Parity Scrubbing Automatizado: A Única Defesa Real Contra o Bit Rot
O bit rot é silencioso e inevitável. Aprenda como o Parity Scrubbing automatizado detecta e corrige corrupção de dados antes que seja tarde demais. Guia prático para ZFS, MDADM e Btrfs.
Você não confia no seu disco rígido. Se você confia, é porque ainda não perdeu dados suficientes. Como arquiteto, a premissa base de qualquer desenho de solução de storage é simples: o hardware mente. O disco diz que gravou o dado, o controlador diz que verificou, e o sistema operacional acredita. Enquanto isso, um raio cósmico, uma flutuação de voltagem ou um bug de firmware inverteu um bit silenciosamente.
Isso é o Bit Rot (apodrecimento de bits). E backups não resolvem isso — backups apenas copiam o arquivo corrompido para outro lugar, garantindo que você tenha múltiplas cópias do seu desastre. A única defesa real é a verificação ativa e contínua: o Parity Scrubbing.
Não estamos falando de "passar um scandisk". Estamos falando de matemática aplicada à sobrevivência de dados. Vamos dissecar como implementar isso, por que o RAID de hardware falha miseravelmente nessa tarefa e como automatizar o processo sem derrubar a performance da sua produção.
O Que é Parity Scrubbing? Parity Scrubbing é o processo automatizado de leitura sequencial de todos os blocos de dados e paridade em um array de armazenamento para validar a integridade. Diferente de uma leitura comum, o scrubbing recalcula os checksums ou a paridade esperada e os compara com o que está gravado no disco, identificando e corrigindo corrupções silenciosas (bit rot) antes que elas se tornem irrecuperáveis.
A Anatomia do Bit Rot e a Degradação Silenciosa
A maioria dos administradores opera sob o modelo mental de que um disco tem dois estados: "Funcionando" ou "Falho". Isso é falso. O estado mais perigoso é o "Funcionando, mas mentindo".
O Silent Data Corruption ocorre quando os dados lidos do disco diferem dos dados gravados, mas o subsistema de disco não reporta erro. Discos modernos possuem ECC (Error Correction Code) interno, mas eles falham. Cabos SATA/SAS oxidam e causam erros de transmissão transitórios. Firmwares de SSDs possuem bugs de wear leveling.
Se você não está procurando ativamente por esses erros, você só os descobrirá quando tentar ler aquele arquivo crítico de 3 anos atrás. Nesse ponto, o bit rot já pode ter destruído o arquivo original e todas as versões dele no seu backup incremental.
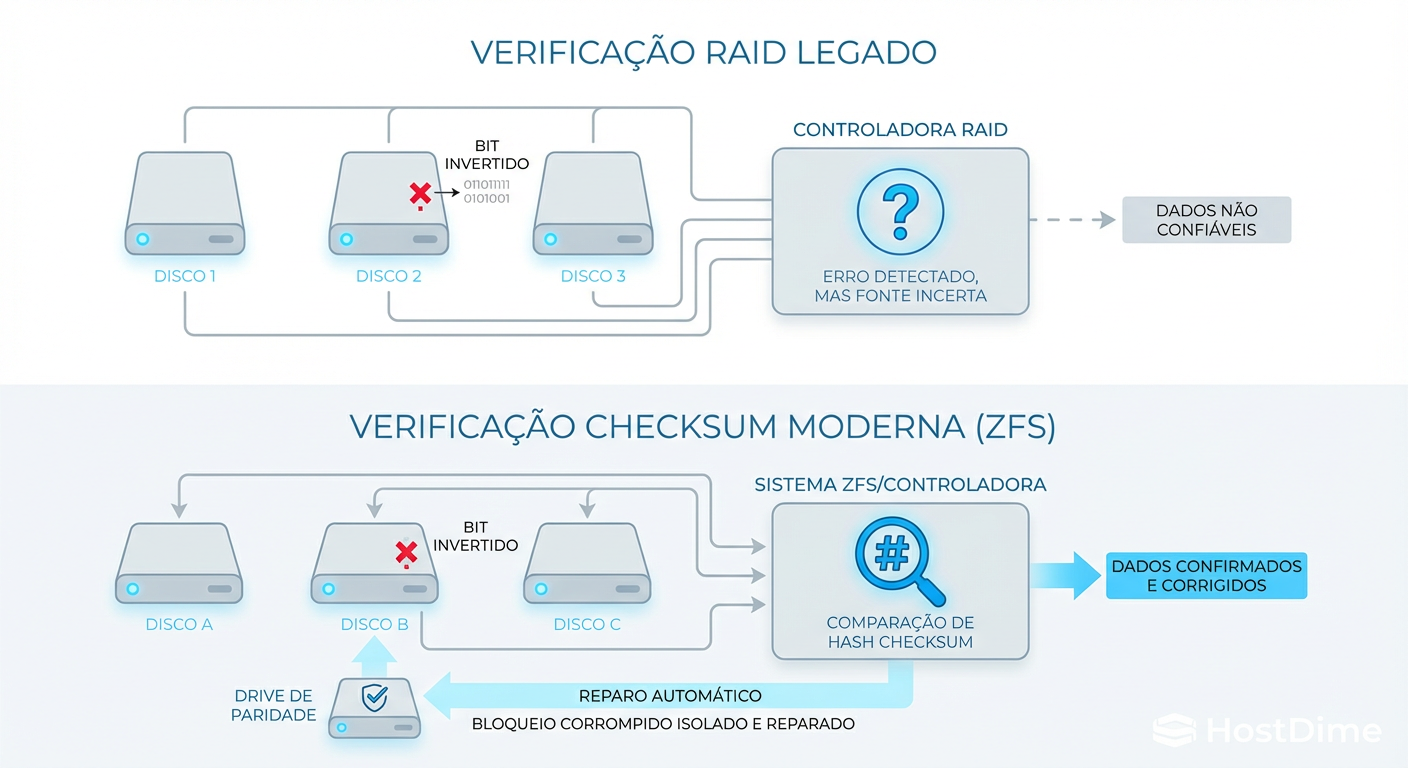 Figura: A Ilusão da Segurança: Por que a verificação de paridade simples (Legacy RAID) não garante a integridade dos dados como o Checksumming moderno.
Figura: A Ilusão da Segurança: Por que a verificação de paridade simples (Legacy RAID) não garante a integridade dos dados como o Checksumming moderno.
ZFS vs. RAID Tradicional: A Falha do Hardware RAID no Scrubbing
Aqui reside o maior trade-off arquitetural entre Hardware RAID e Software Defined Storage (como ZFS ou Btrfs).
O Hardware RAID tradicional (RAID 5/6) realiza o que chamam de "Patrol Read" ou "Consistency Check". No entanto, ele é cego semanticamente. Se o controlador lê um bloco de dados e a paridade não bate, ele sabe que algo está errado. Mas ele não sabe quem está mentindo: o dado ou a paridade? Em muitos casos, o controlador assume que o dado está certo e reescreve a paridade, "cimentando" a corrupção para sempre.
O ZFS (e Btrfs) muda o jogo com Checksumming Hierárquico. O ZFS não confia no disco. Ele armazena o checksum do bloco no ponteiro do bloco "pai". Quando o ZFS faz um scrub:
Ele lê o dado.
Calcula o hash (ex: SHA-256/Fletcher4).
Compara com o checksum armazenado no pai.
Se não bater, ele sabe com certeza matemática que aquele bloco está corrompido.
Ele usa a paridade (RAIDZ) ou o espelho (Mirror) para reconstruir o dado correto e sobrescrever o bloco ruim.
Tabela Comparativa: Capacidade de Detecção e Correção
| Recurso | Hardware RAID (Patrol Read) | ZFS / Btrfs (Scrub) | Linux MDADM (Software RAID) |
|---|---|---|---|
| Verificação de Leitura | Verifica se o setor é legível | Verifica integridade do conteúdo (Checksum) | Verifica se o setor é legível |
| Detecção de Bit Rot | Limitada (Inconsistência de Paridade) | Total (Falha de Checksum) | Limitada (Mismatch count) |
| Auto-Correção | Adivinhação (Geralmente confia no dado) | Determinística (Sabe qual cópia é válida) | Manual ou Adivinhação |
| Consciência de Dados | Não (Scrub em espaço vazio) | Sim (Scrub apenas em dados alocados) | Não (Scrub no disco inteiro) |
Implementação Prática: Automatizando Scrubs
A automação é a única maneira de garantir que o scrubbing ocorra. Depender de memória humana é falha de arquitetura.
Automatizando Scrubbing no ZFS
No Linux, o pacote zfs-utils geralmente já instala um timer do systemd, mas ele pode não estar ativado.
Para verificar o status e ativar:
systemctl status zfs-scrub-monthly@zpool_data.timer
# Ativar para um pool específico (ex: 'tank')
systemctl enable --now [email protected]
Se você prefere controle via cron (comum em BSDs ou distros legadas), a sintaxe é direta:
# Executar no dia 1 e 15 de cada mês às 02:00
0 2 1,15 * * /sbin/zpool scrub tank
Automatizando Scrubbing no MDADM (Linux Raid)
O MDADM chama isso de check. Em sistemas baseados em Debian/Ubuntu, isso é controlado pelo script /etc/cron.d/mdadm.
Para forçar um check manual ou criar seu próprio agendamento:
# Iniciar verificação no /dev/md0
echo check > /sys/block/md0/md/sync_action
Cuidado: O MDADM apenas conta os erros (mismatch_cnt). Ele não corrige automaticamente a menos que você execute um repair, o que é perigoso se você não souber qual disco está errado. O fluxo recomendado é: check -> Alertar Admin -> Diagnosticar -> Substituir disco ou repair.
O Trade-off de Performance e Latência no Scrubbing
O scrubbing é uma operação de I/O intensiva. Ele compete diretamente com sua aplicação por IOPS e throughput. Se você rodar um scrub a toda velocidade em um array de HDDs mecânicos durante o horário comercial, sua latência vai explodir.
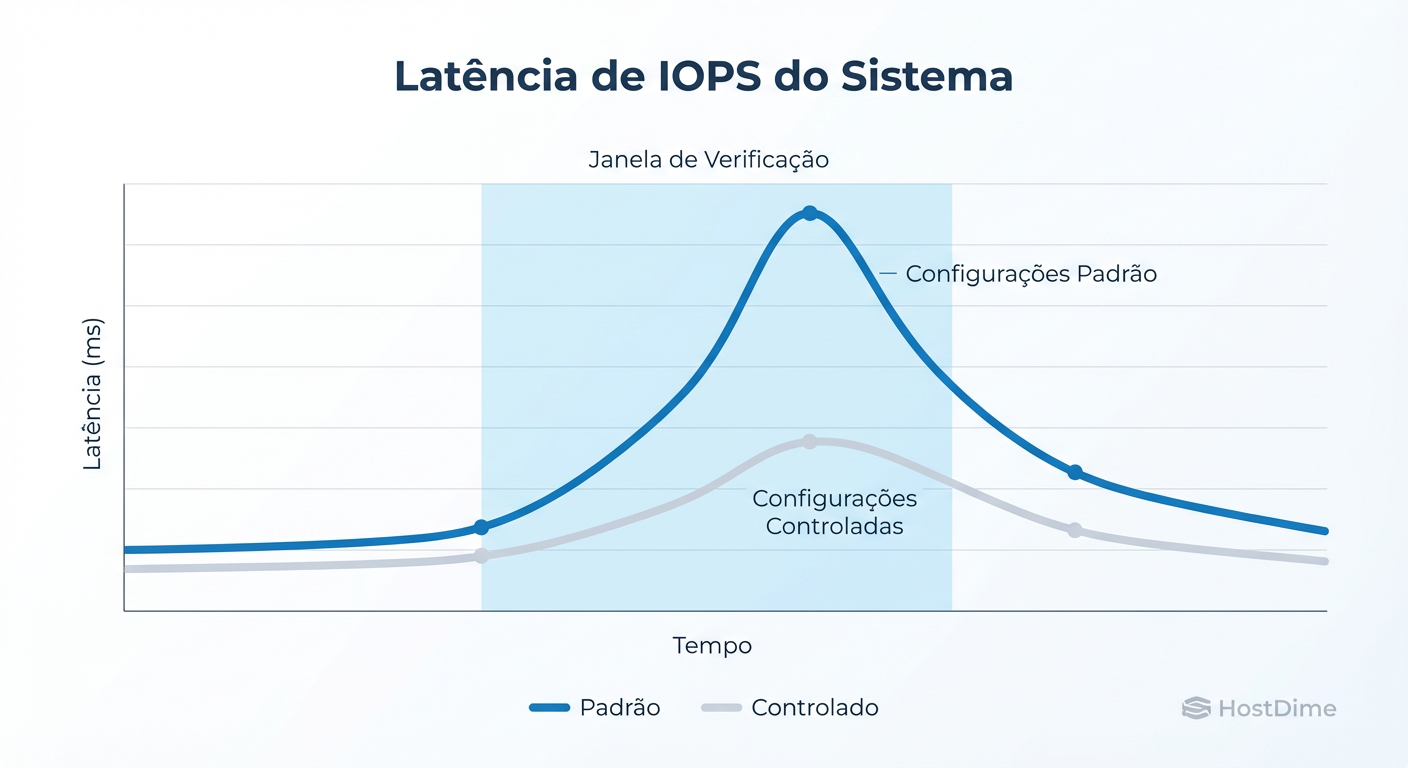 Figura: Impacto do Scrubbing na Latência: O custo oculto da manutenção e como o 'Throttling' evita que seu storage engasgue a produção.
Figura: Impacto do Scrubbing na Latência: O custo oculto da manutenção e como o 'Throttling' evita que seu storage engasgue a produção.
Ajustando a Agressividade (Throttling)
Você precisa configurar o sistema para priorizar a produção sobre a manutenção, mas sem pausar a manutenção eternamente.
No ZFS:
O parâmetro zfs_scrub_delay define quantos "ticks" o ZFS espera entre I/Os de scrub se houver outra atividade no disco.
# Verificar valor atual (padrão costuma ser 4)
cat /sys/module/zfs/parameters/zfs_scrub_delay
# Aumentar para ser mais gentil com a latência (ex: 20)
echo 20 > /sys/module/zfs/parameters/zfs_scrub_delay
Nota: Se o valor for muito alto e seu array for muito grande, o scrub pode nunca terminar. É um equilíbrio de TCO: quanto vale a performance vs. a janela de risco?
No MDADM: Você controla pelos limites de velocidade de reconstrução:
# Definir mínimo e máximo em KB/s
echo 1000 > /proc/sys/dev/raid/speed_limit_min
echo 200000 > /proc/sys/dev/raid/speed_limit_max
Estratégia de Agendamento: Frequência Ideal
A resposta padrão de consultor é "depende", mas vamos quantificar esse "depende".
Discos de Consumidor (SATA não-Enterprise): Scrub Semanal. A taxa de erro não recuperável (URE) é maior (geralmente 1 em 10^14 bits).
Discos Enterprise (SAS/Nearline): Scrub Mensal. Eles são mais robustos, e o scrub causa desgaste mecânico.
SSDs NVMe: Scrub Mensal ou Trimestral. O bit rot em flash é real (vazamento de carga da célula), mas a leitura intensiva desgasta menos o dispositivo do que em mecânicos, embora consuma ciclos de P/E indiretamente.
O Fator Capacidade: Se você tem um pool de 100TB que leva 4 dias para fazer scrub, rodar semanalmente significa que seu array estará em estado de performance degradada mais de 50% do tempo. Nesse cenário, mensal é o único viável.
Análise de Métricas: Interpretando o 'zpool status'
Não basta rodar o scrub; você precisa interpretar a saída.
zpool status -v
Foque nas colunas:
READ: Erro de I/O. O disco falhou em entregar o dado. Mau sinal. Cabo ou disco morrendo.
WRITE: O disco falhou em gravar. Geralmente o disco entra em modo Faulted logo depois.
CKSUM (O mais crítico): O disco entregou o dado, mas o dado estava errado.
- Se CKSUM > 0 em um disco: Provável Bit Rot ou cabo ruim. Monitore. Se aumentar no próximo scrub, substitua o disco.
- Se CKSUM > 0 em TODOS os discos simultaneamente: O problema não é o disco. É a controladora (HBA), a backplane ou a memória RAM (se não for ECC).
Ação Imediata: Se o ZFS reportar "Permanent errors have been detected" na lista de arquivos, esses arquivos estão perdidos. Restaure do backup. O scrub fez o trabalho dele: te avisou que o dado morreu, em vez de te entregar lixo silenciosamente.
Veredito Técnico
Implementar Parity Scrubbing automatizado não é "melhoria de processo", é requisito funcional de qualquer arquitetura de armazenamento que pretenda durar mais que a garantia dos discos. Hardware falha, bits viram, e a entropia sempre vence no final. O scrub é a única ferramenta que permite que você lute contra a entropia de forma proativa.
Configure seus timers hoje. Verifique seus logs amanhã. Não espere o erro de leitura para descobrir que seus dados já se foram.
Referências & Leitura Complementar
Bonwick, J. & Moore, B. (2007). ZFS: The Last Word in File Systems. Sun Microsystems. (Conceitos fundamentais de end-to-end data integrity).
Jiang, W. et al. (2008). An Analysis of Data Corruption in the Storage Stack. FAST '08 Proceedings. (Estudo empírico sobre como a corrupção ocorre).
OpenZFS Documentation. Scrub and Resilver Performance Tuning.
Linux Kernel Documentation. RAID/MDADM sysfs tunables (Documentation/md.txt).

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.