Network Jitter vs. Storage Distribuído: O Assassino de Performance Oculto
Alta largura de banda não salva seu cluster se a variância da latência (jitter) estiver alta. Entenda como o jitter na rede mata a performance de IOPS em Ceph, vSAN e iSCSI.
Você comprou os switches de 10Gbps (ou 25Gbps). Encheu os servidores com NVMe. Configurou o Ceph, vSAN ou GlusterFS com orgulho. No papel, o cluster deveria voar. Na prática, o banco de dados está engasgando, o load average está alto e os desenvolvedores estão abrindo chamados reclamando de "disco lento".
Você olha os gráficos de utilização de banda: 20% de ocupação. O disco? Nem suou. O que está acontecendo?
Bem-vindo ao inferno do Jitter de Rede. A maioria dos administradores foca obsessivamente em Throughput (largura de banda) e Latência Média. Mas em sistemas de storage distribuído, a variância da latência (jitter) é o verdadeiro assassino silencioso. Um link de 10Gbps instável é infinitamente pior para um banco de dados transacional do que um link de 1Gbps sólido como uma rocha. Vamos dissecar o porquê, como provar isso e como mitigar o problema sem gastar o orçamento do ano que vem em RDMA (a menos que precise).
O que é Network Jitter no Storage?
Network Jitter (Variação de Atraso de Pacotes) é a inconsistência no tempo que os dados levam para viajar entre nós. Em sistemas de storage distribuído com replicação síncrona (como Ceph ou vSAN), o jitter causa o travamento das operações de gravação (I/O), pois o cluster deve esperar pela confirmação da réplica mais lenta antes de liberar a aplicação. Isso transforma micro-picos de latência na rede em paralisia de disco no sistema operacional.
A Ilusão da Banda Larga e o Impacto no Storage Distribuído
Existe uma falácia perigosa no mercado: "Se está lento, precisamos de mais banda". Isso raramente é verdade para cargas de trabalho de IOPS (Input/Output Operations Per Second).
Imagine uma rodovia de 10 faixas (10Gbps). Se os carros (pacotes) fluem a 100km/h constantemente, você tem alta vazão e baixa latência. Agora, imagine essa mesma rodovia onde, a cada 10 segundos, o trânsito para completamente por 200 milissegundos e depois volta a correr. A "média" de velocidade ainda pode parecer boa, mas se você está transportando nitroglicerina (dados síncronos), essa parada brusca é catastrófica.
Bancos de dados e sistemas de arquivos distribuídos dependem de consistência temporal. Quando você grava um bloco de dados, o sistema operacional bloqueia o processo até receber um ACK (confirmação). Se a rede entrega 99 pacotes em 0.1ms, mas o centésimo pacote demora 50ms devido a jitter (buffer bloat no switch, colisão, ou CPU do switch ocupada), a aplicação sente uma "travada".
Para o storage, consistência é rei. Velocidade bruta com alta variância é inútil para produção.
O Custo da Replicação Síncrona e o Efeito Comboio
A maioria dos sistemas de storage modernos (HCI, Ceph, vSAN) utiliza replicação síncrona para garantir durabilidade. Se você define Replica=3, o dado é gravado no nó local e enviado simultaneamente para outros dois nós via rede.
Aqui entra a física cruel: A operação de escrita só é confirmada quando a réplica MAIS LENTA responder.
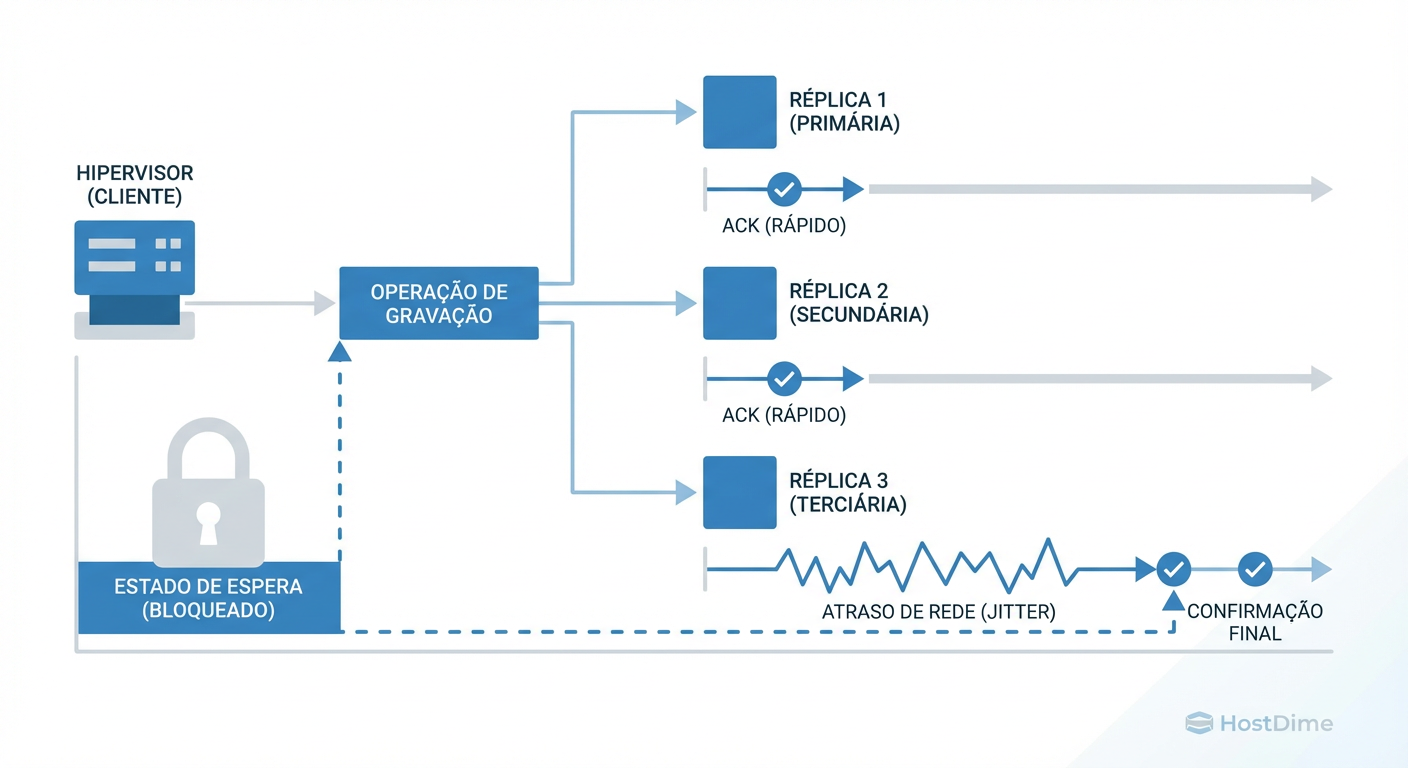 Figura: Figura 1: O Efeito Comboio na Replicação Síncrona. O Hypervisor permanece travado (I/O Wait) até que a réplica mais lenta, afetada pelo jitter, confirme a gravação.
Figura: Figura 1: O Efeito Comboio na Replicação Síncrona. O Hypervisor permanece travado (I/O Wait) até que a réplica mais lenta, afetada pelo jitter, confirme a gravação.
Se o Nó A e o Nó B respondem em 1ms, mas o Nó C sofre um pico de jitter e responde em 100ms, a latência de escrita percebida pelo servidor (e pelo usuário final) será de 100ms. O sistema todo nivela por baixo. Isso é o "Write Penalty" amplificado pela rede.
Em clusters grandes, a probabilidade estatística de algum nó ou porta de switch estar sofrendo jitter em um dado momento aumenta exponencialmente. Se sua rede não for determinística, seu storage distribuído será apenas uma coleção cara de discos esperando por pacotes atrasados.
Sintomas no Hypervisor: Identificando I/O Wait e Latência de Rede
O aspecto mais frustrante do jitter é que ele se mascara de problema de disco. Quando o hypervisor (ESXi, Proxmox/KVM) ou o SO Guest fica esperando a confirmação da rede para dar o ACK da gravação, a CPU entra em estado de I/O Wait (iowait).
O que procurar no monitoramento:
CPU Ociosa, Load Alto: O comando
topmostra CPUid(idle) alta, maswa(wait) alto. O sistema não está processando, está esperando.Filas de Disco (Queue Depth): As filas de disco aumentam não porque o NVMe é lento, mas porque o protocolo de rede (iSCSI, RBD, vSAN traffic) não retornou.
Timeouts de Aplicação: O banco de dados desconecta ou a aplicação web dá erro 504, mas não há erros nos logs do disco físico (
dmesglimpo de erros SCSI locais).
Aviso de Perigo: Se você vir latência de disco alta no hypervisor, não assuma imediatamente que o SSD falhou. Verifique se a latência de rede entre os nós de storage correlaciona com os picos de latência de disco.
Por que o Ping Mente: Métricas Reais para Diagnosticar Jitter
O comando ping é a ferramenta mais mal interpretada da história. Ele usa ICMP. Switches e roteadores frequentemente tratam ICMP com a menor prioridade possível na CPU do control plane. Além disso, o ping mostra a média por padrão.
A média é uma mentira estatística em sistemas de tempo real. Se eu colocar uma mão no congelador e outra no fogo, na média, minha temperatura está ótima.
O Histograma de Latência
Você precisa olhar para os percentis: P95, P99 e P99.9.
P50 (Mediana): O comportamento normal.
P99: Onde o jitter se esconde. Significa que 1% das suas requisições são lentas. Em um banco de dados fazendo 10.000 IOPS, 1% significa 100 travamentos por segundo.
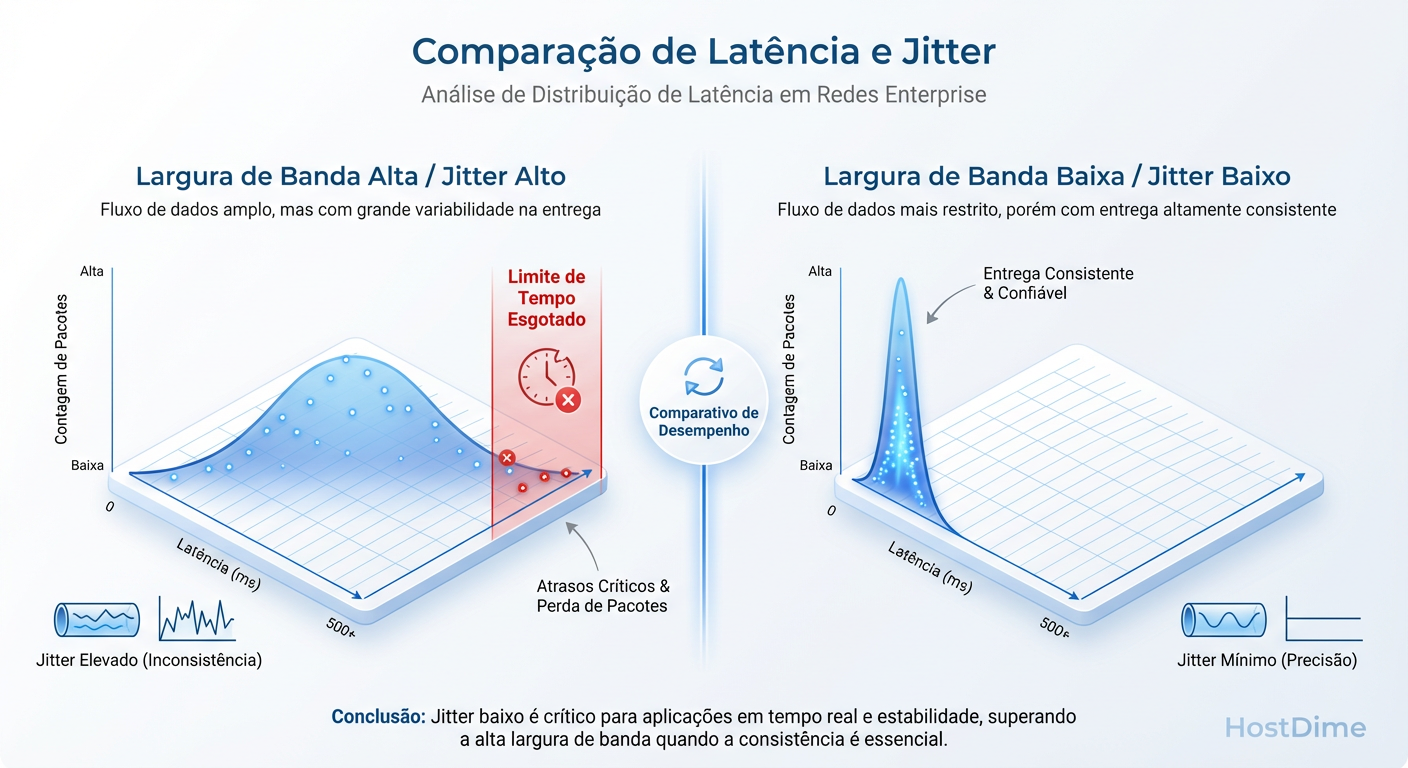 Figura: Figura 2: Distribuição de Latência (Histograma). A consistência (gráfico à direita) é preferível à velocidade média com alta variância (gráfico à esquerda), pois evita timeouts de aplicação.
Figura: Figura 2: Distribuição de Latência (Histograma). A consistência (gráfico à direita) é preferível à velocidade média com alta variância (gráfico à esquerda), pois evita timeouts de aplicação.
Como medir de verdade (iperf3 com UDP)
Para ver o jitter, pare de usar ICMP e pare de testar apenas TCP (que mascara perda de pacotes com retransmissão). Use o iperf3 em modo UDP. O UDP não retransmite, então o iperf pode medir exatamente quanto o pacote atrasou ou se foi perdido.
iperf3 -s
# No Cliente (Emissor - simulando tráfego de storage)
# -u: UDP
# -b 1G: Tenta empurrar 1Gbps constante (ajuste conforme seu link)
# -t 30: Teste de 30 segundos
iperf3 -c <IP_DO_SERVIDOR> -u -b 1G -t 30
O que analisar na saída:
Jitter (ms): Deve ser próximo de zero (< 0.05ms em LAN). Se estiver em 2ms ou 10ms em uma LAN, seu storage vai sofrer.
Lost/Total Datagrams: Qualquer perda de pacote em uma rede de storage local é inaceitável. Perda de pacote = Retransmissão TCP = Latência multiplicada por 2 ou 3.
Mitigação de Jitter: Hardware, Flow Control e Configurações
Não existe mágica, existe engenharia. Se você confirmou que o jitter está matando seu storage, aqui estão as áreas de intervenção, ordenadas do "ajuste lógico" para a "troca de hardware".
1. Flow Control (Pause Frames)
Ethernet Flow Control (802.3x) permite que um nó diga ao switch "pare de mandar dados, estou cheio". Em teoria, evita perda de pacotes. Na prática, pode causar o "Head-of-Line Blocking", onde o switch para o tráfego para todos por causa de um nó lento.
- Veredito: Em redes modernas de alta velocidade (10G+), geralmente recomenda-se DESLIGAR o Flow Control global e confiar nos buffers do switch ou usar Priority Flow Control (PFC) se estiver usando RoCE/DCB.
2. Buffers de Switch: Deep vs. Shallow
Muitos switches "10Gbps baratos" são feitos para tráfego de escritório, não storage. Eles têm buffers pequenos (Shallow Buffers). Quando ocorre um "Microburst" (vários servidores gravando ao mesmo tempo), o buffer enche e o switch descarta pacotes.
Sintoma: Jitter alto e retransmissões TCP durante picos de escrita.
Solução: Switches "Deep Buffer" (ex: baseados em chipset Jericho) ou configurar QoS agressivo para priorizar o tráfego de storage.
3. Offloading (TSO/LRO)
As placas de rede modernas tentam ajudar a CPU fazendo o trabalho pesado (TCP Segmentation Offload).
O Risco: Às vezes, o hardware da NIC segura pacotes para agrupar em um lote maior (coalescing) para economizar interrupções de CPU. Isso aumenta a latência e o jitter.
Ação: Se a latência é crítica, experimente desativar o Interrupt Coalescing (adaptative-rx/tx) via
ethtool. Você troca maior uso de CPU por menor latência.
Tabela Comparativa: Onde o Jitter Nasce
| Componente | Cenário de Risco | Impacto no Jitter | Solução Típica |
|---|---|---|---|
| Switch (Buffer) | Microbursts (Muitos nós gravando simultaneamente) | Crítico. Descarte de pacotes gera retransmissão TCP (latência x3). | Switches Deep Buffer ou QoS (DSCP/CoS). |
| Cabeamento | Cabos CAT6/Fibra dobrados ou sujos (CRC Errors) | Alto. Frames corrompidos são descartados silenciosamente. | Limpeza de fibra, troca de cabos, verificar contadores de erro na porta. |
| NIC (Offload) | Interrupt Coalescing agressivo para economizar CPU | Médio. NIC "segura" pacotes para enviar em lote. | Ajuste de ethtool -C (Adaptive RX/TX off). |
| Protocolo | TCP padrão em redes congestionadas | Médio/Alto. Algoritmo de congestionamento reduz janela agressivamente. | TCP BBR, Jumbo Frames (MTU 9000) ou migrar para RDMA/RoCE. |
Veredito Técnico Pragmática
Não confie na etiqueta da caixa do switch. Um link de 10Gbps com 5ms de jitter é pior que um link de 1Gbps com 0.1ms de jitter para storage distribuído.
Se o seu storage está lento:
Pare de olhar a média do ping.
Use
iperf3 -ue procure por jitter e perda de pacotes.Verifique se seus switches estão descartando pacotes por falta de buffer.
Lembre-se: O nó mais lento dita a velocidade de todo o cluster.
Referências & Leitura Complementar
RFC 2544: Benchmarking Methodology for Network Interconnect Devices (Define metodologias padrão para medir latência e jitter).
Ceph Documentation - Network Configuration: Recomendações oficiais sobre MTU e separação de redes Cluster/Public.
VMware vSAN Network Design Guide: Detalhes sobre requerimentos de buffer de switch e Multicast vs Unicast.
Breandan Gregg, "Systems Performance": Capítulo sobre Network e Latency Analysis.

André Bastos
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.