Nic Offloads Tsogrolro Efeitos Colaterais Em Storage

Antes de falarmos sobre bits e bytes, precisamos ajustar nosso modelo mental sobre o que acontece quando o sistema operacional diz "envie este arquivo"....
Nic Offloads Tsogrolro Efeitos Colaterais Em Storage
Antes de falarmos sobre bits e bytes, precisamos ajustar nosso modelo mental sobre o que acontece quando o sistema operacional diz "envie este arquivo".
Imagine que você é o gerente de um armazém (a CPU). Você tem um caminhão (a placa de rede/NIC) que só pode carregar caixas pequenas (o MTU, geralmente 1500 bytes). Se você tiver que embalar, etiquetar e carregar 100.000 caixas pequenas individualmente, você vai passar o dia todo na doca de carga e não vai conseguir gerenciar o escritório.
A solução? Offloading.
Você pega um container gigante de 64KB, joga tudo dentro, lacra e diz para o motorista do caminhão: "Se vira. Quando chegar na estrada, você quebra isso em caixas de 1500 bytes".
Isso é o TSO (TCP Segmentation Offload). O sistema operacional (Linux) mente para si mesmo. Ele constrói um pacote TCP gigante, muito maior que o MTU físico da rede, e o entrega para a placa de rede. O silício da placa de rede — que é especializado e estúpido, mas rápido — fatia esse monstro em pacotes reais que cabem no cabo Ethernet.
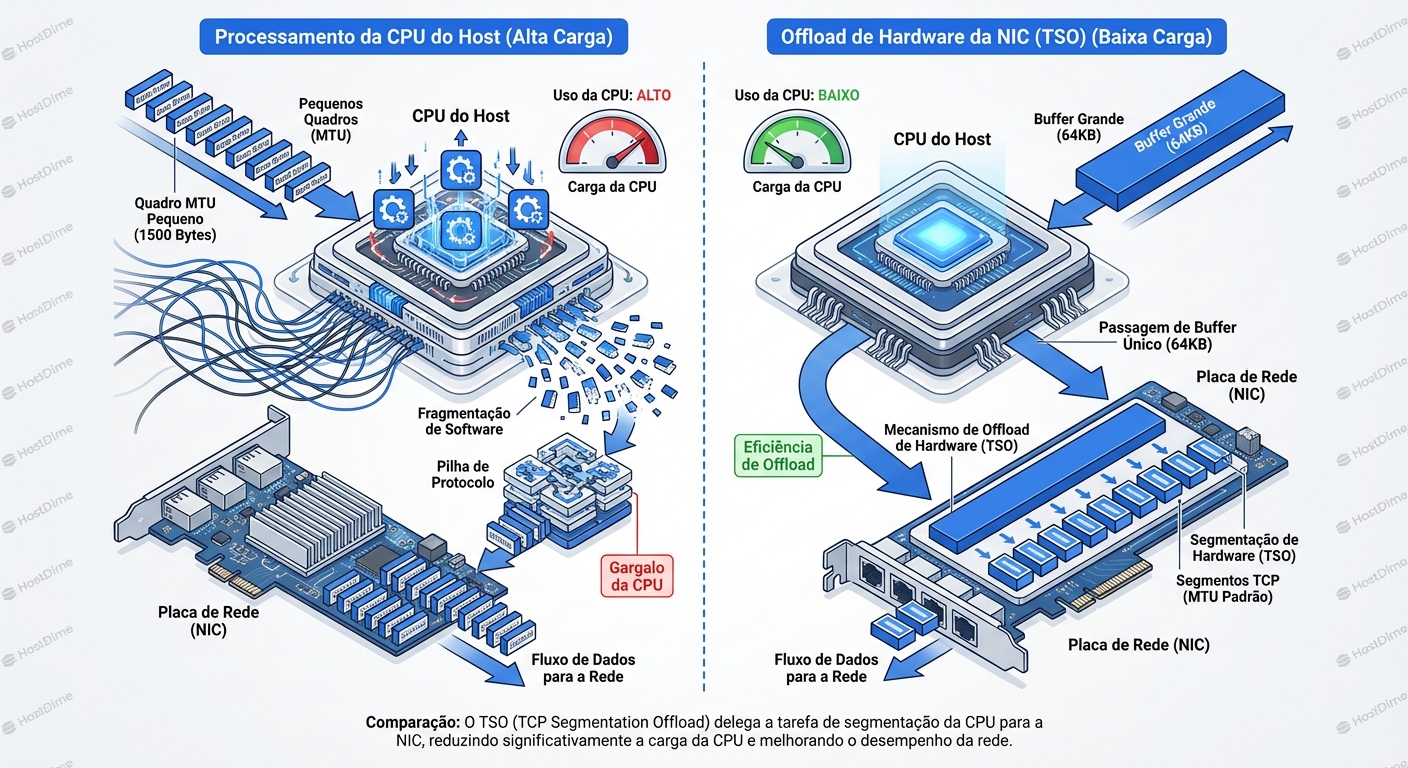
Do outro lado, na recepção, acontece o inverso com LRO/GRO. O motorista recebe milhares de caixinhas pequenas, espera acumular um monte delas, cola tudo com fita adesiva e entrega um container gigante de 64KB para o gerente do armazém de destino (a CPU receptora). "Aqui está, processe uma vez só".
A Economia de Interrupções
Por que fazemos isso? Por causa do custo de contexto.
Cada pacote que chega na placa de rede gera uma interrupção de hardware (IRQ). A CPU precisa parar o que está fazendo, salvar o estado, atender a interrupção, copiar dados, processar a pilha TCP/IP e voltar.
- Sem Offload (10Gbps): Milhões de pacotes por segundo = Milhões de interrupções. A CPU trava apenas movendo dados (o temido
ksoftirqdem 100%). - Com Offload: A NIC junta tudo. Uma interrupção trata 64KB de dados de uma vez. A CPU respira.
Parece mágico. Para um servidor web servindo Nginx estático ou streaming de vídeo, é perfeito. Mas para storage, onde cada milissegundo conta para o commit de uma transação de banco de dados, essa "espera para juntar pacotes" ou "processamento em lote" tem um preço oculto.
A Grande Mentira do Tcpdump
O primeiro sintoma de que você está lidando com offloads é a confusão ao diagnosticar a rede. Você roda um tcpdump na interface e vê isto:
14:20:01.554 IP 10.0.0.1.443 > 10.0.0.2.5566: Flags [.], seq 1:65535, length 65534
Você pensa: "Impossível! Meu MTU é 1500 (ou 9000 com Jumbo Frames). Como diabos passou um pacote de 65KB?"
A Realidade: O tcpdump captura os pacotes na camada de software, antes de eles serem entregues à NIC (no envio) ou depois de serem remontados pela NIC/Kernel (no recebimento).
Você está vendo a "ilusão" do Kernel. Na fibra ótica real, esses pacotes nunca existiram dessa forma. Eles foram fatiados. Se você espelhar a porta no switch (SPAN port) e capturar lá, verá a verdade: dezenas de pacotes de 1500 bytes.
Isso é crucial: ferramentas de host mentem sobre o que está no fio quando offloads estão ativos.
O Efeito Micro-Burst: Quando o TSO Ataca
Vamos focar no problema de armazenamento. Imagine um servidor iSCSI ou um OSD do Ceph.
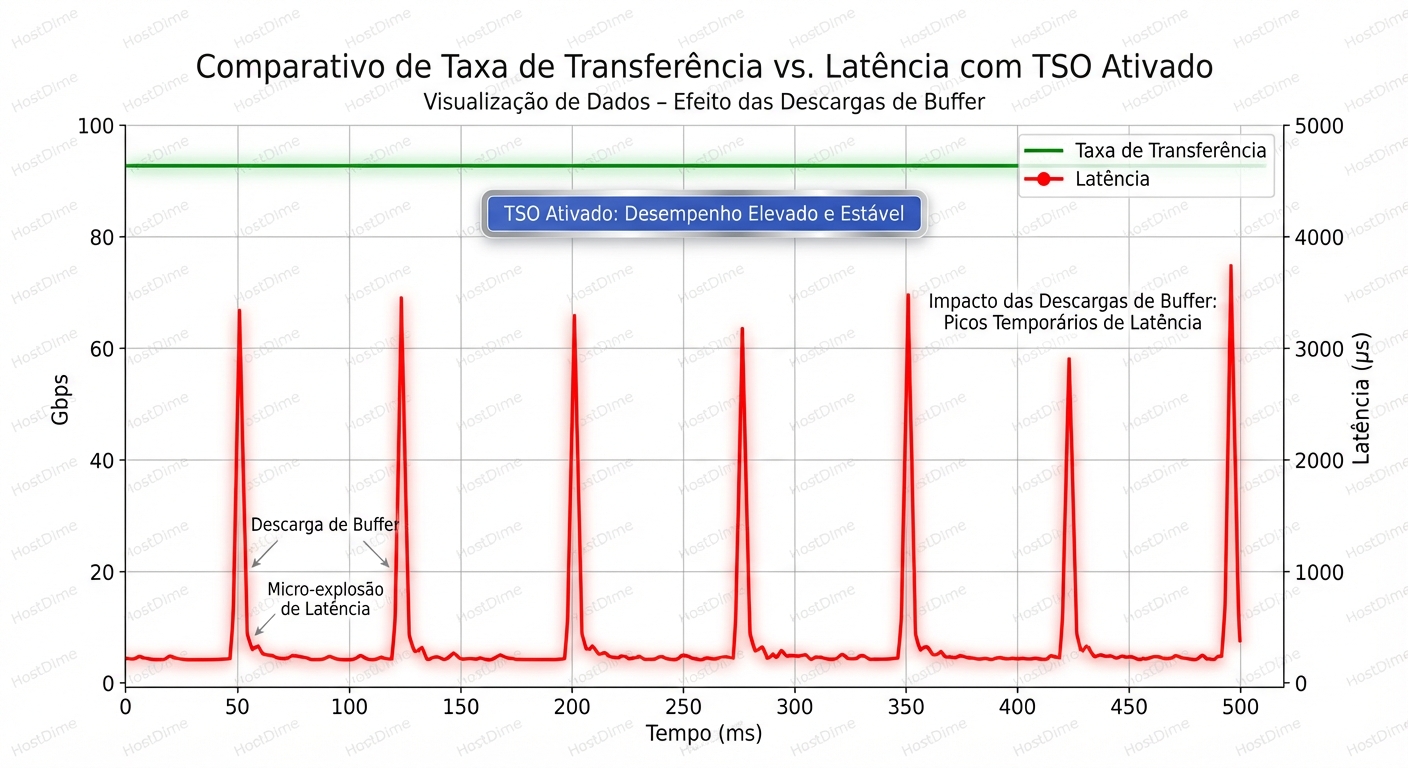
Quando o TSO está ativado, o Kernel passa um buffer de 64KB para a NIC. A NIC, sendo um hardware eficiente, fatia isso e cospe os pacotes no fio na velocidade da linha (line-rate) instantaneamente.
Isso cria um Micro-burst.
Em vez de um fluxo suave de dados espaçados pela latência de processamento da CPU, você tem rajadas violentas de dados seguidas de silêncio.
O Cenário do Switch Top-of-Rack
Seu switch tem buffers. Mas switches de acesso (Top-of-Rack) geralmente têm buffers pequenos (alguns MBs compartilhados).
- Seu servidor de storage dispara um micro-burst via TSO.
- O switch recebe essa rajada a 10Gbps.
- A porta de destino (digamos, um host de virtualização ocupado) está congestionada ou negociando a uma velocidade ligeiramente diferente.
- O buffer do switch enche instantaneamente.
- Drop. O switch descarta os pacotes excedentes.
Para o TCP, perda de pacote é o fim do mundo. Ele entra em Slow Start, corta a janela de transmissão pela metade e retransmite.
Resultado: Seu throughput médio (visto no gráfico de 5 minutos) parece bom. Mas sua latência de cauda (P99) explode porque a cada poucos segundos, conexões TCP estão parando para retransmitir dados perdidos em micro-bursts que duram milissegundos.
LRO e GRO: A Armadilha da Recepção
Se o TSO é sobre enviar rajadas, o LRO (Large Receive Offload) e o GRO (Generic Receive Offload) são sobre "esperar para processar".
A diferença técnica é vital:
- LRO: Feito inteiramente no hardware da NIC. A NIC funde os pacotes e o Kernel nem vê os cabeçalhos originais. É agressivo e muitas vezes destrutivo (perde informações de timestamp ou headers precisos).
- GRO: Feito pelo Kernel (software), logo após receber da NIC. É mais inteligente e respeita as regras do TCP, mas ainda gasta ciclos de CPU para "fundir" pacotes.
O Problema da Latência de Coalescência
Para que o LRO/GRO funcione, a NIC ou o driver precisa esperar um pouco. Não adianta enviar um pacote para a CPU se o próximo pacote da mesma sequência chega em 2 microssegundos. Melhor esperar e enviar os dois juntos.
Essa espera é controlada por parâmetros de Interrupt Coalescing (rx-usecs no ethtool).
Em um fluxo de transferência de arquivo (throughput puro), esperar 50µs para juntar dados é ótimo. Em uma gravação síncrona de banco de dados via iSCSI, esperar 50µs é um pecado. O disco já é lento; adicionar latência artificial na rede é inaceitável.
Além disso, o LRO quebra o roteamento. Se o seu servidor atua como roteador, bridge ou firewall, o LRO é fatal. Ele altera o pacote de tal forma que, se o Linux tentar reencaminhá-lo, o pacote resultante será inválido ou grande demais para sair pela outra interface sem fragmentação (que o bit DF - Don't Fragment - provavelmente proíbe).
Regra de Ouro: Se a máquina faz routing, bridging ou é um nó de virtualização (KVM/Hyper-V), DESLIGUE O LRO. Use GRO se necessário, mas nunca LRO.
Diagnóstico: Como Enxergar o Invisível
Como saber se os offloads estão matando sua performance de storage? Não confie apenas no "sentimento". Use dados.
1. Verificando o Estado Atual
O comando básico é o ethtool -k.
# ethtool -k eth0 | grep -i -E "segmentation|large-receive"
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off
tx-tcp6-segmentation: on
generic-receive-offload: on
large-receive-offload: off [fixed]
Nota: Muitas placas modernas desativam LRO por padrão ou o marcam como [fixed] se o driver não suportar a alteração, preferindo o GRO via software.
2. Caçando Drops Silenciosos
O lugar onde a verdade se esconde é nas estatísticas estendidas da NIC. O ifconfig mostra erros genéricos. O ethtool -S mostra o que o driver viu.
Procure por contadores que indicam que a NIC ficou sem buffer ou que o fluxo de controle (Pause Frames) foi ativado.
ethtool -S eth0 | grep -E "drop|flow|miss|buff"
Saída hipotética preocupante:
rx_dropped: 0
tx_dropped: 0
rx_missed_errors: 4520 <-- A NIC recebeu pacotes mas o barramento PCIe ou CPU não drenou a tempo.
rx_flow_control_xon: 120
rx_flow_control_xoff: 4500 <-- O switch mandou a NIC parar de transmitir (Pause Frames).
Se você vê flow_control_xoff subindo, significa que seu switch está gritando "PARE!". Isso é um sinal clássico de micro-bursts causados por TSO saturando o receptor ou o switch.
3. A Análise via sar
Use o sar para comparar pacotes vs. kilobytes.
sar -n DEV 1
Observe a relação entre rxpck/s (pacotes por segundo) e rxkB/s.
Se você tem rxkB/s alto, mas rxpck/s suspeitosamente baixo, o LRO/GRO está agressivamente fundindo pacotes antes de você vê-los.
Se você desligar o LRO/GRO, o rxpck/s deve disparar e a carga de CPU (softirq) deve subir. Se a latência da aplicação cair nesse momento, você achou o culpado.
Tuning e Soluções: O Bisturi
Não saia desativando tudo. Offloads existem por uma razão. Desativar TSO em uma rede de 40Gbps pode fazer sua CPU atingir 100% de uso apenas para manter o tráfego, matando a performance por exaustão de recursos.
A abordagem deve ser cirúrgica.
Cenário A: O Nó de Storage Puro (iSCSI Target / Ceph OSD)
Aqui, a latência é rei.
Desative LRO: O hardware não deve mexer nos pacotes recebidos de forma opaca.
ethtool -K eth0 lro offAvalie TSO: Se a CPU tiver folga, teste desativar o TSO para reduzir micro-bursts.
ethtool -K eth0 tso offMonitore a CPU imediatamente. Se o
si(software interrupt) notoppassar de 20-30% em um núcleo, volte atrás. O custo da CPU está superando o ganho de latência.Ajuste de Coalescência (O Segredo): Em vez de desligar offloads, ajuste o tempo que a NIC espera.
# Ver configuração atual ethtool -c eth0 # Ajustar para latência baixa (exemplo) # rx-usecs: Microsegundos para esperar antes de gerar interrupção # rx-frames: Quantos pacotes esperar antes de gerar interrupção ethtool -C eth0 rx-usecs 10 rx-frames 4Valores menores em
rx-usecssignificam resposta mais rápida, mas mais carga de CPU. O padrão de muitas placas é adaptativo, mas o algoritmo adaptativo muitas vezes favorece throughput em vez de latência. Para storage, fixar valores baixos (10-20µs) costuma ser mais estável.
Cenário B: O Roteador / Hypervisor
Se a máquina passa tráfego de uma interface para outra (VMs, containers, routing):
- LRO OFF (Obrigatório): LRO quebra bridging e routing.
- GRO ON: O Kernel sabe lidar com GRO ao rotear (ele "desfaz" o pacote gigante se necessário ou usa GSO para re-segmentar na saída).
- TSO ON: Geralmente seguro e necessário para manter a performance das VMs.
A Armadilha do MTU (Jumbo Frames)
Uma nota rápida sobre Jumbo Frames (MTU 9000). Muitos admins ativam Jumbo Frames pensando que isso resolve o problema de sobrecarga de CPU, tornando o TSO desnecessário.
Matemática básica:
- MTU 1500 -> TSO junta ~43 pacotes em um buffer de 64KB.
- MTU 9000 -> TSO junta ~7 pacotes em um buffer de 64KB.
Jumbo Frames ajudam, sim. Eles reduzem a sobrecarga de cabeçalho por byte de dado. Mas eles não eliminam a necessidade de TSO em redes de alta velocidade (25G/40G/100G). A CPU ainda não consegue lidar com pacotes 1:1 nessas velocidades sem ajuda.
O perigo dos Jumbo Frames é a fragmentação silenciosa se um único switch ou dispositivo no caminho não estiver configurado corretamente. Em storage, isso resulta em black holes: o handshake TCP (pacotes pequenos) funciona, mas assim que o dado real (pacote grande) é enviado, a conexão trava.
Tabela de Decisão: O Que Desligar?
| Cenário | TSO (Envio) | GRO (Recepção Soft) | LRO (Recepção Hard) | Foco Principal |
|---|---|---|---|---|
| Web Server / App | ON | ON | ON (se suportado) | Throughput / CPU |
| iSCSI Target / NAS | Testar OFF* | ON | OFF | Latência / Integridade |
| Ceph OSD | ON (geralmente)** | ON | OFF | Latência de Cauda |
| Hypervisor (KVM) | ON | ON | OFF | Compatibilidade de Bridge |
| Router / Firewall | ON | ON | OFF | Conformidade de Protocolo |
** Desligar TSO em storage depende da capacidade da CPU. Se a CPU for fraca, deixe ON.*
*** Ceph é complexo. TSO ajuda na replicação de backfill, mas atrapalha na latência de client. O ajuste de coalescência (ethtool -C) costuma ser mais eficaz que desligar o TSO.*
O Veredito: Latência é o Preço da Eficiência
Não existe almoço grátis. Os offloads de NIC foram criados para resolver um problema de escalabilidade da CPU, mas introduziram uma camada de buffer e processamento em lote que é antitética à natureza "tempo real" do armazenamento de alta performance.
Como Sysadmin ou SRE, seu trabalho não é seguir "melhores práticas" cegas, mas entender o fluxo de dados.
- Se você vê latência alta com CPU baixa: Desconfie dos Offloads.
- Se você vê retransmissões TCP e drops em switches: Desconfie do TSO (Micro-bursts).
- Se você roteia tráfego: Mate o LRO.
A próxima vez que seu cluster de storage engasgar sem motivo aparente, não olhe apenas para os discos. Olhe para a placa de rede. Ela pode estar tentando ser eficiente demais para o seu próprio bem.
Para Aprofundar
- eBPF e XDP: Como novas tecnologias do Linux permitem processar pacotes antes mesmo de chegarem ao stack TCP/IP, contornando alguns problemas de offload tradicionais.
- SmartNICs / DPUs: Placas (como Mellanox BlueField) que possuem CPUs ARM reais embutidas. Elas não fazem apenas offload simples; elas rodam um OS inteiro, permitindo que o TSO/LRO seja programável e inteligente, não apenas um circuito fixo em silício.
- TCP BBR: Como algoritmos de controle de congestionamento modernos lidam (ou falham) com o bufferbloat causado por offloads agressivos.

Alexei Volkov
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.