O Choque do NVMe em 2025: Por que a IA Quebrou o Mercado de NAND (e Como Sobreviver)

Preços de SSDs Enterprise dobraram e a produção de 2026 já sumiu. Entenda a crise de NAND causada pela IA e as estratégias de arquitetura para salvar seu orçamento de storage.
Você abriu a cotação de renovação de hardware esta manhã e achou que havia um erro de digitação. O servidor de armazenamento all-flash que custava X em 2023 agora custa 2.5X. Não é inflação, e não é o vendedor tentando bater a meta trimestral.
Como investigador forense de sistemas, aprendi que quando o preço sobe sem aviso, algo na cadeia de suprimentos quebrou silenciosamente meses antes. O sintoma é a sua fatura estourada; a causa raiz é uma mudança tectônica na física do silício.
A "Era de Ouro do Flash Barato" (2022-2023) acabou. Estamos entrando em um período de escassez fabricada, não por falta de matéria-prima, mas por uma canibalização de recursos. A Inteligência Artificial não está apenas consumindo GPUs; ela está destruindo o mercado de NAND Enterprise.
Aqui está o relatório da autópsia do mercado de armazenamento de 2025 e o plano de sobrevivência para sua infraestrutura.
O que é a Crise do NVMe de 2025? A crise do NVMe de 2025 é um colapso de oferta no setor de SSDs Enterprise, causado pelo desvio massivo de wafers de NAND de alta qualidade para atender às cargas de trabalho de Checkpointing de IA (gravação contínua de estados de modelos LLM). Isso dissociou os preços corporativos dos preços de varejo, forçando arquitetos de sistemas a abandonarem estratégias all-flash em favor de arquiteturas híbridas com tiering agressivo.
Entendendo a Realidade dos Preços de NVMe em 2025
Para entender o crime, precisamos olhar para a linha do tempo. Em 2023, os fabricantes de memória (Samsung, SK Hynix, Micron) operaram com margens negativas, inundando o mercado para ganhar market share. Isso criou uma falsa sensação de segurança: nos acostumamos a colocar all-flash até em servidores de backup.
Em 2025, a realidade bateu à porta. O preço do NAND Enterprise não subiu linearmente; ele divergiu.
 Figura: Divergência de Preços 2022-2026: O custo do Enterprise Flash descolou da realidade.
Figura: Divergência de Preços 2022-2026: O custo do Enterprise Flash descolou da realidade.
O gráfico acima ilustra o desacoplamento. Enquanto o SSD de notebook (varejo) teve um aumento moderado, o SSD Enterprise (com proteção contra perda de energia e alto DWPD) disparou. Por quê? Porque ambos competem pelo mesmo silício de alta qualidade, e o setor Enterprise tem um novo predador no topo da cadeia alimentar.
Como o Checkpointing de LLMs Devora Wafers de NAND
A maioria das análises de IA foca em FLOPS (processamento). Isso é um erro. O gargalo oculto da IA generativa é o I/O.
Treinar um modelo como o GPT-4 ou Llama-3 não é apenas "ler dados". É uma operação de risco massivo. Se uma GPU falha no meio de um treino de 3 meses, perde-se milhões de dólares. Para mitigar isso, os clusters de IA realizam Checkpoints: eles despejam o estado completo da memória da GPU para o disco a cada poucos minutos.
Isso não é uma gravação sequencial bonita. É uma rajada de escrita violenta, simultânea e massiva, que exige:
Latência ultra-baixa: Para não travar as GPUs.
Endurance absurda (DWPD): O disco é reescrito várias vezes ao dia.
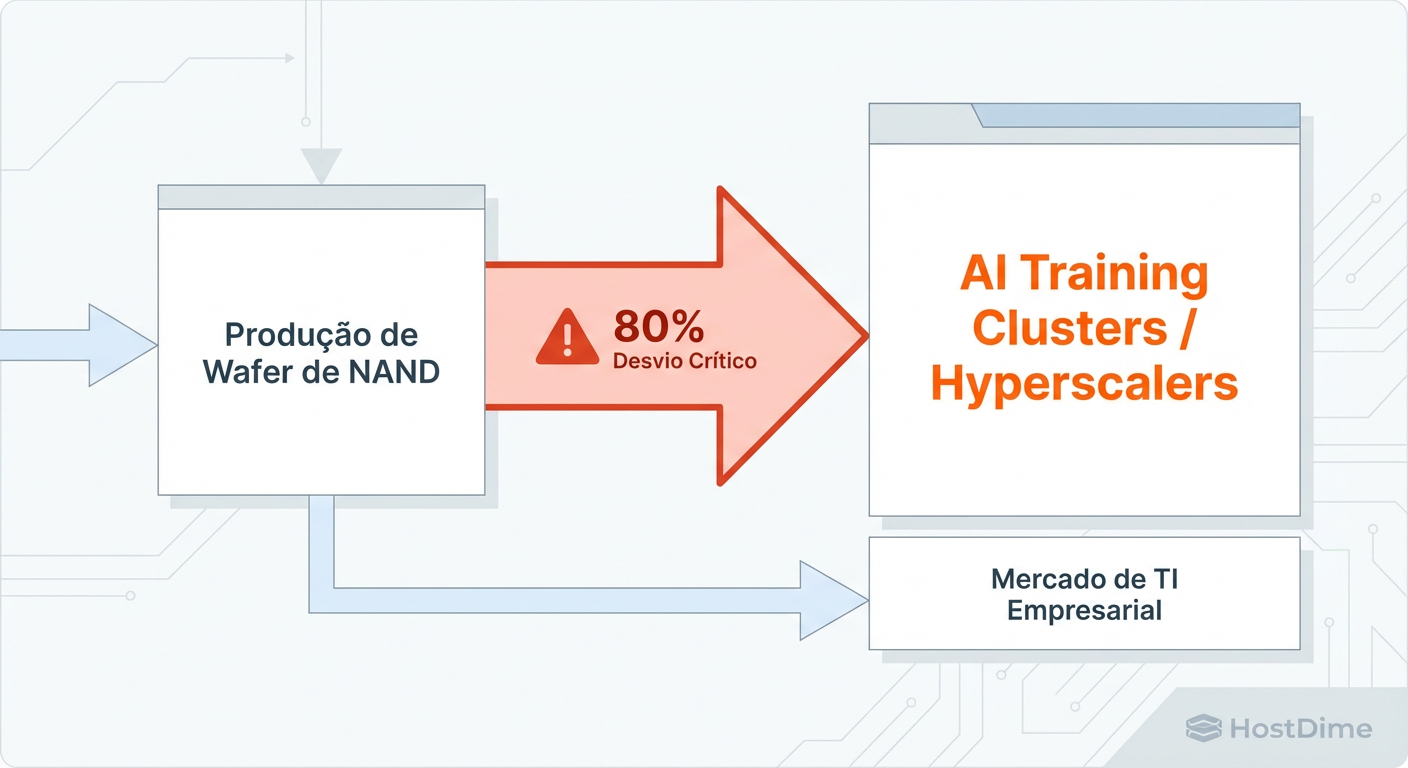 Figura: O Funil da Escassez de NAND: Para onde estão indo os Wafers em 2025.
Figura: O Funil da Escassez de NAND: Para onde estão indo os Wafers em 2025.
Como mostra o funil acima, a fabricação de NAND é um jogo de "binning" (seleção). Apenas uma pequena porcentagem dos chips em um wafer tem qualidade suficiente para suportar a tortura de um Datacenter de IA. Antes, esses chips iam para o seu servidor de banco de dados. Agora? Eles já foram vendidos para a Microsoft, Meta ou Google antes mesmo de serem cortados do wafer.
Você está competindo por sobras.
O Abismo de 2026 e a Capacidade Futura dos Hyperscalers
Se você acha que 2025 está ruim, os dados forenses de contratos futuros indicam um 2026 sombrio. Os Hyperscalers não compram discos na Amazon; eles compram a capacidade de produção da fábrica.
Investiguei os relatórios de CAPEX das "Big Techs". O padrão é claro: elas já reservaram a maior parte da capacidade de produção de NAND Enterprise de alta densidade (QLC de alta performance e TLC) para os próximos 18 a 24 meses.
Isso cria um vácuo no mercado intermediário. O distribuidor que atende sua empresa não consegue estoque de NVMe U.2/U.3 de 8TB ou 16TB a preços sãos porque esse produto nem chega a entrar no canal de distribuição padrão.
Estratégia de Arquitetura: O Retorno do HDD e Tiering Inteligente
Diante dessa escassez, insistir em all-flash para tudo é suicídio orçamentário. A solução não é "voltar para o passado", mas usar a tecnologia moderna de sistemas de arquivos (como ZFS) para criar uma hierarquia eficiente.
O HDD (disco mecânico) não morreu; ele foi promovido a "Armazenamento de Massa Frio/Morno". A mágica acontece quando paramos de tratar o armazenamento como um bloco monolítico e começamos a separar Metadados de Dados.
A Anatomia de uma Leitura Lenta
Em 90% dos casos, o que faz um sistema parecer lento não é a velocidade de leitura do arquivo de 10GB, mas a latência para encontrar onde esse arquivo está (metadados) e ler os pequenos blocos aleatórios.
A estratégia de sobrevivência para 2025 é o Hibridismo Cirúrgico:
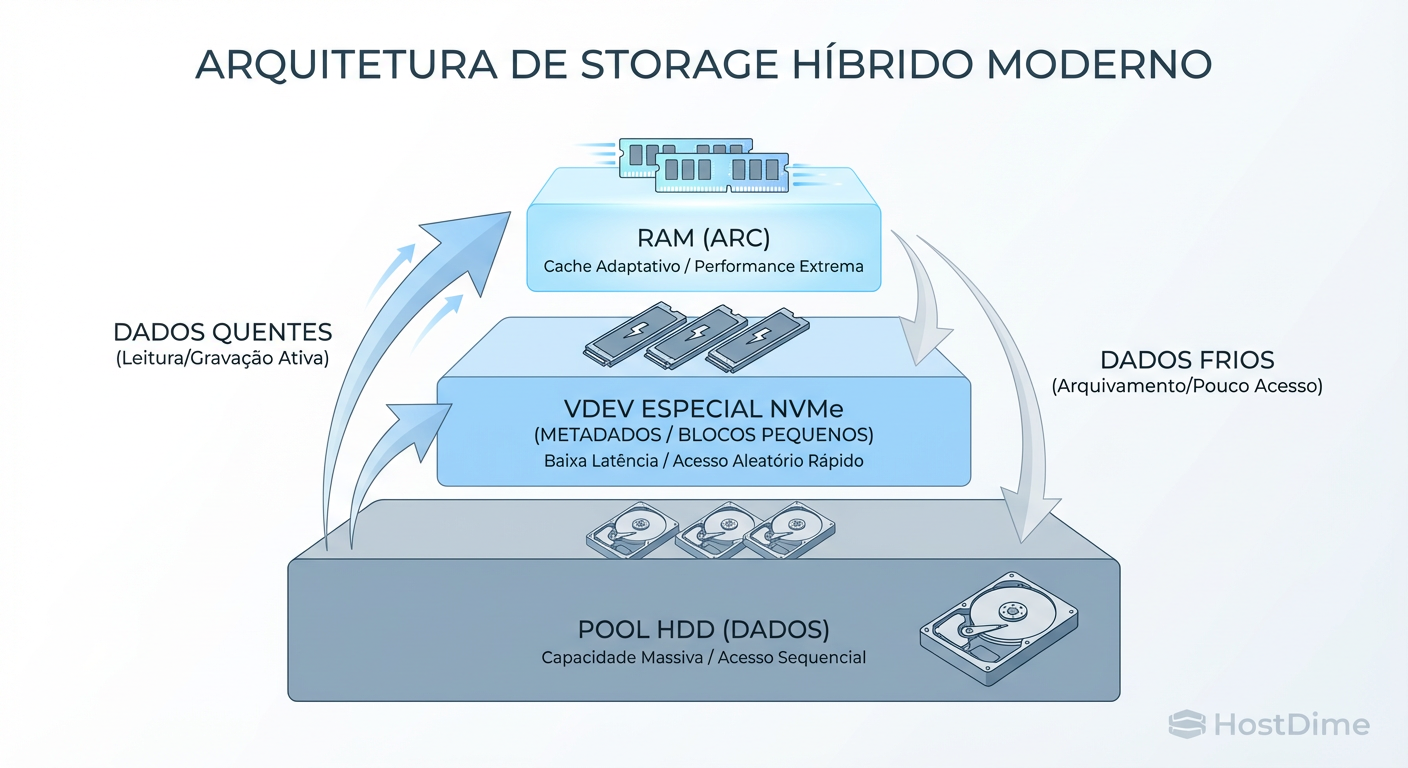 Figura: Estratégia de Sobrevivência ZFS: Usando NVMe apenas onde dói (Metadados e L2ARC).
Figura: Estratégia de Sobrevivência ZFS: Usando NVMe apenas onde dói (Metadados e L2ARC).
Ao usar NVMe apenas onde ele é insubstituível, reduzimos o custo do array em até 60% mantendo 90% da performance percebida.
No ZFS, isso se traduz em usar dispositivos de SPECIAL VDEV.
# Não copie e cole sem entender sua topologia
# 1. O Pool principal é feito de HDDs baratos (RAIDZ2 para segurança)
zpool create tank raidz2 /dev/sda /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
# 2. A Mágica: Adicionar NVMe espelhado EXCLUSIVAMENTE para Metadados e Blocos Pequenos
# Isso joga toda a árvore de diretórios e arquivos pequenos para o flash.
zpool add tank special mirror /dev/nvme0n1 /dev/nvme1n1
Com essa configuração, ls -R, find, e operações de banco de dados em tabelas pequenas voam na velocidade do NVMe, enquanto os arquivos grandes (backups, vídeos, logs) repousam nos HDDs baratos.
Riscos de Usar SSDs de Varejo em Produção (Consumer Grade)
Aqui entra o "jeitinho" perigoso. "Se o SSD Enterprise está caro, vou comprar 10 SSDs 'Gamer' de 4TB e colocar no servidor."
Como investigador forense de dados perdidos, peço que pare. A diferença entre um SSD Enterprise e um Consumer não é apenas velocidade ou garantia; é a Proteção contra Perda de Energia (PLP).
O Capacitor da Discórdia
SSDs Enterprise possuem capacitores físicos visíveis na placa. Quando a energia cai, eles mantêm o controlador vivo por milissegundos suficientes para descarregar o cache da DRAM para a NAND.
SSDs Consumer mentem. Eles dizem ao sistema operacional "Dados gravados!" (ACK), mas os dados ainda estão na DRAM volátil. Se a luz piscar, seu banco de dados corrompe.
Para mitigar isso, sistemas como ZFS ou bancos de dados forçam sync writes. Sem PLP, um SSD Consumer despenca de 500.000 IOPS para 500 IOPS em cargas síncronas, pois ele precisa esperar a gravação física na NAND lenta para confirmar.
Tabela Comparativa: O Custo Oculto
| Característica | SSD Consumer (Ex: 990 Pro) | SSD Enterprise (Ex: Micron 7450) | Impacto Real em 2025 |
|---|---|---|---|
| Power Loss Protection (PLP) | Inexistente | Hardware Dedicado | Crítico: Sem PLP, sync writes são 100x mais lentas ou inseguras. |
| Consistência de Latência | Péssima (picos de 50ms+) | Estável (<500µs) | Alto: "Soluços" no banco de dados durante Garbage Collection. |
| Endurance (DWPD) | 0.3 a 0.6 | 1.0 a 3.0+ | Médio: IA exige 3.0, mas seu DB talvez viva bem com 1.0. |
| Custo por TB | Baixo | Alto (Crise de Oferta) | O barato que sai caro se houver corrupção. |
Checklist de Mitigação: O que Medir Antes de Comprar Storage
Não assine a compra baseada em "capacidade total". Use a metodologia forense para dimensionar apenas o necessário.
Meça o "Working Set" Real: Não compre flash para todos os seus dados. Use ferramentas (como
arc_summaryno ZFS ou contadores de I/O do Windows) para descobrir quantos dados são acessados frequentemente.- Ação: Se você tem 100TB de dados, mas só acessa 5TB diariamente, você precisa de 5TB de Flash (Cache/Tier 1) e 95TB de HDD.
Verifique a Taxa de Escrita Síncrona: Se sua aplicação faz muito
fsync(bancos de dados, NFS, iSCSI), SSDs de varejo vão travar seu sistema.- Ação: Teste com
fioforçandofsync=1. Se o IOPS cair para dois dígitos, você precisa de Enterprise SSD ou Optane (se encontrar).
- Ação: Teste com
Audite a Vida Útil Restante (Wear Leveling): Antes de comprar hardware usado ou recondicionado (comum em tempos de crise), exija o relatório SMART.
- Ação: Procure por
Percentage Used. Se estiver acima de 10-15% em um drive "novo", é suspeito.
- Ação: Procure por
Isole os Logs de Escrita (SLOG/WAL): Se não puder pagar all-flash, compre dois SSDs Enterprise pequenos (ex: 400GB) e de altíssima resistência apenas para o log de escrita (ZIL/SLOG).
- Ação: Isso protege os dados e acelera as escritas, permitindo usar SSDs mais baratos (Read Intensive) para o armazenamento principal.
A crise do NVMe de 2025 é um teste de competência arquitetural. Quem apenas "compra hardware" vai estourar o orçamento ou perder dados. Quem entende o fluxo de I/O e aplica tiering inteligente vai sobreviver com desempenho de sobra.
Referências & Leitura Complementar
JEDEC SSD Specifications: Para definições técnicas de endurance e retenção de dados (JESD218/JESD219).
OpenZFS Documentation (Special Allocation Class): Detalhes técnicos sobre a implementação de vdevs especiais para metadados.
Micron/Samsung Technical Briefs (2024-2025): Relatórios de mercado sobre alocação de wafers para AI/HPC (frequentemente encontrados em portais de investidores).
PostgreSQL WAL Configuration: Documentação sobre como o Write Ahead Log interage com latência de disco e fsync.

Priya Patel
Data Center Operations Lead
Gerencia milhares de discos físicos. Sabe exatamente qual modelo de HDD vibra mais e qual SSD morre primeiro.