Latência p99 em Storage Distribuído: Por que seu Banco de Dados trava (e o IOPS não importa)

Seu ERP está lento mas o monitoramento diz que está tudo bem? Descubra como a latência p99 (tail latency) em storage distribuído destrói a performance de bancos de dados transacionais e como medir o que realmente importa.
Você já viveu este cenário: o dashboard do Zabbix ou Prometheus está todo verde. O uso de CPU está baixo, a RAM tem folga e o throughput de disco está longe do limite teórico da sua SAN ou storage na nuvem. Mas o telefone não para de tocar. O ERP está travando, o checkout do e-commerce dá timeout e os desenvolvedores juram que o código não mudou.
O fornecedor do storage jura que entrega "100.000 IOPS". E ele provavelmente entrega. O problema é que o seu banco de dados não se importa com quantos IOPS o storage aguenta no total; ele se importa com quanto tempo uma única operação crítica de escrita leva para retornar.
Bem-vindo ao mundo da latência de cauda (tail latency). Aqui, a média é uma mentira confortável e o p99 é onde sua infraestrutura vai morrer. Vamos parar de olhar para métricas de vaidade e entender a física por trás do travamento.
O que é Latência p99 e a Cauda Longa?
Latência p99 (percentil 99) é a métrica que define o limiar de velocidade para 99% das suas operações de I/O, revelando que o 1% restante é mais lento que esse valor. Enquanto a média dilui picos de lentidão em um mar de operações rápidas, o p99 expõe a "cauda longa" — aquelas poucas operações críticas que demoram 500ms ou mais — que são as verdadeiras responsáveis por travamentos em cascata, bloqueios de transações (locks) e timeouts em aplicações sensíveis.
Por que a Latência Média do Storage esconde o problema
Se você colocar a cabeça no freezer e os pés no forno, na média, sua temperatura corporal está ótima. Na prática, você está morto. O mesmo vale para o I/O de disco.
Ferramentas clássicas de monitoramento tendem a agregar dados em intervalos de 1 ou 5 minutos e apresentar a média. Se o seu storage processou 1.000 requisições em um segundo, sendo 999 delas em 1ms e apenas uma delas em 1 segundo (1000ms), a média será de aproximadamente 2ms.
O gerente olha e diz: "2ms de latência é excelente!". Mas para o usuário que caiu naquela requisição de 1 segundo, o sistema travou.
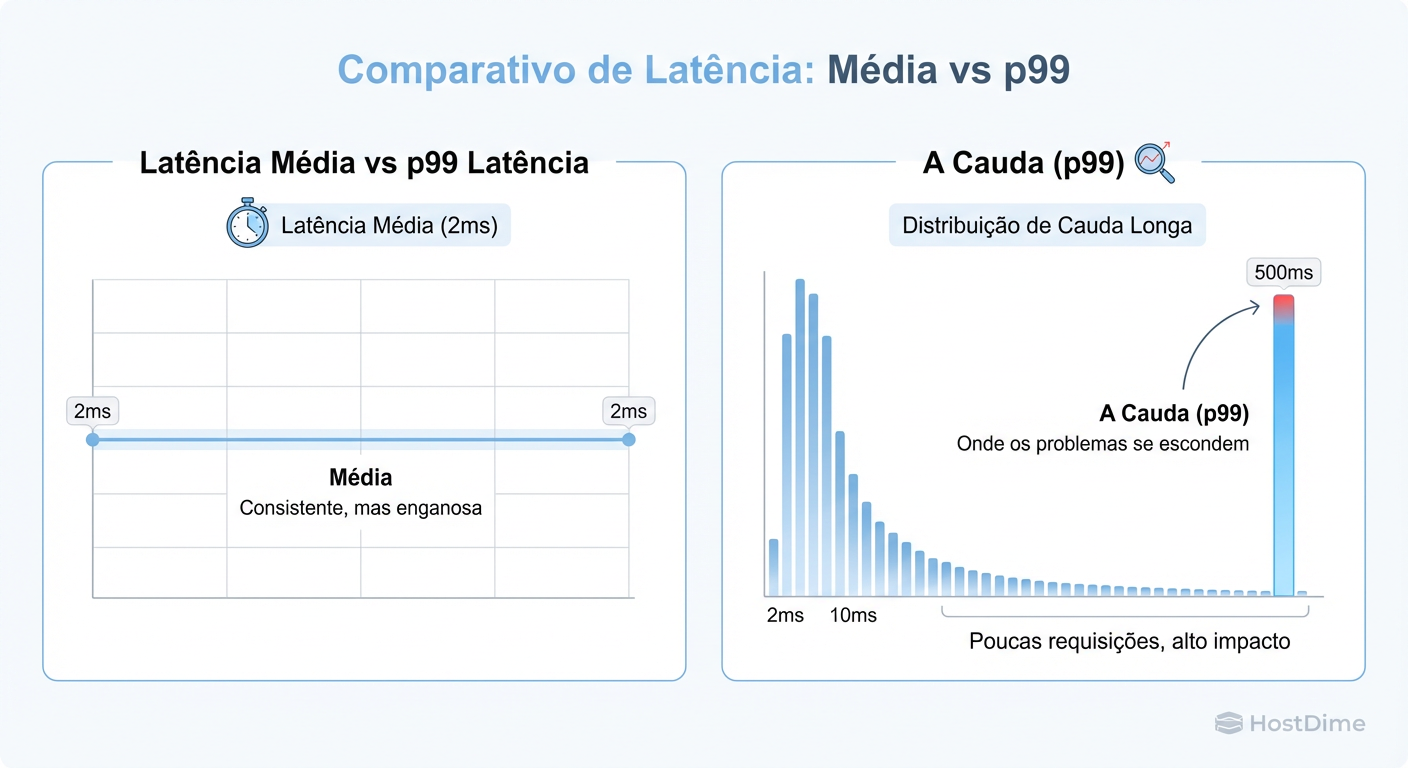 Figura: A Ilusão da Média: A maioria dos I/Os é rápida, mas a 'cauda longa' (p99) é onde vivem os travamentos do seu ERP.
Figura: A Ilusão da Média: A maioria dos I/Os é rápida, mas a 'cauda longa' (p99) é onde vivem os travamentos do seu ERP.
O problema real surge quando você tem sistemas transacionais complexos. Uma única página web pode gerar 50 chamadas ao banco de dados. Se qualquer uma dessas chamadas cair na "cauda longa" (o p99 ou p99.9), a página inteira fica lenta. Em storage distribuído, a probabilidade de atingir essa latência aumenta exponencialmente com a complexidade da rede.
O Efeito Dominó no Banco de Dados e Lock Contention
O maior erro do sysadmin júnior é achar que um I/O lento afeta apenas a requisição que o solicitou. Em bancos de dados relacionais (PostgreSQL, MySQL, Oracle), a latência de disco gera congestão de locks.
Veja a anatomia do desastre:
Uma transação faz um
UPDATEem uma tabela muito acessada.O banco de dados aplica um Row Lock (bloqueio de linha) ou, pior, um Page Lock.
Para confirmar a transação (ACID), o banco precisa fazer um
fsyncno Write Ahead Log (WAL) para garantir que o dado está no disco.O storage engasga. O p99 bate 500ms devido a um vizinho barulhento ou rebalanceamento de dados.
Durante esses 500ms, o Lock continua ativo.
Outras 50 conexões tentam ler ou escrever naquele registro e ficam em estado de espera (
WAIT).O pool de conexões da aplicação enche.
A aplicação começa a rejeitar novas conexões.
O storage "voltou ao normal" meio segundo depois, mas o estrago na camada de aplicação pode levar minutos para se desfazer. O IOPS não importa aqui; o que importa é a latência de confirmação de escrita (sync latency).
A Física do Storage Distribuído e Replicação
Quando saímos do disco local e vamos para Ceph, GlusterFS, vSAN ou EBS, introduzimos a rede na equação. E a rede é hostil.
Em um storage distribuído com replicação 3x (padrão de mercado para segurança), uma escrita não é confirmada até que os dados estejam seguros em múltiplas réplicas.
 Figura: O Ciclo da Escrita Síncrona: Em storage distribuído, o banco de dados só recebe o 'OK' depois que o disco mais lento da cadeia responde.
Figura: O Ciclo da Escrita Síncrona: Em storage distribuído, o banco de dados só recebe o 'OK' depois que o disco mais lento da cadeia responde.
O Problema do "Straggler" (O mais lento dita o ritmo)
Na replicação síncrona, o banco de dados só recebe o "OK" quando o disco mais lento do grupo responde. Se você grava em três nós:
Nó A responde em 1ms.
Nó B responde em 1.2ms.
Nó C está sofrendo com Garbage Collection ou compactação de SSD e leva 200ms.
A latência da sua escrita será 200ms. Você é refém do pior componente da sua infraestrutura distribuída. Isso é física, não configuração. Adicione a isso o Network Jitter (variação na latência da rede) e retransmissões TCP, e você entenderá por que storage local NVMe sempre parecerá mágica comparado a qualquer SAN all-flash.
Tabela Comparativa: Latência vs. Confiabilidade
| Tipo de Storage | Latência Típica (Escrita Sync) | Risco de p99 Alto | Custo/GB | Melhor Uso |
|---|---|---|---|---|
| NVMe Local | < 0.1 ms | Baixo | Alto (Efêmero) | Caches, TempDB, Logs (se houver replicação app-level) |
| SAN All-Flash (FC/iSCSI) | 0.5 - 2 ms | Médio | Altíssimo | BDs Legados, Virtualização densa |
| Storage Distribuído (Ceph/vSAN) | 2 - 10 ms | Alto (Network Jitter) | Médio | Cloud Privada, Containers, Big Data |
| Storage de Objeto (S3) | 20 - 100+ ms | Muito Alto | Baixo | Backups, Mídia, Datalakes (Nunca para BDs) |
Como medir Latência p99 com eBPF (Saindo do iostat)
Se você usa iostat -x 1, você está olhando para médias (r_await e w_await). Para ver a verdade, precisamos de histogramas. A melhor forma de fazer isso hoje no Linux moderno é usando eBPF (extended Berkeley Packet Filter), que permite inspecionar cada I/O sem o overhead de ferramentas de debug antigas.
A ferramenta biolatency (do pacote bcc-tools ou iovisor) é essencial. Ela mostra a distribuição de latência em um histograma.
O que você deve procurar
Execute o comando abaixo durante um momento de lentidão percebida:
# Mede a latência de I/O de disco por 10 segundos
/usr/share/bcc/tools/biolatency -D 10
Saída esperada (o cenário de horror):
usecs : count distribution
0 -> 1 : 0 | |
2 -> 3 : 0 | |
4 -> 7 : 0 | |
8 -> 15 : 0 | |
16 -> 31 : 24 | |
32 -> 63 : 568 |**** |
64 -> 127 : 4102 |**************************************|
128 -> 255 : 2011 |****************** |
256 -> 511 : 58 | |
512 -> 1023 : 2 | |
1024 -> 2047 : 0 | |
2048 -> 4095 : 0 | |
4096 -> 8191 : 0 | |
8192 -> 16383 : 15 |* | <--- O PERIGO
16384 -> 32767 : 4 | | <--- O TRAVAMENTO
Note que a maioria (a "barriga" do gráfico) está rápida, entre 64 e 255 microsegundos. Mas veja lá embaixo: temos 19 operações que levaram entre 8ms e 32ms. Se essas 19 operações forem fsync de commit de transações vitais, seu banco travou 19 vezes nesses 10 segundos. O iostat mostraria uma média perfeita, escondendo esses outliers.
Callout de Risco: Se você vê latências acima de 10ms em discos SSD/NVMe consistentemente na cauda do histograma, seu disco está saturado, falhando ou (se for nuvem) você atingiu o limite de burst e está sendo limitado (throttled) pelo provedor.
Estratégias de Mitigação: Quando o Cache Local salva o dia
Você provou que o p99 está alto. E agora? Mudar de storage nem sempre é opção. Aqui estão estratégias pragmáticas para sobreviver a um storage distribuído com "jitter".
1. Separação de WAL/Journal
O I/O mais sensível à latência é o log de transação (WAL no Postgres, Redo Log no Oracle, Journal no Ceph).
Ação: Mova esses logs para um dispositivo dedicado, preferencialmente local ou um volume de latência ultra-baixa, separado do volume onde residem os dados brutos (datafiles).
Por que funciona: Evita que leituras pesadas de relatórios (analytics) briguem por IOPS e fila com a gravação síncrona das transações.
2. QoS de Rede (Quality of Service)
Em ambientes convergentes (HCI), o tráfego de storage compete com o tráfego da aplicação.
- Ação: Implemente VLANs dedicadas para storage com prioridade DSCP ou, idealmente, interfaces físicas separadas. Jumbo Frames (MTU 9000) são obrigatórios para reduzir a sobrecarga de CPU no processamento de pacotes de storage.
3. Cache de Leitura Local (L2ARC / bcache)
Se a latência de leitura é o problema, traga os dados para perto da CPU.
ZFS: O L2ARC (Level 2 Adaptive Replacement Cache) permite usar um SSD local rápido para cachear dados de um pool de discos magnéticos ou de rede lentos.
Linux Nativo:
bcacheoudm-cachepodem colocar um NVMe local na frente de um volume iSCSI lento.Atenção: Isso resolve latência de leitura. Latência de escrita (p99 de write) só se resolve com hardware mais rápido ou garantias de rede melhores, pois escritas precisam ser persistidas com segurança.
Veredito Técnico
Não aceite "a média está boa" como resposta. Quando seu banco de dados trava, raramente é porque o disco parou de funcionar; é quase sempre porque ele demorou tempo demais para responder a uma pergunta crítica.
Aprenda a usar histogramas. Ignore o marketing de "milhões de IOPS". Foque na latência de cauda. Se você conseguir garantir que 99.9% das suas escritas retornem em menos de 2ms, você terá um sistema que não apenas é rápido, mas é previsível. E previsibilidade é o que nos deixa dormir à noite.
Referências & Leitura Complementar
Google Site Reliability Engineering Book - Capítulo sobre "Tail at Scale" (Dean & Barroso). Fundamental para entender como latências pequenas se somam.
Brendan Gregg's Systems Performance - A bíblia da análise de performance e uso de eBPF.
Ceph: A Scalable, High-Performance Distributed File System - Paper original (Weil et al.) que detalha a mecânica do CRUSH map e replicação.
PostgreSQL Documentation: Write Ahead Log - Entendimento profundo de por que o
fsyncé o gargalo.

Carlos Menezes
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.