Mpio No Windows Como Planejar Caminhos Corretamente

Antes de falarmos de drivers e registros, precisamos alinhar o modelo mental....
Mpio No Windows Como Planejar Caminhos Corretamente
O Policial de Trânsito Invisível
Antes de falarmos de drivers e registros, precisamos alinhar o modelo mental.
Imagine que o Windows é um armazém (o Sistema Operacional) e o Storage Array é o porto onde as mercadorias (dados) são despachadas. Entre o armazém e o porto, existem várias estradas (caminhos/paths).
Sem o MPIO, o Windows é ingênuo. Se ele vê quatro cabos conectados ao mesmo disco, ele acha que tem quatro discos diferentes. Ele montaria o volume E:, F:, G: e H:, todos apontando para os mesmos dados, o que resultaria em corrupção imediata se você tentasse escrever em dois ao mesmo tempo.
O MPIO atua como um policial de trânsito situado na saída do armazém. Ele intercepta as requisições de leitura/escrita e diz: "Espere. Esses quatro caminhos levam ao mesmo lugar. Vou apresentar apenas um disco lógico para o Windows (o volume E:), e eu cuido de qual estrada usar para cada pacote".
O problema é: como esse policial decide qual estrada usar? Ele joga uma moeda? Ele olha qual estrada está vazia? Ele sabe se a estrada tem buracos? É aqui que a maioria das implementações falha. O policial precisa de um manual de instruções, e esse manual é o DSM (Device Specific Module).
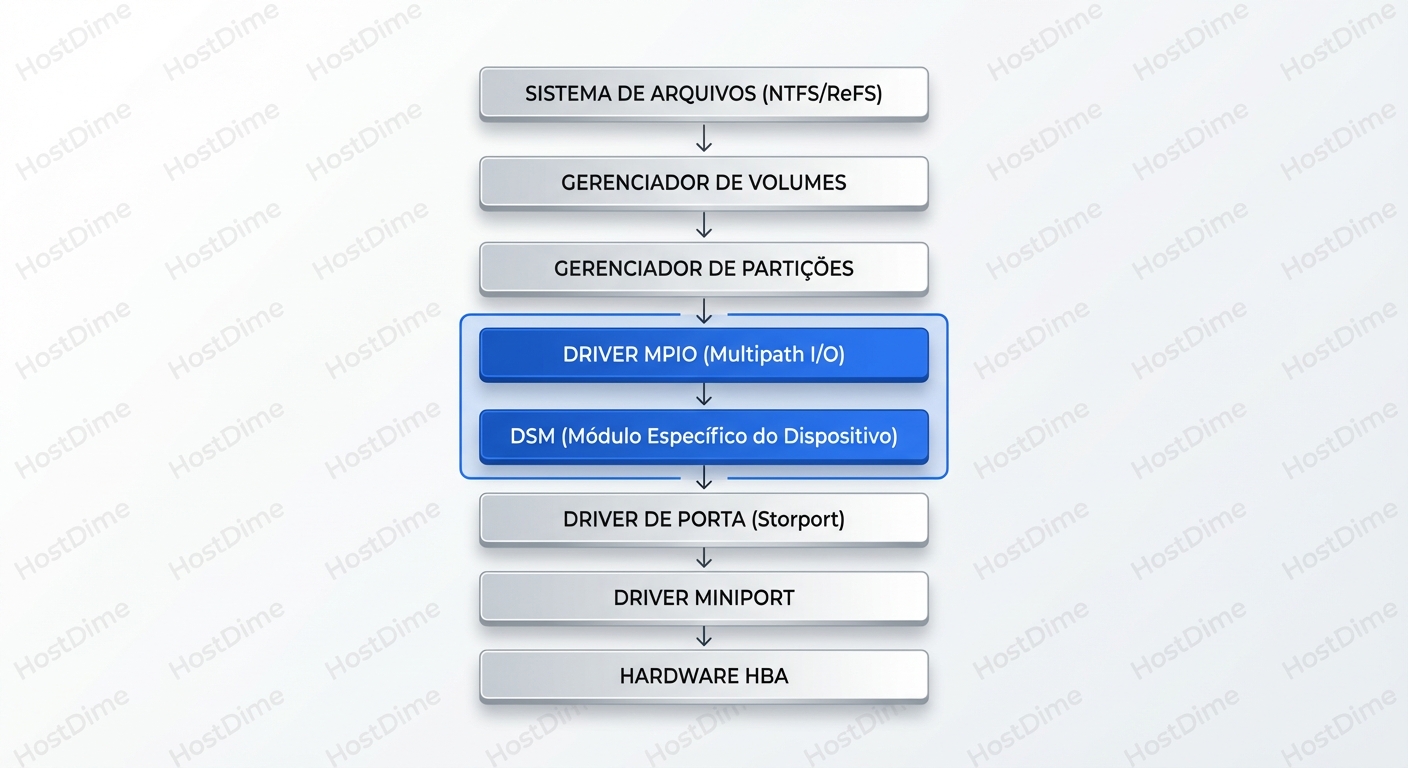
Olhando para a pilha acima, perceba que o sistema de arquivos (NTFS/ReFS) não faz ideia de que existem múltiplos caminhos. Ele fala com o Volume Manager, que fala com o Partition Manager. A mágica acontece na camada do MPIO Driver.
O MPIO Driver é genérico. Ele não sabe como falar com um storage Dell, HP, Pure ou NetApp especificamente. Ele delega a inteligência para o DSM.
- O MPIO pergunta: "Tenho este I/O. Para qual caminho envio?"
- O DSM responde: "O caminho 2 está morto e o caminho 3 é lento. Use o caminho 1."
Se você não instalar o DSM do fabricante, o Windows usa o Microsoft DSM (MSDSM). O MSDSM é competente, mas genérico. Ele suporta o padrão ALUA (Asymmetric Logical Unit Access), mas não entende nuances proprietárias de hardware, como códigos de erro específicos que indicam "estou reiniciando, espere 5 segundos" versus "estou morto para sempre".
A Camada Física: Isolamento não é Opcional
Antes de tunar o software, precisamos garantir que a física não minta para o software. O erro número um em implementações iSCSI MPIO é a falta de isolamento de sub-rede.
Se você tem duas placas de rede no servidor (NIC A e NIC B) e dois controladores no storage (Ctrl A e Ctrl B), e coloca tudo na mesma sub-rede (ex: 192.168.1.x/24), o Windows tentará ser "inteligente". O ARP pode fazer com que o tráfego destinado à NIC B saia pela NIC A. Ou pior, o tráfego de retorno do storage pode vir por um caminho assimétrico.
O MPIO precisa de caminhos determinísticos.
Para que o MPIO funcione como uma arquitetura de Alta Disponibilidade (HA) real, cada caminho deve ser um universo isolado.
- Sub-rede A: NIC Servidor 1 -> Switch A -> NIC Storage A.
- Sub-rede B: NIC Servidor 2 -> Switch B -> NIC Storage B.
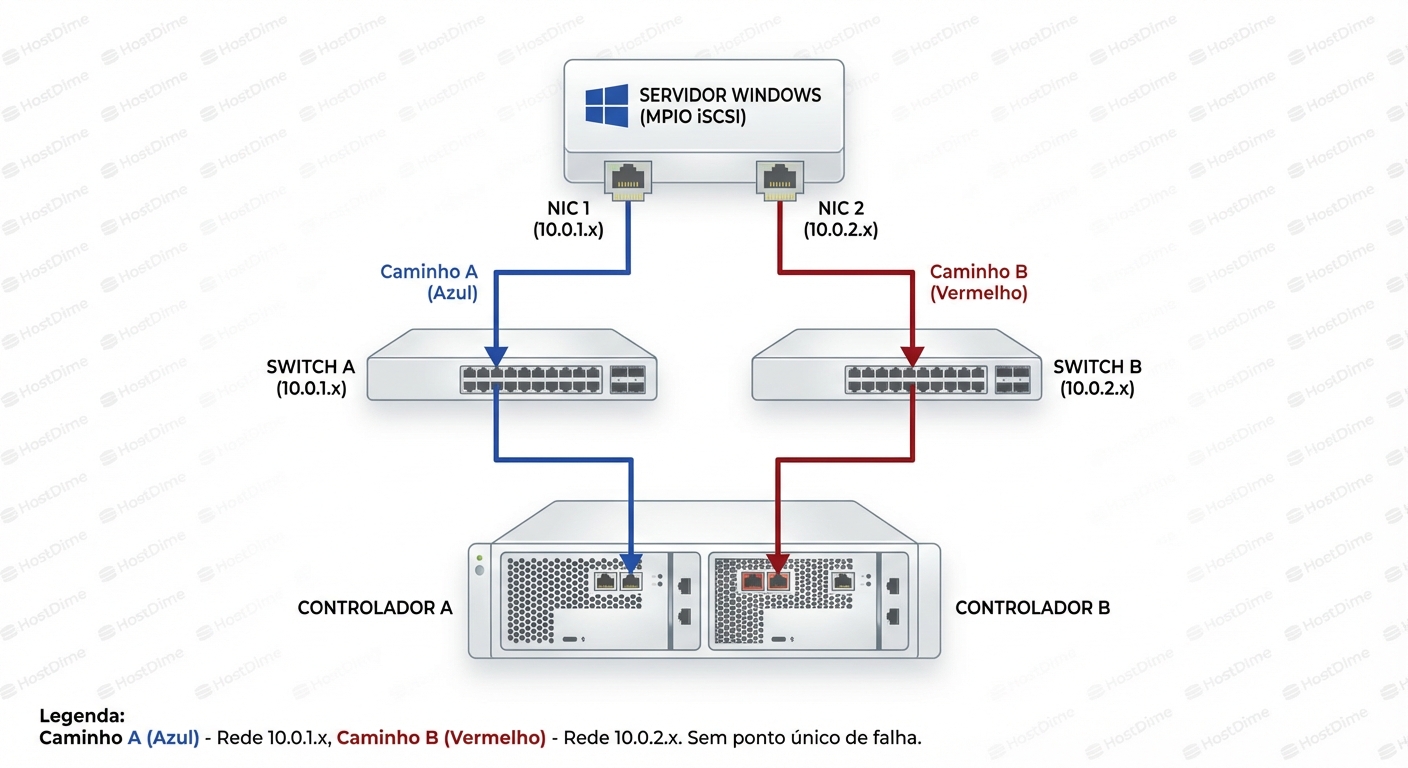
Nesta topologia, se o Switch A queimar, o caminho azul morre instantaneamente. O Windows detecta a queda do link físico imediatamente. Se tudo estivesse na mesma VLAN/Sub-rede e apenas um cabo entre switches falhasse, o TCP tentaria retransmitir, causando timeouts (o famoso "congelamento" de 30 a 60 segundos) antes do MPIO perceber que o caminho lógico morreu.
Regra de Ouro: Se o MPIO tiver que esperar um timeout de TCP para declarar um caminho como morto, sua arquitetura falhou. A falha deve ser detectada no nível do link (Link Down) ou via mensagens SCSI explícitas gerenciadas pelo DSM.
DSMs: A Guerra entre Genérico e Proprietário
Por anos, a regra era: "Sempre instale o DSM do fabricante". Hoje, a resposta é: "Depende".
Arrays modernos (All-Flash, NVMe-oF) aderem estritamente aos padrões ALUA. O Microsoft DSM (MSDSM) evoluiu muito e é o padrão para Windows Server 2019/2022.
No entanto, o DSM proprietário ainda tem valor em cenários de borda:
- Recuperação de Erros: Um DSM proprietário pode reconhecer que um erro de "Check Condition" específico do array significa que o cache está sendo destageado e que ele deve segurar o I/O na fila em vez de falhar o caminho imediatamente.
- Load Balancing Inteligente: Alguns DSMs conseguem ler a carga da CPU do controlador do storage e rotear o I/O baseando-se na saúde do array, não apenas na fila do Windows.
Como verificar qual DSM está em controle?
Não confie na GUI. Use o comando mpclaim.
mpclaim -s -d
A saída mostrará algo como:
| MPIO Disk | System Disk | LB Policy | DSM Name |
|---|---|---|---|
| MPIO Disk0 | Disk 1 | Round Robin | Microsoft DSM |
| MPIO Disk1 | Disk 2 | Failover Only | Nimble DSM |
Se você vir "Microsoft DSM" em um array que exige software proprietário, você está rodando em modo de compatibilidade básica. Isso geralmente funciona, até que a carga aumente.
Políticas de Load Balancing: Onde a Performance Morre
Aqui é onde o Sysadmin júnior configura "Round Robin" e vai embora, achando que dobrou a performance. Vamos analisar as políticas reais e quando usá-las.
1. Failover Only (Apenas Failover)
- Como funciona: Usa um caminho ativo. Os outros ficam em standby.
- Onde usar: Storages "Active-Passive" antigos.
- Problema: Desperdício total de largura de banda. Se você tem 4 cabos de 10Gbps, está usando apenas 10Gbps.
2. Round Robin (O Padrão Perigoso)
- Como funciona: O DSM envia o I/O 1 para o Caminho A, o I/O 2 para o Caminho B, e assim por diante.
- O A Lógica por Trás: Imagine um cruzamento onde o guarda manda um carro para a esquerda, um para a direita, independentemente do tamanho do carro ou do trânsito na rua.
- A Armadilha: Em storages com ALUA (Active/Optimized vs Active/Non-Optimized), o Round Robin pode enviar I/O para um controlador que não é o dono do disco. O controlador recebe o dado e tem que enviá-lo internamente para o outro controlador. Isso dobra a latência.
- A Armadilha 2: O Round Robin não considera o tamanho do I/O. Um comando de backup de 64KB pode ir para o caminho A, e um comando de log de 4KB para o caminho B. O caminho A ficará congestionado, mas o MPIO continuará mandando requisições para lá porque é "a vez dele".
3. Round Robin with Subset (O Padrão ALUA)
- Como funciona: O MPIO identifica quais caminhos são "Otimizados" (diretos ao controlador dono) e faz Round Robin apenas entre eles. Os outros ficam como backup.
- Veredito: É o mínimo aceitável para arrays modernos.
4. Least Queue Depth (LQD - A Escolha do Profissional)
- Como funciona: O DSM monitora quantos comandos estão pendentes em cada caminho. Ele envia o novo comando para o caminho com a menor fila.
- O A Lógica por Trás: Fila de supermercado. Você não entra no caixa 1 só porque o cliente anterior foi para o caixa 2. Você olha qual caixa tem menos pessoas (ou carrinhos mais vazios) e vai para lá.
- Veredito: Esta é quase sempre a melhor política para cargas de trabalho mistas (SQL, Virtualização). Ela compensa automaticamente se um caminho estiver degradado (ex: um switch com problemas de buffer ou um cabo de fibra sujo gerando retransmissões). O caminho lento naturalmente acumula fila, então o LQD para de enviar tráfego para lá. O Round Robin continuaria enviando e causando timeouts.
5. Weighted Paths (Caminhos Ponderados)
- Como funciona: Você atribui pesos manuais. "Use o caminho A 80% das vezes".
- Veredito: Evite. Requer manutenção manual constante. Se a topologia mudar, sua performance quebra.
Observabilidade: Diagnosticando o Invisível
O Task Manager mente. Ele mostra a atividade do disco lógico, não a luta interna dos caminhos. Para diagnosticar problemas de MPIO, você precisa descer o nível.
Cenário: "O disco está lento, mas o storage diz que está tudo bem"
Passo 1: Validar o Balanceamento Abra o PowerShell e verifique se o tráfego está realmente sendo distribuído ou se está "colado" em um caminho ruim.
# Verifique a política atual e o estado dos caminhos
Get-MpioPath -PathId "0000000000000001" # ID obtido via Get-MpioDisk
Procure por State: Active/Optimized. Se você vir Active/Unoptimized recebendo tráfego, sua configuração de ALUA ou zoneamento está errada.
Passo 2: Performance Monitor (A Verdade)
Adicione os contadores corretos. Esqueça PhysicalDisk.
- Objeto:
MPIO Path(não disponível por padrão em todas as versões, às vezes aparece como contadores de adaptador iSCSI/FC). - Se não houver contadores MPIO diretos, olhe para os contadores da Interface de Rede (para iSCSI) ou Adaptador FC.
Compare Output Queue Length entre as interfaces.
- NIC 1: Queue 0
- NIC 2: Queue 0
- NIC 3: Queue 55 (Problema aqui!)
- NIC 4: Queue 0
Se você usa Least Queue Depth, isso não deveria acontecer. Se usa Round Robin, isso indica que o caminho 3 está processando mais lentamente que os outros (talvez erros de CRC no cabo), e o MPIO continua martelando ele.
Passo 3: Logs do MPIO
O Windows não loga trocas de caminho no Event Viewer "System" por padrão de forma verbosa. Você precisa olhar em:
Applications and Services Logs -> Microsoft -> Windows -> MPIO -> Operational.
Procure por eventos de "Path Failover". Se você vir failovers acontecendo a cada 5 minutos, você tem um link "flapping" (oscilando). Isso destrói a performance porque cada failover pausa o I/O momentaneamente para reordenar a fila.
Tuning Avançado: Timers e o Registro
Às vezes, o padrão do Windows é conservador demais. Em ambientes de alta performance, esperar 60 segundos por um timeout é inaceitável.
Atenção: Alterar isso requer cuidado. Valores muito baixos podem causar desconexões em momentos de latência transitória de rede.
Chaves de registro críticas em HKLM\SYSTEM\CurrentControlSet\Services\Disk:
| Valor | Descrição | Padrão | Recomendação (Agressiva) |
|---|---|---|---|
TimeOutValue |
Quanto tempo o Windows espera por uma resposta SCSI antes de abortar. | 60s | 20-30s (Para SQL/Cluster) |
E nas configurações do MPIO (HKLM\SYSTEM\CurrentControlSet\Services\mpio\Parameters):
| Valor | Descrição | Padrão | Cenário |
|---|---|---|---|
PathRecoveryInterval |
Com que frequência o MPIO tenta ressuscitar um caminho morto. | N/A | Defina se o storage demora a voltar. |
PDORemovePeriod |
Quanto tempo o MPIO mantém o dispositivo na memória após perder todos os caminhos antes de dizer ao OS "o disco sumiu". | ~60s | Aumente se o boot do storage for lento. |
O Caso Específico do iSCSI: O "Binding" Esquecido
Um erro clássico em iSCSI MPIO no Windows é deixar o "Binding" automático.
Quando você configura o iSCSI Initiator, na aba "Targets" -> "Connect", existe um botão "Advanced". A maioria clica em OK e ignora.
Para MPIO funcionar corretamente, você deve conectar o Target múltiplas vezes (uma para cada caminho) e, em cada conexão, usar o botão "Advanced" para forçar:
- Source IP: IP da NIC A
- Target Portal: IP do Controller A
Se você deixar como "Default", o Windows pode decidir rotear o tráfego da Conexão 2 (que deveria ser redundante) pela mesma NIC da Conexão 1. Resultado: Você vê duas conexões no console, mas fisicamente tudo passa pelo mesmo cabo. Se esse cabo cair, você perde ambos os caminhos.
Use o PowerShell para auditar isso:
Get-IscsiConnection | Select-Object InitiatorAddress, TargetAddress, ConnectionIdentifier
Você deve ver pares distintos de IPs de origem e destino. Se todos os InitiatorAddress forem iguais, seu MPIO é uma mentira.
Veredito: MPIO é Gerenciamento de Risco
Configurar MPIO não é apenas sobre "ligar e funcionar". É sobre definir como seu sistema reage sob estresse.
- Isolamento Físico: Seus caminhos devem ser independentes. Sem isso, o software não pode salvar você.
- Política de Balanceamento: Use Least Queue Depth (ou Round Robin with Subset) para a maioria das cargas modernas. Evite Round Robin simples em arrays complexos.
- Observabilidade: Monitore as filas por caminho, não apenas a latência do volume. Um único caminho doente pode derrubar todo o cluster se a política de balanceamento não for inteligente.
O MPIO bem configurado é silencioso. Ele absorve falhas de cabos, reboots de switch e atualizações de firmware do storage sem que o SQL Server sequer perceba um aumento na latência. O MPIO mal configurado transforma uma falha de um único cabo em uma interrupção de serviço completa. Escolha qual cenário você quer depurar na próxima terça-feira às 14h.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.