Latência p95/p99: Por que a Média Engana

A latência média mente. Se você está gerenciando sistemas distribuídos, confiando apenas na latência média, está construindo sobre areia movediça. A latência mé...
Latência p95/p99: Por que a Média Engana
A latência média mente. Se você está gerenciando sistemas distribuídos, confiando apenas na latência média, está construindo sobre areia movediça. A latência média pode parecer boa, mas esconder problemas seríssimos que afetam diretamente a experiência do usuário e a saúde do seu sistema. Este guia é para sysadmins, SREs e engenheiros de infraestrutura que querem entender a fundo a latência, os perigos de ignorar a cauda longa e como usar percentis (p95, p99, p99.9) para construir sistemas mais robustos e confiáveis.
O Problema da Média:
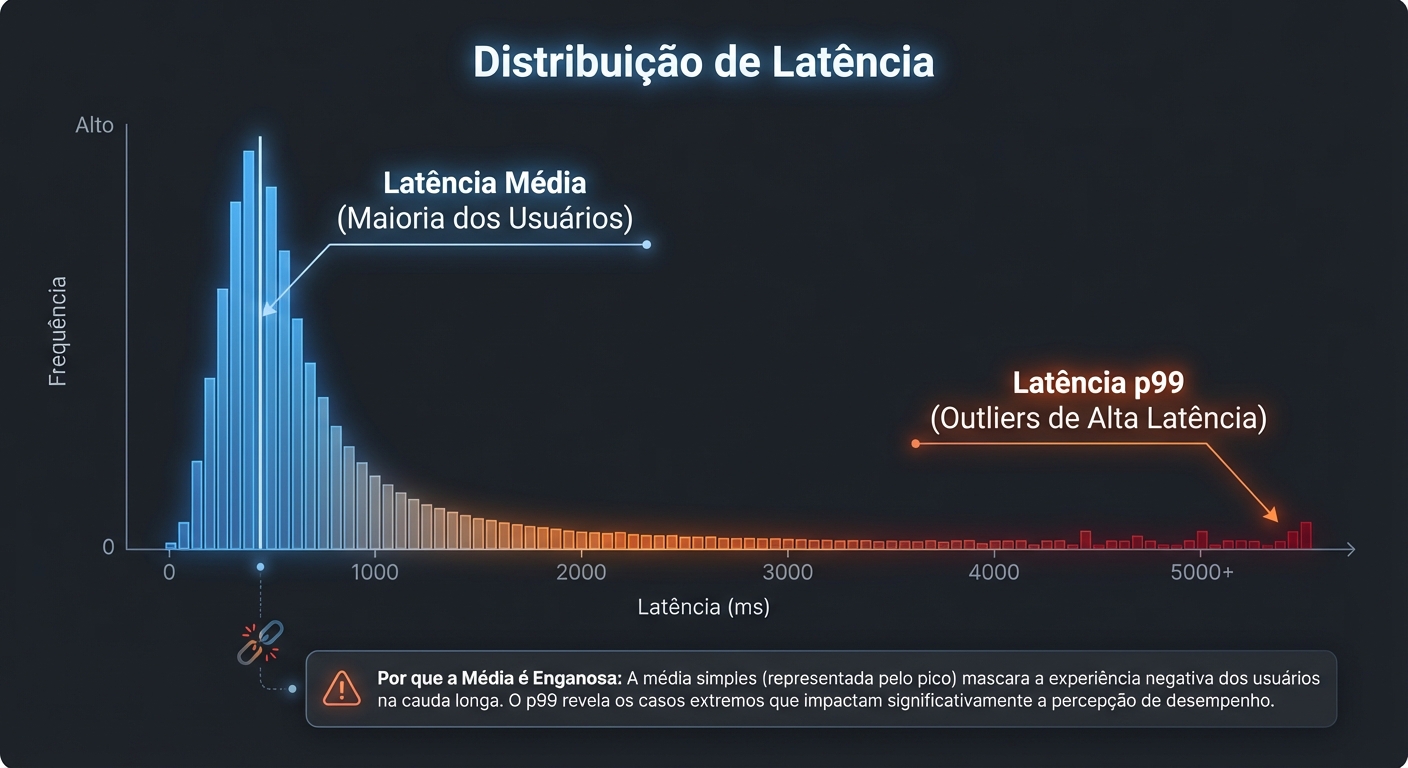
Imagine que você está monitorando o tempo de resposta de uma API. A latência média é de 50ms. Parece ótimo, certo? Mas e se, secretamente, 5% das requisições estiverem demorando 1 segundo? A média esconde essa informação crucial. Usuários que ocasionalmente experimentam latências altíssimas podem ficar frustrados e abandonar a plataforma. A média suaviza os picos, dando uma falsa sensação de segurança.
A média é sensível a outliers. Um único valor extremamente alto pode inflar a média, mascarando o comportamento geral do sistema. Em sistemas distribuídos, onde a variabilidade é a regra, a média se torna uma métrica praticamente inútil para entender o desempenho real.
O Que é Latência:
Latência é o tempo que leva para uma requisição ser completada. Simples assim. Ela é geralmente medida em milissegundos (ms) ou microssegundos (µs). Em um sistema distribuído, a latência é a soma de vários fatores: tempo de rede, tempo de processamento no servidor, tempo de acesso ao disco, etc.
Para medir a latência, você precisa de instrumentação. Isso significa adicionar código que registra o tempo de início e o tempo de fim de cada requisição. Esses dados podem ser coletados e agregados para calcular a latência.
# Exemplo simplificado de medição de latência em Python
import time
start_time = time.time()
# ... código que processa a requisição ...
end_time = time.time()
latency = (end_time - start_time) * 1000 # Latência em ms
print(f"Latência: {latency:.2f} ms")
É fundamental que a medição da latência seja o mais precisa possível. Isso significa minimizar o overhead da instrumentação e garantir que os relógios dos diferentes servidores estejam sincronizados (usando NTP, por exemplo).
Percentis (p95, p99, p99.9):
Percentis são uma forma de entender a distribuição da latência. Em vez de apenas um número (a média), os percentis nos dão uma visão mais completa do desempenho do sistema.
- p95 (Percentil 95): Significa que 95% das requisições são completadas em um tempo menor ou igual a esse valor. Em outras palavras, apenas 5% das requisições são mais lentas.
- p99 (Percentil 99): Significa que 99% das requisições são completadas em um tempo menor ou igual a esse valor. Apenas 1% das requisições são mais lentas.
- p99.9 (Percentil 99.9): Significa que 99.9% das requisições são completadas em um tempo menor ou igual a esse valor. Apenas 0.1% das requisições são mais lentas.
Como Interpretar:
Se o p95 da latência da sua API é de 200ms, isso significa que 95% dos seus usuários estão experimentando um tempo de resposta menor ou igual a 200ms. Os outros 5% estão tendo uma experiência pior. Se o p99 é de 1 segundo, isso significa que 1% dos seus usuários está esperando muito tempo.
A escolha do percentil a ser monitorado depende da sua aplicação e das suas necessidades. Para aplicações interativas, como websites, o p95 e o p99 são geralmente os mais importantes. Para aplicações de alta frequência ou que exigem extrema consistência, o p99.9 ou até mesmo o p99.99 podem ser relevantes.
É importante notar que, quanto mais alto o percentil, mais difícil é otimizar. Melhorar o p99.9 requer muito mais esforço do que melhorar o p95.
Causas da Cauda Longa (Long Tail Latency):
A "cauda longa" da latência se refere aos valores de latência mais altos, que ocorrem com menos frequência, mas que podem ter um impacto desproporcional na experiência do usuário. Existem diversas causas para a cauda longa, e identificá-las é fundamental para otimizar o desempenho do sistema.
- Context Switching: O sistema operacional precisa alternar entre diferentes processos. Essa troca de contexto leva tempo, e pode afetar a latência de algumas requisições.
- Garbage Collection (GC): Em linguagens com coleta automática de lixo (como Java e Go), o GC pode pausar a execução do programa por um tempo significativo. Essas pausas podem causar picos de latência. GCs mais modernos (como GCs pauseless) minimizam esse impacto, mas não o eliminam completamente.
- Contenção de Recursos: Se vários processos estão competindo pelos mesmos recursos (CPU, memória, disco, rede), a latência pode aumentar. Por exemplo, se dois processos estão tentando escrever no mesmo arquivo ao mesmo tempo, um deles terá que esperar.
- Lentidão de Rede: Problemas na rede (congestionamento, perda de pacotes, latência alta) podem aumentar a latência. É importante monitorar a rede para identificar gargalos e problemas de conectividade.
- Retransmissões: Se um pacote de rede é perdido, ele precisa ser retransmitido. Isso aumenta a latência. Retransmissões podem ser causadas por congestionamento na rede, erros de hardware ou problemas de software.
- Problemas de Disco: Acesso a disco lento (especialmente em discos mecânicos) pode aumentar a latência. Usar SSDs em vez de discos mecânicos pode melhorar significativamente o desempenho.
- Problemas de Cache: Se os dados necessários não estão no cache, o sistema precisa buscá-los na memória principal ou no disco. Isso aumenta a latência. É importante otimizar o cache para maximizar a taxa de acerto (hit rate).
- Deadlocks e Livelocks: Condições raras de concorrência que podem travar ou impedir o progresso de operações.
- Problemas de Hardware: Falhas em componentes de hardware (CPU, memória, disco, rede) podem causar picos de latência.
- Picos de Carga: Aumentos repentinos na carga do sistema podem levar à sobrecarga e aumentar a latência.
Como Medir Percentis:
Existem diversas ferramentas e técnicas para medir percentis de latência.
- fio: Uma ferramenta de benchmark flexível para testar o desempenho de I/O. Pode ser configurada para medir percentis de latência.
fio --name=test --ioengine=libaio --filename=/dev/sdb --bs=4k --direct=1 --rw=randrw --rwmixread=70 --numjobs=1 --iodepth=16 --runtime=60 --time_based --group_reporting --stats_aggression=cumulative --percentile_list=50:95:99:99.9 - hdr_histogram: Uma biblioteca para registrar histogramas de alta resolução com baixo overhead. Pode ser usada para calcular percentis com precisão. Existem implementações em várias linguagens (Java, C++, Python, etc.).
- Prometheus/Grafana: Uma combinação poderosa para monitoramento e visualização de métricas. Prometheus pode coletar métricas de latência, e Grafana pode ser usado para criar dashboards que exibem os percentis.
- No Prometheus, você pode usar a função
histogram_quantile()para calcular percentis a partir de histogramas.
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) - No Prometheus, você pode usar a função
- APM (Application Performance Monitoring): Ferramentas de APM (como New Relic, Datadog, Dynatrace) fornecem monitoramento detalhado do desempenho de aplicações, incluindo medição de percentis de latência.
- Logging: Registrar o tempo de cada requisição em logs e, posteriormente, usar scripts para analisar os logs e calcular os percentis. Essa abordagem é mais simples, mas pode ser menos precisa e mais custosa em termos de recursos.
Ao configurar ferramentas de monitoramento, certifique-se de definir alertas para quando os percentis de latência excederem os limites aceitáveis. Isso permite que você reaja rapidamente a problemas de desempenho antes que eles afetem os usuários.
O Impacto na UX e SLAs:
A cauda longa da latência pode ter um impacto significativo na experiência do usuário. Usuários que experimentam latências altas podem ficar frustrados, abandonar a plataforma, ou ter uma percepção negativa da marca.
Além disso, a cauda longa pode afetar o cumprimento de SLAs (Service Level Agreements). SLAs geralmente definem metas de desempenho em termos de percentis de latência. Por exemplo, um SLA pode exigir que 99% das requisições sejam completadas em menos de 500ms. Se a cauda longa da latência for muito grande, pode ser difícil cumprir esse SLA.
É crucial definir SLAs realistas e monitorar o desempenho do sistema em relação a esses SLAs. Se o sistema não estiver cumprindo os SLAs, é preciso investigar as causas da cauda longa e tomar medidas para otimizar o desempenho. Negociar SLAs que considerem os percentis é fundamental para garantir que as expectativas estejam alinhadas com a capacidade real do sistema.
O Que Levar Disso:
Parar de olhar para a média e começar a monitorar os percentis (p95, p99, p99.9) é o primeiro passo para construir sistemas mais robustos e confiáveis. Entenda as causas da cauda longa da latência e invista em ferramentas de monitoramento e otimização.
- Monitore Percentis, Não Apenas Médias: Configure seus sistemas de monitoramento para coletar e exibir percentis de latência.
- Entenda a Distribuição: Analise a distribuição da latência para identificar padrões e anomalias.
- Otimize para a Cauda Longa: Invista em otimizações que reduzam a cauda longa da latência. Isso pode envolver otimizar o código, ajustar a configuração do sistema operacional, ou investir em hardware mais rápido.
- Defina SLAs Baseados em Percentis: Negocie SLAs que considerem os percentis de latência.
- Automatize a Resposta a Problemas: Use alertas e automação para responder rapidamente a problemas de desempenho.
Lembre-se: a latência média mente. Os percentis contam a história completa. Ao focar nos percentis, você estará construindo sistemas que proporcionam uma melhor experiência do usuário e que são mais resilientes a problemas de desempenho.

Julia M. Santos
Enterprise Storage Consultant
Consultora para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.