Linux Multipath Dm Multipath Conceitos Essenciais

Para entender o DM-Multipath, você precisa entender a filosofia do Device Mapper (DM) no Linux. O DM é, essencialmente, um framework de mentiras organizadas....
Linux Multipath Dm Multipath Conceitos Essenciais
A Grande Mentira: O Device Mapper
Para entender o DM-Multipath, você precisa entender a filosofia do Device Mapper (DM) no Linux. O DM é, essencialmente, um framework de mentiras organizadas.
O Kernel Linux vê a realidade crua: você tem dois HBAs (Host Bus Adapters) de fibra óptica. Cada HBA conecta-se a dois switches SAN. Cada switch conecta-se a duas controladoras no Storage Array. Isso significa que, para um único volume lógico (LUN) apresentado pelo storage, seu servidor pode ver 4, 8 ou até 16 caminhos físicos diferentes.
Se você montar /dev/sda (caminho 1) e o cabo cair, o mount morre. Fim de jogo.
O Device Mapper entra no meio do caminho para criar uma camada de abstração. Ele diz ao Kernel: "Ignore esses 8 dispositivos físicos (sd*). Eu vou criar um dispositivo virtual (/dev/dm-0 ou /dev/mapper/mpatha). O sistema de arquivos só fala comigo. Eu me viro para decidir por qual cabo físico vou mandar os bits".
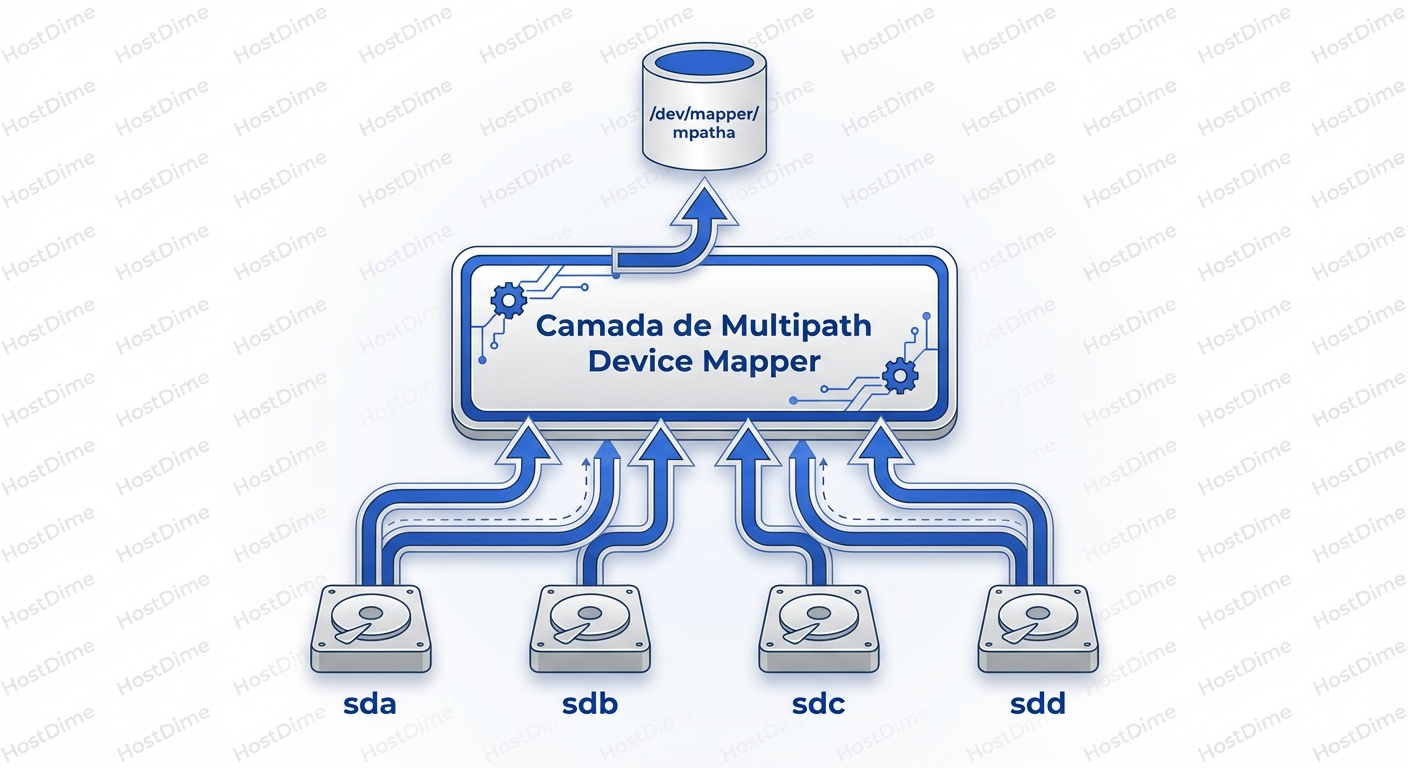
Essa abstração é vital. O sistema de arquivos (XFS, EXT4) não tem ideia de que existe uma SAN, cabos ou switches. Ele escreve blocos em um dispositivo virtual. O DM-Multipath intercepta esses blocos e aplica uma lógica de roteamento.
O Identificador Único (WWID)
Como o Linux sabe que /dev/sda e /dev/sdz são, na verdade, o mesmo disco físico? Eles têm nomes diferentes, números maiores/menores (major/minor) diferentes e podem até ter geometrias detectadas ligeiramente diferentes dependendo do driver.
A resposta é o WWID (World Wide Identifier).
Cada LUN criada em um storage enterprise possui um número serial único gravado em sua firmware (Page 0x83 do VPD - Vital Product Data). Quando o Linux escaneia o barramento SCSI, ele pergunta a cada dispositivo: "Quem é você?".
Se sda responde "Eu sou o disco ID 60050768...", e sdb responde "Eu sou o disco ID 60050768...", o multipathd (o daemon em userspace) percebe a duplicidade. Ele agrupa todos os dispositivos que compartilham o mesmo WWID sob um único mapa.
Nota Mental: Se o multipath não está agrupando seus discos, 99% das vezes o problema é que o Linux não está conseguindo ler o WWID (problema de uid_attribute na config) ou os discos realmente são diferentes. Nunca force um agrupamento sem confirmar o WWID.
Arquitetura: Kernel vs. Userspace
Aqui é onde a confusão começa para muitos. O multipath não é um monólito; ele é dividido em duas partes que conversam constantemente.
- Kernel (dm-multipath): É o operário. Ele reside no espaço do kernel e é responsável pelo roteamento real dos pacotes de I/O. Ele não pensa muito; ele apenas segue a tabela de mapeamento atual. Se você matar o serviço
multipathd, o I/O continua funcionando porque o mapeamento já está carregado no kernel. - Userspace (multipathd): É o gerente. Ele monitora a saúde dos caminhos. Ele envia "pings" (TUR - Test Unit Ready ou Read sector 0) para os caminhos a cada X segundos. Se um caminho falha, o
multipathdpercebe, reconfigura o mapa e envia a nova instrução para o kernel ("Pare de usar o caminho A, use o caminho B").
Se o multipathd travar ou for desligado, o kernel perde a capacidade de reagir a novas falhas. O sistema continua rodando até que o caminho atual morra; aí, sem o gerente para atualizar a rota, o I/O falha.
O Lado do Storage: ALUA e a Ilusão do "Ativo-Ativo"
Você comprou um storage caro que o vendedor jurou ser "Active/Active". Você configura o Linux para usar Round-Robin (distribuir I/O igualmente entre todos os cabos). De repente, a performance cai pela metade. O que aconteceu?
Bem-vindo ao mundo do ALUA (Asymmetric Logical Unit Access).
A maioria dos storages modernos não é verdadeiramente simétrica. Eles têm duas controladoras (A e B). Um LUN específico (digamos, o do seu Banco de Dados) é "dono" da Controladora A.
- Se você enviar dados pela Controladora A: O disco grava direto na memória cache. Rápido.
- Se você enviar dados pela Controladora B: A Controladora B recebe o dado, percebe que não é a dona do LUN, envia o dado via um link interno (inter-connect) para a Controladora A, que então grava. Lento.
O Linux precisa saber disso. O protocolo ALUA permite que o storage diga ao Linux: "Ei, eu aceito I/O por este caminho, mas não é o ideal".
Os estados típicos do ALUA são:
- Active/Optimized: O caminho vai direto para a controladora dona do LUN. (Use este!).
- Active/Non-Optimized: O caminho funciona, mas tem latência extra de inter-connect. (Use apenas se o Optimized morrer).
- Standby/Unavailable: O caminho está lá, mas não aceita I/O a menos que seja enviado um comando explícito de ativação.
Se o seu multipath.conf não estiver configurado para respeitar o ALUA (geralmente prio "alua"), o Linux pode alegremente enviar metade dos seus pacotes para a controladora errada, destruindo sua latência.
Anatomia do Comando: Lendo a Verdade
Esqueça o lsblk ou df -h para diagnóstico. A única fonte de verdade é o multipath -ll. Mas a saída é densa. Vamos dissecar um cenário real de produção.
360060e80104dac0005202d9c0000030d dm-2 HITACHI,OPEN-V
size=100G features='1 queue_if_no_path' hwhandler='0' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:1 sdb 8:16 active ready running
| `- 2:0:0:1 sdd 8:48 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:1 sdc 8:32 active ready running
`- 2:0:1:1 sde 8:64 active ready running
Vamos ler isso como um SRE:
- O WWID:
360060e8.... Este é o ID único. - O Dispositivo DM:
dm-2. É isso que o kernel vê. - Features:
queue_if_no_path. PERIGO E SALVAÇÃO. Isso diz que se todos os caminhos morrerem, o Linux não retorna erro de I/O para o app; ele pausa (enfileira) o I/O indefinidamente até que um caminho volte.- Lado bom: Uma falha de switch de 10 segundos não crasha o Oracle.
- Lado ruim: Se o storage explodir e nunca mais voltar, seu
umountourebootvai travar para sempre (hang), porque o kernel está esperando infinitamente para esvaziar a fila.
- Grupos de Prioridade (Path Groups): Note que existem dois grupos (
|-+-).- O primeiro grupo tem
prio=50estatus=active. - O segundo grupo tem
prio=10estatus=enabled. Isso é o ALUA em ação. O Linux detectou quesdbesddsão os caminhos rápidos (Optimized). Ele só vai usarsdcesde(Non-Optimized) se os dois primeiros falharem.
- O primeiro grupo tem
- Policy:
service-time 0. Isso é mais inteligente que Round-Robin. O kernel mede a latência de cada caminho e envia mais dados para o caminho que está respondendo mais rápido.
Estratégias de Seleção de Caminho
A forma como o kernel escolhe qual "fio" usar dentro de um grupo ativo define o throughput do seu sistema.
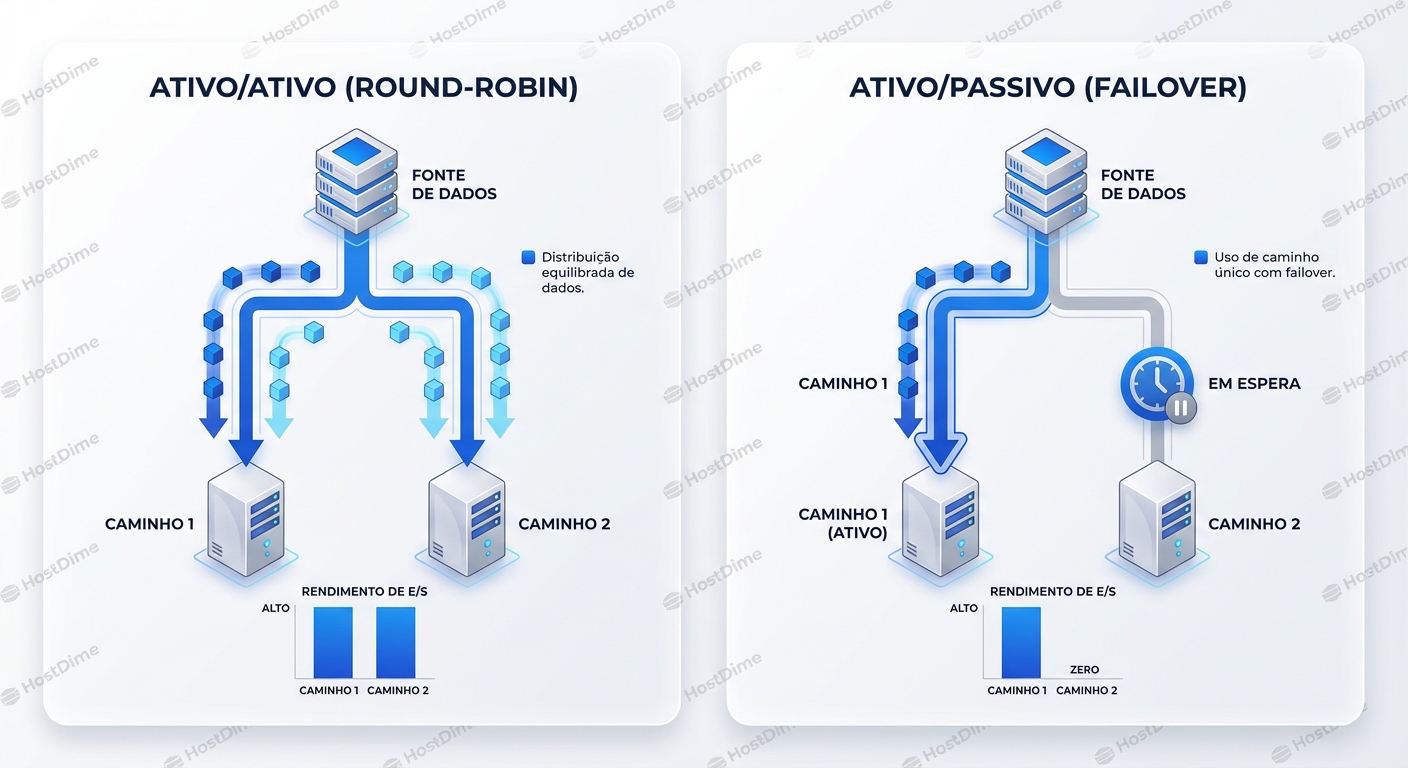
Vamos comparar as políticas mais comuns (configuradas em path_selector):
| Política | Como funciona | Quando usar | Onde falha |
|---|---|---|---|
| round-robin 0 | Envia X I/Os para o caminho A, depois X para o B, em loop. | Ambientes simples, links idênticos. | Se um caminho degrada (perda de pacotes, não queda total), o RR continua mandando dados para lá, atrasando tudo. |
| queue-length 0 | Envia para o caminho com menos I/Os pendentes na fila atual. | Cargas desbalanceadas. | Não considera o tempo de resposta, apenas a quantidade de pedidos. |
| service-time 0 | Estima o throughput baseado no tempo de conclusão de I/Os passados. | Padrão Ouro moderno. | Requer um pouco de histórico para ser preciso (warm-up). |
Dica de Trincheira: Em storages modernos (All-Flash), use service-time. O Round-robin é burro demais para lidar com micro-latências variáveis em redes SAN congestionadas.
O Momento da Falha: O que acontece quando você puxa o cabo?
Aqui é onde a teoria encontra a realidade. Vamos simular mentalmente um "cable pull".
- Evento Físico: O cabo de fibra do HBA1 é removido.
- O Kernel Reage: O driver SCSI tenta enviar um pacote e recebe um erro de transporte ou timeout.
- Bloqueio: O I/O que estava em trânsito falha. O Kernel tenta novamente (retries) no mesmo caminho, dependendo das configurações de timeout da camada SCSI (
/sys/class/scsi_device/*/device/timeout). - A Decisão: Após esgotar as tentativas rápidas, o driver SCSI retorna erro para o Device Mapper.
- Failover: O Device Mapper marca aquele caminho como
failed. Ele olha para o grupo de prioridade. Tem outro caminhoactive?- Sim: Reenvia o I/O pelo caminho vizinho. Aplicação sente uma latência de milissegundos.
- Não (Todos ativos morreram): Ele ativa o grupo de prioridade inferior (os caminhos ALUA Non-Optimized). Isso pode levar tempo (segundos) pois o storage precisa mudar o ownership do LUN internamente.
O Assassino Silencioso: Timeouts
O maior inimigo da disponibilidade não é a falha, é a indecisão.
Se o seu storage "meio que morre" (a porta do switch pisca, pacotes são dropados, mas o link não cai totalmente), o Linux padrão é extremamente paciente. Ele pode tentar retransmitir por 30, 60 segundos antes de declarar o caminho morto. Para um banco de dados, 60 segundos de I/O congelado é o mesmo que indisponibilidade.
Existem dois parâmetros vitais no multipath.conf que você deve ajustar:
fast_io_fail_tmo: (Geralmente 5s). Diz ao driver SCSI: "Se o link estiver duvidoso, espere no máximo 5 segundos. Se não resolver, declare falha de transporte imediatamente e deixe o multipath tentar outro caminho". Isso é obrigatório para SANs. Sem isso, o failover demora tempo demais.dev_loss_tmo: (Geralmente infinito ou 600s). Diz: "Depois que o caminho falhou, por quanto tempo eu mantenho o dispositivo/dev/sdXna memória antes de removê-lo completamente?". Se você remover rápido demais e o link voltar oscilando, você causa caos no kernel.
Diagnosticando em Produção: Comandos de Sobrevivência
Quando o alerta tocar, não saia reiniciando o iscsi/fc services. Use a observabilidade.
1. Verifique a Topologia e Saúde
multipath -ll
Procure por caminhos failed ou faulty. Se você ver caminhos alternando rapidamente entre active e failed, você tem um "path thrashing" (cabo ruim ou porta de switch com erro de CRC).
2. Veja as Estatísticas de I/O por Caminho
O iostat padrão mostra todos os discos, o que é confuso. Use a flag -m para ver por device mapper ou use o dmsetup:
dmsetup status --target=multipath
Isso mostra a contagem bruta de I/Os e erros por grupo.
3. Forçando uma Reconfiguração
Se você adicionou discos novos ou mudou o zoneamento da SAN, o kernel não descobre sozinho instantaneamente.
multipath -v2 # Escaneia e atualiza a topologia (verboso)
multipath -r # Força reload do mapa (cuidado com I/O pesado)
4. O Cenário "Ghost Device"
Às vezes, um caminho morre, mas o dispositivo /dev/sdX fica em estado "zumbi", causando erros no console.
echo 1 > /sys/block/sdX/device/delete
Isso remove o dispositivo SCSI manualmente do kernel. O multipathd deve limpar o mapa em seguida.
Blacklisting: Protegendo o que não é SAN
Um erro clássico de novato é instalar o multipath e ele engolir tudo, inclusive o disco local do sistema operacional (/dev/sda que é um SSD SATA local). O multipath tenta gerenciar o disco de boot, falha (porque só tem um caminho) e cria logs de erro infinitos ou problemas no initramfs.
Sempre, sempre configure a blacklist no /etc/multipath.conf.
Abordagem Moderna (Allowlist): Em vez de tentar bloquear tudo o que você não quer (blacklist), bloqueie tudo por padrão e libere apenas o seu storage.
blacklist {
devnode ".*" # Bloqueia tudo
}
blacklist_exceptions {
property "(SCSI_IDENT_|ID_WWN)" # Exceções baseadas em UDEV
devnode "^mapper"
wwid "360060e80..." # Libere apenas seus LUNs críticos
}
Ou, mais comum, bloquear por tipo de dispositivo:
blacklist {
devnode "^(ram|raw|loop|fd|md|dm-|sr|scd|st)[0-9]*"
devnode "^hd[a-z]"
devnode "^sda$" # Cuidado com nomes instáveis! Melhor usar WWID.
}
O Veredito sobre Resiliência
O DM-Multipath não é "instalar e esquecer". É uma camada ativa de lógica de roteamento que precisa estar sintonizada com a física do seu hardware (Storage + Switches).
Se você sair deste artigo com apenas três lições, que sejam estas:
- O WWID é rei. Se os WWIDs não batem, não há multipath. Se o multipath agrupou coisas erradas, verifique os WWIDs.
- ALUA importa. Se você ignorar a prioridade dos caminhos, transformará seu array All-Flash em um disco USB 2.0 devido à latência interna das controladoras.
- Timeouts definem o Failover. O padrão do Linux é conservador demais. Use
fast_io_fail_tmopara garantir que o sistema desista rápido de um caminho ruim e pule para o bom.
Da próxima vez que o banco de dados travar às 3 da manhã, não culpe o "disco". Culpe o caminho. E agora você sabe como encontrá-lo.

Julia M. Santos
Enterprise Storage Consultant
Consultora para Fortune 500. Traduz 'economês' para 'técniquês' e ajuda empresas a não gastarem milhões em SANs desnecessárias.