NVMe-oF com RoCEv2: O Guia de Sobrevivência para Baixa Latência em 100GbE

Domine o NVMe over Fabrics (RoCEv2). Entenda os perigos do PFC, como configurar ECN em redes 100GbE e as métricas reais para garantir latência de flash local via Ethernet.
A promessa do NVMe over Fabrics (NVMe-oF) é sedutora: latência de armazenamento local através de uma rede Ethernet. Com links de 100GbE (ou 400GbE) se tornando commodities, a largura de banda deixou de ser o gargalo. O novo inimigo é a latência da pilha de protocolos e a consistência da entrega de pacotes.
Muitos engenheiros caem na armadilha de tratar NVMe-oF com RoCEv2 (RDMA over Converged Ethernet version 2) como "apenas mais um tráfego TCP". Isso é um erro fatal. RoCEv2 não é tolerante; ele é exigente. Ele requer uma rede determinística em um meio (Ethernet) que foi projetado para ser "best effort".
Se você está implementando NVMe-oF para cargas de trabalho de Inteligência Artificial, HPC ou bancos de dados de alta frequência, esqueça as "melhores práticas" genéricas de rede corporativa. Vamos dissecar a física, a configuração e a metrologia necessárias para fazer isso funcionar.
O que é NVMe-oF com RoCEv2?
NVMe-oF com RoCEv2 é um protocolo de transporte de armazenamento que encapsula comandos NVMe dentro de pacotes RDMA sobre UDP/IP. Diferente do iSCSI ou NVMe/TCP, ele utiliza tecnologias de Kernel Bypass e Zero-Copy para permitir que a aplicação grave diretamente na memória da placa de rede (NIC), eliminando trocas de contexto da CPU e visando latências de ponta a ponta inferiores a 10µs, desde que a rede Ethernet seja configurada como "Lossless" (sem perdas).
Anatomia do RDMA e o Kernel Bypass
Para entender por que RoCEv2 é necessário, precisamos quantificar o custo do TCP/IP tradicional. Em uma rede de 100GbE, um único pacote de 4KB chega a cada ~300 nanossegundos. Se a sua CPU precisa interromper o que está fazendo, copiar dados do espaço do kernel para o espaço do usuário e processar a pilha TCP para cada pacote, você saturou seus núcleos muito antes de saturar o link.
O RDMA (Remote Direct Memory Access) resolve isso removendo o sistema operacional do caminho de dados (Data Path). O caminho de controle (estabelecer a conexão) ainda envolve o kernel, mas a transferência de dados é direta.
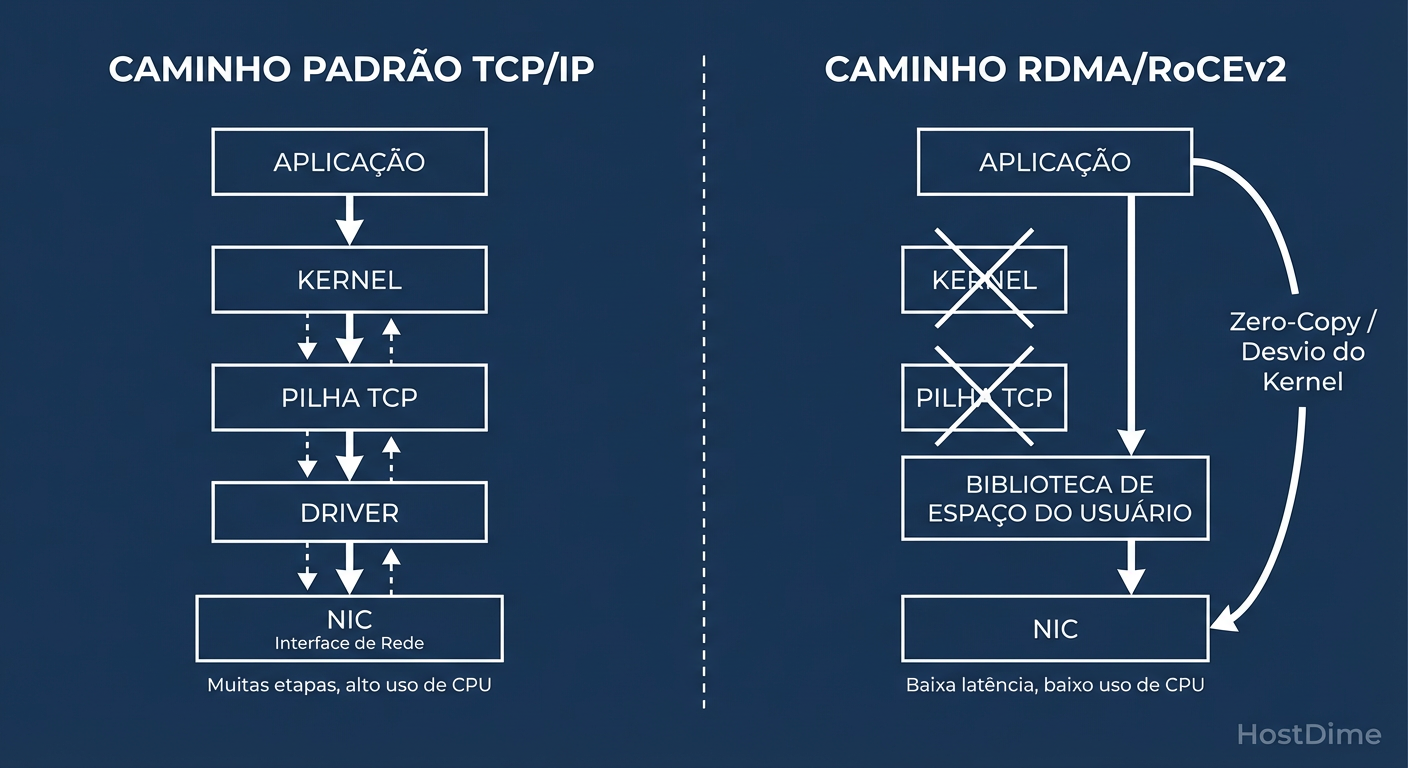 Figura: Diagrama de Kernel Bypass: O segredo da baixa latência do RoCEv2 é pular a pilha TCP/IP do sistema operacional.
Figura: Diagrama de Kernel Bypass: O segredo da baixa latência do RoCEv2 é pular a pilha TCP/IP do sistema operacional.
Como ilustrado acima, a mágica do Kernel Bypass reside na capacidade da aplicação (neste caso, o driver NVMe) conversar diretamente com a HCA (Host Channel Adapter - a NIC RDMA). Isso resulta em:
Zero-Copy: Os dados não são copiados da RAM para buffers do kernel e depois para a NIC. A NIC lê diretamente da memória da aplicação via DMA.
Redução de Latência: Eliminamos microssegundos preciosos de context switching.
Liberação de CPU: A CPU fica livre para computar, não para mover bits.
No entanto, essa eficiência cobra um preço alto: a perda da camada de transporte robusta do TCP. O RoCEv2 usa UDP. Se um pacote é perdido, o hardware (NIC) precisa lidar com a retransmissão, e a performance cai de um penhasco.
O Dilema da Rede Lossless: PFC vs. ECN
O maior desafio operacional do RoCEv2 em Ethernet é garantir que pacotes não sejam descartados. Em TCP, um drop é apenas um sinal para reduzir a janela de congestionamento. Em RDMA, um drop força uma retransmissão "Go-Back-N" (retransmitir tudo desde o pacote perdido), o que destrói a latência de cauda (P99).
Para evitar drops, transformamos a Ethernet em uma rede Lossless. Existem dois mecanismos principais para isso, e a escolha errada pode derrubar seu Data Center.
Priority Flow Control (PFC): O Martelo
O PFC (IEEE 802.1Qbb) opera na camada 2. Quando o buffer de um switch enche, ele envia um frame de "PAUSE" para o remetente, dizendo: "Pare de enviar tráfego na prioridade X".
- O Risco: Se mal configurado, o PFC pode causar Head-of-Line Blocking e propagação de congestionamento, onde um switch pausa o outro, que pausa o host, travando a rede inteira (PFC Storm).
Explicit Congestion Notification (ECN): O Bisturi
O ECN opera na camada 3 (IP). Em vez de parar o tráfego, o switch marca o bit ECN no cabeçalho IP quando detecta congestionamento incipiente. A NIC de destino vê o bit, envia um Congestion Notification Packet (CNP) de volta à fonte, e a fonte reduz a taxa de transmissão (algoritmo DCQCN).
 Figura: PFC vs. ECN: A diferença entre parar o tráfego brutalmente (PFC) e sinalizar congestionamento suavemente (ECN) em redes Ethernet 100GbE.
Figura: PFC vs. ECN: A diferença entre parar o tráfego brutalmente (PFC) e sinalizar congestionamento suavemente (ECN) em redes Ethernet 100GbE.
Veredito de Engenharia: Não confie apenas no PFC. O design moderno de RoCEv2 exige ECN (DCQCN) como mecanismo primário de controle de congestionamento, usando o PFC apenas como um "disjuntor" de emergência para evitar buffer overflow físico. Se o PFC está ativando frequentemente, sua configuração de ECN está frouxa demais.
Configuração do Switch e NIC para Baixa Latência
A configuração padrão de switches 100GbE não suporta RoCEv2 adequadamente. Você precisa segregar o tráfego de armazenamento do tráfego "best effort" (SSH, HTTP, monitoramento).
Checklist de Implementação de Rede
MTU (Maximum Transmission Unit):
- Configure Jumbo Frames (MTU 9000 ou 9216) de ponta a ponta (Hosts e Switches).
- Por que: Reduz o overhead de cabeçalhos e aumenta a eficiência do throughput. O NVMe adora transferências grandes.
QoS e Mapeamento de Prioridade (DSCP/CoS):
- O RoCEv2 depende de VLANs e prioridades (PCP/DSCP).
- Geralmente, mapeamos o tráfego RoCE para a Prioridade 3 ou 4 (Lossless) e o restante para Prioridade 0 (Lossy).
- Perigo: Se o mapeamento DSCP-to-Priority no switch não coincidir exatamente com a configuração da NIC, o tráfego cairá na fila errada e sofrerá drops.
Buffer Carving:
- Em switches cut-through (como os baseados em Broadcom Tomahawk ou NVIDIA Spectrum), reserve buffers dedicados para a fila Lossless (ingress e egress) para absorver micro-bursts sem disparar o PFC imediatamente.
Tuning do Host Linux: Onde a Latência se Esconde
O hardware está pronto. Agora, precisamos impedir que o Linux atrapalhe. O scheduler padrão e o gerenciamento de energia são inimigos da latência determinística.
1. IRQ Affinity (Afinidade de Interrupção)
Em NICs de alta velocidade, as interrupções de conclusão de I/O podem ser espalhadas por todas as CPUs, causando cache thrashing. Você deve fixar as filas da NIC (MSI-X vectors) para núcleos de CPU específicos, idealmente no mesmo soquete NUMA onde a placa PCIe está instalada.
# Verificar em qual nó NUMA a placa está
cat /sys/class/net/eth4/device/numa_node
# O script 'set_irq_affinity' da Mellanox/NVIDIA é o padrão ouro aqui
/usr/sbin/set_irq_affinity_cpulist.sh 0-15 eth4
2. NVMe Polling vs. Interrupt
O modelo clássico de interrupção tem um custo de latência (~5-6µs para acordar a CPU). Para armazenamento ultrarrápido (Optane ou NVMe Gen4/5), isso é inaceitável. O Linux suporta Hybrid Polling. O driver faz spin na CPU esperando a conclusão do I/O por um tempo antes de dormir. Isso gasta mais CPU, mas reduz drasticamente a latência.
Para ativar no boot (parâmetro do kernel nvme.poll_queues):
- Aloque filas dedicadas para polling.
3. C-States do Processador
Desative estados profundos de economia de energia. Você não quer que sua CPU leve 10µs para "acordar" (sair de C6 para C0) quando um pacote chega.
- Adicione
intel_idle.max_cstate=1ouprocessor.max_cstate=1no GRUB.
Metrologia de Storage: Medindo o que Importa
Não use ping. Não use dd. Para validar NVMe-oF, precisamos de ferramentas que gerem profundidade de fila (Queue Depth - QD) e meçam latência de cauda.
O Teste de Ouro com FIO
Use o fio com a engine libaio ou io_uring (preferível em kernels 5.10+).
# Exemplo de teste de Latência (QD=1) para validar o overhead da rede
fio --name=latency_test \
--filename=/dev/nvme0n1 \
--direct=1 \
--rw=randread \
--bs=4k \
--ioengine=io_uring \
--iodepth=1 \
--numjobs=1 \
--time_based --runtime=60 \
--group_reporting
O que procurar nos resultados:
Latência Média (slat + clat): Em 100GbE RoCEv2 bem ajustado, deve ser < 100µs (muitas vezes < 20µs + latência da mídia).
Latência P99.99: É aqui que o RoCEv2 falha se a rede tiver perdas. Se o P99.99 saltar de 200µs para 50ms, você tem retransmissões ou PFC storms.
Monitoramento de Rede (Evidence-based)
No Linux, use ethtool -S <interface> e procure por contadores específicos de RDMA/RoCE.
Métricas de Sucesso:
rx_vport_rdma_unicast_packets,tx_vport_rdma_unicast_packets.Métricas de Falha (O "Smoking Gun"):
rx_prio[N]_discard: Pacotes jogados fora por falta de buffer.rx_prio[N]_pause: Quantidade de PAUSE frames recebidos (você está sendo freado).tx_prio[N]_pause: Quantidade de PAUSE frames enviados (você está freando alguém).cnp_sent/cnp_handled: Atividade do ECN. Se estiver subindo rápido, há congestionamento, mas o sistema está controlando.
NVMe/TCP vs. RoCEv2: Quando a complexidade não compensa
Existe um hype massivo em torno do RoCEv2, mas ele exige hardware específico (RNICs) e switches configurados com precisão cirúrgica. O NVMe/TCP, por outro lado, roda em qualquer Ethernet padrão, usando a pilha TCP otimizada do Linux.
Quando escolher qual?
| Característica | NVMe/TCP | NVMe-oF (RoCEv2) |
|---|---|---|
| Dependência de Hardware | Nenhuma (NIC padrão) | Alta (RNIC com suporte RDMA) |
| Configuração de Rede | Padrão (Lossy é aceitável) | Complexa (Requer Lossless/PFC/ECN) |
| Custo de CPU (Host) | Médio/Alto (Processamento TCP) | Baixo (Offload/Bypass) |
| Latência Base | +10µs a +30µs vs Local | +2µs a +5µs vs Local |
| Escalabilidade | Extrema (Roteável na Internet) | Limitada (Geralmente intra-DC / Pod) |
| Caso de Uso Ideal | Storage Geral, VMware, VDI | AI/ML Training, HPC, High-Freq Trading |
Conclusão Prática: Se você não tem uma equipe de engenharia de rede dedicada para monitorar PFC/ECN e sua aplicação não morre com 20µs extras de latência, use NVMe/TCP. A complexidade operacional do RoCEv2 só se paga em escalas de performance extremas.
Referências & Leitura Complementar
Para aprofundar sua metodologia de testes e configuração, consulte as especificações originais:
NVM Express Base Specification 2.0: Detalha a arquitetura do NVMe over Fabrics.
IBTA (InfiniBand Trade Association) RoCEv2 Spec: A definição do encapsulamento UDP para RDMA (Annex A17).
RFC 3168 (The Addition of Explicit Congestion Notification to IP): A base teórica para entender como o ECN funciona em detrimento do PFC.
Mellanox/NVIDIA Community Posts: "Recommended Network Configuration Examples for RoCEv2" (Busque pelos whitepapers de configuração de QoS e Buffer).

Marta G. Oliveira
DevOps Engineer & Storage Nerd
Automatiza provisionamento de storage com Terraform e Ansible. Defensora do 'Infrastructure as Code' para storage.