Proxmox Backup Server: Ocultando a Latência e Domando o I/O
Esqueça a largura de banda. No PBS, IOPS é rei. Aprenda a tunar ZFS, entender o Garbage Collection e dimensionar datastores sem gargalos.
Esqueça a ideia de que o Proxmox Backup Server (PBS) é apenas um destino para onde você joga arquivos .vma ou .qcow2. Se você tratar o PBS como um servidor de arquivos glorificado (como um NFS ou SMB share), você vai falhar. E vai falhar de forma barulhenta: backups lentos, operações de manutenção que duram dias e discos que "gritam" por misericórdia.
Para operar o PBS em escala, você precisa entender que ele não é um sistema de armazenamento de arquivos; ele é, essencialmente, um banco de dados de deduplicação.
O PBS não "copia arquivos". Ele quebra seus dados em pedaços (chunks), calcula um hash criptográfico para cada pedaço e armazena apenas os únicos. Isso muda tudo: desde como o disco é acessado até onde o gargalo de CPU realmente está. Vamos dissecar essa arquitetura e ver onde a realidade colide com o marketing.
A Ilusão do Arquivo: Content-Addressable Storage
A maioria dos sysadmins está acostumada com backups incrementais baseados em cadeia: Full -> Incr 1 -> Incr 2. Se o "Incr 1" corromper, você perdeu tudo o que veio depois. O PBS elimina isso usando Content-Addressable Storage (CAS).
No PBS, não existem "backups full" ou "incrementais" no sentido tradicional. Todo backup é matematicamente um backup completo, mas ocupa apenas o espaço das mudanças.
Como isso funciona na prática?
O cliente lê os dados da VM.
O cliente quebra os dados em chunks (geralmente de até 4MB).
O cliente calcula o hash (SHA-256) desse chunk.
O cliente pergunta ao servidor: "Você já tem o chunk
a1b2c3...?"Se o servidor disser "Sim", o cliente não envia nada. Apenas registra o índice.
Se o servidor disser "Não", o cliente envia o dado.
Isso cria uma divisão de trabalho brutal que muitas vezes é ignorada no dimensionamento de hardware.
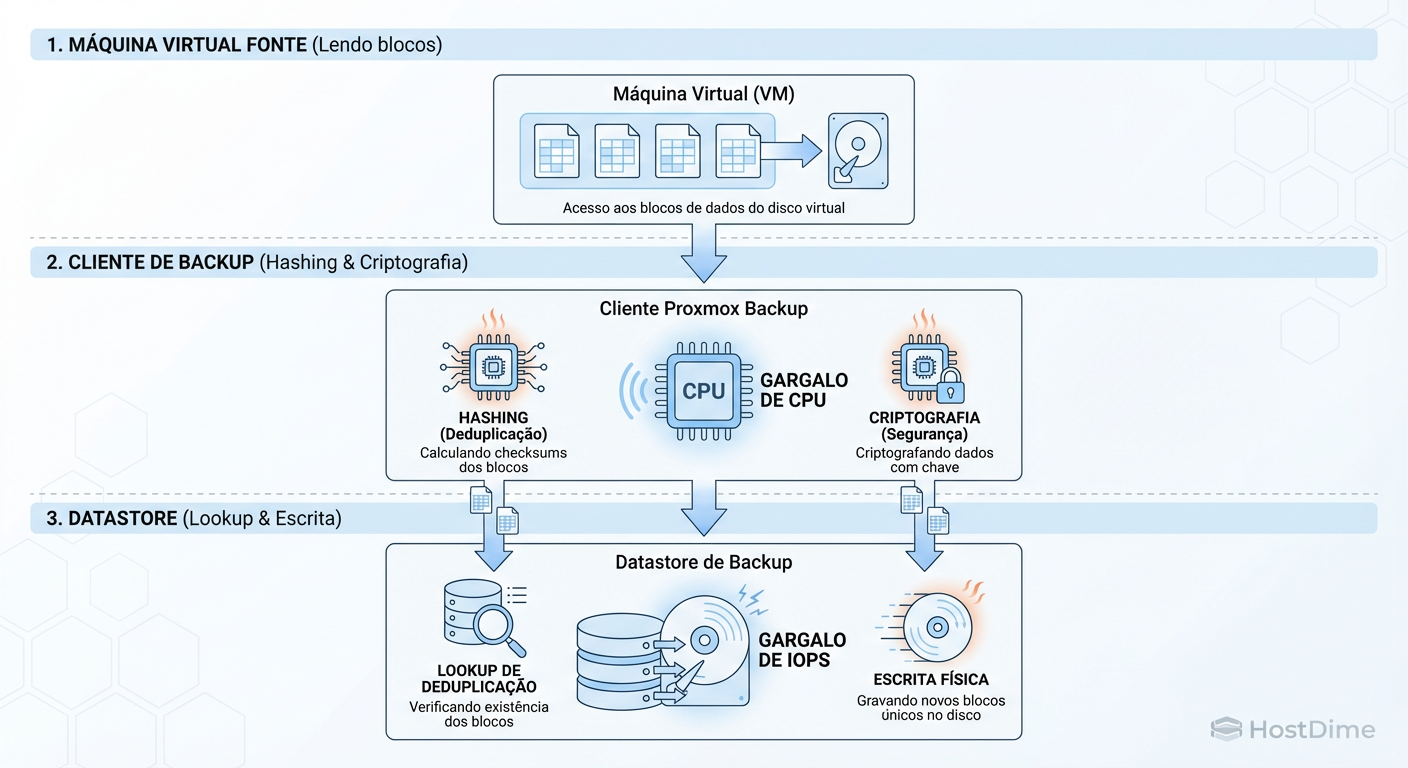 Figura: Onde dói: O cliente sua a CPU para hashear, o servidor sua o disco para buscar chunks existentes.
Figura: Onde dói: O cliente sua a CPU para hashear, o servidor sua o disco para buscar chunks existentes.
O gargalo aqui muda de lugar constantemente. Se você tem dados novos, o gargalo é a Rede e a Escrita em Disco. Se você tem dados repetidos (a maioria dos casos), o gargalo é a CPU do Cliente (para hashear) e o IOPS de Leitura do Servidor (para verificar a existência do índice).
O Gargalo Invisível: CPU e AES-NI
Muitos administradores reclamam que o backup está lento (ex: 50MB/s em uma rede 10Gbps) e culpam o disco do servidor. Na maioria das vezes, o culpado é o processador da máquina de origem (o host Proxmox VE).
O processo de hashing (SHA-256) e criptografia é intensivo. Se o seu host de virtualização está rodando em CPUs antigas ou se você limitou severamente os recursos de CPU do processo de backup, o disco do PBS ficará ocioso esperando o cliente terminar a matemática.
Regra de Ouro: Verifique se suas CPUs suportam e estão usando instruções AES-NI. Sem aceleração de hardware para criptografia, seu throughput vai despencar.
Para testar se o seu gargalo é o cliente ou a rede/disco, use a ferramenta de benchmark embutida no próprio cliente, não o iperf. O iperf mede rede pura; o benchmark do PBS mede a capacidade de processar criptografia e hashing:
# Rode isso no CLIENTE (PVE Host)
proxmox-backup-client benchmark --repository [email protected]:datastore
Se o resultado de "TLS speed" ou "SHA256 speed" for baixo, não adianta comprar NVMe para o servidor. O problema é a CPU da origem.
A Tirania dos IOPS: Onde os HDDs vão para morrer
Aqui é onde o "barato sai caro". O PBS armazena os chunks como arquivos individuais dentro de uma estrutura de diretórios baseada nos hashes (.chunks/aa/bb/aabb...).
Um datastore de 10TB pode conter milhões de pequenos arquivos de chunks. Durante um backup, a escrita é sequencial (bom para HDD). Mas durante operações de Garbage Collection (GC) ou Prune, o padrão de acesso é aleatório.
O Garbage Collection precisa percorrer todos os índices de todos os backups para saber quais chunks ainda estão em uso e quais podem ser deletados. Em um array de HDDs mecânicos (spinning rust), isso gera milhões de operações de seek.
O Sintoma: O GC demora 24h, 48h ou nunca termina. O servidor fica inavegável.
A Causa: HDDs entregam cerca de 100-200 IOPS aleatórios. O PBS pede milhares.
Se você está montando um PBS apenas com HDDs rotacionais sem nenhuma camada de cache ou log, você está construindo um sistema que vai falhar na primeira operação de manutenção pesada.
ZFS Tuning: A Salvação via Special Device
O ZFS é o sistema de arquivos "nativo" recomendado para o PBS. Mas as configurações padrão do ZFS no Linux não são otimizadas para a carga de trabalho do PBS.
1. Recordsize
O PBS grava chunks que variam de tamanho, mas tendem a ser maiores (até 4MB). O padrão do ZFS é recordsize=128k. Isso pode causar fragmentação e overhead de IOPS. Aumentar o recordsize para 1M no dataset do datastore geralmente melhora a performance de leitura sequencial e reduz a fragmentação dos metadados do ZFS.
zfs set recordsize=1M tank/backup-datastore
2. Compressão
Use zstd. É o padrão moderno. O PBS já faz compressão, mas o ZFS pode pegar o que sobra ou metadados. Mais importante: compression=on reduz a quantidade física de dados escritos, o que é sempre um ganho líquido em performance de disco moderno.
3. O "Special Device" (Obrigatório para HDDs)
Se você precisa de muita capacidade (ex: 100TB) e não pode pagar por 100TB de SSDs, a arquitetura híbrida é a única saída viável.
O ZFS permite adicionar um vdev Special. Este dispositivo armazena os Metadados (onde os dados estão fisicamente) e, opcionalmente, blocos de dados pequenos.
Ao colocar os metadados em um par de SSDs (mirror) e os dados brutos nos HDDs, você elimina a maior parte dos seeks lentos durante o Garbage Collection e listagens de arquivos. O PBS precisa ler metadados massivamente para saber "quem é quem". Se isso vier do SSD, a performance voa.
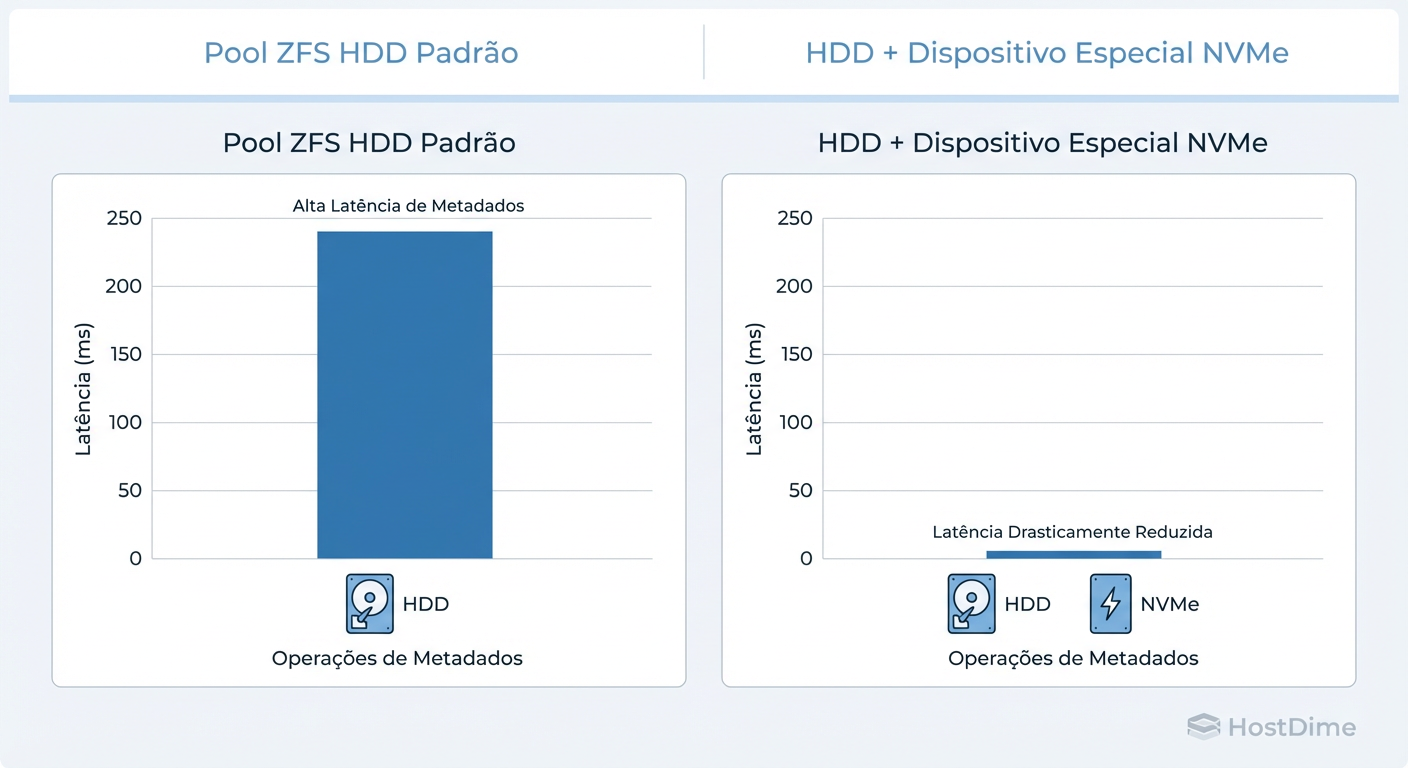 Figura: A diferença brutal que um 'Special Device' faz em operações de metadados (prune/GC).
Figura: A diferença brutal que um 'Special Device' faz em operações de metadados (prune/GC).
Para configurar isso, você define o special_small_blocks. Se você definir, por exemplo, para 4K, qualquer arquivo menor que 4K vai para o SSD. Como os metadados do PBS e os próprios índices são pequenos, eles vivem no flash, enquanto os chunks gordos vivem no disco magnético.
Aviso Crítico: Se você perder o vdev Special, você perde o pool inteiro. Sempre use espelhamento (RAID1) para o dispositivo Special. Um único SSD falhando aqui é catastrófico.
Ciclos de Manutenção: O Impacto na Produção
Não configure suas tarefas de manutenção (Prune, GC, Verify) para rodarem simultaneamente ou durante a janela de backup.
Prune (Poda): É leve. Ele apenas deleta os arquivos de índice (
.fidx) que definem um ponto de backup. Ele não deleta os dados (chunks) imediatamente. Pode rodar diariamente.Garbage Collection (GC): É pesado. Ele varre o sistema procurando chunks órfãos (que foram podados e não são usados por nenhum outro backup). É intensivo em leitura e CPU.
- Dica de Operação: Agende o GC para rodar após o Prune e fora do horário de backup. Se seus discos são lentos, rode semanalmente, não diariamente.
Verify: Lê os dados fisicamente para checar bit-rot. É o teste definitivo de que seu backup é restaurável.
- Estratégia: Não tente verificar tudo todo dia. Use a opção de verificar apenas snapshots novos ou aqueles com mais de X dias (
re-verify-after).
- Estratégia: Não tente verificar tudo todo dia. Use a opção de verificar apenas snapshots novos ou aqueles com mais de X dias (
Métricas que Importam (Show me the numbers)
Não confie na interface web para diagnóstico fino. Vá para o terminal.
Quando o sistema estiver lento ("iowait" alto), use o iostat para ver a latência real dos discos.
# Instale sysstat se não tiver
iostat -x 1
Olhe para as colunas:
r_awaitew_await: O tempo (em ms) que o disco leva para responder. Se você ver números acima de 10-20ms em SSDs ou 100ms em HDDs consistentemente, seu armazenamento saturou.%util: Se está em 100% constantemente, você atingiu o limite físico da interface ou do disco.
Para o ZFS especificamente:
zpool iostat -v 2
Isso mostrará a escrita/leitura separada por vdev. Aqui você pode provar se o seu "Special Device" está realmente absorvendo a carga de metadados ou se os HDDs ainda estão sendo martelados.
Resumo Operacional
Entenda o Fluxo: O cliente hashea (CPU), o servidor armazena chunks (IOPS).
Hardware: Evite HDDs puros. Se usar, exija um ZFS Special Device (SSD Mirror).
Tuning:
recordsize=1Mno ZFS, ative AES-NI no cliente.Ceticismo: Se o backup está lento, teste o cliente (
proxmox-backup-client benchmark) antes de culpar o servidor.
O PBS é uma ferramenta de nível enterprise. Ele exige arquitetura, não apenas instalação. Trate-o com o respeito que um banco de dados merece, e ele salvará sua pele quando o ransomware atacar. Trate-o como uma pasta compartilhada, e ele será seu pesadelo.

Elena Kovacs
Arquiteta de Cloud Infrastructure
Focada em NVMe-oF e storage definido por software. Projeta clusters de petabytes para grandes provedores de nuvem.