O Paradoxo de Performance do Ceph: Por que seus Benchmarks estão Mentindo
Entenda por que o Ceph parece lento em testes sintéticos mas escala em produção. Aprenda a medir latência distribuída, fila de I/O e a evitar a armadilha do 'dd'.
Você acabou de aprovar um orçamento de seis dígitos. O cluster Ceph All-Flash NVMe está montado, a rede é 100GbE e a expectativa está no teto. Então, um administrador roda um comando dd simples para testar a velocidade e o rosto dele fica pálido. "Chefe, estamos conseguindo apenas 300 MB/s. Meu laptop faz mais que isso."
Bem-vindo ao Paradoxo de Performance do Ceph.
Se você tentar medir um sistema de armazenamento distribuído (SDS) com a mesma régua que usa para um disco local, os números não apenas serão decepcionantes; eles serão tecnicamente irrelevantes. O problema não é o hardware, e raramente é a configuração padrão do Ceph. O problema é a física do armazenamento distribuído e a incapacidade das ferramentas legadas de entenderem o conceito de paralelismo massivo.
O Paradoxo do Ceph: O Ceph é projetado para throughput agregado (largura de banda total de milhares de clientes), não para latência de thread único (velocidade de um único processo). Enquanto um disco local vence em latência pura (nanossegundos), o Ceph vence em escalabilidade linear. Julgar o Ceph por uma única operação de escrita sequencial é como julgar a capacidade de carga de um trem de carga cronometrando a velocidade de um único vagão em uma corrida de 100 metros contra uma Ferrari.
O Choque da Física no Storage Distribuído vs. Local
Para entender por que seus benchmarks estão "mentindo", precisamos dissecar o caminho do dado. Quando você grava em um SSD local (NVMe), o caminho é curto: CPU -> Barramento PCIe -> Flash. A latência é medida em microssegundos.
No Ceph, a "física" muda. O armazenamento não é um dispositivo; é um serviço de rede com garantias de consistência.
Uma gravação no Ceph envolve:
Serialização do dado no cliente.
Cálculo do algoritmo CRUSH para saber onde o dado vai.
Transmissão pela rede (TCP/IP overhead).
Processamento na CPU do servidor (OSD).
Gravação no Journal/WAL (Write Ahead Log).
Replicação para outros nós (fator de replicação, geralmente 3x).
Isso nos leva a um trade-off inevitável que arquitetos experientes conhecem bem: Latência vs. Durabilidade.
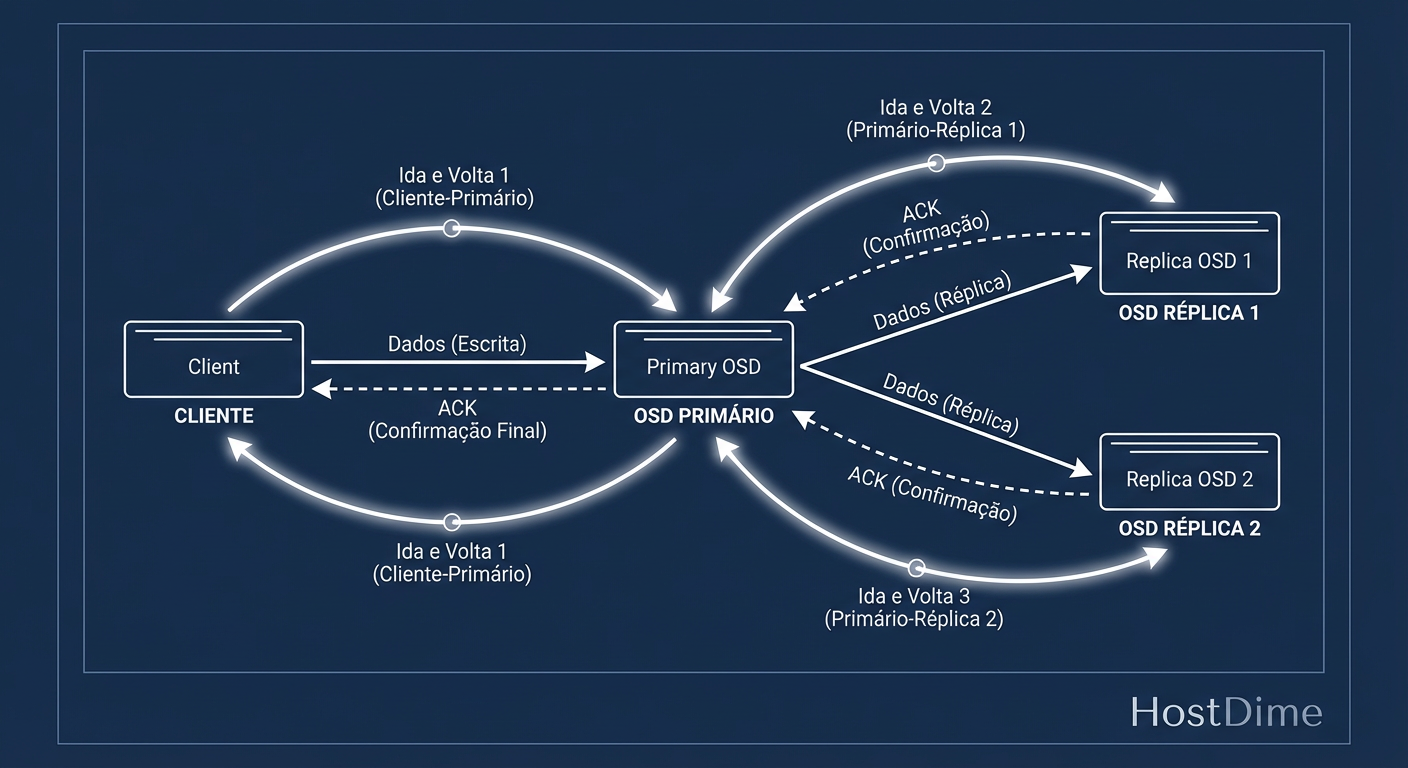 Figura: O Ciclo da Escrita Segura: A latência do Ceph é a soma do RTT da rede + gravação em disco x3 (replicação).
Figura: O Ciclo da Escrita Segura: A latência do Ceph é a soma do RTT da rede + gravação em disco x3 (replicação).
Como ilustrado acima, a latência de escrita que você vê no terminal do cliente é, na verdade, a soma do tempo de viagem (RTT) da rede mais o tempo de gravação em disco, multiplicado pela necessidade de confirmação dos pares. O Ceph não confirma a gravação ("ack") até que os dados estejam seguros em todas as réplicas ativas. Se você tem latência de rede de 0.5ms entre nós, sua latência de escrita mínima teórica já começa com uma penalidade que um disco local não tem.
A Mentira do 'dd': Por que Testes Sequenciais Mono-Thread Falham
A ferramenta dd é onipresente, mas é a pior ferramenta possível para medir storage distribuído.
O comando clássico dd if=/dev/zero of=/mnt/ceph/test bs=1G count=1 é um teste de latência, não de largura de banda.
Por que isso acontece?
Queue Depth (QD) de 1: O
ddenvia um bloco, espera a confirmação, envia o próximo. O Ceph passa a maior parte do tempo ocioso esperando o sinal de "ok" da rede entre um bloco e outro.Single Thread: Você está usando apenas um núcleo de CPU para gerar carga contra um cluster que tem, talvez, centenas de núcleos de OSDs disponíveis.
A analogia da mudança: Imagine que você precisa mudar de casa.
Teste
dd: Você pega uma caixa, leva até o caminhão, volta para a casa, pega outra caixa. Não importa o tamanho do caminhão (largura de banda), você é limitado pela velocidade das suas pernas (latência).Cenário Real (Cloud/VMs): Você contrata 50 pessoas (threads/VMs) para carregar caixas simultaneamente. O caminhão enche instantaneamente.
Se o seu benchmark não preenche a fila de operações (Queue Depth), você está medindo a distância do cabo de rede, não a velocidade do storage.
A Ilusão do Cache e o Perigo de Medir a RAM
Outro erro comum que infla o ego (e depois destrói a produção) é o benchmark que acidentalmente mede a RAM.
Se você rodar um teste e obtiver 10GB/s em uma rede de 10Gbps, a física diz que é impossível. O que aconteceu? Você escreveu no Page Cache do Linux do cliente, ou no cache de RAM do OSD, e o teste terminou antes que os dados fossem forçados para o disco (flush).
Como identificar a Ilusão do Cache:
Resultados "Rápidos Demais": Velocidades superiores ao link físico de rede.
Queda Abrupta: O teste começa em 2GB/s e depois de 10 segundos cai para 300MB/s (o buffer encheu).
Para um Arquiteto de Soluções, IOPS de cache não pagam as contas. Precisamos saber o desempenho sustentado quando o cache acaba. Por isso, testes sérios no Ceph devem usar flags como O_DIRECT ou fsync a cada operação para garantir que estamos medindo a capacidade do sistema de persistir dados, que é a função primária de um storage enterprise.
Paralelismo e Queue Depth: Onde o Ceph Realmente Escala
Aqui está o segredo que separa os administradores juniores dos engenheiros de storage sêniores: O Ceph precisa de pressão para performar.
Discos locais saturam rápido. O Ceph, por ser distribuído, escala quase linearmente com o aumento da profundidade de fila (Queue Depth - QD) e número de jobs simultâneos. Quanto mais requisições você joga nele, mais inteligente ele fica em agrupar, ordenar e despachar essas gravações para centenas de discos em paralelo.
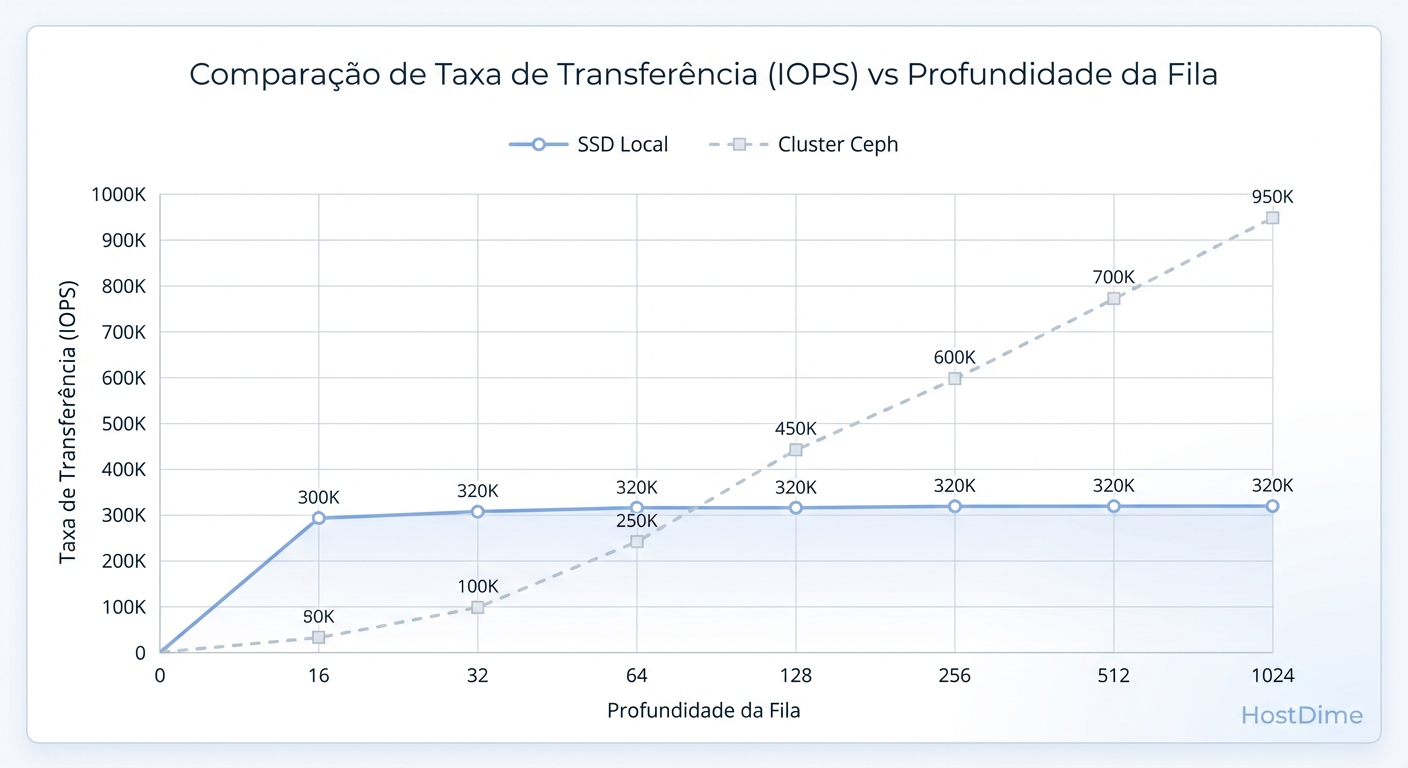 Figura: Escalabilidade vs. Latência: O Ceph precisa de profundidade de fila (Queue Depth) para brilhar, ao contrário de discos locais que saturam cedo.
Figura: Escalabilidade vs. Latência: O Ceph precisa de profundidade de fila (Queue Depth) para brilhar, ao contrário de discos locais que saturam cedo.
Observe a diferença fundamental:
Local Storage: A latência explode assim que você satura o controlador local.
Ceph: A latência sobe, mas o throughput (IOPS/Bandwidth) continua subindo junto até atingir o limite físico da rede ou dos discos backend.
Tabela Comparativa: Local vs. Ceph (Expectativa Realista)
| Característica | Local NVMe (RAID 10) | Ceph Cluster (NVMe) | Veredito do Arquiteto |
|---|---|---|---|
| Latência (QD=1) | < 0.1 ms | 1 ms - 3 ms | Local vence para apps single-thread sensíveis (ex: logs síncronos antigos). |
| Escalabilidade | Limitada à controladora/CPU local | Linear (adicione nós = mais IOPS) | Ceph vence em ambientes de virtualização/cloud. |
| Segurança | Falha de 1-2 discos | Falha de nós inteiros ou racks | Ceph é desenhado para "No Single Point of Failure". |
| Throughput Agregado | Alto (até saturar barramento) | Massivo (limitado apenas pelo budget) | Ceph brilha com 100+ VMs acessando simultaneamente. |
Como Executar Benchmarks no Ceph Corretamente com FIO
Esqueça o dd. A ferramenta padrão da indústria é o fio (Flexible I/O Tester). E, crucialmente, não teste através do sistema de arquivos montado (Kernel RBD map) se você quiser testar o cluster. Teste diretamente contra a API do Ceph usando a engine rbd. Isso remove o overhead do kernel do cliente da equação e isola o desempenho do storage.
O "Golden Standard" do Benchmark Ceph
Aqui está um exemplo de job file para o fio que testa o que realmente importa: IOPS randômicos (padrão de banco de dados) com paralelismo adequado.
# Crie um volume de teste primeiro
rbd create pool_teste/bench_vol --size 100G
# Execute o FIO (não use sudo se configurado corretamente)
fio --name=ceph-random-write \
--ioengine=rbd \
--pool=pool_teste \
--rbdname=bench_vol \
--rw=randwrite \
--bs=4k \
--direct=1 \
--numjobs=4 \
--iodepth=64 \
--runtime=60 \
--group_reporting
Parâmetros Críticos Explicados:
ioengine=rbd: Fala diretamente com o cluster, sem passar pelo sistema de arquivos local.direct=1: Ignora o cache de RAM do cliente. A verdade nua e crua.iodepth=64enumjobs=4: Simula uma carga real de virtualização (256 IOs em voo). É aqui que o Ceph acorda.bs=4k: Tamanho de bloco padrão para bancos de dados e discos virtuais. Se você testar com 4M, terá números bonitos de throughput, mas irreais para IOPS.
Métricas Críticas: Tail Latency e Commit On-Disk
Ao analisar a saída do fio ou seus dashboards do Grafana, cuidado com a "Média". A média é o refúgio dos mentirosos estatísticos.
Em sistemas distribuídos, a métrica rainha é a Tail Latency (Latência de Cauda) ou Percentil 99 (p99).
Média: 2ms (Parece ótimo).
p99: 500ms (Catastrófico).
O que isso significa? Que 99% das suas requisições são rápidas, mas 1% demora meio segundo. Em um banco de dados transacional processando milhares de requisições, esse 1% vai causar locks que paralisam a aplicação inteira.
No Ceph, a latência de cauda geralmente é causada por:
Slow OSDs: Um disco falhando ou uma CPU sobrecarregada em um único nó.
Network Jitter: Micro-cortes ou buffers de switch cheios.
Deep Scrubbing: O processo de manutenção do Ceph competindo com I/O de produção (configure o
osd_scrub_begin_hourpara janelas noturnas).
Resumo para Decisão
Se o seu workload é um banco de dados legado, monolítico, que faz fsync a cada transação e não suporta paralelismo: Não use Ceph. Use NVMe local ou SAN tradicional de baixa latência.
Se o seu workload é virtualização (KVM, OpenStack, Proxmox), Kubernetes, Object Storage ou Big Data: O Ceph é imbatível, desde que você meça o throughput agregado e entenda que a latência individual paga o "imposto" da replicação tripla.
Referências & Leitura Complementar
Para aprofundar seu entendimento técnico e validar as afirmações acima, consulte as seguintes documentações e padrões da indústria:
Ceph Documentation - Architecture: Detalhes sobre o algoritmo CRUSH e fluxo de dados RADOS.
Jens Axboe's FIO Documentation: Manual oficial da ferramenta de benchmark padrão (fio.readthedocs.io).
Intel Whitepaper: "Ceph Storage Performance Optimization on Intel Architecture" – Análise detalhada de tunning de hardware.
RFC 3720 (iSCSI) & NVMe-oF Specs: Para comparação de protocolos de bloco sobre rede.
Brendan Gregg - Systems Performance: O livro definitivo sobre metodologias de análise de desempenho (USE Method).

Marcelo Furtado
Ceph Cluster Administrator
Escala clusters Ceph para o infinito. Mestre em CRUSH maps e recuperação de placement groups.