Paths Ativo Ativo Vs Ativo Passivo Implicacoes
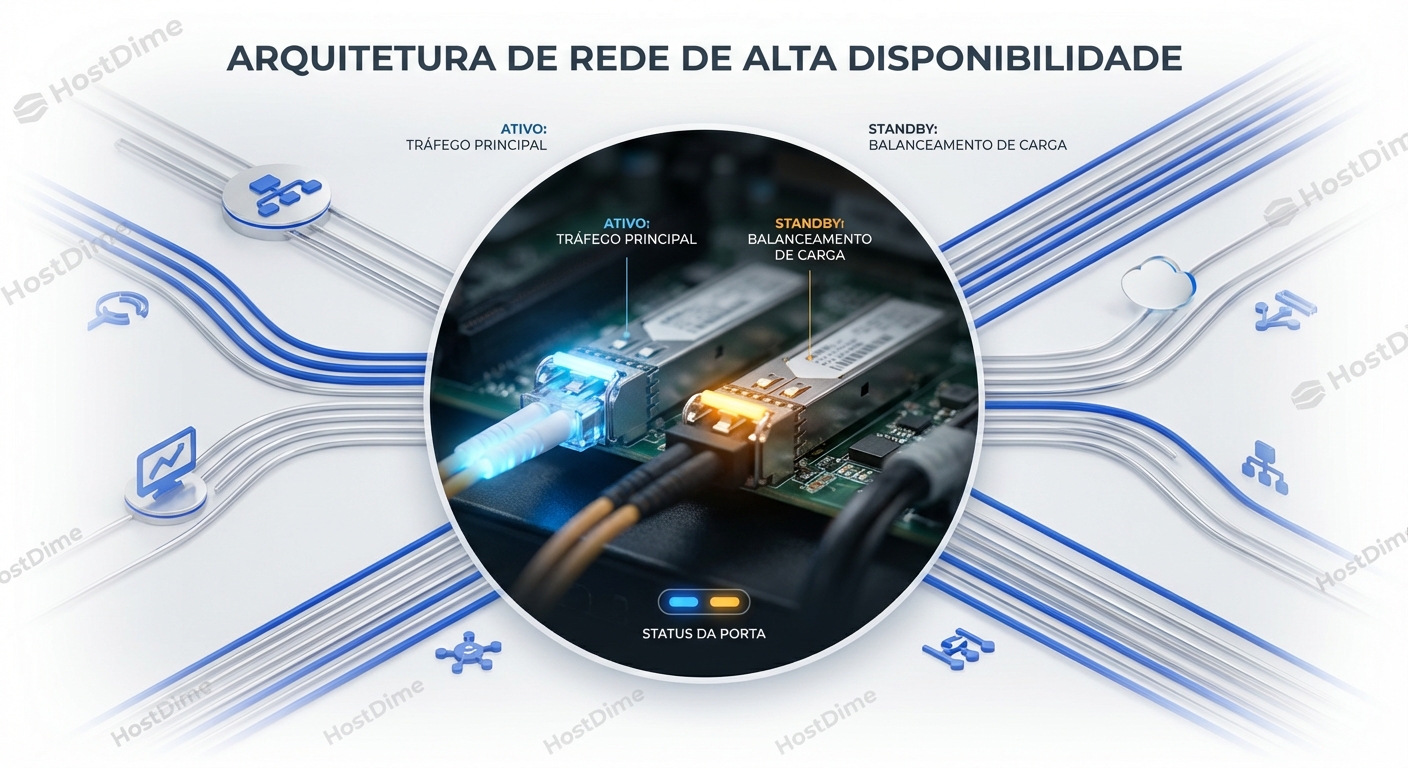
Para entender o tráfego de I/O moderno, esqueça os diagramas de rede por um minuto. Vamos usar uma analogia de logística física....
Paths Ativo Ativo Vs Ativo Passivo Implicacoes
A Ilusão da Recepção do Hotel
Para entender o tráfego de I/O moderno, esqueça os diagramas de rede por um minuto. Vamos usar uma analogia de logística física.
Imagine que seu Storage Array é um grande hotel de luxo. Os dados (LUNs) são os hóspedes nos quartos. Os Controladores (Storage Processors - SPs) são os recepcionistas no balcão. Você é o entregador de pizza (Host).
Existem três formas de operar esse balcão:
- Ativo-Passivo (Legado): Existe apenas um recepcionista (Controller A). O Controller B está dormindo na sala dos fundos. Se você entregar a pizza para o B, ele não aceita. Você tem que esperar o A morrer para o B acordar, vestir o uniforme e assumir o balcão. O tempo de inatividade é visível e doloroso.
- Ativo-Ativo Simétrico (O Santo Graal): Existem dois recepcionistas. Ambos têm as chaves de todos os quartos. Não importa para quem você entrega a pizza, o tempo para ela chegar ao quarto é idêntico. Isso existe (ex: high-end enterprise arrays, clusters vSAN, alguns sistemas distribuídos), mas é complexo e caro manter a coerência de cache entre dois cérebros que escrevem no mesmo lugar ao mesmo tempo.
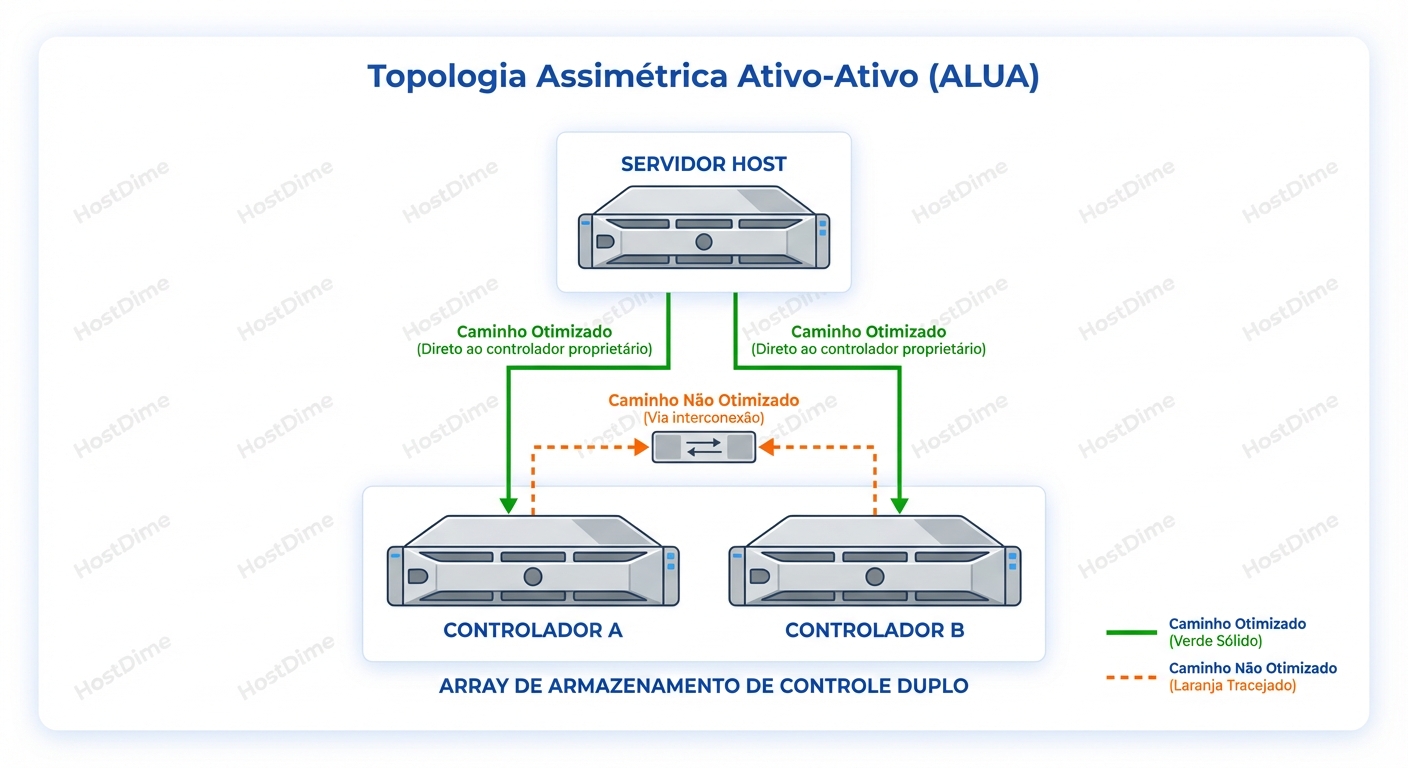
- Ativo-Ativo Assimétrico (ALUA): É aqui que 90% dos storages modernos de médio porte (Mid-range) vivem. Ambos os recepcionistas estão no balcão sorrindo. Ambos aceitam a pizza. Porém, apenas o Controller A tem a chave do quarto 101.
Se você entregar a pizza do quarto 101 para o Controller A, ele sobe o elevador e entrega. Rápido. Se você entregar a pizza do quarto 101 para o Controller B (que não é o dono daquele LUN), ele aceita o pacote, vira para trás, caminha por um corredor interno longo e estreito até o Controller A, e pede para o A entregar.
Esse "corredor interno" é o Interconnect ou Backplane. E essa volta extra é o que chamamos de Non-Optimized Path.
O marketing chama isso de "Ativo-Ativo" porque ambas as portas aceitam I/O. Mas para nós, engenheiros, isso é uma armadilha de latência. O host vê o caminho como "Up/Active", mas o custo de travessia é radicalmente diferente.
Under the Hood: ALUA (Asymmetric Logical Unit Access)
ALUA é o padrão SCSI que permite ao storage dizer ao host: "Olha, eu aceito I/O nessa porta, mas se você puder mandar pela outra, eu agradeço".
Quando um host escaneia os caminhos SCSI, o array retorna um Target Port Group (TPG). Cada caminho é classificado com um estado de acesso. Os dois que mais importam para nós são:
- Active/Optimized: O caminho vai direto para o controlador que "possui" o LUN e tem o cache de escrita travado para ele. Latência: Baixa.
- Active/Non-Optimized: O caminho vai para o controlador parceiro. O I/O precisa atravessar o link C2C (Controller-to-Controller). Isso adiciona latência de transporte e, pior, consome ciclos de CPU do controlador parceiro apenas para fazer proxy de dados.
O Custo do Interconnect
O link entre controladores (seja PCIe, InfiniBand ou SAS proprietário) não é infinito. Ele é projetado primariamente para espelhamento de cache de escrita (para redundância) e heartbeat. Quando você começa a forçar leituras/escritas maciças através desse link porque configurou mal o multipath, você pode saturar esse canal.
O resultado? Latência de disco aumenta, mas o pior efeito colateral é que a latência de commit de escrita aumenta globalmente, pois o espelhamento de cache começa a competir com o tráfego de dados desviado. Você pode derrubar a performance de todo o array, não apenas daquele LUN, simplesmente enviando os dados para a porta errada.
O Vilão: Path Thrashing e Round-Robin Cego
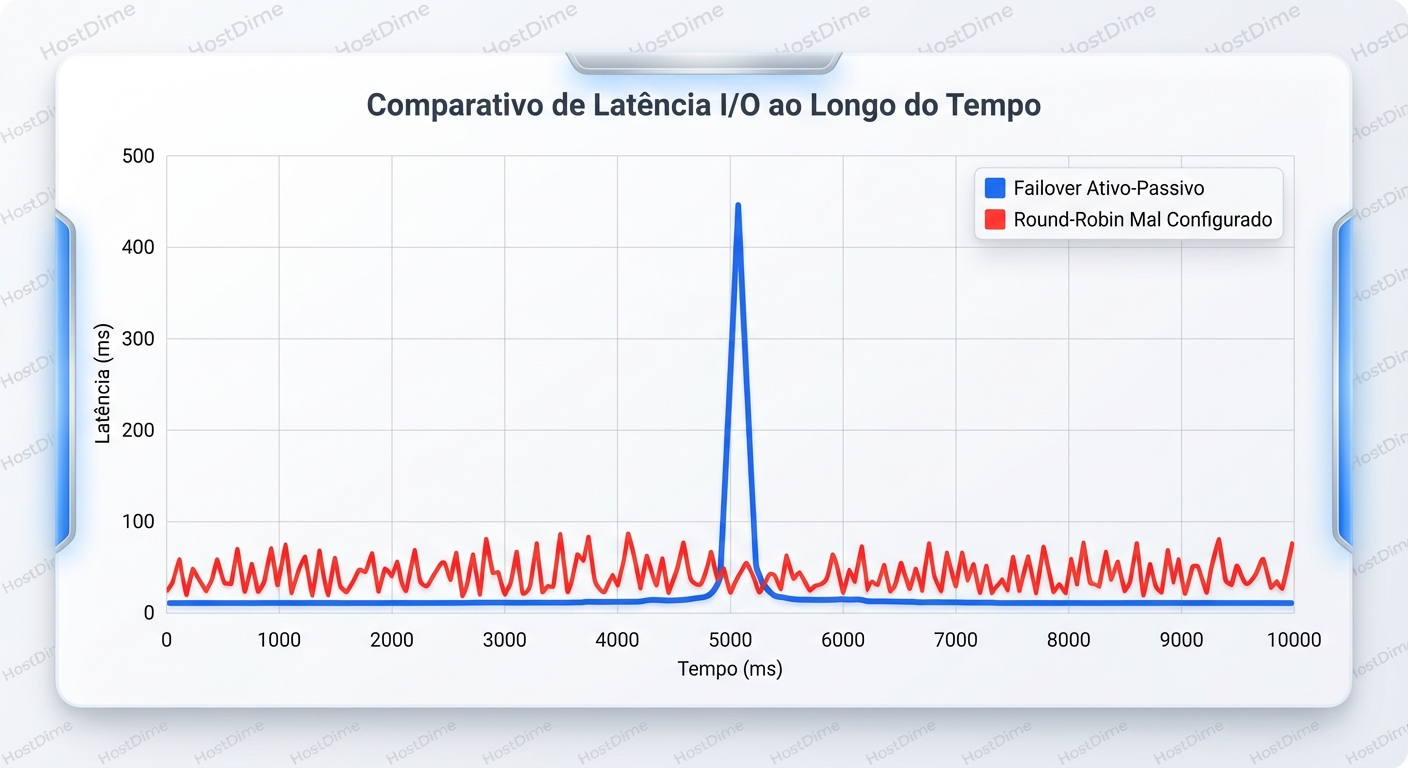
Aqui voltamos ao chamado do DBA. Por que a latência estava serrilhada?
O administrador configurou o multipathing no servidor (Linux DM-Multipath ou Windows MPIO) com a política Round-Robin. Na teoria, isso balanceia a carga: I/O 1 vai para o caminho A, I/O 2 vai para o caminho B, e assim por diante.
Se o array fosse Ativo-Ativo Simétrico, isso seria perfeito. Mas em um array ALUA, o Round-Robin cego faz o seguinte:
- I/O 1 -> Caminho 1 (Controller A - Otimizado): Resposta em 0.5ms.
- I/O 2 -> Caminho 2 (Controller B - Não-Otimizado): O Controller B recebe, manda pelo interconnect para o A, o A processa, devolve para o B, o B responde ao host. Resposta em 2.5ms.
- I/O 3 -> Caminho 3 (Controller A - Otimizado): Resposta em 0.5ms.
- I/O 4 -> Caminho 4 (Controller B - Não-Otimizado): Resposta em 3.0ms (o interconnect estava ocupado).
O host vê uma latência média de 1.6ms. Parece bom. Mas a aplicação sente o jitter. O banco de dados, que espera consistência para seus logs de transação, começa a engasgar nos I/Os lentos.
Pior ainda é o cenário de Path Thrashing (Ping-Pong de LUN).
Alguns arrays mais antigos ou configurados agressivamente podem decidir que, se receberem muito I/O na porta Não-Otimizada, eles devem mover a posse do LUN para aquele controlador (operação de Trespass).
Imagine o cenário:
- Host manda I/O para o Controller B.
- Storage pensa: "Ei, o cliente quer falar com o B. Vou mover o LUN para o B." (Trespass).
- Host, seguindo o Round-Robin, manda o próximo I/O para o Controller A.
- Storage pensa: "Agora ele quer o A? Vou mover de volta." (Trespass).
Mover a posse de um LUN (Trespass) é uma operação pesada. Envolve flushing de cache, travas de metadados e pausa momentânea de I/O. Se isso acontecer em loop, sua performance vai a zero.
Diagnóstico: Lendo os Sinais de Fumaça
Como saber se você está sofrendo disso agora? Vamos para o terminal. O foco aqui é Linux (device-mapper-multipath), mas a lógica se aplica ao Windows/VMware.
1. A Verdade no multipath -ll
Execute multipath -ll. Não olhe apenas se os caminhos estão "active". Olhe para a prioridade (prio) e o agrupamento.
mpatha (360060160123456789012345678901234) dm-0 DGC,VRAID
size=100G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:0 sdb 8:16 active ready running
| `- 2:0:0:0 sdc 8:32 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:0 sdd 8:48 active ready running
`- 2:0:1:0 sde 8:64 active ready running
Análise Forense:
hwhandler='1 alua': O kernel detectou que é um array ALUA. Ótimo.- Grupos de Prioridade: Veja que temos dois grupos. O primeiro tem
prio=50. O segundo temprio=10. - Status: O primeiro grupo está
active, o segundo estáenabled.
Isso é um sistema saudável. O Device Mapper sabe que sdb e sdc são caminhos otimizados (prio 50) e só enviará I/O para eles. Os caminhos sdd e sde (prio 10) são de backup (não-otimizados). O tráfego não está sendo balanceado entre todos os 4, apenas entre os 2 melhores.
O Cenário de Desastre: Se você vir algo assim:
policy='multibus 0' prio=1 status=active
|- 1:0:0:0 sdb active ready running
|- 2:0:0:0 sdc active ready running
|- 1:0:1:0 sdd active ready running
`- 2:0:1:0 sde active ready running
Aqui, a política multibus colocou todos num único grupo. O prio é igual para todos. O host vai fazer Round-Robin entre caminhos otimizados e não-otimizados. Isso é a receita para a latência serrilhada.
2. Observando o Desbalanceamento com iostat
Se você suspeita que o ALUA não está sendo respeitado, use o iostat estendido.
iostat -x -d -p dm-0 2 (monitorando o dispositivo multipath e seus membros).
Sinal de Saúde:
sdbesdc(Otimizados): 2000 IOPS cada,await2ms.sddesde(Não-Otimizados): 0 IOPS.
Sinal de Perigo (Leakage):
sdb: 1500 IOPS,await2ms.sdd: 500 IOPS,await8ms.
Se você vê tráfego fluindo nos caminhos não-otimizados sem que tenha havido uma falha nos caminhos principais, sua configuração de multipath está errada. O host está "vazando" I/O para o caminho lento.
Políticas de Seleção: Escolhendo sua Arma
A configuração padrão de muitas distros Linux antigas ou instalações Windows default pode não ser a ideal. Vamos comparar as estratégias de seleção de caminho (Path Selection Policies - PSP).
| Política | Como Funciona | Veredito para ALUA |
|---|---|---|
| Round Robin (RR) | Envia I/O sequencialmente para cada caminho ativo no grupo. | Perigoso se mal configurado. Se agrupar caminhos otimizados e não-otimizados juntos, destrói a performance. Se usar grupos de prioridade corretos, é aceitável, mas cego à carga real. |
| Least Queue Depth (LQD) | Envia o próximo I/O para o caminho com menos I/Os pendentes na fila. | Excelente. Naturalmente evita caminhos lentos. Se um caminho não-otimizado demorar a responder, a fila dele enche, e o host para de mandar I/O para lá automaticamente. |
| Service Time (ST) | Calcula a latência baseada no throughput e tempo de serviço recente. | O Padrão de Ouro. É mais inteligente que o LQD. Ele percebe se um caminho está degradado (ex: erro de cabo intermitente) mesmo que a fila esteja vazia. |
| Fixed / Failover | Usa apenas um caminho até que ele morra. | Seguro, mas desperdício. Em um cenário com 4 caminhos, usar apenas 1 deixa muita banda na mesa. Útil apenas para debug. |
Recomendação Prática:
Em Linux modernos, service-time é geralmente o default para arrays conhecidos. Em VMware, o NMP (Native Multipathing Plugin) geralmente usa Round Robin por padrão, mas você deve verificar se o SATP (Storage Array Type Plugin) detectou corretamente o array como ALUA. Se o VMware achar que é "Active-Active" simétrico quando é ALUA, ele vai fazer o balanceamento errado.
O Mito da Redundância "Sem Soluços"
É crucial alinhar expectativas sobre o que acontece quando um cabo realmente quebra.
Em um cenário Ativo-Passivo puro, se o controlador ativo morre, há uma pausa de I/O de 10 a 60 segundos enquanto o passivo assume. O host segura o I/O na fila (queueing) e reenvia quando o novo caminho sobe. A aplicação congela, mas não cai (se o timeout de disco for configurado corretamente).
Em um cenário ALUA, a falha de um caminho otimizado é mais suave, mas não invisível.
- O host detecta erro no Caminho A (Otimizado).
- O driver de multipath marca o caminho como failed.
- O host começa a usar o Caminho B (Não-Otimizado) imediatamente?
- Depende. Geralmente, o host prefere esperar o array notificar que o LUN mudou de dono (Trespass implícito ou explícito).
- Se o host começar a mandar I/O pelo caminho Não-Otimizado antes do Trespass acontecer, teremos um pico de latência.
- Assim que o Storage percebe que o Controller A morreu, ele transfere a posse do LUN para o B. O caminho B vira "Otimizado". A latência volta ao normal.
A lição aqui: "Ativo-Ativo" não significa "Zero Impacto". Significa que os caminhos alternativos já estão estabelecidos, reduzindo o tempo de negociação, mas a física da mudança de posse do LUN ainda impõe uma penalidade transitória.
O Veredito sobre Arquitetura de Falhas
A complexidade é inimiga da disponibilidade. A promessa do "Ativo-Ativo" vende arrays, mas frequentemente entrega dores de cabeça operacionais se não for compreendida.
Ao auditar seu ambiente hoje, faça três perguntas:
- O Host sabe o que é Otimizado? Verifique se o driver MPIO está agrupando os caminhos por prioridade ALUA, e não jogando tudo num balde só.
- A Política é Inteligente? Mude de Round-Robin fixo para
service-timeouleast-queue-depthsempre que possível. Deixe a fila de I/O ditar o melhor caminho, não um algoritmo cego de distribuição de cartas. - Os Logs Mentem? Não confie na latência média. A média esconde os pecados do caminho não-otimizado. Olhe para os desvios padrão e os máximos.
Multipathing não é "set and forget". É um protocolo dinâmico de roteamento de dados. Se você tratar seus caminhos de fibra como cabos de rede passivos, sua latência pagará o preço. Configure para a falha, otimize para a física do hardware, e ignore o marketing.

Sarah 'The Backup' Connor
Gerente de Recuperação de Desastres
Seus dados não estão seguros até que ela diga que estão. Especialista em estratégias de backup imutável e RPO/RTO.