Live Migration: O Storage é o "Ponto Único de Verdade" (e de Falha)
Live migration parece mágica, mas é física pura. Entenda como latência de disco, locking e coerência de cache decidem se sua VM migra ou corrompe.
Para o observador casual ou o gerente de TI, o Live Migration (seja vMotion, KVM Live Migration ou Hyper-V Live Migration) é mágica. Você pega uma máquina virtual rodando SQL Server a todo vapor no Host A e a move para o Host B sem perder um único ping.
Para o Engenheiro de Performance, "mágica" é apenas complexidade que ainda não foi instrumentada.
A migração ao vivo não é um teletransporte; é um problema de sistemas distribuídos operando no limite da física. Enquanto a CPU e a RAM estão ocupadas copiando o estado volátil, o subsistema de armazenamento (Storage) assume o papel mais ingrato: ele é o árbitro da verdade. Se a memória falhar na cópia, a VM trava e reinicia (crash-consistent). Se o Storage falhar na coordenação de quem pode escrever onde, você tem corrupção de dados silenciosa e irreversível.
Vamos dissecar a anatomia desse processo, ignorando a interface gráfica e focando no que os contadores de performance e os logs de latência nos dizem.
A Anatomia do Salto: O Algoritmo de Pré-Cópia Iterativa
A primeira falácia é achar que a VM é "pausada" e depois movida. Se fizéssemos isso, o downtime seria proporcional ao tamanho da RAM (mover 512GB de RAM em uma rede de 10Gbps levaria minutos). O segredo é a Pré-Cópia Iterativa.
O hipervisor começa a copiar as páginas de memória do Host A (origem) para o Host B (destino) enquanto a VM continua rodando e sujando a memória.
Passo 1 (Bulk Copy): Todo o mapa de memória é enviado.
Passo 2 (Dirty Page Tracking): O hipervisor monitora quais páginas foram modificadas (escritas) durante o Passo 1.
Passo 3 (Delta Copy): Apenas as páginas "sujas" são enviadas.
Repetição: O processo se repete até que o delta seja pequeno o suficiente para caber em uma janela de tempo minúscula (o Stun Time).
Onde a Física Colide com a Configuração
Aqui entra o conceito de Taxa de Convergência. Para que a migração termine, a velocidade da rede de migração deve ser estritamente maior que a taxa de gravação na memória (Dirty Page Rate) da VM.
Se você tem um banco de dados OLTP agressivo alterando 4GB de RAM por segundo, e seu link de vMotion é de 10Gbps (teoricamente ~1.25GB/s, na prática menos devido ao overhead), você tem um problema matemático.
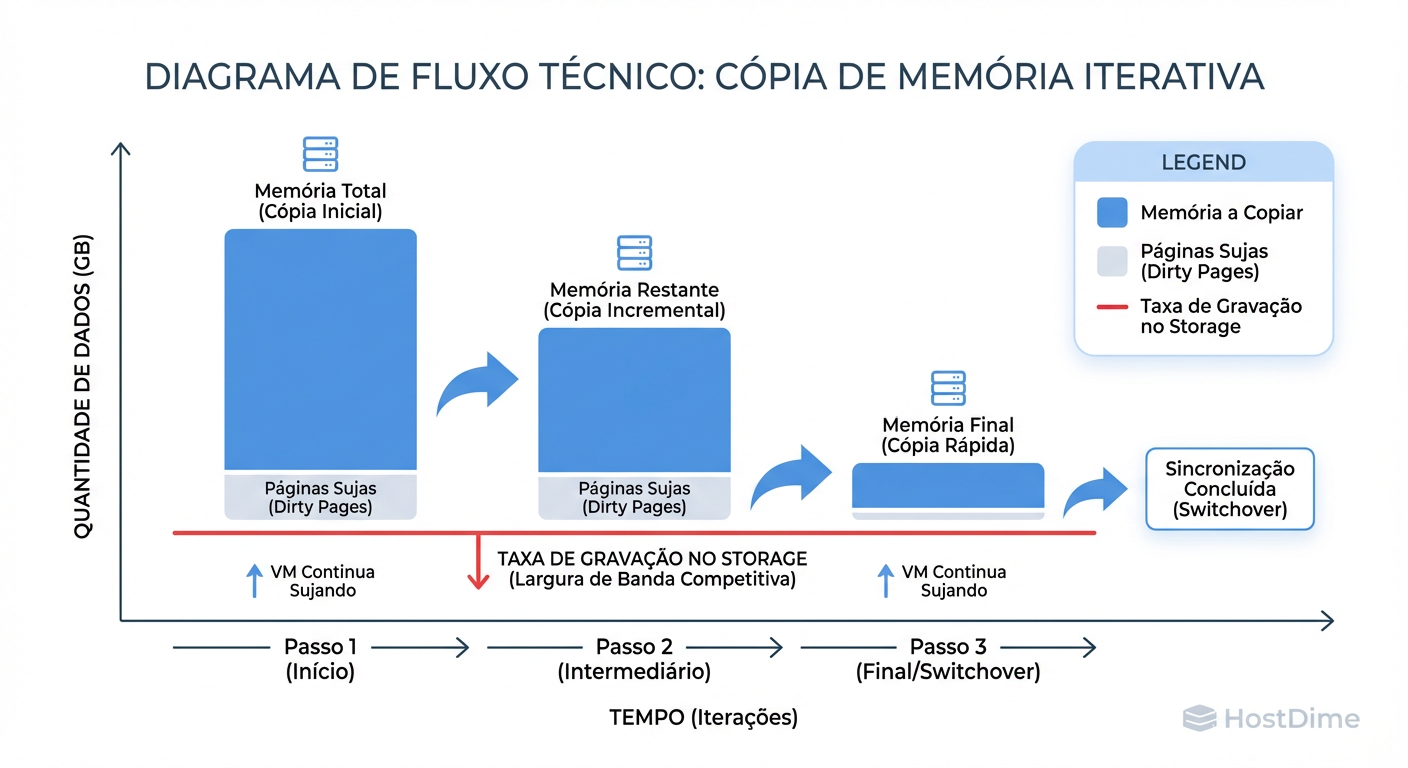 Figura: A Corrida da Convergência: Se a VM escreve na RAM (Dirty Rate) mais rápido do que a rede consegue copiar para o destino, a migração entra em loop infinito. O tráfego de Storage compete aqui.
Figura: A Corrida da Convergência: Se a VM escreve na RAM (Dirty Rate) mais rápido do que a rede consegue copiar para o destino, a migração entra em loop infinito. O tráfego de Storage compete aqui.
A imagem acima ilustra o cenário de não-convergência. O hipervisor entra em um loop infinito de cópias delta, saturando a rede e degradando a performance da VM e dos vizinhos, até que o limite de iterações seja atingido e ele force um "stun" longo (derrubando conexões) ou aborte a operação.
Como medir isso na prática (KVM/Libvirt):
Não adivinhe. Use o virsh para ver se a migração está convergindo ou apenas queimando ciclos de CPU.
# Durante uma migração, monitore o progresso e a taxa de transferência
watch -n 1 "virsh domjobinfo <nome-da-vm>"
# Saída crítica para observar:
# Data remaining: Se este número não baixar, você não tem largura de banda suficiente.
# Memory bandwidth: A velocidade real da rede de migração.
# Dirty rate: A velocidade com que a VM está escrevendo na RAM.
A Ilusão do Compartilhamento: O Storage como Juiz
Enquanto a memória é copiada bit a bit, o disco geralmente não se move (em uma migração de computação clássica). Ambos os hosts, A e B, enxergam o mesmo LUN ou Datastore.
O desafio aqui não é mover dados, é gerenciar a propriedade.
O Storage é o "Ponto Único de Verdade". A qualquer momento, apenas um host pode ter permissão de escrita nos metadados do sistema de arquivos da VM. Se o Host A e o Host B escreverem no mesmo bloco NTFS ou EXT4 simultaneamente, o sistema de arquivos deixa de existir.
Block-Level (FC/iSCSI) vs. File-Level (NFS)
A complexidade muda dependendo do protocolo, e isso afeta como você diagnostica problemas de "travamento" durante a migração.
NFS (File-Level): É mais simples. O bloqueio é feito via arquivos
.lck. O Host B tenta adquirir o lock do arquivo.vmdkou.qcow2. Se o Host A não liberar o lock a tempo (devido a latência de rede ou sobrecarga), a migração falha ou a VM congela no destino esperando o I/O.Block (FC/iSCSI): Aqui vive o perigo. Não há "arquivos" para bloquear no nível do array, apenas endereços LBA. Os hipervisores usam primitivas SCSI como SCSI Reservations ou ATS (Atomic Test and Set) no VAAI da VMware.
Callout de Risco: Em storages legados que não suportam ATS, o uso de SCSI Reservations tradicionais bloqueia o LUN inteiro (não apenas a VM) durante as atualizações de metadados. Isso causa "vizinhos barulhentos" onde uma migração causa picos de latência em outras VMs que compartilham o mesmo Datastore.
O Pesadelo do Split-Brain e o Fencing
O momento mais crítico é o handover. O Host A diz: "Terminei, Host B, é com você". O Host B diz: "Entendido, assumindo I/O".
Mas e se a rede de gerenciamento falhar exatamente nesse milissegundo?
O Host A acha que a migração falhou e continua rodando a VM. O Host B acha que a migração teve sucesso e começa a rodar a VM.
Agora você tem duas instâncias da mesma VM, com o mesmo IP, escrevendo no mesmo disco virtual. O resultado é a corrupção imediata.
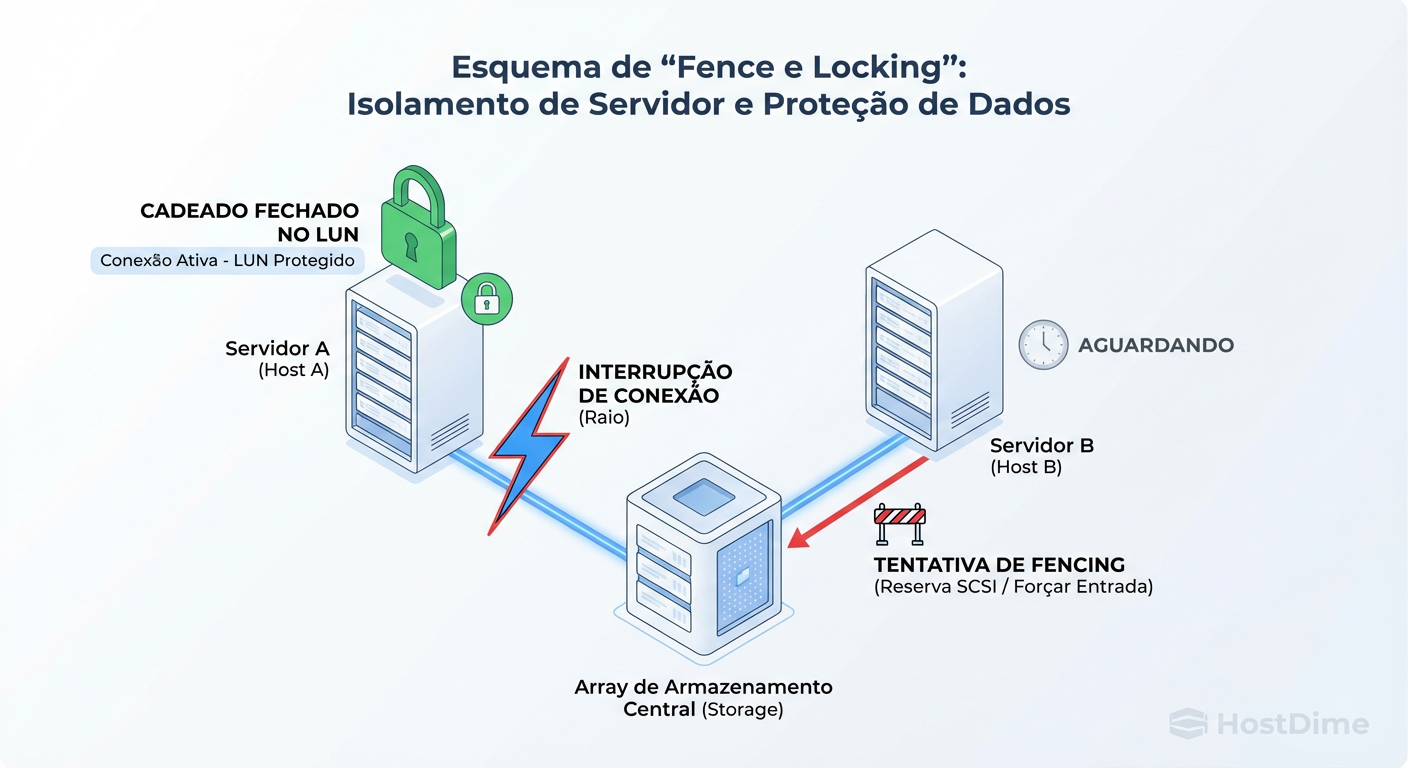 Figura: O Dilema do Split-Brain: Se o Host A perde a rede mas mantém o disco montado, e o Host B monta o mesmo disco, o sistema de arquivos é corrompido instantaneamente. O mecanismo de Fencing é o juiz.
Figura: O Dilema do Split-Brain: Se o Host A perde a rede mas mantém o disco montado, e o Host B monta o mesmo disco, o sistema de arquivos é corrompido instantaneamente. O mecanismo de Fencing é o juiz.
Para evitar isso, o Storage atua como o mecanismo de Fencing (isolamento). Através de SCSI-3 Persistent Reservations, o host que detém a "chave" expulsa o outro. É brutal, mas necessário. Se o seu storage tiver alta latência no processamento de comandos SCSI de reserva, esse processo de eleição demora, e a VM fica em um estado de "limbo" (I/O congelado), o que a aplicação percebe como um timeout.
Hiperconvergência (HCI): O Custo Oculto da Latência de Gravação
Em arquiteturas modernas de HCI (vSAN, Nutanix, Ceph), não existe "Storage Compartilhado" físico. O disco é local.
Quando você faz uma migração de computação + armazenamento (Shared-Nothing Migration), o cenário muda drasticamente. Você não está apenas copiando RAM; está espelhando o disco inteiro pela rede.
O impacto na performance de I/O é imediato e severo devido à replicação síncrona.
A VM no Host A emite uma gravação (Write).
O dado é escrito no disco local do Host A.
O dado é enviado pela rede para o Host B (destino).
O Host B escreve no disco e envia um ACK.
Só então o Host A confirma a gravação para o sistema operacional convidado.
Durante uma migração ativa, a latência de gravação da VM é ditada pela latência da rede + latência do disco do destino.
O que medir: Não olhe apenas para o throughput (MB/s). Olhe para a Latência de Gravação (Write Latency) dentro da VM. Se ela subir de 2ms para 15ms durante a migração, sua aplicação sensível (como um log de transação de banco de dados) vai sofrer engasgos, mesmo que a migração pareça "suave" no console de gerenciamento.
O Momento Crítico: Switchover e Stun Time
No final do processo, a VM deve ser paralisada para transferir o estado final da CPU (registradores) e os últimos bits de memória suja. Este é o "Stun Time".
O objetivo é manter isso abaixo de 1 segundo. Se passar de 5 segundos (o timeout padrão de TCP em muitas aplicações é maior, mas o keepalive de clusters costuma ser curto), você terá quedas de aplicação.
O Stun Time não é afetado apenas pela memória. Ele é afetado pelo I/O Queue Depth.
Se houver muitas operações de I/O pendentes na fila do Storage no momento do switchover, o hipervisor precisa drenar essa fila ou garantir que o estado do I/O seja replicado. Um storage lento ou uma rede congestionada aumenta o tempo de stun.
Checklist de Diagnóstico para Engenheiros
Se suas migrações estão causando impacto na aplicação, pare de culpar "a rede" genericamente e isole a variável:
Verifique o Dirty Page Rate: A aplicação escreve na RAM mais rápido do que a rede de migração suporta? (Solução: Aumente a banda de vMotion/Live Migration ou agende para horários de menor carga).
Analise a Latência de Storage (DAVG/KAVG no esxtop): O storage de destino está demorando para aceitar gravações durante a cópia?
Verifique Retransmissões TCP: Na rede de migração, pacotes perdidos destroem o throughput. Uma taxa de perda de 0.1% pode reduzir a velocidade de uma conexão de 10Gbps para 1Gbps.
MTU Mismatch: O erro clássico. Se o vMotion está configurado para Jumbo Frames (MTU 9000) mas um switch no meio do caminho está com MTU 1500, a migração falhará misteriosamente ou terá performance abismal devido à fragmentação ou drop silencioso.
Veredito Técnico
Live Migration é uma funcionalidade de conveniência que trocamos por complexidade de engenharia. O Storage não é apenas o lugar onde os dados vivem; durante a migração, ele é o mecanismo de bloqueio, o gargalo de replicação e o juiz final contra a corrupção de dados.
Para operar corretamente, você deve tratar a migração como um workload de alta intensidade. Meça a taxa de sujeira da memória, monitore as reservas SCSI e, acima de tudo, respeite a física: você não pode mover dados mais rápido do que o link mais lento da sua cadeia permite.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.