Monitoramento de Discos em RAID: Indo Além do Status SMART e Prevendo Falhas Reais

Não confie apenas no LED verde. Aprenda a monitorar atributos SMART críticos através de controladoras RAID, interpretar valores RAW e antecipar falhas de disco antes da perda de dados.
A redundância de dados é frequentemente vendida como um seguro contra falhas, mas na engenharia de performance, sabemos que RAID não é uma caixa mágica. É uma camada de abstração que, ironicamente, pode ocultar a degradação física dos seus discos até que seja tarde demais. Se você espera a luz vermelha acender no chassi do servidor ou o volume entrar em modo "Degraded", você já falhou na gestão da infraestrutura.
O monitoramento eficaz exige ceticismo. O status "OK" retornado pela controladora é, muitas vezes, uma simplificação grosseira de um cenário caótico de setores realocados e latência intermitente. Neste artigo, vamos desmontar a abstração, acessar a telemetria bruta e aplicar uma análise baseada em evidências para prever falhas antes que elas derrubem seu array.
O que é o Monitoramento Preditivo de RAID? O monitoramento preditivo de RAID é a prática de extrair e analisar métricas de telemetria física (SMART) de discos individuais ocultos atrás de uma camada lógica (Controladora RAID ou HBA). Diferente do monitoramento passivo de status (OK/Fail), ele foca na taxa de crescimento de erros de leitura/escrita e setores defeituosos para substituir hardware degradado antes que ocorra uma falha catastrófica ou perda de performance.
A Ilusão da Redundância e o Risco Oculto
Muitos administradores operam sob o modelo mental de que "RAID cuida dos discos". A realidade técnica é oposta: o RAID (especialmente hardware) isola o sistema operacional da física do disco.
Quando um setor falha em um disco único, o SO recebe um erro de I/O. Em um RAID 5 ou 6, a controladora calcula a paridade, entrega os dados ao SO e marca internamente aquele evento. Do ponto de vista do top ou iostat, o sistema continua funcionando, talvez com um leve aumento na latência de CPU (devido ao cálculo de XOR).
O perigo reside nas Falhas Cinzas (Gray Failures). Um disco pode não estar "morto", mas estar tentando reler um setor 50 vezes antes de desistir. Isso destrói o throughput do array inteiro e eleva a latência da cauda (P99), mas o status do RAID permanece "Optimal". Monitorar apenas o status lógico é voar às cegas.
Superando o Túnel de Visibilidade em Controladoras Hardware
O maior desafio técnico no monitoramento de RAID é o acesso aos dados. Se você rodar um smartctl -a /dev/sda em um servidor com uma controladora MegaRAID, você verá as estatísticas do Volume Lógico, não dos discos físicos. Precisamos de Passthrough.
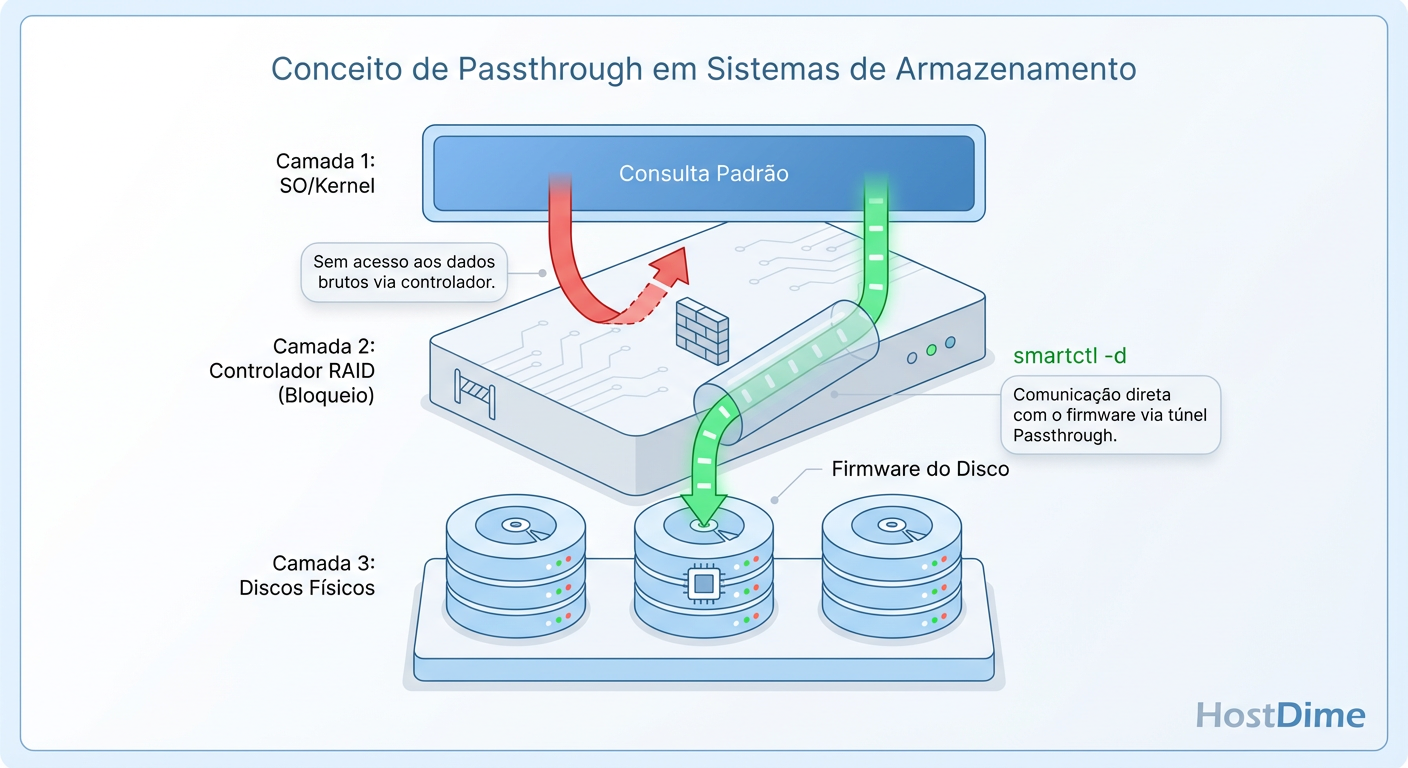 Figura: Diagrama de Passthrough: Superando a abstração da controladora RAID para acessar a telemetria física.
Figura: Diagrama de Passthrough: Superando a abstração da controladora RAID para acessar a telemetria física.
Para acessar a telemetria real, precisamos enviar comandos SCSI ou ATA encapsulados que a controladora repassa diretamente ao drive físico. Ferramentas como smartctl possuem drivers específicos para "furar" esse túnel de visibilidade.
Comandos de Acesso Direto (Passthrough)
Não confie em interfaces gráficas proprietárias lentas. A linha de comando é a única fonte da verdade em tempo real.
Se você utiliza controladoras baseadas em LSI/Broadcom (MegaRAID) ou HP Smart Array, a sintaxe muda. O objetivo é consultar o disco pelo seu ID no backplane, ignorando o mapeamento do SO.
# Exemplo para controladoras LSI MegaRAID
# Onde -d megaraid,N indica o driver e o ID físico do disco (0, 1, 2...)
smartctl -a -d megaraid,0 /dev/sda
# Exemplo para controladoras HP Smart Array (cciss/hpsa)
smartctl -a -d cciss,0 /dev/sda
# Para verificar todos os discos em um loop simples e filtrar erros
for i in {0..7}; do
echo "--- DISK $i ---";
smartctl -a -d megaraid,$i /dev/sda | grep -E "Reallocated_Sector|Current_Pending";
done
Callout de Risco: Rodar comandos de interrogação SMART agressivos em controladoras RAID muito antigas ou com firmware instável pode, em casos raros, causar timeouts na controladora. Teste a frequência de polling em ambiente de homologação.
Decodificando a Mentira: Normalizados vs. Raw Values
Uma vez que você obtém a saída do SMART, o próximo erro comum é a interpretação. O padrão SMART apresenta os dados em três colunas principais que confundem iniciantes: Value (Normalizado), Threshold e Raw_Value.
A tabela abaixo ilustra a diferença crítica:
| Atributo | Significado | O que o SO vê (Normalizado) | A Realidade Física (Raw) |
|---|---|---|---|
| Value (Current) | Saúde calculada pelo firmware (100-253 é bom, 1 é ruim). | Uma pontuação arbitrária (ex: 100). | Irrelevante para análise granular. |
| Threshold | O ponto onde o fabricante declara o disco "falho". | O limite da pontuação (ex: 50). | Geralmente baixo demais para ser útil. |
| Raw Value | A contagem real do evento físico. | Hexadecimal ou Decimal. | A verdade absoluta. (ex: 5 setores mortos). |
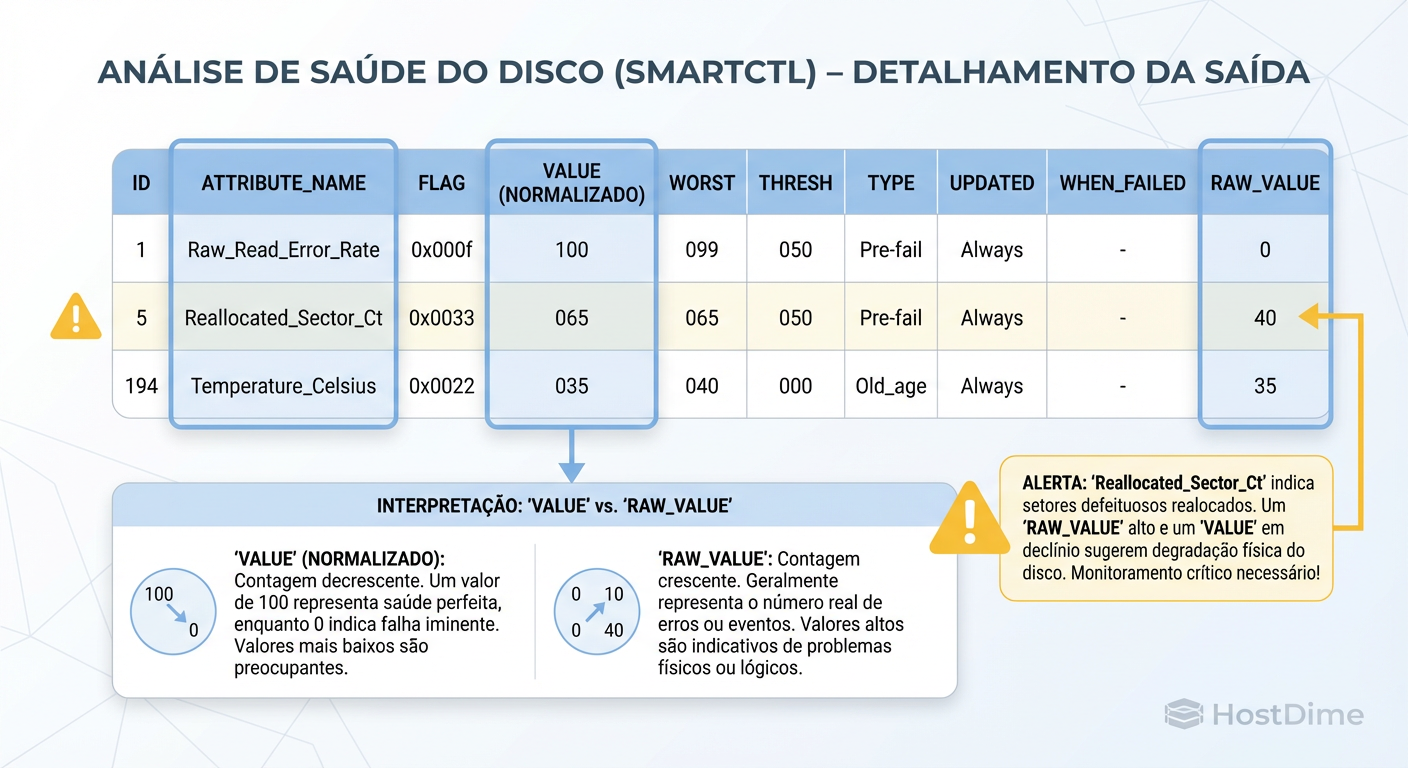 Figura: Decifrando a Tabela SMART: O perigo de olhar apenas para o valor normalizado e ignorar a contagem bruta de erros.
Figura: Decifrando a Tabela SMART: O perigo de olhar apenas para o valor normalizado e ignorar a contagem bruta de erros.
O problema é que o valor normalizado é uma "caixa preta" do fabricante. Um disco pode ter 100 setores defeituosos (Raw Value) e o firmware ainda reportar o atributo normalizado como "100" (Perfeito), porque na lógica do fabricante, 100 setores não são suficientes para acionar a garantia.
Como engenheiro, ignore o status "PASSED". Olhe para o Raw Value. Se o número de setores realocados subiu de 0 para 1, a integridade física do prato magnético foi comprometida.
Os 5 Sinais Vitais de Falha de Disco (Baseado em Backblaze)
Não perca tempo monitorando "Temperature" (a menos que seja extremo) ou "Power_On_Hours". A análise estatística de centenas de milhares de discos feita pela Backblaze isolou cinco atributos SMART que têm correlação direta com mortalidade iminente.
Se qualquer um destes valores Raw for maior que zero, o disco está em degradação.
SMART 5 (Reallocated Sector Count): O disco encontrou um erro de leitura/escrita/verificação, marcou o setor como "ruim" e moveu os dados para uma área reservada. É uma cicatriz física permanente.
SMART 187 (Reported Uncorrectable Errors): O número de erros que o hardware ECC (Error Correcting Code) do disco não conseguiu corrigir. Isso indica perda de dados que o RAID teve que mitigar.
SMART 188 (Command Timeout): O disco não respondeu a um comando a tempo. Frequentemente causado por cabos defeituosos ou falha na PCB do disco, não na mídia magnética.
SMART 197 (Current Pending Sector Count): Setores instáveis esperando para serem remapeados. O disco teve problema ao ler, mas precisa de uma escrita bem-sucedida nesse local para confirmar se o setor está morto ou se foi apenas um "soft error".
SMART 198 (Offline Uncorrectable Sector Count): Similar ao 197, mas detectado durante testes de autodiagnóstico (offline).
A Regra de Ouro: Um único setor realocado não é pânico. Um crescimento constante de setores realocados ao longo de 24 horas é uma sentença de morte.
Detecção Ativa: Patrol Read e ZFS Scrub
O SMART é passivo; ele registra erros que ocorreram durante o uso normal. Mas e os dados "frios" que estão gravados no final do disco e não são lidos há meses? Eles podem ter sofrido Bit Rot (degradação magnética) e você não saberá até tentar restaurar aquele arquivo antigo.
Para combater isso, utilizamos processos de verificação ativa.
Tabela Comparativa: Hardware vs. Software Scrubbing
| Característica | Hardware RAID (Patrol Read) | Software RAID / ZFS (Scrub) |
|---|---|---|
| Mecanismo | A controladora varre o disco em busca de setores ilegíveis. | O sistema de arquivos lê dados + paridade e verifica checksums. |
| Correção | Tenta remapear o setor. Não sabe qual arquivo foi afetado. | Corrige os dados corrompidos usando paridade/espelho automaticamente. |
| Visibilidade | Baixa. Logs proprietários da controladora. | Alta. zpool status mostra exatamente quantos bits foram corrigidos. |
| Impacto na Perf. | Configurável (ex: rodar apenas 30% de IOPS em background). | Alto impacto se não limitado via tunables (zfs_scrub_delay). |
Recomendação Operacional: Agende um Patrol Read (em controladoras HW) ou um Scrub (ZFS/MDADM) para rodar quinzenalmente ou mensalmente. Sem isso, você corre o risco de descobrir um erro URE (Unrecoverable Read Error) durante a reconstrução de um RAID degradado, o que leva à perda total do array (o temido "RAID 5 write hole" ou falha dupla).
Decisão Operacional: Quando Substituir um Disco Preventivamente?
A decisão de trocar um disco envolve um trade-off financeiro e de risco. Trocar cedo demais desperdiça orçamento; trocar tarde demais arrisca dados.
Aqui está um framework de decisão baseado em risco:
O Cenário de "Pending Sectors" (SMART 197 > 0):
- Isso é um sinal de alerta amarelo. O disco não confirmou a falha.
- Ação: Force uma escrita no disco (Scrub ou
ddse possível) para forçar o disco a resolver esses pendentes. Se eles virarem "Reallocated" (SMART 5), o dano é físico.
O Cenário de Crescimento Exponencial:
- Se
Reallocated_Sector_Countsobe de 10 para 100 em uma semana: Troque imediatamente. A superfície magnética está desintegrando (efeito avalanche).
- Se
O Cenário de Erros UDMA CRC (SMART 199):
- Isso geralmente é cabo ou backplane, não o disco. Não jogue o disco fora. Reseat (reconecte) o drive ou troque o cabo SATA/SAS.
Conclusão Pragmática: Em ambientes de produção crítica, o custo de um disco é irrelevante comparado ao custo de downtime. Adote uma política de "Tolerância Zero" para erros não corrigíveis (SMART 187). Se o disco mentiu para o SO ou falhou em corrigir um bit, ele não é mais confiável para persistência de dados. Monitore a física, ignore o status "OK" da GUI e confie nos dados brutos.
Referências & Leitura Complementar
SFF-8035i Specification: Especificação técnica original para a arquitetura de monitoramento S.M.A.R.T.
Backblaze Drive Stats Reports: Relatórios trimestrais detalhando taxas de falha por modelo e correlação com atributos SMART.
Google Whitepaper (Failure Trends in a Large Disk Drive Population): Estudo seminal sobre a falta de correlação entre temperatura e falhas, e a alta correlação com erros de scan.
Manpages:
man smartctl,man zpool-scrub.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.