Mtu Mss E Fragmentacao Impacto Em Storage Na Rede

Para um Sysadmin Sênior, a rede não é um tubo contínuo de dados. É uma série de eventos discretos. Cada pacote que entra ou sai da interface de rede (NIC) é um ...
Mtu Mss E Fragmentacao Impacto Em Storage Na Rede
A Física do Overhead: Por que o Tamanho Importa
Para um Sysadmin Sênior, a rede não é um tubo contínuo de dados. É uma série de eventos discretos. Cada pacote que entra ou sai da interface de rede (NIC) é um evento que exige atenção.
Imagine que você precisa enviar 1 GB de dados.
Em uma rede Ethernet padrão (MTU 1500 bytes), a carga útil máxima (MSS - Maximum Segment Size) para TCP é tipicamente 1460 bytes (1500 - 20 bytes IP - 20 bytes TCP). Para enviar aquele 1 GB, o kernel precisa criar, e a NIC precisa serializar, aproximadamente 715.000 pacotes.
Se ativarmos Jumbo Frames (MTU 9000 bytes), o MSS salta para cerca de 8960 bytes. Para o mesmo 1 GB, agora precisamos de apenas 119.000 pacotes.
Essa é uma redução de 6x na quantidade de eventos. Mas por que isso importa se temos largura de banda de sobra? Porque a largura de banda é barata, mas os ciclos de CPU e as interrupções de hardware são caros.
O Custo Oculto da Interrupção
Cada pacote que chega à NIC gera uma interrupção de hardware (ou consome um ciclo de polling se estivermos usando drivers modernos com NAPI). A CPU precisa parar o que está fazendo, salvar o contexto, processar o cabeçalho do pacote, copiar os dados do buffer do anel da NIC para o sk_buff do kernel, subir a pilha TCP/IP, e finalmente entregar os dados à aplicação (o iniciador iSCSI ou driver NVMe).
Mesmo com tecnologias como LRO (Large Receive Offload) e TSO (TCP Segmentation Offload), onde a placa de rede tenta agrupar pacotes antes de incomodar a CPU, a granularidade de 1500 bytes impõe um teto rígido na eficiência. Em redes de armazenamento de alta performance (NVMe-oF), onde a latência é medida em microssegundos, o tempo gasto processando cabeçalhos repetidos de 40 bytes torna-se uma porcentagem significativa da latência total.
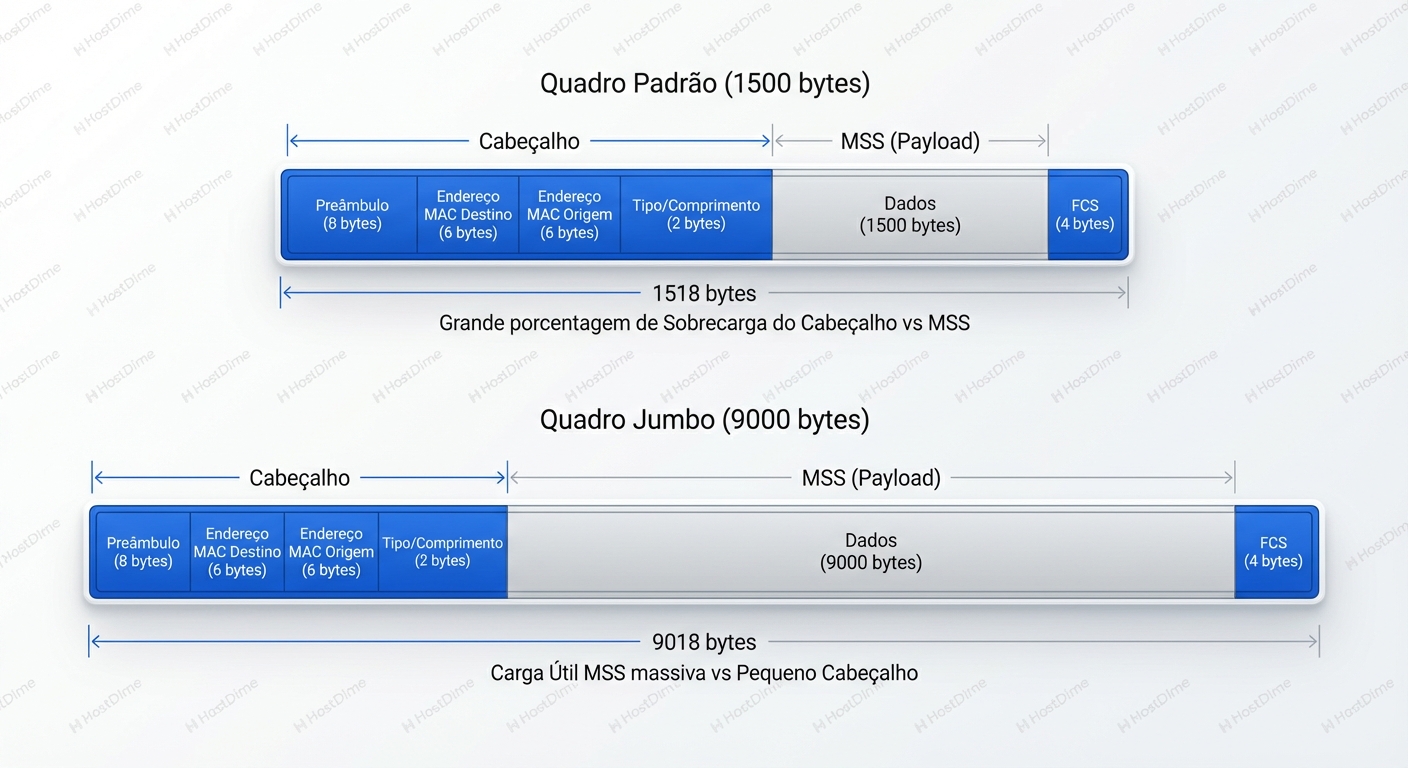
A imagem acima ilustra a proporção. No cenário padrão, estamos desperdiçando ciclos de CPU processando cabeçalhos e preâmbulos Ethernet repetidamente. Com Jumbo Frames, a proporção de "Payload Útil" versus "Overhead de Protocolo" inverte drasticamente a favor dos dados. Em Storage, onde movemos blocos massivos de dados, essa eficiência é a diferença entre saturar um link de 100GbE ou ficar preso em 40GbE devido ao gargalo da CPU.
Anatomia da Negociação: MTU vs. MSS
Aqui é onde a confusão começa e onde a maioria das implementações falha. Existe uma distinção vital entre o que a Camada 2 (Ethernet) aceita e o que a Camada 4 (TCP) decide enviar.
- MTU (Layer 2/3): É o limite físico da estrada. "Nesta estrada não passam veículos com mais de 1500 (ou 9000) bytes de largura". Isso é configurado na interface e no switch.
- MSS (Layer 4): É o tamanho da carga do caminhão. Durante o Handshake de três vias do TCP (SYN, SYN-ACK, ACK), os dois lados dizem um ao outro: "Eu consigo receber segmentos de até X bytes".
O Modelo Mental do Handshake:
- Servidor A (Storage): MTU 9000. Envia SYN com opção TCP
MSS=8960. - Servidor B (Host): MTU 1500 (configuração esquecida/errada). Recebe o SYN.
- Servidor B: Responde SYN-ACK. Ele vê que A aceita 8960, mas B sabe que sua própria interface só aguenta 1500. Então, B diz: "Ok, mas meu
MSS=1460".
O protocolo TCP, sendo educado e robusto, vai operar pelo menor denominador comum. A conexão será estabelecida com MSS de 1460 bytes. O resultado? Você tem Jumbo Frames habilitados no Storage e no Switch, mas o Host força todo o tráfego a ser fragmentado logicamente em pedaços pequenos. Você não tem erros de rede, mas também não tem a performance de Jumbo Frames. É um desperdício silencioso de configuração.
O Vilão: Fragmentação IP e o Bit DF
O cenário acima (negociação de MSS correta para o menor valor) é o "melhor caso de falha". O sistema funciona, mas lento. O pesadelo real acontece quando a negociação falha ou quando protocolos sem conexão (como UDP em alguns cenários de armazenamento legado ou NFS sobre UDP) entram em jogo, ou pior, quando o Path MTU Discovery (PMTUD) quebra.
A fragmentação IP ocorre quando um roteador ou host precisa enviar um pacote maior do que o MTU da próxima interface. Ele divide o pacote em dois (ou mais). Isso soa como uma feature, mas em 2024, é um bug de arquitetura.
Por que a fragmentação destrói a performance de Storage:
- Esforço da CPU (Reassembly): O receptor deve armazenar os fragmentos na memória até que todos cheguem para reconstruir o pacote original. Isso consome memória e CPU.
- A Regra do "Tudo ou Nada": Se um pacote de 9000 bytes é fragmentado em 6 pedaços de 1500, e um desses pedaços é perdido na rede (congestionamento, erro de CRC), o receptor descarta todo o pacote original de 9000 bytes. O remetente precisa retransmitir tudo. Em redes congestionadas, isso cria um ciclo de feedback positivo de retransmissões que pode colapsar o link (Goodput vai a zero).
- Firewalls Odeiam Fragmentos: Muitos firewalls modernos descartam fragmentos IP por padrão porque eles são vetores históricos de ataques de evasão e DoS (como o ataque Teardrop).
O Buraco Negro (Black Hole)
Para evitar a fragmentação, o TCP moderno usa o bit DF (Don't Fragment) no cabeçalho IP. Ele diz aos roteadores/switches: "Se este pacote for grande demais para passar, não o fragmente. Jogue fora e me avise".
O mecanismo esperado (PMTUD) é:
- Host envia pacote de 9000 bytes com DF setado.
- Switch/Roteador intermediário tem MTU 1500.
- Switch descarta o pacote.
- Switch envia de volta uma mensagem ICMP Type 3, Code 4 ("Fragmentation Needed and DF set"), informando o MTU correto (Next-Hop MTU).
- Host recebe o ICMP, ajusta o tamanho do pacote e tenta de novo.
O Problema: Sysadmins zelosos ou configurações de segurança padrão frequentemente bloqueiam ICMP no firewall.
Se o servidor não receber o ICMP Type 3 Code 4, ele não sabe que o pacote foi dropado. Ele acha que o pacote se perdeu e tenta reenviar o mesmo pacote gigante. E de novo. E de novo. A conexão TCP trava. O comando iscsiadm -m discovery pendura para sempre.
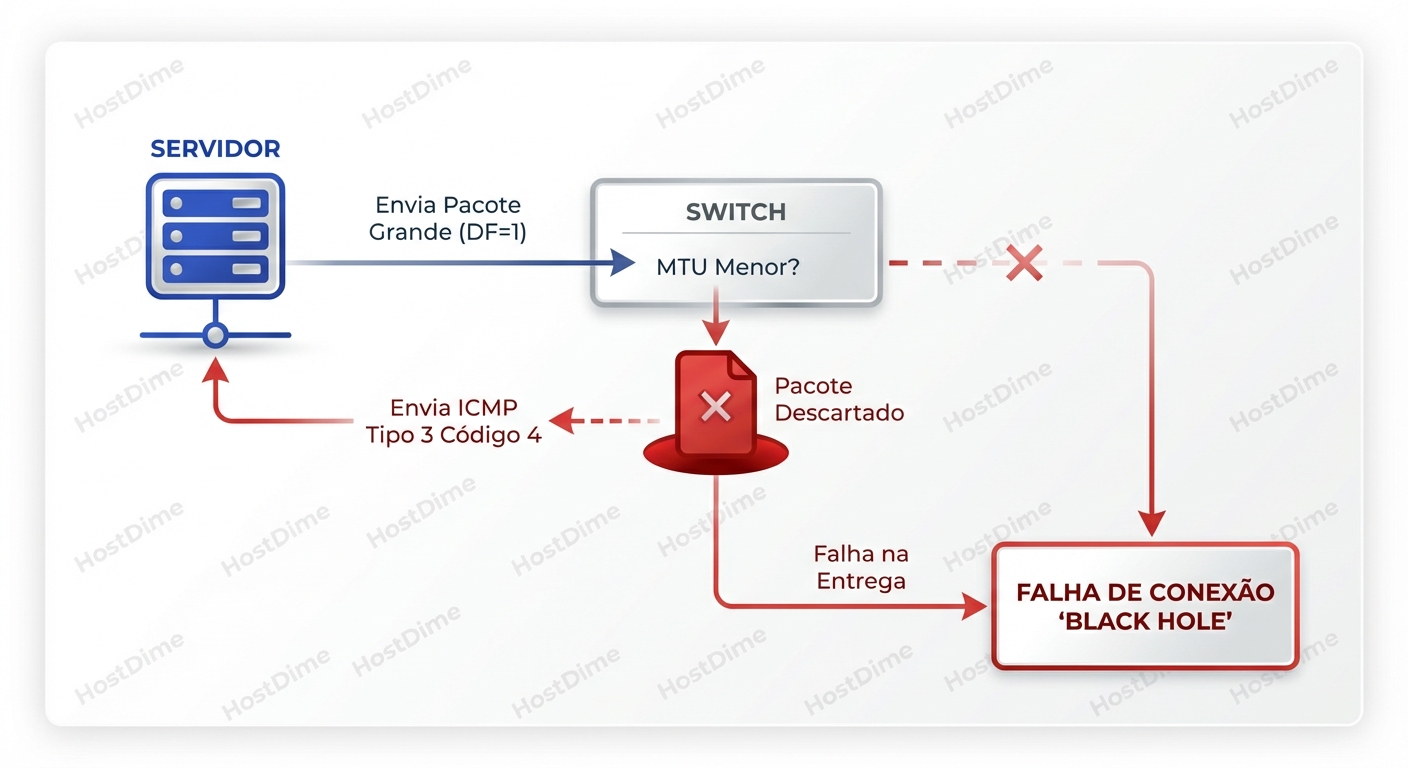
Este diagrama de fluxo ilustra o "Buraco Negro". É a causa número um de chamados onde "o ping funciona (porque o ping padrão é pequeno), mas a aplicação não conecta".
Diagnóstico de Campo: Comandos e Interpretação
Não vamos apenas rodar comandos; vamos interrogar o sistema.
1. Verificação de Camada 2 e Configuração
Primeiro, a sanidade básica. O que a interface acha que está fazendo?
ip -d link show eth0
O que procurar: O valor de mtu. Se estiver 1500 em uma rede de storage, pare aqui. Mas olhe também para qdisc. Em interfaces de alta velocidade, configurações de fila padrão podem ser gargalos, mas isso é assunto para outro artigo.
2. O Teste Definitivo de PMTUD (Ping com esteroides)
O ping comum engana. Você precisa simular um payload de dados.
Linux:
# -s 8972: Tamanho do payload (8972 + 8 ICMP + 20 IP = 9000 bytes)
ping -M do -s 8972 <IP_DO_STORAGE>
Windows:
ping -f -l 8972 <IP_DO_STORAGE>
Interpretação:
- Sucesso: O caminho inteiro suporta Jumbo Frames.
- "Message too long" (Linux) / "Packet needs to be fragmented" (Windows): A sua própria interface está com MTU menor que o pacote.
- Timeout (Perda de 100%): Aqui está o perigo. O pacote saiu da sua interface, mas morreu no caminho. Algum switch no meio tem MTU baixo E não retornou ICMP (ou o ICMP foi bloqueado). Isso é um Black Hole.
3. Tracepath: O Raio-X do Caminho
O tracepath é superior ao traceroute para este diagnóstico porque ele tenta descobrir o MTU de cada salto.
tracepath <IP_DO_STORAGE>
Saída Crítica: Procure por linhas que dizem pmtu 1500 logo após uma linha que dizia pmtu 9000. Isso identifica exatamente qual switch/roteador está "estrangulando" o tráfego.
4. Tcpdump: Analisando o Handshake MSS
Se a conexão estabelece, mas a performance é ruim, verifique a negociação MSS.
tcpdump -i eth0 -nn -v "tcp[tcpflags] & (tcp-syn) != 0" and host <IP_STORAGE>
O que procurar:
Olhe para as opções TCP na saída: options [mss 8960,...].
- Se você vê
mss 8960indo e voltando: Ótimo. - Se você vê
mss 1460: Um dos lados (ou um dispositivo intermediário fazendo MSS Clamping) forçou o tamanho baixo. Jumbo Frames não estão sendo usados efetivamente.
5. Nstat e Netstat: Contando os Corpos
Verifique se há fragmentação ou remontagem falha acontecendo no host.
nstat -az | grep -E 'IpReasm|IpFrag'
IpReasmFails: Se este número estiver subindo, você tem um problema grave. Pacotes estão chegando fragmentados e o kernel não consegue remontá-los (timeout ou corrupção).IpFragOKs: Se este número sobe, você está fragmentando com sucesso. Isso não é um erro, mas é um sinal de performance degradada. Em uma SAN ideal, isso deveria ser zero.
Storage Específico: iSCSI vs. NVMe/TCP vs. RoCE
O impacto do MTU varia dependendo do protocolo de transporte.
| Protocolo | Dependência de Jumbo Frames | Comportamento na Falha de MTU |
|---|---|---|
| iSCSI | Alta. O iSCSI encapsula comandos SCSI em TCP. O overhead de empacotamento em 1500 bytes consome muita CPU (softirq) em velocidades >10Gbps. | Degradação de throughput. Aumento de latência da CPU. Funciona, mas "engasga". |
| NVMe/TCP | Crítica. O NVMe é projetado para paralelismo massivo. O overhead de cabeçalho TCP/IP padrão anula os ganhos de latência do protocolo NVMe. | Similar ao iSCSI, mas a perda de performance relativa é maior porque o protocolo base é mais eficiente. O gargalo da rede torna-se mais óbvio. |
| NVMe-oF (RoCE v2) | Existencial. RDMA (Remote Direct Memory Access) exige uma rede "Lossless". | O RoCE v2 é extremamente sensível. Se houver fragmentação, a performance colapsa. Se o MTU estiver errado, o PFC (Priority Flow Control) pode entrar em ação erroneamente, pausando toda a rede. Em RoCE, MTU incorreto geralmente significa nenhuma conectividade, não apenas lentidão. |
A Armadilha: Quando NÃO usar Jumbo Frames
Depois de ler isso, o instinto é "habilitar MTU 9000 em tudo". Não faça isso.
Jumbo Frames quebram a regra de ouro da interoperabilidade da Internet. A Internet é MTU 1500. Se você tem um servidor que precisa falar com o Storage (9000) e com a Internet (1500) na mesma interface, você está criando um cenário complexo para o kernel gerenciar.
Riscos e Cenários de Evitar:
- Ambientes Mistos na Mesma VLAN: Se você tem dispositivos legados que não suportam Jumbo na mesma VLAN de broadcast, você terá problemas de comunicação esporádicos.
- Links WAN/VPN: Nunca tente passar Jumbo Frames por túneis VPN ou links WAN a menos que você controle cada centímetro da fibra. A fragmentação será garantida e a performance será pior do que com 1500.
- Cloud Pública: Na AWS, Azure e GCP, Jumbo Frames são suportados dentro da VPC, mas se o tráfego sair para a Internet ou para certos serviços gerenciados, o MTU cai. A AWS usa MTU 9001, o Azure 9000. Essa diferença de 1 byte pode causar dores de cabeça se você não estiver atento ao MSS Clamping.
Veredito: Consistência é a Única Solução
O "Assassino Silencioso" não é o MTU 1500. Você pode rodar uma rede de storage perfeitamente estável com MTU 1500, desde que aceite o custo de CPU mais alto. O assassino é o MTU Mismatch.
O segredo para uma infraestrutura de storage de alta performance não é apenas "ligar o Jumbo Frames". É garantir a consistência end-to-end:
- Iniciador (Host)
- Switch de Acesso
- Switch Core/Spine
- Target (Storage Array)
Todos devem cantar a mesma música. Se um único elemento desafinar, o TCP vai gastar mais tempo tentando consertar o fluxo do que movendo seus dados.
Ao diagnosticar lentidão em iSCSI ou NVMe-oF, antes de culpar os discos flash ou o código da aplicação, faça um favor a si mesmo: verifique o tamanho dos seus pacotes. Use o ping -M do. Olhe os contadores de reassembly. A solução para o seu problema de banco de dados pode estar em um simples ajuste de cabeçalho Ethernet.

Dr. Marcus 'Bitrot' Silva
Engenheiro Sênior de Armazenamento
20 anos recuperando RAIDs quebrados. Especialista em ZFS e sistemas de arquivos distribuídos. Já viu mais falhas de disco do que gostaria.