você muitas vezes pode desligar o FEC ou usar um FEC mais leve (Base-R) para recuperar a latência perdida.
# Exemplo em Arista para desativar FEC em link curto e ganhar latência
interface Ethernet1
speed 25g
error-correction encoding reed-solomon # Padrão (Lento, Seguro)
! vs
error-correction encoding none # Rápido (Arriscado se o cabo for ruim)
Aviso: Só desligue o FEC se seus contadores de CRC/FCS permanecerem em zero.
Head-of-Line Blocking (HOL) e Virtual Output Queues (VOQ)
Imagine que você tem um switch com 3 portas.
- Porta 1 (Entrada): Tráfego misturado.
- Porta 2 (Saída): Livre.
- Porta 3 (Saída): Congestionada.
Se o switch usa uma fila simples na entrada (Input Queuing), um pacote destinado à Porta 3 (congestionada) fica na frente da fila. Atrás dele, há um pacote para a Porta 2 (livre). O pacote da Porta 2 não pode sair porque está preso atrás do pacote da Porta 3. Isso é Head-of-Line Blocking.
Switches "Enterprise" baratos sofrem disso. Switches de Data Center decentes usam VOQ (Virtual Output Queues). No VOQ, a porta de entrada mantém filas virtuais separadas para cada porta de saída possível antes de enviar os dados pelo backplane do switch. Isso garante que o congestionamento de um servidor lento (Porta 3) não afete a latência de um servidor rápido (Porta 2).
Ao comprar switches para storage ou cluster, pergunte ao seu vendor: "Este switch tem arquitetura VOQ?". Se eles gaguejarem, corra.
O Veredito: Consistência > Velocidade
A lição final para o Sysadmin/SRE não é "compre o switch mais rápido". É "compre o switch mais previsível".
Uma latência média de 50µs com picos de 50ms é muito pior para uma aplicação distribuída do que uma latência constante de 100µs. Jitter causa timeouts. Timeouts causam retransmissões. Retransmissões causam mais carga, criando um ciclo de feedback positivo que derruba o cluster.
Resumo da Sobrevivência:
- Desconfie das Médias: Se o link está a 10%, mas há retransmissões TCP, você tem Microbursts.
- Conheça seu ASIC: Saiba se você tem Buffers Rasos (Cut-Through rápido) ou Profundos (Absorção de rajadas). Use a ferramenta certa para o trabalho.
- Use Métricas de Fila: Configure seu monitoramento para ler
discardcounters, não apenasbytes. - Cuidado com o FEC: Em 25G+, verifique se a correção de erro não está comendo seu orçamento de latência.
Da próxima vez que o desenvolvedor culpar a rede, não mostre apenas o gráfico de utilização de banda. Mostre o gráfico de descartes de fila e a profundidade do buffer. É aí que a verdade se esconde.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.