NVMe-oF TCP vs RoCE: Análise Pragmática de Performance e Deploy em 2025

Pare de configurar PFC cegamente. Analisamos os trade-offs reais entre NVMe/TCP e RoCEv2: latência, overhead de CPU e a complexidade de redes 'lossless' em 2025.
Como investigador forense de sistemas, já vi datacenters inteiros paralisados não por falha de hardware, mas por excesso de otimização. O cenário é clássico: um arquiteto lê sobre "latência de nanossegundos", implementa RDMA (Remote Direct Memory Access) sem entender a física da rede e, seis meses depois, sou chamado para descobrir por que o banco de dados principal trava aleatoriamente às terças-feiras.
Em 2025, a batalha pelo transporte de armazenamento NVMe over Fabrics (NVMe-oF) não é mais sobre quem tem o número mais baixo no benchmark de marketing. É uma escolha entre a fragilidade de alto desempenho do RoCE (RDMA over Converged Ethernet) e a resiliência evoluída do NVMe/TCP. Vamos dissecar essa infraestrutura, começando pelos sintomas e indo até a causa raiz.
O que é NVMe-oF e como escolher o transporte? NVMe over Fabrics (NVMe-oF) é a especificação que estende a eficiência do protocolo NVMe local para redes de armazenamento. A escolha do transporte define a estabilidade: RoCE (v2) utiliza RDMA para latência ultra-baixa e bypass de CPU, exigindo uma rede Ethernet "lossless" (sem perdas) complexa de gerenciar. NVMe/TCP utiliza a pilha TCP/IP padrão, oferecendo desempenho próximo ao RDMA com hardware moderno (SmartNICs), mas priorizando a compatibilidade e a tolerância a falhas da rede existente.
O Mito da "Latência Zero" e a Realidade do RoCE
O hype do RDMA é construído sobre uma promessa sedutora: mover dados da memória de um servidor para a memória de outro sem acordar a CPU. Na teoria, isso elimina o overhead do sistema operacional. Na prática forense, isso remove a camada de proteção que o Kernel oferece.
Quando analisamos um trace de IO quebrado em um ambiente RoCE, o que vemos não é lentidão, é ausência. O RoCE v2 encapsula pacotes InfiniBand dentro de UDP. Para que isso funcione com a performance prometida, a placa de rede (NIC) precisa saber exatamente onde colocar os dados na memória RAM do destino.
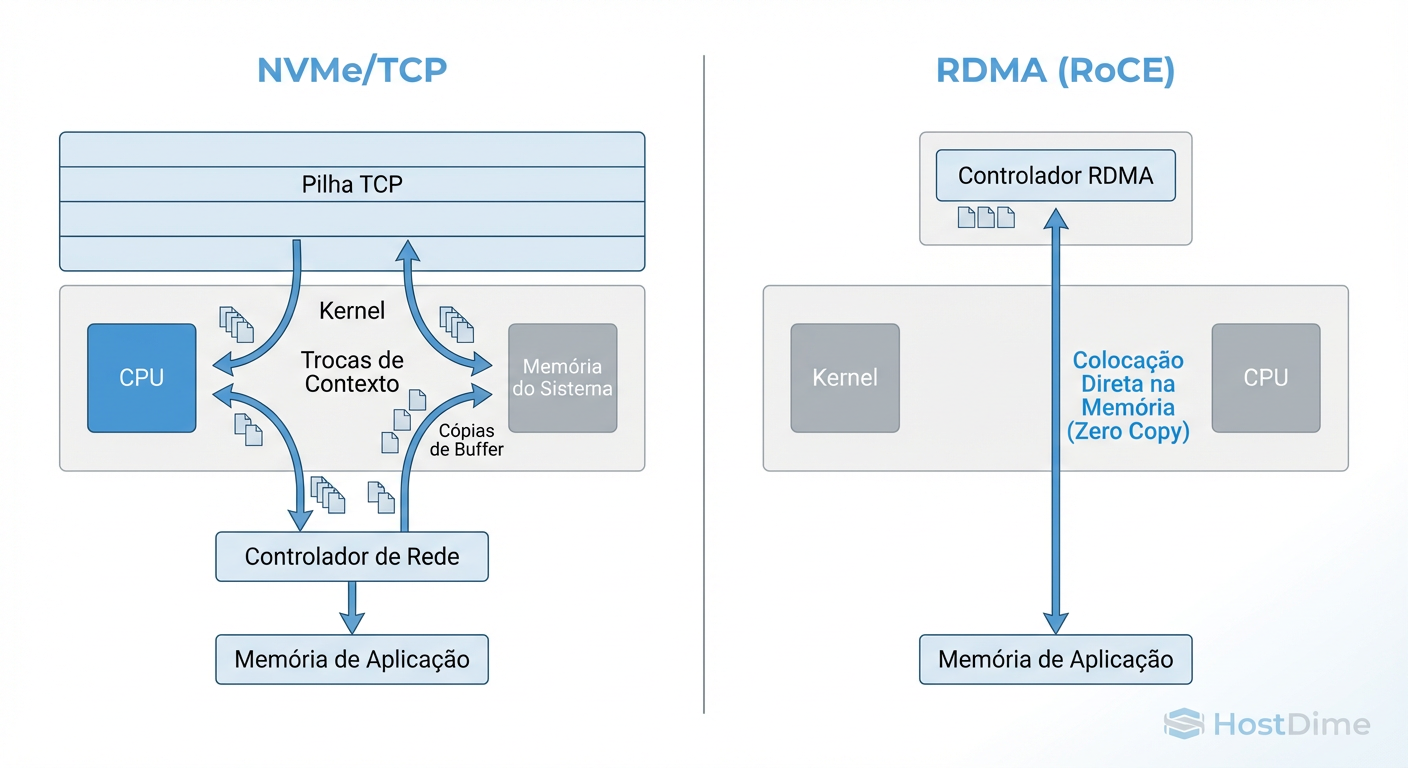 Figura: O Caminho dos Dados: Onde o RoCE ganha tempo (bypass de Kernel) e onde o TCP gastava ciclos (cópias de buffer).
Figura: O Caminho dos Dados: Onde o RoCE ganha tempo (bypass de Kernel) e onde o TCP gastava ciclos (cópias de buffer).
Isso exige que a aplicação e a NIC conversem diretamente. O ganho de performance é real — estamos falando de latências de leitura na casa dos 5µs a 10µs em redes locais. Porém, o custo desse "bypass" é a perda de visibilidade. Ferramentas padrão de observabilidade do Linux (como eBPF ou contadores TCP tradicionais) ficam cegas para o tráfego que não passa pela stack de rede do Kernel. Se algo quebra, você está depurando firmware de NIC, não software.
Anatomia do Transporte: Zero-Copy do RoCE vs Stack TCP Moderno
Para entender por que o TCP voltou à mesa de discussão em 2025, precisamos olhar para como os dados trafegam.
O Caminho do RoCE (Otimização Extrema)
No modelo RoCE, usamos Zero-Copy real. O comando NVMe é montado na memória do usuário e a NIC o lê via DMA (Direct Memory Access). Não há cópia de buffer, não há context switch, não há interrupções de CPU para cada pacote. É um tubo direto.
O Caminho do TCP (A Evolução Silenciosa)
Historicamente, o TCP era lento para armazenamento porque exigia múltiplas cópias de memória (User Space -> Kernel Buffer -> NIC). Isso queimava ciclos de CPU e aumentava a latência.
No entanto, em 2025, o cenário mudou. Com a introdução de tecnologias como io_uring no Linux e o suporte generalizado a Zero-Copy send nas stacks TCP modernas, a diferença diminuiu drasticamente. Além disso, o offload de TCP em SmartNICs (DPUs) agora é onipresente. O "custo do TCP" foi terceirizado para o silício da placa de rede, mas mantendo a semântica robusta do protocolo.
O Pesadelo Operacional do "Lossless Ethernet"
Aqui é onde a maioria dos projetos falha. O RDMA foi desenhado para InfiniBand, uma rede que nunca perde pacotes. O Ethernet, por design, é "best effort" — se houver congestionamento, ele descarta pacotes. O RDMA odeia descarte de pacotes; a retransmissão destrói a performance.
Para fazer o RoCE funcionar em Ethernet, inventaram o PFC (Priority Flow Control). É aqui que o pesadelo forense começa.
O PFC permite que um switch diga ao vizinho: "Pare de mandar dados, estou cheio". Isso cria uma "pausa" na rede. Se mal configurado, isso gera o fenômeno de Congestion Spreading (Propagação de Congestionamento).
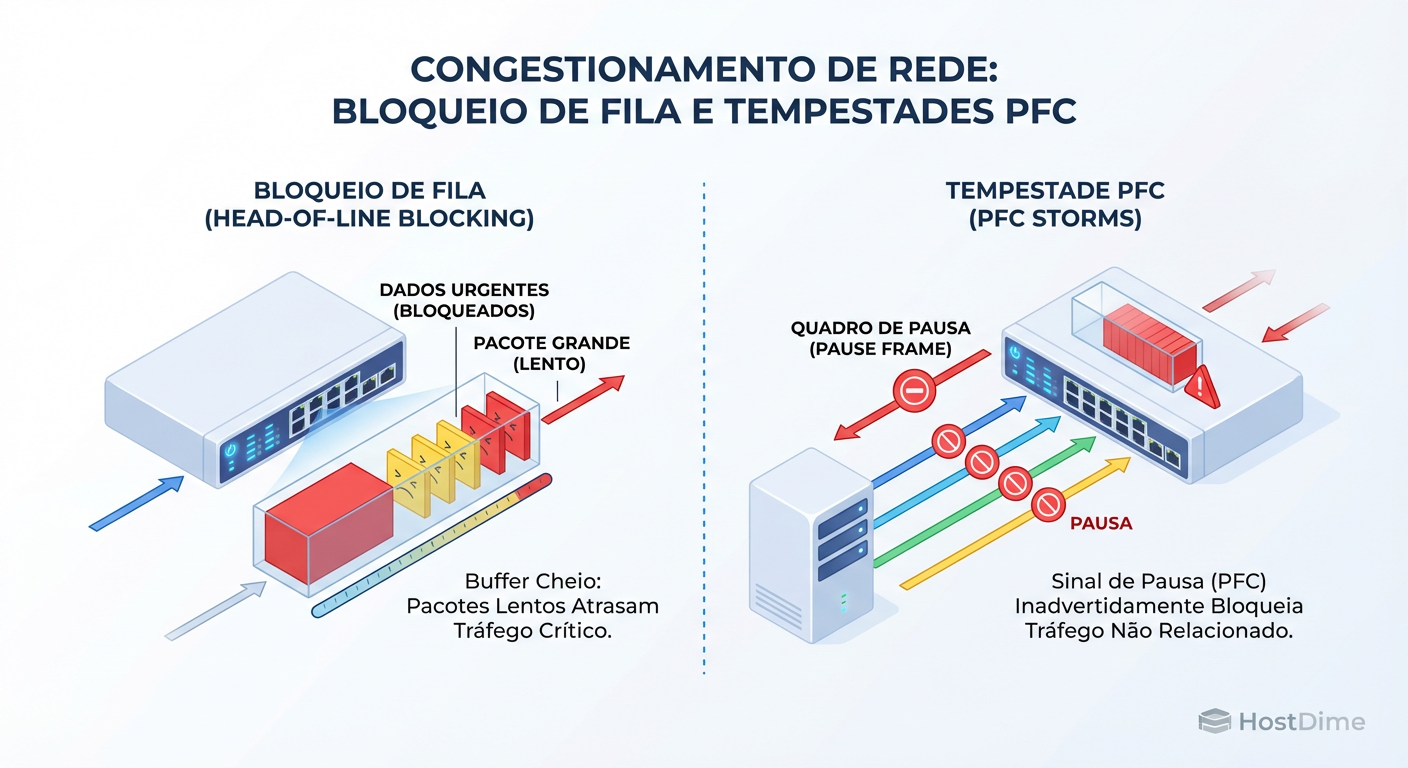 Figura: O Custo Oculto do RoCE: Como o Flow Control (PFC) pode transformar um pico de tráfego em uma paralisação da rede.
Figura: O Custo Oculto do RoCE: Como o Flow Control (PFC) pode transformar um pico de tráfego em uma paralisação da rede.
Imagine um nó de armazenamento lento. Ele envia um Pause Frame para o switch. O switch, ficando cheio, envia um Pause Frame para todos os servidores conectados a ele. De repente, um banco de dados crítico para de responder porque um servidor de backup não relacionado saturou o link. Em uma investigação, isso aparece como uma "latência fantasma": a rede não mostra erros, apenas pausas.
Como detectar Tempestades de PFC
Se você opera RoCE, este comando é seu monitor cardíaco. Se os contadores estiverem subindo rapidamente, sua rede está parando, não fluindo.
# Verificando estatísticas de Pause Frames na interface (ex: eth0)
ethtool -S eth0 | grep -E 'pause|pfc'
# Saída típica de um cenário problemático:
# rx_pause_frames: 154023 <-- ALERTA: O switch está mandando parar
# tx_pause_frames: 0
# rx_pfc_frames: 23091 <-- ALERTA: Flow control prioritário ativo
A Renascença do NVMe/TCP em 2025
Por que lutar contra a rede se você pode usá-la? O NVMe/TCP aceita a natureza "suja" do Ethernet. Se um pacote cai, o TCP retransmite. Sim, a latência de cauda (p99) sobe momentaneamente, mas a conexão não colapsa e não trava switches vizinhos.
Em 2025, três fatores trouxeram o TCP de volta ao topo da lista de decisão:
Maturidade do Driver: O driver NVMe/TCP no kernel Linux (5.15+) é extremamente eficiente, utilizando poll queues dedicadas.
Custo de Complexidade: Configurar DCB (Data Center Bridging), ECN (Explicit Congestion Notification) e PFC em switches de múltiplos vendors é propenso a erro humano. TCP funciona "out of the box".
SmartNICs Acessíveis: Placas que fazem offload completo de NVMe/TCP agora custam frações do preço de soluções proprietárias de RDMA.
Métricas que Importam: Latência de Cauda (p99) vs Throughput
Não se deixe enganar por IOPS de folheto. Em armazenamento distribuído, a métrica rainha é a Latência de Cauda (Tail Latency).
Cenário Ideal (Lab): O RoCE vence. Latência média de 10µs contra 30µs do TCP.
Cenário Real (Congestionado): Quando o link satura, o RoCE depende do PFC. Se o PFC falhar ou causar head-of-line blocking, a latência de cauda dispara para segundos (ou timeout). O TCP, usando algoritmos de congestionamento modernos (como BBR), ajusta a janela e mantém o fluxo, talvez subindo para 200µs, mas nunca travando a rede.
Para validar sua escolha, não use apenas dd. Use fio medindo os percentis altos.
# Exemplo de teste de FIO focado em latência de cauda (p99)
fio --name=lat_test --ioengine=libaio --direct=1 --rw=randread \
--bs=4k --numjobs=1 --iodepth=1 --runtime=60 --time_based \
--filename=/dev/nvme0n1 --group_reporting \
--percentile_list=99:99.9:99.99
Se o seu p99.99 no RoCE for instável sob carga, o "ganho" de latência média não vale o risco.
Matriz de Decisão: RoCE vs NVMe/TCP
Quando o custo operacional do RoCE paga a conta? Use esta tabela para guiar sua decisão arquitetural.
| Característica | NVMe over RoCE (v2) | NVMe over TCP |
|---|---|---|
| Dependência de Rede | Crítica. Exige switches com DCB/PFC/ECN configurados perfeitamente. | Baixa. Funciona em qualquer infraestrutura Ethernet L3 padrão. |
| Complexidade de Deploy | Alta. Requer alinhamento entre times de Storage e Redes. | Baixa. Plug-and-play na maioria das distros Linux modernas. |
| Custo de Hardware | Médio/Alto. Exige NICs compatíveis com RDMA e Switches Enterprise. | Baixo/Médio. Roda em NICs padrão (melhor com SmartNICs). |
| Performance (Latência) | Excelente (<10µs adicionais). | Muito Boa (<30µs adicionais com otimizações). |
| Risco Operacional | Alto. Risco de "Congestion Spreading" e paralisia da rede. | Baixo. Isolamento de falhas nativo do protocolo TCP. |
| Escalabilidade | Limitada ao domínio de Layer 2 ou roteamento complexo. | Infinita. Roteável globalmente como qualquer tráfego web. |
| Caso de Uso Ideal | HPC, AI Training Clusters, Bancos de Dados Oracle Exadata. | Cloud Generalista, VMware vSAN, Kubernetes PVs, Edge. |
Veredito Técnico Investigativa
Na minha experiência dissecando falhas, a complexidade é o inimigo da disponibilidade. O RoCE oferece uma Ferrari, mas exige uma pista de corrida perfeita (Lossless Ethernet). Se houver um buraco na pista, a Ferrari quebra. O NVMe/TCP é um veículo de rally: talvez não atinja a velocidade máxima teórica na reta, mas atravessa qualquer terreno sem parar.
Para 95% das empresas em 2025, a "penalidade" de 20 microssegundos do NVMe/TCP é irrelevante comparada ao ganho de noites de sono sem alertas de PFC Storms. Reserve o RoCE para clusters de IA e HPC onde cada ciclo de CPU conta. Para todo o resto, o TCP venceu pela pragmática.
Referências & Leitura Complementar
NVM Express Base Specification 2.0: Seções sobre Transport Binding (TCP e RDMA).
RFC 793 / RFC 8985: Protocolo TCP e o algoritmo RACK-TLP para recuperação de perdas (essencial para NVMe/TCP estável).
RoCE v2 Annex (InfiniBand Trade Association): Detalhes sobre o encapsulamento UDP e requisitos de PFC.
Linux Kernel Archives (Networking): Documentação sobre
io_uringe Zero-Copy networking.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.